
耦合信息量和Logistic回归模型的滑坡易发性评价
2021-08-25 18:24李怡静胡奇超刘华赞杜臻陈佳武黄锦昌黄发明
人民长江 2021年6期
李怡静 胡奇超 刘华赞 杜臻 陈佳武 黄锦昌 黄发明
摘要:区域滑坡易发性预测能准确地反映出特定研究区内滑坡分布的空间概率特征。基于信息量和Logistic回归的耦合模型,对江西省崇义县滑坡易发性进行了预测,首先选取高程、坡度、坡体结构、平面曲率、剖面曲率、地形起伏度、距水系距离、岩性、归一化植被指数(NDVI)和归一化建筑指数(NDBI)等 10个影响因子;之后利用各因子的信息量值来构建Logistic回归模型;最后以信息量模型和Logistic回归模型作为对比模型来探讨3种模型各自的滑坡易发性评价结果。结果表明:耦合模型具有最好的预测性能(AUC=80.4%),其余依次为Logistic回归模型(76.8%)和信息量模型(72.8%);各模型所预测的滑坡易发性分布规律具有一定的相似性,滑坡灾害多集中发生于海拔高程较低、接近水系、碳酸盐岩性地层构造、植被覆盖率低、建筑密集的区域。
关 键 词:
滑坡易发性预测; 影响因子; 信息量模型; Logistic回归模型; 信息量-Logistic回归耦合模型
中图法分类号: O319.56
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2021.06.016
0 引 言
滑坡是指斜坡岩土体沿着一定的软弱面或者软弱带发生剪切破坏产生滑移的一种灾害现象,常常给工农业生产以及人民生命财产造成巨大损失[1]。在全球范围内,每年因滑坡及其次生灾害导致的人员伤亡数以万计[2-4]。根据自然资源部《中国土地矿产海洋资源统计公报》公布的数据,仅2017年国内就发生了地质灾害7 122起,造成327人死亡,25人失踪,173人受伤,直接经济损失达35.37亿元。此外,许多学者通过滑坡易发性预测来获取各地区潜在高危险区域来降低滑坡灾害损失,并在世界各地取得了良好的效果[5]。
根据各个研究区内不同的环境状况,构建出与研究区相匹配的评价模型对滑坡易发性评价的准确性尤为重要。Huang等[6]根据评价原理将易发性预测模型分为概率模型[7]、启发式模型[8]、确定性模型[9]、数理统计[10]和机器学习模型[11-13]。其中,数理统计模型利用统计方法来寻找各环境因子与滑坡发生之间的潜在联系,在易发性评价中有着广泛的应用[14]。
在单一数理统计模型运用方面,许英姿等[15]采用信息量模型对滑坡易发性进行了评价,张向营等[16]也利用信息量模型对京张高铁的滑坡危险性进行了预测。此外,许冲等[17-19]也借助Logistic回归模型预测了降雨型滑坡易发性。虽然这两种模型的评价效果较理想,但仍具有单一模型评价的缺陷。对于信息量模型,其信息量值虽然能够反映出环境因子各子区间是否有利于滑坡发育,却并不能够表现出各影响因子对诱发滑坡的贡献权重。Logistic回归模型是基于自变量与因变量之间的多元统计分析,能够体现不同因子对滑坡影响程度的差异,但却无法从空间角度表现各因子子区间与滑坡的相关性。
综上所述,信息量模型与Logistic回归模型的互相结合,将弥补单一模型的局限性。因此,为了获取更理想的预测模型,本文以江西省崇义县滑坡为例,对信息量模型、Logistic回归模型以及信息量-Logistic回归耦合模型进行滑坡易发性对比研究,以期获得准确率更高的评估结果。
1 研究方法
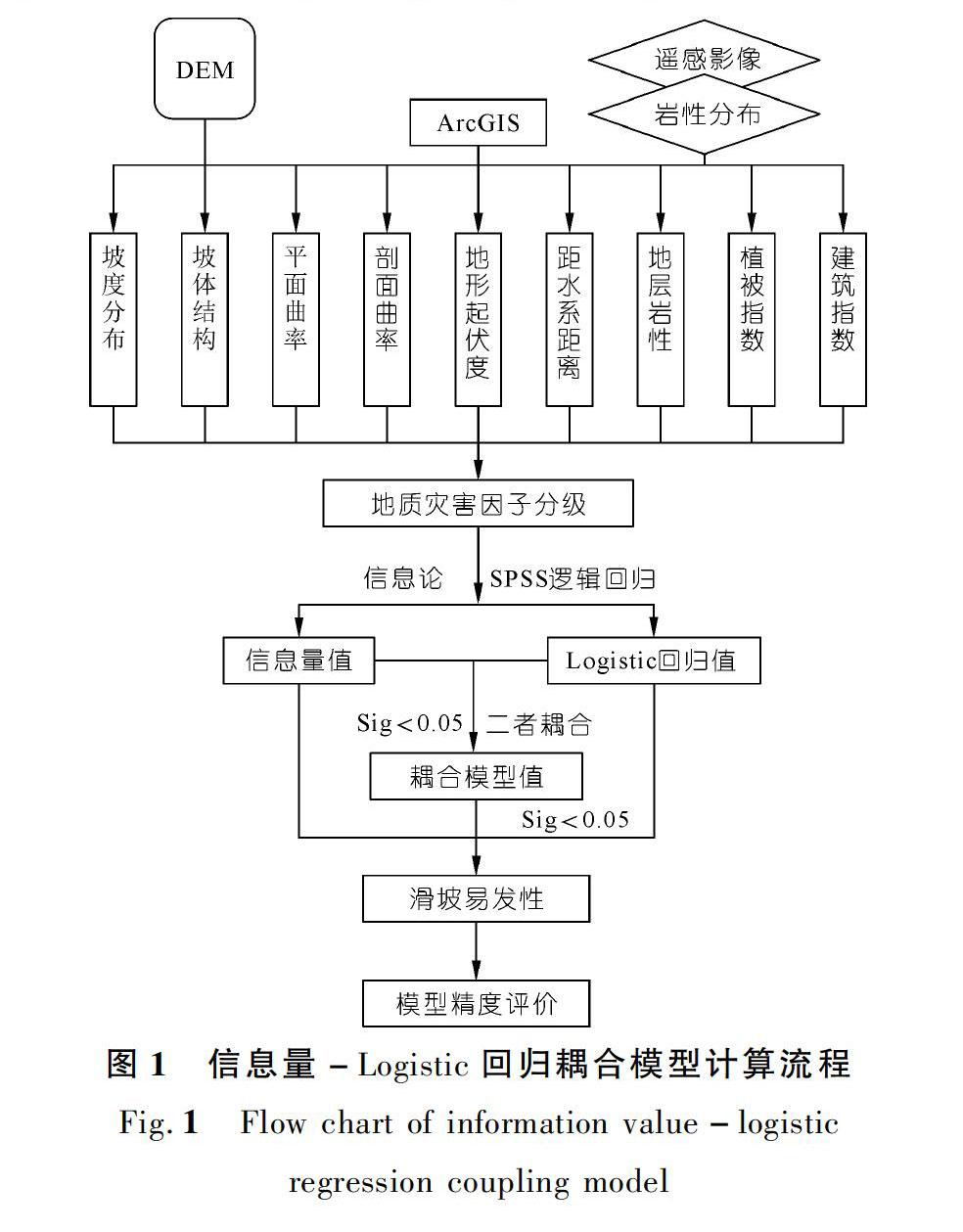
通过信息量-Logistic回归耦合模型开展研究的主要步骤包括:① 结合研究区滑坡发育特征及地质条件,选取合理的各环境因子;② 基于滑坡编录信息及相关环境因子,提取各环境因子信息量值;③ 以信息量值为指标,构建逻辑回归模型;④ 易发性分布图的制作及模型精度评价。具体计算流程如图1所示。
1.1 信息量模型
信息量模型在滑坡灾害预测领域应用较为广泛。在实际操作中,一般先计算出每个评价因子中各区间所对应的信息量值,再进行叠加得到多因子综合信息量值。其中,综合信息量值越大,表明滑坡灾害易发性程度越高[20-24]。信息量模型的计算过程如下:
IAj-k=lnnj-k/sj-kn/s
j=1,2,3,…,m;k=1,2,3,…,n(1)
I=mj=1IAj-k=mj=1(IAj-1,IAj-2,IAj-3,…,IAj-n)(2)
式中:nj-k和sj-k分别为第j个影响因子第k区间的滑坡面积和研究区面积;n和s分别为滑坡总面积和研究区总面积;IAj-k和I分别为单因子信息量值和综合信息量值。各影响因子信息量值是有正负的,正值表示有利于滑坡灾害的发生;负值表示不利于滑坡灾害的发生。
1.2 Logistic回归模型
在已知的回归模型中,Logistic回归模型因其简单的形式以及优异的性能被广泛应用于滑坡的易发性评价。在本文研究当中,选取各评价因子的频率比值作为自变量,以滑坡发生与否作为分类因变量,利用构建好的模型对未知的滑坡栅格进行概率预测。该模型的计算过程如式(3)所示,对P作Logit函数转换,结果如式(4)所示:
LogitP=a0+a1x1+a2x2+…+anxn (3)
P=expa0+a1x1+a2x2+…+anxn1+expa0+a1x1+a2x2+…+anxn(4)
式中:x1,x2,x3,…,xn表示各環境因子;LogitP为滑坡灾害发生概率;a0为常数,表示在所有影响因子影响的前提下滑坡发生与不发生概率之比的对数值[25];ai为逻辑回归系数。
1.3 信息量-逻辑回归耦合模型
在滑坡灾害分析中,信息量-Logistic回归耦合模型主要是利用已知的滑坡点和随机选取相同数量的非滑坡点来提取各因子子区间的信息量值,并以此建立逻辑回归方程。这样,不仅考虑了不同因子对滑坡发生的贡献权重,而且兼顾了各因子子区间致灾效应的大小。信息量-Logistic回归耦合模型的计算过程如下:
LogitP=b0+b1(IA1-1,IA1-2,IA1-3,…,IA1-n)+
…+bm(IAm-1,IAm-2,IAm-3,…,IAm-n)=b0+b1(lnn1-1/s1-1n/s,lnn1-2/s1-2n/s,…,lnn1-n/s1-nn/s)+…+bm(lnnm-1/sm-1n/s,lnnm-2/sm-2n/s,…,lnnm-n/sm-nn/s)(5)
式中:b1,b2,b3,…,bn为逻辑回归系数;IA1-1,IA1-2,IA1-3,…,IAm-n为影响因子集,也即各影响因子不同子区间的信息量值;lnn1-1/s1-1n/s,lnn1-2/s1-2n/s,…,lnnm-n/sm-nn/s是利用式(1)计算得到的不同影响因子各个子区间的信息量值。
2 研究区概况
崇义县位于江西省西南边陲,地处113°55′E~114°38′E和25°24′N~25°55′N之间,面积约为2 206 km2,海拔140.0~2 061.3 m,境内地势高低起伏,山脉横纵交错。此外,全区以侵蚀构造中低山和侵蚀构造低山地形为主,少部分为岩溶和侵蚀堆积地形。全县雨量充沛,水资源极为丰富,主要水系有大江、小江及扬眉江等。因处于南岭东西向构造带与诸广山-万洋山南北向构造带复合部位,导致该地区局部滑坡灾害时有发生。
崇义县地质灾害较为发育,类型较全,分布范围广,其主要地质灾害类型为滑坡和不稳定斜坡。通过研究区遥感影像解译及野外走访调查,总共编录了289处滑坡,其分布面积约为6.73 km2,滑坡平均面密度为0.31%,如图2所示。研究区滑坡发育表现为:人口居住密度较大的低山丘陵地区滑坡灾害较为频繁,雨季和暴雨季往往呈现出集中暴发滑坡灾害的趋势。
3 滑坡易发性评价因子体系的建立
3.1 评价单元划分
当前用于滑坡易发性评价的单元主要有:栅格、斜坡、子流域、均一条件及行政区划单元[26]。其中,栅格
和斜坡单元应用得比较广泛。依据山脊山谷线等斜坡单元对真实地貌进行划分,虽然具有明确的地质特征意义,但是实际操作中十分依赖人工操作[27]。而栅格单元能够快速剖分并进行高效率的模型计算,被广泛应用于易发性的研究当中[28]。因此,本文选择栅格作为研究区评价单元,且栅格单元大小为30 m。
3.2 数据来源
本次研究采用的数据包括:① 滑坡灾害点编录数据以及野外调查资料,用于获取滑坡分布图;② 30 m分辨率的数字高程模型,用于提取坡度、地形起伏度等地形因子信息;③ 1∶100 000比例尺的地质图,用于提取地层岩性信息;④ 崇义地区遥感影像,用于提取植被指数(NDVI)和建筑指数(NDBI)等。
3.3 评价因子的选取及相关性分析
在滑坡易发性的预测过程中,对于最适合的环境因子选取尚未达成统一意见,通常考虑地形地貌、水文环境、基础地质和植被覆盖等方面与滑坡关系密切的因子。本文通过分析崇义县滑坡灾害发育特征和常用的环境因子,选取高程、坡度、坡体结构、平面曲率、剖面曲率、地形起伏度、距水系距离、岩性、NDVI、NDBI等因子组成研究区滑坡易发性评价因子体系[29]。根据Jenks自然间断点法将各连续型因子分为6类,各因子子类别频率比和信息量值如表1所列。利用ArcGIS 10.2软件得到各个评价因子的分级图如图3所示。
3.3.1 地形地貌因子和水文环境因子
各环境因子与滑坡之间的相关性主要利用各因子子类别相应的滑坡密度和信息量值来反映,如图4 所示。高程和坡度是影响滑坡的重要因素。由图4(a)和图4(b)可知,滑坡主要发生在高程140~353 m和坡度8.03°~19.96°的区域,其滑坡分布密度分别为0.59%和0.57%。坡体结构的类型也能影响滑坡的发育,主要分为凹形坡、凸形坡、直线形坡和复合形坡,且在复合型和凸型坡中有利于滑坡的出现,如图4(c)所示。平面曲率和剖面曲率反映了地形对地表水流的敛散性和加速作用,当平面曲率在-0.30~0.19、剖面曲率在-0.27~0.79區间时,滑坡有较大概率发生,如图4(d)~(e)所示。而地形起伏度作为一个地区重要的地形属性,其对研究区内滑坡灾害的发生也有着重要的影响,当地形起伏度在0~70之间时,有利于滑坡的发生,如图4(f)所示。
水系指流域内所有河流、湖泊等各种水体组成的水网系统,是诱发滑坡或在滑坡出现之后加剧灾害的重要因素[30-31]。研究区主要的水系包括大江、小江及扬眉江等河流。本文通过ArcGIS软件对DEM数据经过填洼、流向流量提取、栅格河网矢量化处理,得到水系矢量河网,再进行多环缓冲区分析得到距水系距离分布图,如图4(g)所示。当距水系距离在500 m以内时,信息量大于0,表明距离水系越近的区域越容易发生滑坡灾害。
3.3.2 基础地质和地表覆被因子
岩性是滑坡发生的重要内部因素,如图4(h)所示。变质岩岩类、碎屑岩岩类、碳酸盐岩岩类构造较为软弱,其对应的信息量均大于0,有利于滑坡发生。NDVI和NDBI是用来表征地表植被覆盖程度以及地表建筑化程度的相对大小,如图4(i)~(j)所示;当NDVI小于0.345和NDBI大于0.483时,该区域有利于滑坡的发育;而当NDBI小于0.29时,则不利于滑坡的发生。
4 滑坡易发性评价
4.1 信息量模型与逻辑回归模型
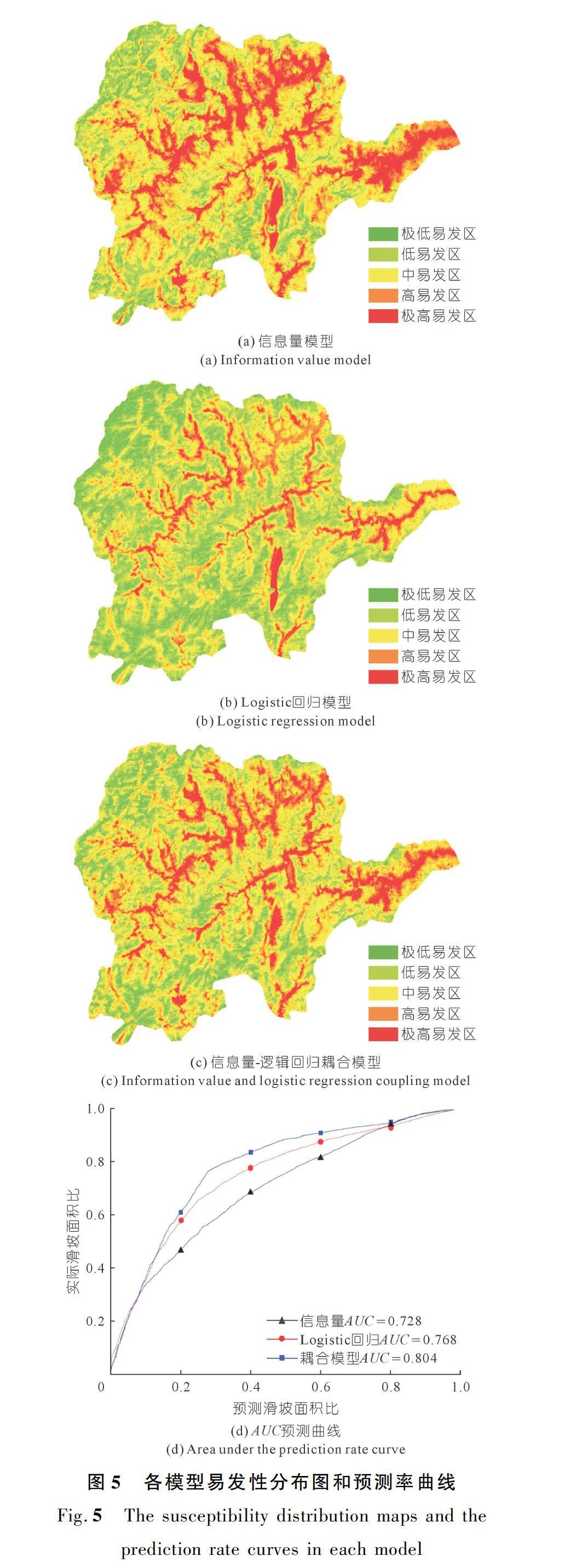
本次研究利用研究区内7 618个已知滑坡栅格和7 618个非滑坡栅格所提取的各因子子区间信息量值,并结合式(2)来获取研究区滑坡易发性。另外,通过Jenks自然间断点法将崇义县滑坡易发性划分为5个等级:极低易发区、低易发区、中易发区、高易发区、极高易发区,最终得到滑坡易发性分级图,如图5(a)所示。
再利用研究区内7 618个滑坡栅格和随机选取的7 618个非滑坡栅格作为Logistic回归模型的数据集。以高程、坡度等10个因子不同子区间的频率比值作为自变量,以滑坡发生与否(标记为1和0) 作为因变量。随后利用统计软件SPSS 24.0进行二元Logistic回归分析,得到各个影响因子的Logistic回归系数值。由表 2可知,各因子显著性检验统计量Sig均小于所设的显著性水平0.05,说明Logistic回归模型具有统计意义。Logistic回归拟合方程如式(6)所示,从方程中可以看出:高程、距水系距离、岩性、NDVI、NDBI等因子对滑坡的发生起主要控制作用。利用ArcGIS10.2获取的研究区滑坡易发性分级图,如图5(b)所示。
LogitP=-3.856+0.594×高程+0.352×坡度+0.391×坡体结构+0.382×平面曲率+0.406×剖面曲率-0.295×地形起伏度+0.531×距水系距离+0.426×岩性+0.544NDVI+0.611NDBI(6)
4.2 信息量-Logistic回归耦合模型
本文将各因子子区间的信息量值和滑坡发生与否(记为1和0)作为逻辑回归模型的输入数据来构建信息量-Logistic回归耦合模型。耦合模型下各个影响因子的Logistic回归系数值如表3所列。结果显示各因子Sig均小于所设的显著性水平0.05,说明耦合模型具有统计意义。上述耦合模型的回归拟合方程如下式(7)所示,从方程中可以看出,高程、距水系距离、NDVI、NDBI等因子对滑坡的发育起主要控制作用。此外,耦合模型的滑坡易发性分级图,如图5(c)所示。将该分级图与历史滑坡灾害点图层进行对比分析,发现耦合模型得出的评估结果与实际情况具有很高的吻合度。
LogitP=-0.014+0.635×高程+0.098×坡度+0.304×坡体结构+0.345×平面曲率+0.289×剖面曲率+0.002×地形起伏度+0.530×距水系距离+0.323×岩性+0.557NDVI+0.728NDBI(7)
4.3 模型精度评估及易发性结果分析
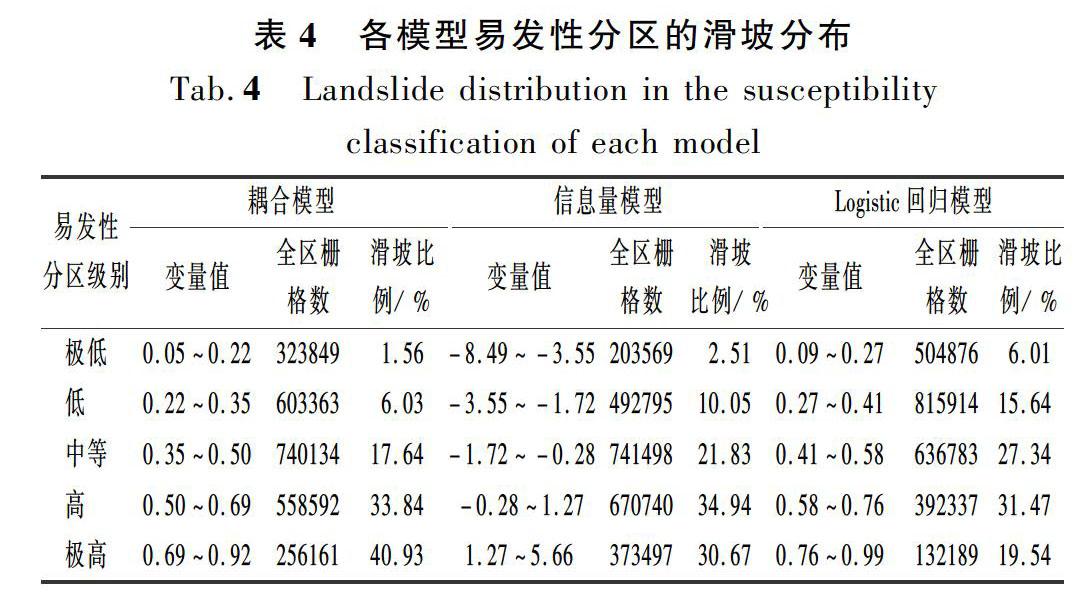
本文采用预测率曲线法对信息量模型、Logistic回归模型和信息量-Logistic回归耦合模型得出的滑坡易发性进行精度评估。预测率曲线能够表示实测数据与拟合数据之间的关系,预测率曲线下的面积AUC越大,说明拟合数据和实测数据越接近,模型的成功率也就越高。从图5(d)中可以看出:耦合模型的成功率(80.4%) 较信息量模型(72.8%)和Logistic回归模型(76.8%)的成功率更高,说明耦合模型具有更好的预测性能。由上述3种模型得到的易发性分级图可知,其滑坡易发性分布规律具有一定相似性。本文通过将滑坡易发性分布图和滑坡灾害点分布图进行叠加分析,结果如下。
(1) 从统计结果表 4可以看出,耦合模型较信息量模型和Logistic回归模型有40.93%的滑坡灾害点落在极高易发区(信息量模型为30.67%,Logistic回归模型为19.54%),其面积占全县总面积11.56%;有33.84%的滑坡灾害点落在高易发区(信息量模型为34.94%,Logistic回归模型为31.47%),其面积占全县总面积22.74%。
(2) 极高易发区和高易发区集中于海拔高程较低、接近水系、碳酸盐岩性地层构造、植被覆盖率低、建筑密集的区域。其中水通过对斜坡进行冲刷、软化以及水压力作用,使岩土体的抗剪强度大大降低,增加了滑坡发生的概率;而碳酸盐岩本身地层构造较为软弱,在降雨、地震等诱发因素下也极易产生滑坡灾害。
(3) 信息量模型的高和极高易发性分区表现得最为分散;逻辑回归模型的高和极高易发性分区则集中分布在水系周围;而耦合模型弥补了上述2种模型各自的局限性,表现出沿着水系的集中趋势同时又呈现出一定的分散性。这个现象也体现出耦合模型较其他2种模型的优越性。
5 结 论
(1) 3种模型都具有良好的预测效果,其中耦合模型的预测性能(80.4%) 较信息量模型(72.8%)、逻辑回归模型(76.8%)更高,其评价结果也更加合理、准确。
(2) 高易發区和极高易发区多集中于海拔高程较低、接近水系、碳酸盐岩性地层构造、植被覆盖率低、建筑密集的区域。各个评价因子中高程、距水系距离、岩性、NDVI、NDBI对滑坡灾害的发生起主要控制作用。
(3) 基于耦合模型所计算得出的易发性分级图与研究区历史滑坡灾害点分布情况较为吻合。34.30%的高和极高易发性研究区内发生了74.77%的滑坡。综上所述,基于耦合模型得出的评价结果能够为崇义县乃至其他地区的滑坡灾害风险评估提供理论指导。
参考文献:
[1] 陈亮青,邹宗兴,苑谊,等.考虑诱发因素影响滞后性的库岸滑坡位移预测[J].人民长江,2018,49(12):60-65.
[2] GUO Z,YIN K,GUI L,et al.Regional rainfall warning system for landslides with creep deformation in Three Gorges using a statistical black box model[J].Scientific Reports,2019,9(1):8962.
[3] HUANG F,YIN K,ZHANG G,et al.Landslide groundwater level time series prediction based on phase space reconstruction and wavelet analysis-support vector machine optimized by PSO algorithm[J].Earth Science-Journal of China University of Geosciences,2015,40(7):1254-1265.
[4] LIU W,LUO X,HUANG F,et al.Uncertainty of the soil-water characteristic curve and its effects on slope seepage and stability analysis under conditions of rainfall using the markov Chain Monte Carlo Method[J].Water,2017,9(10):758.
[5] 鮮木斯艳·阿布迪克依木,何书,基于MIV-BP神经网络的滑坡易发性空间预测[J].人民长江,2019,50(23):140-144.
[6] HUANG F,CAO Z,GUO J,et al.Comparisons of heuristic,general statistical and machine learning models for landslide susceptibility prediction and mapping[J].Catena,2020(191):104580.
[7] ALTHUWAYNEE O F,PRADHAN B,PARK H J,et al.A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping[J].Catena,2014,114(2):21-36.
[8] LI D,HUANG F,YAN L,et al.Landslide susceptibility prediction using particle-swarm-optimized multilayer perceptron:comparisons with multilayer-perceptron-only,BP Neural Network,and information value models[J].Applied Sciences,2019,9(18):3664.
[9] 刘磊,殷坤龙,王佳佳,等.降雨影响下的区域滑坡危险性动态评价研究:以三峡库区万州主城区为例[J].岩石力学与工程学报,2016,35(3):558-569.
[10] 张俊,殷坤龙,王佳佳,等.三峡库区万州区滑坡灾害易发性评价研究[J].岩石力学与工程学报,2016,35(2):284-296.
[11] HUANG F,ZHANG J,ZHOU C,et al.A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction[J].Landslides,2020,17(1):217-229.
[12] HUANG F M,WU P,ZIGGAH Y Y.GPS monitoring landslide deformation signal processing using time-series model[J].International Journal of Signal Processing,Image Processing and Pattern Recognition,2016,9(3):321-332.
[13] 高彩云.基于新型智能算法ELM的滑坡变形位移预测[J].人民长江,2017,48(10):46-49,69.
[14] 张旭,周绍武,龚维强,等.金沙江乌东德库区必油照滑坡稳定性分析[J].人民长江,2019,50(23):124-129.
[15] 许英姿,卢玉南,李东阳,等.基于GIS和信息量模型的广西花岗岩分布区滑坡易发性评价[J].工程地质学报,2016,24(4):693-703.
[16] 张向营,张春山,孟华君,等.基于GIS和信息量模型的京张高铁滑坡易发性评价[J].地质力学学报,2018(1):96-105.
[17] 许冲,戴福初,徐素宁,等.基于逻辑回归模型的汶川地震滑坡危险性评价与检验[J].水文地质工程地质,2013,40(3):98-104.
[18] BAI S B,WANG J,GUO N L,et al.GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area,China[J].Geomorphology,2010(115):23-31.
[19] LEE S,JOONG S W,JEON S,et al.Spatial landslide hazard prediction using rainfall probability and a logistic regression model[J].Math Geosciences,2015(47):565-589.
[20] 段钊,赵法锁,李芳.基于GIS的陕西省滑坡灾害空间分异特征探讨[J].灾害学,2012,27(1):34-37.
[21] 方丹,胡卓玮,王志恒.基于GIS的北川县地震次生滑坡灾害空间预测[J].山地学报,2012,30(2):230-238.
[22] 陶舒,胡德勇,赵文吉,等.基于信息量与逻辑回归模型的次生滑坡灾害敏感性评价:以汶川县北部为例[J].地理研究,2010,29(9):1594-1605.
[23] 高治群,薛传东,尹飞,等.基于GIS的信息量法及其地质灾害易发性评价应用:以滇中晋宁县为例[J].地质与勘探,2010,46(6):1112-1118.
[24] 郭宇,黃健民,陈建新,等.广州市白云区金沙洲地区地质灾害风险区划[J].热带地理,2013,33(6):659-665.
[25] 王进,郭靖,王卫东,等.权重线性组合与逻辑回归模型在滑坡易发性区划中的应用与比较[J].中南大学学报(自然科学版),2012,43(5):1932-1939.
[26] PHAM B T,BUI D T,PRAKASH I,et al.Hybrid integration of multilayer perceptron neural networks and machine learning ensembles for landslide susceptibility sssessment at Himalayan area(India) using GIS[J].Catena,2017(149):52-63.
[27] YAO X,THAM L G,DAI F C,Landslide susceptibility mapping based on support vector machine:a case study on natural slopes of Hong Kong,China[J].Geomorphology,2008,101(4):572-582.
[28] 黄发明,汪洋,吴礼舟,等.基于灰色关联度模型的区域滑坡敏感性评价[J].地球科学,2019,44(2):664-676.
[29] 王世梅,刘佳龙,王力,等.三峡水库库水位升降对谭家河滑坡影响分析[J].人民长江,2015,46(21):83-86.
[30] LI Y,HUANG J,JIANG S H,et al.A web-based gps system for displacement monitoring and failure mechanism analysis of reservoir landslide[J].Scientific Reports,2017,7(1):17171.
[31] HUANG F M,TIAN Y G.WA-VOLTERRA coupling model based on chaos theory for monthly precipitation forecasting[J].Earth Science-Journal of China University of Geosciences,2014,34(9):368-374.
(编辑:胡旭东)
Evaluation of landslide susceptibility based on coupling model of
information value-logistic regression
LI Yijing1,HU Qichao1,LIU Huazan1,DU Zhen1,CHEN Jiawu1,HUANG Jinchang2,HUANG Faming1
(1.School of Civil Engineering and Architecture,Nanchang University,Nanchang 330031,China; 2.Hangzhou Weiye Construction Group Co.,Ltd,Hangzhou 310003,China)
Abstract:
The prediction of regional landslide susceptibility can accurately reflect the spatial probability characteristics of landslide distribution in a specific research area.In this paper,the coupling model based on information value model and logistic regression model was used to predict the landslide susceptibility in Chongyi County,Jiangxi Province.First of all,10 influence factors including elevation,slope gradient,slope structure,plane curvature,profile curvature,topographic relief,distance from water system,lithology,Normalized Difference Vegetation Index(NDVI) and Normalized Difference Built-up Index(NDBI)were selected.Then,the logistic regression model was constructed by using the information value of each factor.In addition,the information value model and the logistic regression model were used as comparison models to explore the evaluation results of the landslide susceptibility of the three models.The results showed that the coupling model had the best prediction performance(AUC = 80.4%),and the rest were logistic regression model(76.8%) and information model(72.8%);the distribution rules of landslide susceptibility predicted by each model had certain similarities,namely most of the landslides occurred in areas of low elevations,close to water systems,carbonate lithologic strata,low vegetation coverage and dense buildings.
Key words:
landslide susceptibility prediction;influence factor;information value model;logistic regression model;information value-logistic regression coupling model
猜你喜欢
中国应急管理科学(2022年2期)2022-05-23
中国药学药品知识仓库(2022年9期)2022-05-23
科学与生活(2021年22期)2021-12-27
西部资源(2019年2期)2019-11-12
智富时代(2019年3期)2019-04-30
智富时代(2019年3期)2019-04-30
中国电子报(2019年90期)2019-02-22
计算机辅助工程(2018年3期)2018-09-17
家庭医药(2018年4期)2018-04-24
新课程·下旬(2017年7期)2017-08-14
