
分布式云计算架构在区域医疗大数据分析中的优化研究
2021-08-24 01:46颜冰冰
智慧健康 2021年19期
颜冰冰
(苏州市立医院北区 信息科,江苏 苏州 215000)
0 引言
在医疗信息化不断深入的背景之下,原本较为单一的数据信息也逐步变得更为多元化,这也给相关技术人员的处理利用提出了更高的要求,因此做好区域医疗数据信息的整合工作就显得尤为重要。这一举措不单单能够有效推动医疗数据更为标准化与规范化,也能够实现单一数据的有机融合以及从多个维度来进行分析汇总,进而为相关工作提供数据上的支持。
1 分布式云计算在医疗大数据分析中的架构
1.1 整合架构的设计
分布式云计算整体架构如图1所示。
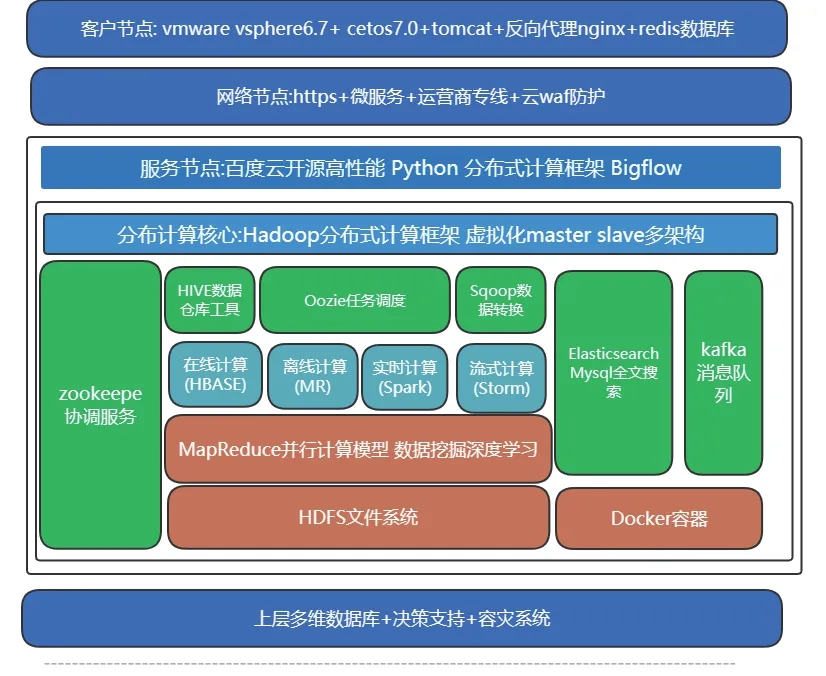
图1 整体架构设计示意图
客户节点包含了主流配置的两台物理服务器,并对其进行了内存容量的提升,医疗终端节点中的数据量分别由redis数据库、Tomcat服务、Nginx反向代理服务进行储存或利用,被架设于边界防火墙之中,所使用的带宽都不低于100M。每个医疗终端节点都和百度云分布式平台中的服务节点相连接,不同节点之间能够智能协同,且每个节点所采取的代码相同,能够执行在不同的引擎之中[1]。通过这一方式,无需明确Bigflow的实际计算与运行部位,只需要按照单机程序的编写来获取独特的逻辑,就会让Bigflow将这些计算分发到相应的执行引擎之上执行。Bigflow的目标是为了使分布式程序更简单,高效,维护更容易,迁移成本更小,进而实现分布式从架构到代码的环节尽可能精简的目的。在每个服务节点之间会按照线路建议申请电信运营商级别的CN2线路,以此来保障网络性能高速且稳定,同时实现最短最优通讯,具体如图2所示。
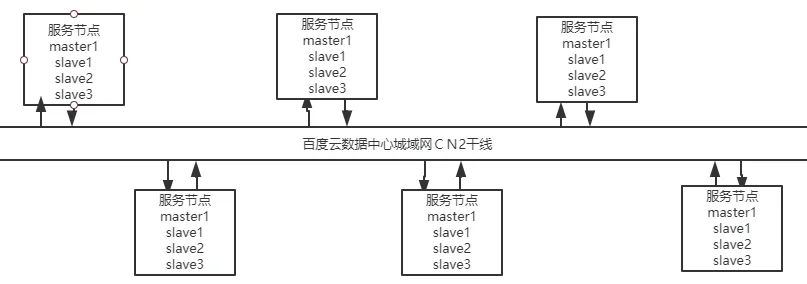
图2 百度云数据中心城域网CN2干线
分布式计算核心节点由master和多个slave虚拟化服务器单元组成,单元操作系统Cetos7.0.Hadoop+HBase+Spark+Hive为主要组件环境搭建,并由keepalived组件协调各个核心节点做主备切换及负载均衡调优,其中最主要计算组件单元为MapReduce,能够分布式并行并设计出计算编程模型。
1.2 分布式日志审计系统
分布式日志审计系统主要是为了让医疗大数据在处理各类信息时能够更为顺畅,通过该系统的应用,可以实现日志分析与处理这一根本目的。分布式日志主要包含了Web应用访问日志、系统日志等,可以有效对日志中所存在的攻击行为进行精准定位并分类,这样一来安全管理人员以及运维工作人员就能够收获到加固应用及事后追溯的关键依据。在进行分析时会出现数量众多的日志,医疗云计算就会将其储存至相应的服务器之中,并为其添加一定的权限,只有已经授权的用户才能够进行访问,有效防止隐私数据泄露这类现象的出现。分布式日志审计系统主要包含了采集层、计算层、汇聚层、数据可视化以及数据存储层,日志的采集与分类具体流程如下:通过syslog来分布式收集海量日志,并将其传输到flume-NG层,以此来统一分发日志[2]。当flume采集系统成功采集数据信息之后,就会将其汇聚到kafka层,并对其进行队列化处理,让日志数据信息在传输的过程之中更为稳定。接着利用分布式计算集群strom来全面分析与处理日志,定位存在着跨站校本(XSS)、暴力破解登录、sql注入、目录遍历这类攻击行为的日志,并统计、储存、预警、可视化结果。利用RESTful API来部署syslog,从而快速下载配置文件,为各类服务的提供奠定基础。通过SSL/TLS协议来完成对数据信息的加密,以此来确保数据信息具备较强的机密性以及完整性。
1.3 分布式入侵检测
入侵检测主要包含了主机层入侵检测(HIDS)、物理层入侵检测以及网络层入侵检测(NIDS)。在传统设备之中,要想完成对IDS的部署,必须依赖交换机所提供的镜像流量,如若用户数量较多,那么就要保证镜像流量分属于不同的端口。在医疗大数据云计算之中,能够通过各类软件的应用来上移控制平面,将安全策略自动派发至子系统,通过SDN技术来完成流量调度,利用SDN控制器来将FLOW_MOD指令下发给Open vSwitch这类网络设备,这样一来就能够有效控制匹配策略的相关流量[3]。而要想在私有性较高的云计算之中完成HIDS,就必须部署agent来全方位监控云主机,有效识别、记录并预警主机用户的可疑行为、基线安全以及系统文件的完整性。
1.4 分布式应用防火墙
通过反向搭建这一手段能够有效部署分布式应用防火墙,而要想部署反向代理vWAF,主要采取了以下几种方式:第一,利用SDN控制器来将FLOW_MOD指令下发,并把Web服务器的HTTP在虚拟网关之中完成与交换机端口的流量定向,这样一来就能够将vWAF作为关键端口。因为一般是将Web应用服务器地址作为HTTP流量目的IP,但反向代理vWAF并不会对这类流量进行处理,所以必须要对目的地址进行重新定向,利用iptables来转发相关流量,这样才能够让分布式应用防火墙的作用得以充分的发挥[4]。第二,利用nginx来反向代理分布式应用,让反向代理服务器能够收获相应的流量,这样一来就能够实现上佳的安全防护效果。Web应用会将nginx作为对外发布的主要途径,通过在nginx层部署防护引擎和安全防护规则,可采用Modsecurity作为vWAF的防护引擎,并部署OWASP开源防护规则,这样的部署方式能够将nginx层的应用访问日志通过agent传输至分布式日志审计系统中对日志进行分析[5]。
1.5 身份认证
Keystone作为openstack中的安全认证模块,通过API实现身份认证、服务规则和服务令牌等功能。在f版本之前,openstack只能依赖UUID生成令牌ID,生成的令牌保存在Keystone的后台数据库中,并发布到客户端。在客户机拥有ID之后,Keystone将验证请求的合法性。这种方式可能导致请求并发,从而使Keystone成为性能的瓶颈[6]。在f版本之后,在密钥石中引入了PKI机制。通过将CA的公钥证书和用户签名的公钥证书存储在服务器上,可以对令牌进行本地验证,可以有效解决密钥问题,同时只要用户不丢失私钥,其他用户就无法窃取和冒充合法用户,大大提高了系统的安全性openstack的整体安全性。为了在医学云中实现AAA认证,我们可以使用轻量级目录访问协议(LDAP协议)结合Keystone集成,通过Keystone的LDAP身份驱动程序使用安装的LDAP服务器。Keystone可以从第三方LDAP服务器获取统一管理用户,完成open stack的操作。Keystone与tenant、US-Er、role和其他概念兼容。通过LDAP服务对账户进行验证,实现企业和组织内部的统一认证[7]。
2 分布式云计算架构优化方式
结合上文可知,要想对分布式云计算架构进行优化,最为关键的便是改善MapReduce组件,具体流程如图3所示。
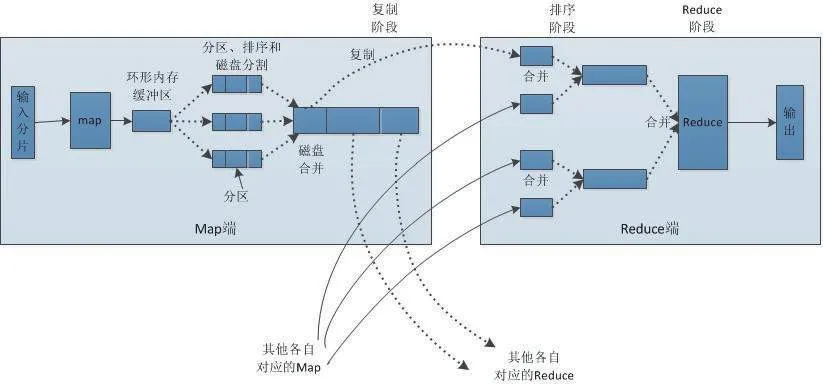
图3 MapReduce组件优化流程
具体而言,Mapeduce组件优化主要包含了数据输入问题、Map阶段、Reduce阶段、ID传输问题以及数据倾斜问题这几个环节,其中数据输入问题主要是进行小文件的合并,并让MAP任务速度得以加快,具体做法是将Combine Text ImputFornat作为主要输入;Map阶段主要是对Spill的次数进行减少,以此来实现磁盘IO降低的目的,具体做法是调整io.sort.factor的参数,并让Merge的文件数目得以增大;Reduce阶段主要是适量设定Map与Reduce的数值,具体做法是让Map与Reduce能够共存,并对slovstart.completedmaps的参数进行调整;IO传输问题主要是为了完成smappy与LZO压缩编码器的安装,具体做法是使用SequenceFlie这类二进制文件;数据倾斜问题主要是为了实现抽样和范围分区,具体做法是结合实际情况来自定义分区[8]。
在完成优化之后,计算机的性能也出现了一定的变化,主要体现在数据频率倾斜在某一个区域的数据量要远远大于其他区域,而数据大小倾斜在某一个区域的大小远远大于平均值[9]。
3 优化结果测试分析
针对优化后的分布式云计算架构主要是对其进行压力测试,所使用的软件为http_load为轻量级高效测试工具,以下为操作系统安装软件:
#tar zxvf http_load-18mar2018.tar.gz
#cd http_load-18mar2018
#make &&make install
测试用法命令为:
http_load-p 并发进程数-s时间URL文件
[root@localhost http-load]# http_loadp30-s10 url.txt
21 fetches,30 max parallel,907207 bytes,in 10.0001 seconds
43200.3 mean bytes/connection
2.09998 fetches/sec,90720 bytes/sec
msecs/connect:15.2955mean,17.253max,13.701min
msecs/first-response:968.356mean,3807.22max,42.817min
HTTP response codes:
code 200——21
从中能够看出测试中共进行了864次请求,最大的并发进程数是921,总传输58647207bytes,运行22.0001s。平均每次请求传输数据量863210.3,实际就等于总传输/请求次数,每秒响应请求数为12.09998,每秒传递数据为270720,连接的平均时间为1.2955ms,最大的响应时间为17.253ms,最小的响应时间为19.701ms,响应的平均时间为968.356ms,最大的响应时间为3807.22ms,最小的响应时间49.817ms,最后服务器会将各类状态码数量正确返回,此处全部是200正常返回(服务器撑不住时会有502返回)[10]。
4 结语
综上所述,分布式云计算架构在区域医疗大数据分析中有着至关重要的作用,不但能够提升分析质量及效率,还能够有效保障分析结果的准确性。通过以上各流程调试以及优化完成分布式计算应用平台的建设,旨在为医疗大数据技术的普及与推广提供理论上的支持,进而促进医疗大数据在不断扩展和复杂的环境中得以更深的应用和改进。
猜你喜欢
电气技术(2022年8期)2022-08-20
华人时刊(2021年13期)2021-11-27
今日农业(2021年17期)2021-11-26
军民两用技术与产品(2021年5期)2021-07-28
汽车工程(2021年12期)2021-03-08
诗选刊(2020年12期)2020-12-03
软件(2020年3期)2020-04-20
科技传播(2019年23期)2020-01-18
当代陕西(2019年16期)2019-09-25
思维与智慧·上半月(2018年10期)2018-11-30
