
基于RGB-D相机数据的SLAM算法研究∗
2021-08-28 06:52:56刘继忠
传感技术学报 2021年6期
刘继忠,王 聪,曾 成
(南昌大学机电工程学院,南昌大学南昌市医工结合技术研究重点实验室,江西 南昌 330031)
同时定位与地图构建(Simultaneous Localization and Mapping)作为智能移动机器人自主导航和定位的基础,近年来,已经成为移动机器人领域的热点。根据采集数据的传感器类型,可以分成激光雷达[1]和视觉传感器[2]两类。在最初的SLAM里,被用来作为传感器采集数据的大多为激光雷达,虽然其具有精度较高的优势,但价格较贵,性价比不高。近年来,视觉传感器开始应用于SLAM并取得较好的效果,与激光雷达相比较,相机的优势在于成本低廉和较高的性价比,而且可以得到更多的信息。应用于SLAM的相机可以大致分为三类:单目相机、双目相机和RGB-D[3]相机。单目相机不能直接得到物体与相机的距离,需经过相机平移后计算深度,但有尺度不确定性的缺点;双目相机可以通过两个相机的视差计算深度,但计算视差的运算量较大,消耗计算资源;RGB-D相机,如Kinect等,可同时获取到RGB(彩色)图像和相对应的深度图像,因可以直接得到深度信息,且价格低廉,性价比较高。因此,RGB-D相机成为了SLAM的主流视觉传感器[4-5]。
自SLAM发展以来,后端诞生了两种主要的方式:滤波和优化。早期的SLAM求解方式大多是基于滤波器的,如卡尔曼滤波等。但当构建地图不断增大,内存会被大量占用,且计算量也逐渐增大。而基于图优化方法,在处理SLAM的优化问题时,会将其转化为图的形式,通常会将图的优化表示成非线性最小二乘问题。和基于滤波器的方法相比,图优化的优势在于,在长时间的更大规模和尺度的地图上,有优良的精度和性能[6]。2014年,Endres等[7]提出了一种较完整的RGB-D SLAM方法,主要包括视觉里程计和后端优化,并生成了三维稠密点云地图。但该方法实时性较差。2016年,Mur-Artal等[8]的ORB-SLAM2方法可以使用双目相机和RGB-D相机,但是最终只生成了稀疏地图。张慧娟等[9]于2019年提出一种基于线特征的视觉里程计方法,但线特征的提取相对于点特征较为困难。在2020年,Cheng[10]在Dyna-SLAM基础上,通过结合语义信息来构建地图,并提出一种DM-SLAM方法。Cheng[11]在ORB-SLAM2的基础上,通过YOLO学习模型和贝叶斯滤波后验估计相结合的方式,从而提出一种改进的动态SLAM。但结合深度学习的视觉SLAM算法会因特征丢失而无法估计位姿。基于上述的研究现状,本文提出了一种改进的RGB-D SLAM算法,对彩色图像使用SURF特征和FLANN算法完成特征提取和匹配,再使用改进的最小距离法和RANSAC相组合的方式将匹配中的误匹配剔除;在前端,使用PNP求解相邻帧间的位姿变化。在后端优化部分使用G2O进行位姿图优化。为了节省系统的计算资源的占用以增强算法的实时性,设计了一种关键帧的提取机制。在前端中产生的累计误差,通过设计的一种基于局部回环和随机回环结合的方式来进行回环检测来消除,并构建出了三维稠密点云地图。
1 系统结构
本文提出的基于RGB-D相机数据的同时定位与地图构建(SLAM)算法的具体框架如图1所示,主要包括特征提取与匹配、帧间配准、后端的优化和回环检测。

图1 基于RGB-D相机数据的SLAM算法的总体框架
2 特征提取与匹配
在视觉SLAM中,前端又被称为视觉里程计(VO)。它使用相邻帧之间的信息来粗略估计摄像机的运动,并把数据传送给后端进行图优化处理。前端根据是否需要提取图像的特征点,将其分为特征点法和直接法。直接法不需进行特征点提取,不用计算描述子和特征点匹配,故节省了计算量和运算时间。缺点是非凸优化易陷入局部极值;且完全依靠梯度搜索,当相机出现较大尺度移动或旋转时,会导致追踪产生的效果不够理想。而基于特征点法的前端一直以来是主流方式,故本文采用特征点法作为前端。
特征点的提取主要是特征检测和描述符提取,特征点提取算法有SIFT[12](Scale Invariant Feature Transform)、SURF[13](Speeded Up Robust Features)、FAST[14](Features From Accelerated Segment Test)等。SIFT即尺度不变特征变换算法,计算量较大,实时性不高,且有时特征点较少。FAST特征点检测速度较快,但不具备方向性。SURF特征具有更好的旋转和尺度变换鲁棒性,实时性也相对较好。因此,本文采用基于SURF特征提取特征点。
特征点匹配方法通常使用两种匹配方式:暴力匹配(Brute Force)和最近邻近似匹配[15](Fast Library for Approximate Nearest Neighbors)。暴力匹配始终尝试所有可能的匹配,来找到最佳的匹配,当处理的特征点数量较大时,该方法的运算量增加,运行时间较长,且有较多误匹配。FLANN算法是查找相对较好的匹配,但不需要找到最佳匹配,从而大大节省了匹配时间。因此,本文选用FLANN算法。
进行特征匹配后,会有大量的误匹配存在,这时就需要剔除产生的误匹配,来提高最终匹配的准确性。本文采用改进的最小距离阈值法与RANSAC共同剔除误匹配的方法[16]。在进行RANSAC剔除时,已经进行过粗剔除,故这里取原来迭代次数的一半,即迭代50次,RANSAC过程使用的内部阈值取5。具体方法如下:首先根据提取的特征点个数进行判断,当特征点数目较少时,即图片所含的场景信息较少,则采用阈值为5的最小距离,当特征点数目较多时,即图片所含的场景信息较丰富,则采用阈值为3的最小距离。然后再使用RANSAC算法剔除剩下的误匹配,来得到最优的匹配结果。
利用SURF特征结合FLANN进行特征检测与匹配的大致流程如下。
①构建高斯金字塔尺度空间
SURF算法主要是通过海森矩阵(Hessian matrix)来构建高斯金字塔尺度空间,其中海森矩阵是由函数的二阶偏导数构成,记函数为f(x,y),具体如式(1)所示。海森矩阵的判别式为式(2):
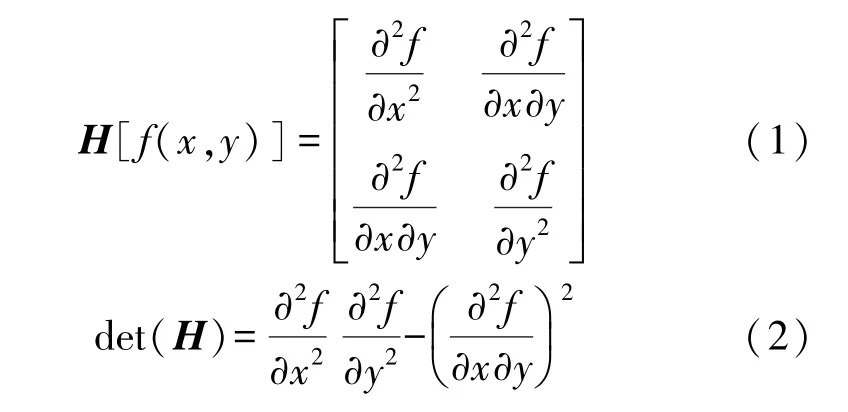
式中:det(H)为H矩阵的特征值。
在SURF算法中,将函数值f(x,y)替换为图像像素l(x,y),滤波器使用二阶标准高斯函数,再通过特定核间的卷积来计算二阶偏导数。先计算出H矩阵中的3个元素L xx(x,σ)、L x y(x,σ)和L y y(x,σ),从而得出H矩阵,具体公式如下式(3)、式(4)
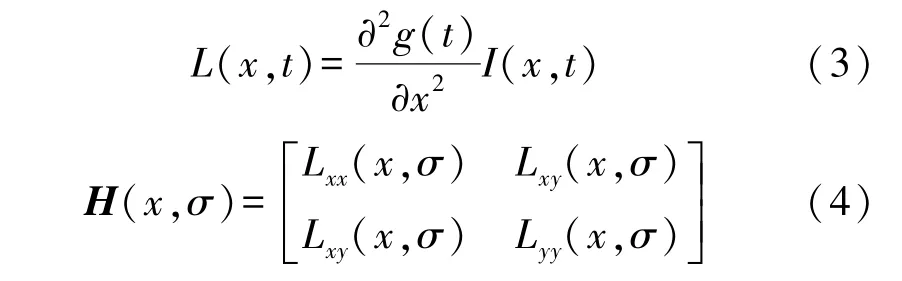
式中:g(t)为高斯函数,t为高斯方差,L xx(x,σ)是高斯二阶导数与图像I在X点处的卷积。L xy(x,σ)和L yy(x,σ)则为高斯二阶导数在对应xy和y方向上的卷积。
Bay提出使用近似值代替L(x,t),通过引入权值的方法来使准确值与近似值达到平衡。H矩阵的判别式的近似计算为:
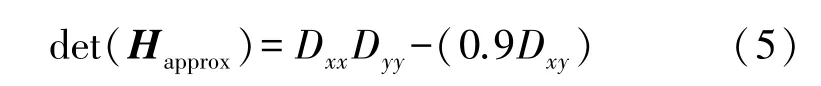
式中:det(Happrox)表示在点x邻近区域的滤波响应值的近似结果。这里的0.9为经验值。
在计算机视觉领域里,图像的尺度空间要反复对输入图像与高斯函数的计算核卷积,并对其进行二次抽样,这被称为图像金字塔。SIFT算法的图像金字塔使用连续对图像降采样建立的结构,并不断利用高斯模板的方式进行平滑处理,以达到滤除图像的噪声效果。而SURF算法则主要是维持图像的原始尺寸不变,对高斯滤波器的大小进行变化。SIFT和SURF的图像金字塔如图2所示。

图2 SIFT和SURF的图像金字塔
②初步检测特征点
在检测过程中,滤波器的大小通常为与该尺度层图像解析度相对应。图3中是以3×3的滤波器为例,该尺度层图像中9个像素点中一个特征点,与该层其余8个点和其上下两个尺度层的9个点,总共26个点进行比较。若图3中“X”标志的特征值大于周围像素,则该点即为该区域的特征点。
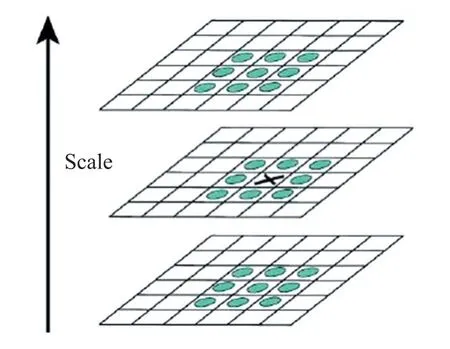
图3 初步检测特征点
③精准定位极值点
在定位极值点时,一般采用三维线性插值法得到亚像素级的特征点,并舍去小于预设阈值的点。通过增加极值的方式,减少检测到的特征点数量,保证只检测出特征最强的点。
④确定特征点的主方向
在SURF算法中,主要是统计特征点领域内的小波特征点的方式,来确定特征点的主方向。即以特征点为中心,半径为6 s(这里的s为该点所在的尺度)的圆形区域内,计算60°扇形内在x和y方向的Haar小波特征总和,Haar小波的尺寸变成4 s,该扇形得到了一个值。旋转遍历整个区域后,其中最大值的区域即为特征点的主方向。
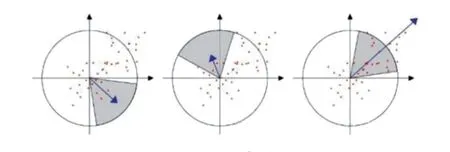
图4 确定特征点的主方向
⑤生成SURF特征描述子
在SURF算法中,以特征点为中心,按照主方向取20 s×20 s的方框,再将该方框分成4×4个的子区域,然后计算每个子区域5 s×5 s内的Haar小波特征。该Haar小波特征为对dx,d|x|,dy,d|y|求和,记 为。这样各个小区域就有4个值,从而得到一个特征点为4×4×4=64维的向量
具体如图5所示。
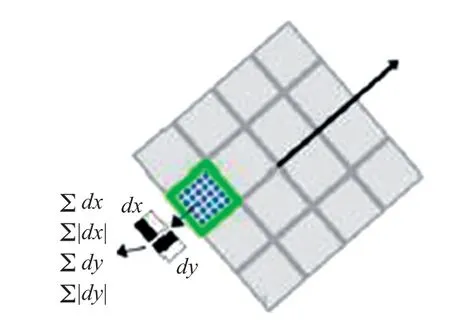
图5 生成SURF特征描述子
⑥通过FLANN对特征描述子进行匹配
FLANN算法模型的特征空间通常是n维的向量空间R n,主要是通过欧式距离寻找实例点的邻居。将两帧图像的特征点集合记为:

则两特征点的欧式距离为:
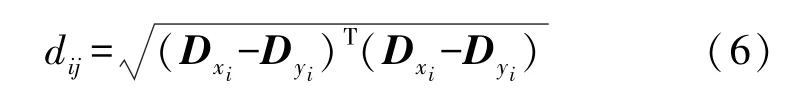
式中:D x i、D y i为x i、y i的特征向量。向量空间R n中的全部欧式距离d i j,在经过KD-TREE结构存储后,就能够搜索与参考点最近距离的点进行两点的匹配。
3 帧间配准
相机通常采用针孔相机模型,来表达空间点投影到像素坐标系的转换关系。若空间中一点为P(X w,Yw,Z w),投影到像素坐标系的点p(x,y),深度值为d,从世界坐标系到像素坐标系的变换如下:

式中:f x和f y分别为深度相机在水平和竖直方向上的焦距;cx和c y分别为图像坐标系与像素坐标系的平移量;s为深度缩放因子。相机的内参K则由f x和f y、c x和c y组成,通常会通过标定的方法来获得准确的数值,常用的标定法有张正友标定法等,这里就不详细介绍。
通常情况下f x、f y、cx、c y所定义的内参矩阵K形式为

当相机处于运动状态时,空间点P根据相机的当前位姿变换到相机坐标系,可表示为:

式中:K是相机的内参矩阵,T代表相机的外参数,由相机位姿的R旋转矩阵和t平移矩阵组成,两帧图像之间的运动关系即为外参。变换矩阵T的表示形式为:

式中:左上角为3×3旋转矩阵R,右上角为3×1的位移向量,左下角为0向量,右下角为1。
在帧间配准阶段,需要计算出两帧图像间运动的变换矩阵T,SLAM中一般通过PNP(Perspective-N-Point),迭代最近点(Iterative Closest Point)算法等来实现。ICP算法是3D-3D点之间的变换,需要较好的初值,且算法本身的缺陷,容易使迭代陷入局部最优解,因此本文选用PNP算法来求解。PNP算法是通过3D-2D点运动的变换来求解,即当已知n个3D空间点和它的投影位置时,来估算获得相机的位姿。OpenCV自带有PNP函数接口,使用时只需调用即可。
4 后端优化与回环检测
4.1 后端优化
在进行相邻两帧匹配后,通过计算它们之间的运动变化来求解相机位姿,并送入后端优化,从而获得相机位姿和运动轨迹的全局最优解,再经点云转换拼接后,构建出完整的点云地图。
一个经典SLAM模型可由运动方程和观测方程[17]表示为:

式中:x k为机器人位姿,u k为运动数据,z k,j为观测数据,y j为路标点,ωk和v k,j为噪声。在SLAM里,一般是通过估计x k来描述机器人定位,估计y j来构建地图。
本文使用G2O[18]优化算法进行位姿图优化,常用的G2O迭代策略有梯度下降法(DogLog)、高斯牛顿法(Gauss-Newton)和列文伯格-马夸尔特方法(Levenberg-Marquadt)等。对于前端产生的带有噪声的数据,后端的G2O优化算法可以把这些数据作为优化变量来优化。在特征匹配后,通过PNP求解估计两个相邻关键帧之间的运动以确定初始值并构造姿势节点的边。当完成初始估计后,就可以不用优化路标点的位姿,而主要去关注所有相机的位姿联系。这显著减少了用于计算特征点的优化时间,并且仅保存了关键帧的轨迹。其总体目标函数表示如下:

这即是一个非线性优化的问题。可以使用G2O来优化。将待优化问题转变为图的模型表示。本文使用Levenberg-Marquadt(L-M)方法进行优化,当误差稳定后算法收敛,同时获得相机的最优位置和姿态。
4.2 回环检测
前端根据相邻或相近两帧图像得到位姿估计,若前端出现误差并送入后端时,后端根据已有的结果进行优化,这样基于误差的估计优化会增加不确定性,一段时间后会出现累计误差,最终使得计算的轨迹出现偏离。而回环检测[19]的目的是消除累计误差。
由于图像帧数较多,把每一帧进行匹配会徒增计算量,从而降低算法实时性,故可通过初步筛选关键帧以降低算法运算时间,详细步骤如下:设关键帧的序列为Qi(i=0,1…,N),并且Q0是第一帧,然后每次获得新的图像帧时,它都会计算它与序列Q i中最后一帧之间的运动变换,并计算它们的变换矩阵T i(i=0,1…,N),通过该运动变换与设定的阈值比较,其关键帧的阈值为0.2,选择满足条件的帧作为关键帧,并将该帧映射到Q i中的最后m个关键帧,形成局部回环。最后,将从Q i中随机选择的n个关键帧映射到一个帧,从而构成随机回环。匹配成功后,将在Q i的末尾放置一个新帧。
4.3 地图构建
经过以上步骤便能够通过提取出的关键帧的位姿构建出三维点云图。到目前为止,视觉SLAM构建的地图共有3种:第一种是稀疏地图,这种地图更倾向于定位;第二种是语义地图,主要是侧重于交互,即人与地图之间的互动;第三种是稠密地图,通常用来导航和定位。文中采用稠密地图来构建地图。
在构造点云图时,每个图像帧会创建大量点云,并且640×480像素的图像将创建超过300000个点云,会使得最终点云地图过大,且会消耗很大的储存空间[20]。因此本文将其转化为八叉树地图(Octo-Map)。其具有内存占用小等优点。OctoMap是一种三维栅格地图,其可以调整体素大小,来改变该地图的分辨率。这类地图可以适用于移动机器人的三维路径规划和导航。
5 实验结果
本文实验采用处理器为一台inter(R)Core(TM)i5-8300H八核CPU@2.30GHz,8G内存,ubuntu 16.04操作系统的笔记本电脑。本文实验采用NYU Depth Dataset V2数据集[21]和TUM公开数据集[22]进行试验。
5.1 特征提取与匹配
通过对相同图像提取特征点,统计了SIFT算法和SURF算法的特征点个数、匹配点数、匹配成功率和运行时间这4个指标,其中,特征点的个数反映了算法提取特征点的能力,若提取的特征点数量越多,则说明图像细节信息越丰富;匹配点数和匹配成功率表示两帧图像匹配的质量,数值越大,匹配效果越好;运行时间即为算法提取特征点的效率。计算图像处理时的平均耗时,结果如表1所示。

表1 特征点检测结果对比
从表1中可明显看出,SURF算法的处理速度和提取特征点个数都要明显优于SIFT算法。图6中为特征点提取结果图。在特征点提取的结果图中,特征点由圆圈表示,圆心表示特征点位于图像中的位置,圆的直径表示特征的尺度信息,从圆心发出的直线表示特征点的方向。表2为本文算法和文献[23]进行对比的结果,可以看出本文算法在运行时间上有很大的提升,且正确的匹配率与之相当。图7为未经处理的匹配结果。其中,cafe总共筛选了707组匹配,fr1/xyz总共筛选了840组匹配,fr1/desk共筛选595组匹配,其中有很多的误匹配。

图6 不同的特征点提取算法结果图

图7 未经处理的匹配结果

表2 剔除误匹配结果对比
图8是经过本文方法筛选后的匹配结果。其中,由于fr1/xyz中所含特征点较多,故采用阈值为3的最小匹配距离,所得结果为图8(b);图8(a)和图8(c)都采用阈值为5。从图8中可以清楚地看到,本文中的方法可以更好地消除误匹配,从而大大提高了匹配特征的准确性。

图8 本文方法剔除误匹配后结果
5.2 地图构建
通过前端(视觉里程计),即未加入后端优化和回环检测,生成如图9(a)所示的地图。可以看出,优化前的地图,即通过前端生成的地图,中间分布有大量散乱的点云,咖啡台外轮廓较模糊,中间的桌子也未能很好的构建出来。图9(b)为本文方法实现的三维点云地图重建。从构建的三维地图各个角度可以发现墙壁,桌子,台灯,行人等得到了较好的构建。经过对比优化前后的地图可以看出,优化后的地图相对更加清晰。在生成三维点云地图后,转化成分辨率为0.05 m的OctoMap格式,如图10所示。其中,三维点云地图占用49 Mbyte左右内参存,而OctoMap地图仅使用了23 kbyte左右,大大减少了内存占用。

图9 三维点云地图

图10 八叉树地图
5.3 回环检测
回环检测时,通过增加帧间的约束,来提高算法的鲁棒性,从而提升SLAM的轨迹和建图质量。本文算法在选取关键帧后,通过PNP求解估计两帧间的运动以确定姿势节点的边,并进行回环检测。表3中最左列里的数即为关键帧的序列,右边的7组数表示相机的位姿,它的记录方式是平移向量加旋转四元数:[x,y,z,q x,q y,qz,q w],其中x,y,z表示空间中的三个坐标轴的位移,q x,q y,q z表示旋转四元数的虚部,qw为旋转四元数的实部。
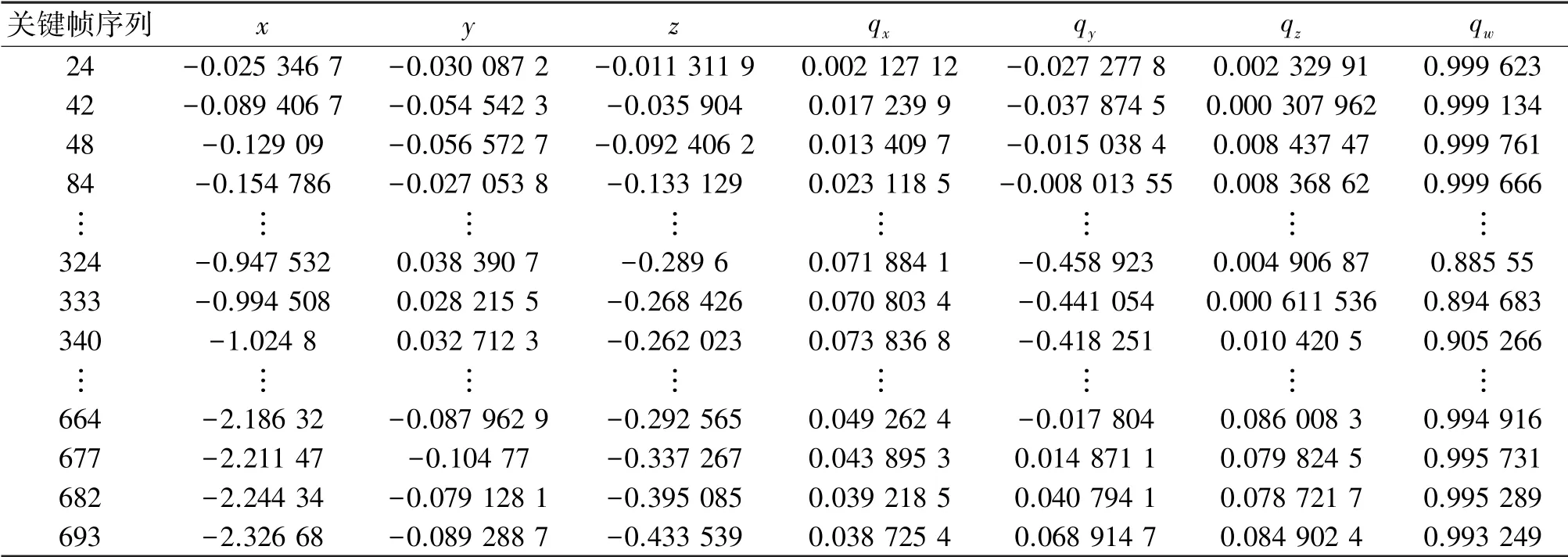
表3 部分关键帧序列与相机位姿
图11(a)中位姿图仅考虑相邻两帧的联系,若某一帧产生误差将会不可避免的累积至后面的帧,从而造成整个SLAM出现累积误差,其中共有700张图像;图11(b)为添加回环检测后的位姿图,深蓝部分表示为选取的关键帧,其顶点为相机位姿,边为两点之间的相对运动估计,即两点间的位姿变换,其中提取关键帧62张。局部回环代表当前帧与最后的m帧间的映射,大回环代表当前帧和关键帧序列中随机n帧的映射。本文中m=5,n=5。图12为回环检测时关键帧的部分变换矩阵T。

图11 位姿图

图12 部分变换矩阵
最后,本文使用公开数据集fr1/xyz和fr1/desk进行测试,通过从运算效率上与文献[7]所提出的RGB-D SLAM算法进行对比,计算出平均处理每帧所需的时间,如表3所示。
从表4中可以看出,本文所提算法处理每帧的时间明显优于RGB-D SLAM算法,说明本文算法的实时性更好。

表4 本文算法与RGB-D SLAM算法对比
6 结束语
文中提出了一种基于RGB-D相机数据的实时性的SLAM方案。该算法使用SURF算法提取特征点,使用FLANN算法进行特征匹配,结合最小距离和RANSAC消除误匹配,提高了算法的实时性和匹配精度;结合回环检测和G2O优化算法,来完成对三维地图的优化,并将三维稠密地图转化为八叉树地图用于后续导航。实验结果表明本文算法具有可行性与有效性。未来将继续通过改进算法来提高算法的实时性和地图的精确性。
猜你喜欢
中学生数理化·八年级物理人教版(2020年6期)2020-10-30 01:52:57
宝藏(2018年3期)2018-06-29 03:43:10
大连理工大学学报(2017年4期)2017-08-07 07:03:20
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
西北工业大学学报(2015年3期)2015-12-14 13:08:46
体育世界(学术版)(2015年3期)2015-07-01 17:15:34
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
