
一种加权图卷积神经网络的新浪微博谣言检测方法
2021-08-24 06:53王昕岩宋玉蓉
小型微型计算机系统 2021年8期
王昕岩,宋玉蓉,宋 波
1(南京邮电大学 自动化学院、人工智能学院,南京 210023)
2(南京邮电大学 现代邮政学院,南京 210003)
1 引 言
谣言是在人和人之间传播的,含有公众关心信息的一种特殊陈述,而其真实性不能及时得到证明或是无法证明[1],往往会带来恶劣的影响.例如新冠肺炎期间,美国总统特朗普在得知消毒剂能够在一分钟之内杀死病毒后,呼吁给新冠病毒患者直接注射消毒剂,或者用强光照射,以起到杀死病毒的作用.据美国疾控中心报告显示,家用清洁剂产品中毒的数量在几周内都在上升.在人们的日常生活中,这类误导性的谣言比比皆是,因此为了避免谣言可能造成的伤害,采取谣言检测的措施是十分必要的.
谣言能够在社会中快速而广泛地传播,与社交媒体的快速发展是密切相关的.社交媒体在提高人们信息获取效率的同时,也产生了许多与真实信息相背的谣言信息[2].由于每个普通人都可以成为信息的发布源,就会造成信息质量的良莠不齐,不可避免地会有不法分子为了达到目的恶意地发布谣言信息误导民众,使其做出符合谣言散布者期望的举动,影响了社会的稳定.近年来,社交媒体的谣言治理已经成为热门研究课题,引起了国内外学者的广泛关注.对社交媒体的谣言检测任务,通过收集与事件相关的各种信息,自动地完成检测任务来判断被检测事件的真伪.对谣言事件的自动检测方法,一方面减轻了人工辟谣的资源消耗,另一方面能更快地检测出流散的谣言,从而能够营造积极健康的网络环境,维护社会的稳定[3].
目前针对社交媒体的谣言检测方法,如传统的机器学习方法,以及深度学习方法包括卷积神经网络(Convolutional Neural Network,CNN)[4]、循环神经网络(Recurrent Neural Network,RNN)[5]等,对事件的学习只是将这些事件看作成独立的个体,平等地学习事件的特征.然而在社交媒体中,事件之间的关系并不是独立的,而是具有拓扑关系的.社交媒体中的每个事件和与该事件有关的用户都存在着联系,包括发布、评论、转发等,并且这些用户之间的交互关系,也是与这些用户有关的事件之间关系的体现.只考虑每个事件本身的特征而忽略事件之间的联系,会对检测效果造成影响.因此有学者考虑了事件之间的联系,提出使用图网络模型来进行谣言检测,但是他们忽略了事件之间联系的紧密程度,也会对检测效果造成一定的影响.在社交网络中,事件之间的联系具有异质性,其紧密程度存在着差异.谣言事件往往具有鼓动性,这是由于大部分的谣言事件的发布者在发布谣言时,擅长使用一些煽动性的语句来激发人们的情绪.往往对这些事件进行评论和转发的用户,更加容易受到这些刺激性语句的蛊惑,也会受到其他谣言事件中这类语句的鼓动.与非谣言相比,谣言的发布者更加希望所发布的谣言信息能够有更多转发和评论,来引起人们的关注.于是许多谣言发布者为了达到这一目的,会有意识地组织用户进行转发、评论来提高事件的热度,而这些用户也更易受到其他谣言发布者的利用.因此本文考虑事件之间相同数量的评论者或转发者,来确定事件之间联系的紧密程度.
为了充分考虑事件之间的联系及其异质性,本文提出了一种基于加权图卷积神经网络(Weighted-Graph Convolutional Network,W-GCN)模型的谣言检测方法.该方法以事件作为节点,以事件之间是否有联系构建连边并根据事件之间联系的紧密程度,赋予连边不同的权重.接着通过BERT(Bidirectional Encoder Representation from Transformers)模型和CNN模型对事件的文本提取特征,并将该特征作为W-GCN模型中节点的特征向量,来完成模型的训练,从而完成对社交媒体中事件的谣言检测任务.考虑到新浪微博是一种基于用户关系信息分享、传播以及获取的实时社交媒体,是中国最大的社交媒体平台,因此本文选择新浪微博作为研究对象来完成谣言检测的任务.实验结果表明,与传统的机器学习模型以及GRU-2[5]、PPC-RNN+CNN[6]等深度学习模型相比,本文提出的W-GCN模型能更有效地完成新浪微博中谣言的检测任务.并且与这些方法相比,本文方法同样能更加有效地完成新浪微博中谣言的早期检测任务.
本文剩余章节安排如下:第2节介绍社交媒体谣言检测的相关研究工作;第3节介绍本文提出的新的谣言检测模型;第4节通过实验及分析,验证本文提出的新的谣言检测方法的有效性;第5节为结束语.
2 相关工作
目前国内外对于谣言检测的工作主要分为两个方面,一个是使用传统的机器学习方法,另一个是使用深度学习的方法.使用传统的机器学习方法大多是通过选取人工特征,主要包括文本特征、用户特征以及传播特征,并使用包括贝叶斯[7]、支持向量机(Support Vector Machine,SVM)、决策树[8]等分类器来对事件进行学习分类.Qazvinian等[9]使用了贝叶斯分类器,提取了用户行为特征及文本特征等特征.Yang等[10]使用了SVM分类器,提取了发布微博的客户端及其所在的地理位置等特征.Liang等[11]提取了质疑文本特征以及用户行为等特征.Yang等[12]提取了热门话题等特征.Wu等[13]提出了基于图核的混合SVM分类器,提取了语义特征以及高阶传播特征.Ma等[14]提出了传播树模型来获取事件的特征表示.
近年来随着深度学习的快速发展,深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)等在计算机视觉[15]等领域上的应用得到了快速发展,使用深度学习模型来解决自然语言处理(Natural Language Processing,NLP)任务[16],逐步取得了显著的成果.并且与传统的机器学习模型相比,深度学习模型对人工特征的依赖较小.因此在NLP任务中,使用深度学习模型可以减少设计特征带来的人力、物力的消耗,并能提高模型的鲁棒性.Ma等[5]首次提出将深度学习模型RNN应用于社交媒体的谣言检测,首先通过TF-IDF(Term Frequency-Inverse Document Frequency)算法来获取时间段内的微博文本向量,接着通过RNN模型的学习,最后获取文本向量的特征表示.Yu等[17]使用生成句向量的方法来获取微博文本向量,再用CNN模型来学习获取文本向量的特征表示.Liao等[18]提取文本特征和用户局部特征,使用GRU(Gated Recurrent Unit)网络和注意力机制来获取微博事件的特征表示.Hu等[19]使用图卷积神经网络(Graph Convolutional Network,GCN)模型,根据新闻的相似性构建连边,并提取历史信用特征对新闻进行分类.Tian[20]等人使用GCN模型,根据谣言传播的方向性构建连边对事件进行分类.虽然这些方法在分类效果上比传统的机器学习方法更加出色,但是它们没有考虑事件之间的联系或事件之间联系的异质性,对谣言检测的效果造成了一定的影响.
3 模型方法
3.1 问题描述
对新浪微博平台的谣言检测任务,实际上是一个对事件进行二分类的问题.对于给定的事件组E={e1;e2;e3;e4;…;ei;…;en}和标签组L={l1;l2;l3;l4;…;li;…;ln}.在事件组E中,ei表示第i个事件,包括所有与这个事件相关的微博原文以及转发、评论等信息,n表示事件总数;在标签组L中,li表示第i个事件的标签,分为谣言标签和非谣言标签.在新浪微博平台的谣言检测任务中,首先将事件组E分为事件训练集Etrain和事件测试集Etest,将标签组分为训练集标签Ltrain和测试集标签Ltest.让模型对事件训练集Etrain以及它们对应的训练集标签Ltrain进行学习,构建出一个以事件信息ei作为输入,分类标签li作为输出的映射模型.接着将事件测试集Etest输入该模型,输出对应的预测标签组Lpred.最后根据预测标签组Lpred与实际标签组Ltest的相符程度,来衡量该谣言检测模型的检测效果.
3.2 模型介绍
1)BERT预训练模型
自然语言处理(NLP)任务一般分为上游任务和下游任务.上游任务主要对数据进行预处理,将文本数据转化为向量表示.下游任务主要对转化后的向量进行操作.上游任务使用的模型主要包括Word2Vec[21]、ELMo[22]等.Word2Vec模型将单词通过高维空间映射成词向量,可以表征现实生活中词语之间的关系.但是通过Word2Vec模型,每个单词与一个固定的词向量相对应,使得每个单词无法理解上下文的语义.ELMo模型通过双向语言模型,并根据具体的输入来得到上下文依赖的词向量表示,将NLP的一部分下游任务转移到了上游任务中,增强了向量的特征表示能力.但是该模型的工作效率低,并且只能将数据用词向量来表示.BERT模型[23]作为一个语言表征模型,由谷歌团队使用双向编码操作,通过大量数据和多层模型训练而成.该模型的并行性好,效率高.并且该模型可以将数据转化为维度具有一致性的句向量,因此本文采用BERT模型对新浪微博中的文本数据进行预处理操作.
2)卷积神经网络(CNN)模型
卷积神经网络(CNN)模型[24]可以使用通过BERT模型转化后的向量,来作为模型的输入,进而完成模型的训练,如图1所示.CNN模型由4部分构成:输入层(Input Layer)、卷积层(Convolution Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer).

图1 卷积神经网络(CNN)结构图
CNN模型将事件ei转化后的向量vi作为输入,通过卷积层(Convolution Layer)选取宽度与向量vi维度等长的卷积核,使该卷积核始终保持在竖直方向滑动,来完成对向量的卷积操作,继而得到与卷积核数量相同的特征向量ci.接着通过池化层(Pooling Layer)对特征向量ci进行最大池化(Max-Pooling)操作,提取局部接受域中向量的最大值,得到特征向量pi.最后通过全连接层,将最大池化操作后提取的特征向量pi,在全连接层中与分类标签进行全连接(Fully Connected)操作,得到该事件ei的预测标签li,最终完成谣言的检测任务.本文提出的模型将最大池化操作后的特征向量pi作为事件ei的特征向量.
3)图卷积神经网络(GCN)
图卷积神经网络[25](GCN)是一种多层神经网络,可以通过图中的节点和连边信息直接对图中的节点进行端对端的学习并完成分类任务.给定一个图G=(N,E),其中N表示节点,E表示连边.GCN模型的输入包括特征矩阵X∈Rn×m,邻接矩阵A∈Rn×n以及标签组L∈Rn×2.其中特征矩阵X包括图中的所有节点n以及每个节点特征向量的维数m.邻接矩阵A表示图中各节点之间的连边关系.如果节点ni和节点nj之间有连边,则Aij=α,其中α为该连边的权重,否则Aij=0.GCN模型通过节点的相邻节点信息来更新该节点的隐层信息,每一层只捕获该节点的最近邻节点的信息.当GCN模型有多个层数时,模型会整合更多的邻居节点信息.因此GCN模型中的第i个隐藏层的特征矩阵Hi,如式(1)所示.
Hi=f(Hi-1,A)
(1)
其中,H0=X,f是传播函数.
GCN模型的第i个隐藏层的特征矩阵Hi,与特征矩阵Hi∈Rn×m相对应,代表这个节点在该层的特征表示.第i个隐藏层的特征矩阵Hi中节点的特征被聚合后再通过传播函数f,得到该节点在下个隐藏层中的特征表示.对于只含有一个隐藏层的GCN模型,节点的k维特征矩阵H1∈Rn×k如式(2)所示.
(2)
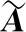
(3)
对于多层GCN模型,下一个隐藏层的特征矩阵Hi+1可以通过上一个隐藏层的特征矩阵Hi及权重矩阵Wi,如式(4)所示.
(4)
3.3 加权图卷积神经网络(W-GCN)模型
1)W-GCN模型介绍
本文在考虑事件之间联系的基础上,充分考虑了事件之间联系的异质性,即事件之间联系的紧密程度,赋予了GCN模型中连边的权重,提出了一种新型社交网络的谣言检测方法.该方法对微博事件中的用户信息以及文本信息进行提取处理.对于用户信息,通过考虑用户与事件之间的评论与转发行为来确定事件与事件之间是否有联系关系,并根据事件之间相同的评论者或转发者数量来确定事件之间联系的紧密程度.将新浪微博中的事件作为节点,事件之间的联系作为连边,联系的紧密程度作为连边的权重,从而搭建了一个加权图卷积神经网络(W-GCN)模型,如图2所示.对于微博事件中的文本信息,首先通过BERT模型将文本信息进行预处理操作,将文本信息转化成维数为768的向量表示,紧接着使用CNN模型对转化后向量进行特征提取.最后将CNN模型中最大池化(Max-Pooling)操作后得到的特征输入到W-GCN模型中,最后模型学习得到事件的隐层表达,进而实现对事件的分类操作,最终完成新浪微博中谣言的检测任务.
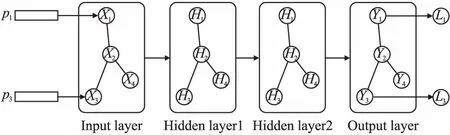
图2 加权图卷积神经网络(W-GCN)结构图
本文提出的加权图卷积神经网络模型W-GCN的输入包括两个部分:由所有事件的特征向量组成的节点的特征矩阵X,以及根据事件之间的联系及其紧密程度构建的W-GCN中的邻接矩阵A.
2)W-GCN模型的节点特征矩阵
考虑到GCN中,每个节点的特征向量需为固定的长度.仅使用预训练模型对一个微博事件的所有文本信息进行预处理转化为向量,无疑会破坏文本的结构特征,会对检测效果造成巨大影响.经过实验,仅通过预训练模型对一个微博事件的所有文本信息进行预处理,不具有很好的分类特征.考虑到现有的深度学习模型中,CNN模型在经过最大池化(Max-Pooling)操作后得到的特征向量,维度相同并且维数较少,可以最大程度地保留文本的结构特征,因此本文使用卷积神经网络模型(CNN)对事件文本进行特征提取.对于图网络模型中作为节点ni的事件ei,首先将事件ei的文本信息,逐条通过BERT模型转化为向量表示,并作为CNN模型的输入.经过CNN的卷积和池化操作后得到特征pi,将其作为W-GCN模型中节点的特征向量xi.
3)W-GCN模型的邻接矩阵
W-GCN模型中节点ni和节点nj之间的连边,由对应的事件ei和事件ej之间的联系来确定.对于事件ei和事件ej,根据这两个事件之间是否有相同的评论者或转发者来确定两个事件之间是否存在联系,继而决定图网络模型中节点ni和节点nj之间是否存在连边.节点之间的连边通过邻接矩阵A来表示,为了简便起见,本文不考虑事件传播的方向,即不考虑连边的有向性.如果事件ei和事件ej之间没有相同的评论者或转发者,那么这两个事件之间不构成传播关系,即事件ei和事件ej之间不存在联系,定义节点ni和节点nj之间不存在连边,令Aij=0;如果事件ei和事件ej之间含有相同的评论者或转发者,那么事件ei和事件ej之间就可能存在传播关系,对此定义节点ni和节点nj之间存在连边,那么Aij的值至少为1.再通过考虑事件ei和事件ej之间联系的紧密程度,即事件ei和事件ej之间相同的评论者或转发者数量α,给Aij赋予不同的值来定义节点ni和节点nj之间连边的权重,即:
4 实验结果及分析
4.1 参数及评价指标
1)实验数据集及模型参数设置
本文选用的数据集是Ma等[5]使用的用于新浪微博平台的谣言检测数据集.该数据集包括4664个事件,每个事件对应的标签,事件信息包括微博用户信息、文本信息、时间等信息,如表1所示.
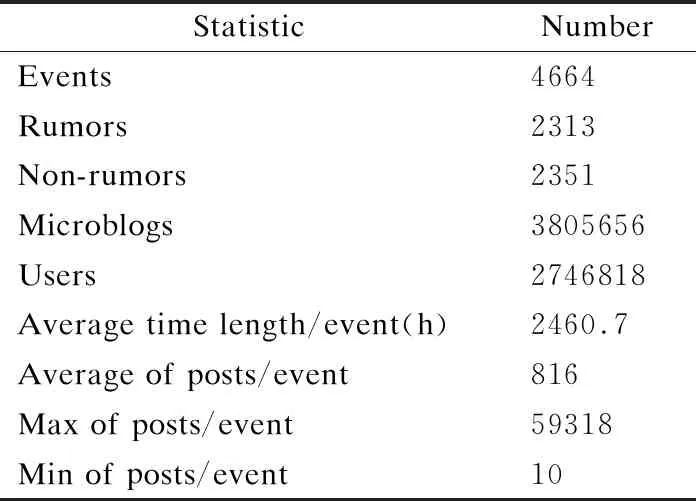
表1 数据集参数表
在模型的参数设置上,本文将该数据集4664个事件中的85%作为训练集,15%作为测试集,并完成了5次5折交叉验证.对BERT模型,设置向量的维度为768;对卷积神经网络(CNN)模型,设置卷积核的宽度设为3,长度为768,卷积核数量为300,dropout为0.5.对加权图卷积神经网络(W-GCN)模型,沿用Kipf等[25]的设置,第一个隐藏层单元数为16,第二个隐藏层单元数为7,dropout设置为0.5.模型在学习时,在每个Epoch中迭代训练所有的训练集事件,直到模型收敛或者Epoch数量达到最大值为止.此外,本文选取了以小时作为单位的9个时间点,分别为1,3,6,12,24,36,48,72,96.从事件中微博原文发出的时间算起,在以上的时间节点内,分别通过W-GCN模型来完成新浪微博的谣言检测任务,来检验该模型在谣言早期检测方面的有效性.
2)实验评估参数
谣言检测任务实际上是一个文本分类的子任务,是一种二分类的文本分类问题,输出的结果为谣言及非谣言的概率,选取概率较大的一类作为模型预测的类别.模型的预测类别与实际类别的分类依据,如表2所示.

表2 分类依据
本文选取了评价分类器优良最常见的4个指标:正确率(Accuracy,Acc)、精确率(Precision,Pre)、召回率(Recall,Rec)、F1值(F1-Measure,F1),来评价本文提出的W-GCN模型的有效性.正确率表示被模型正确分类的事件数量与事件总数的比值,如式(5)所示;精确率表示被模型正确分类为谣言(或非谣言)的事件数量与被分类为谣言(或非谣言)的事件总数的比值,如式(6)所示;召回率表示被模型正确分类为谣言(或非谣言)的事件数量与实际为谣言(或非谣言)的事件总数的比值,如式(7)所示;F1值表示准确率和召回率加权调和平均,是对准确率和召回率的综合考虑,如式(8)所示.
(5)
(6)
(7)
(8)
4.2 实验对比模型
本文将本文方法与同样使用该数据集的基准方法进行对比,所选取的基准方法如下:
1)DT-Rank 模型[26].该模型通过搜索微博文本中有争议的事实性声明,将它们按相似度进行聚类并根据统计特征,使用决策树的排名方法对聚类结果进行排名,来完成微博事件的分类任务.
2)SVM-TS 模型[27].该模型通过使用事件的时间序列来得到随时间变化的事件特征,使用线性SVM分类模型来完成微博事件的分类任务.
3)GRU-2模型[5].该模型基于树结构递归神经网络,捕捉相关帖子随时间变化的上下文信息,使用GRU模型通过传播结构学习事件特征,来完成微博事件的分类任务.
4)PPC_RNN+CNN模型[6].该模型根据事件的传播路径,将循环神经网络(RNN)模型与卷积神经网络(CNN)模型进行模型融合,使用融合后的模型学习事件特征,来完成微博事件的分类任务.
4.3 实验结果
1)谣言检测效果对比
由于GCN的特性,本文在具体实验时,对事件的训练集Etrain只将其中的150个微博事件的标签设置为已知标签,实验结果如表3所示.表格中,第1列为所选取的基准方法的模型及本文的模型,从上至下分别为:DT-Rank,SVM-TS,GRU-2,PPC_RNN+CNN和W-GCN模型;第2列为事件的类别,其中R表示谣言(Rumor),N表示非谣言(Non-rumor);第3列为正确率;第4列为精确率;第5列为召回率;第6列为F1值.
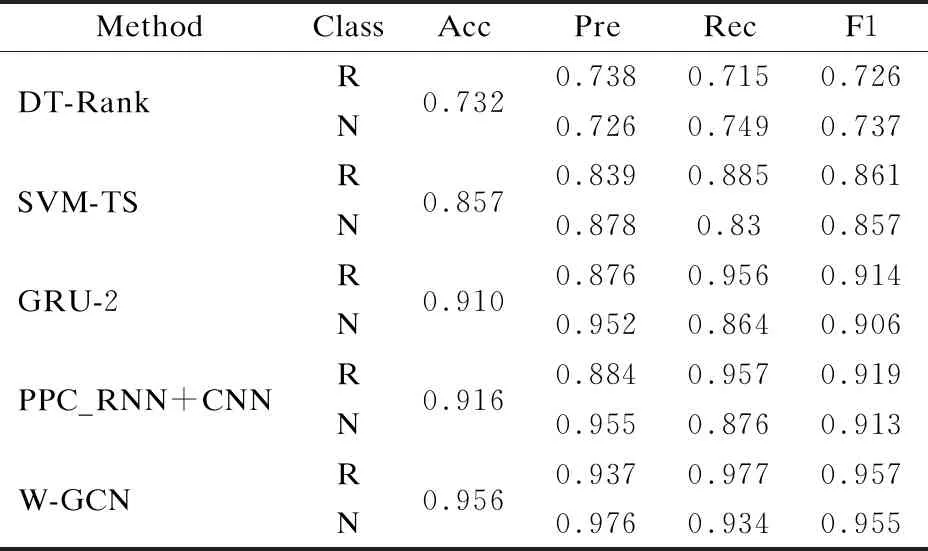
表3 谣言检测结果
从结果中可以看到在基准方法中,传统的机器学习方法中SVM-TS模型的检测效果最好,可以达到0.857的正确率;深度学习方法中PPC_RNN+CNN模型的检测效果最好,可以达到0.916的正确率,可见在谣言检测任务中,使用深度学习的模型可以取得比传统的机器学习方法更加显著的效果.而本文提出的W-GCN模型在检测结果上,正确率达到了0.956,且各项评估指标均优于上述基准方法.而本文在谣言检测的评估指标中,召回率可以达到0.977,表明本文方法对谣言事件有更高的敏感性.因此本文模型在谣言检测的任务上,降低了谣言事件的误判率,能够尽可能多地识别出可能的谣言事件.模型的谣言检测评估指标中的召回率数值更高,意味着更多的谣言事件被筛选出来,能够更大程度地识别出社交网络中潜藏的谣言事件,来减少潜藏谣言事件带来的不利影响,这对社交媒体是十分必要的.综上所述,本文方法在对新浪微博中的谣言检测任务中表现出了更好的检测效果.
与此同时,由于社交媒体信息量的快速增长,对社交媒体中的事件予以谣言或非谣言的标签,往往需要花费大量的时间与精力.因此社交媒体中的事件,拥有标签的事件大多数是已经过时的事件,只有极少部分的事件是较新的事件.因此在对新浪微博的谣言检测任务中,传统的机器学习方法和深度学习方法包括CNN、RNN等在事件标签数量不足的情况下,检测效果会大幅下降,泛化能力较弱.本文提出的模型能够在标签数量有限的情况下,达到同样的检测效果.综上所述,与现有的谣言检测方法相比,本文提出的模型在新浪微博的谣言检测任务中具有更好的实用性.
2)5折交叉验证结果
本文使用5次5折交叉验证,进一步验证本文模型的谣言检测效果.在对数据集的划分中,本文将数据集中的85%划分为训练集,15%划分为测试集.在交叉验证环节中,本文将训练集的数据平均分成5份,每次验证实验只取其中的1份,并将其作为测试集,其余4份作为训练集,通过W-GCN模型来得到这份数据的谣言检测结果,并记录各项评估指标.将该过程重复进行5次,最终得到所有作为本文训练集数据的检测结果,并记录各项评估指标,结果如表4所示.

表4 5折交叉验证结果
结果显示,5次5折的交叉验证结果中,正确率最大值为0.966,最小值为0.942,相差2.4%,正确率的平均值为0.952.本文测试集实验结果的正确率高于这5次交叉验证结果的最小值,低于这5次交叉验证结果的最大值,略高于这5次交叉验证结果的平均值.由此可见本文模型在新浪微博的谣言检测任务中具有较强的泛化能力.
3)早期谣言检测效果对比
本文在谣言的早期检测方面与其他基准方法进行了对比,结果如图3所示.
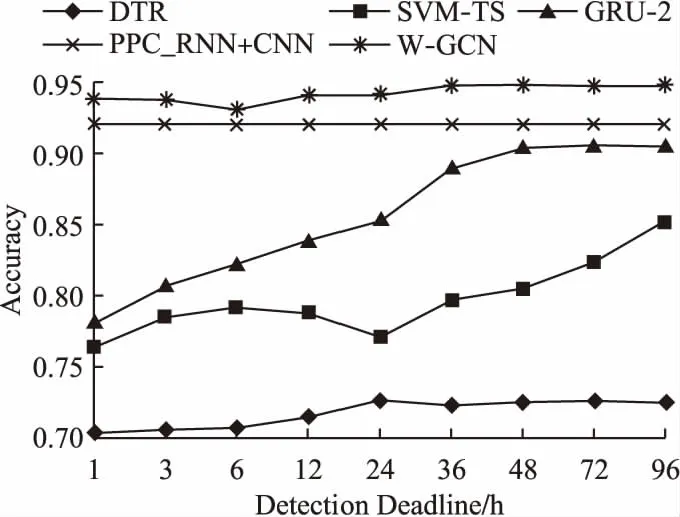
图3 谣言的早期检测结果
在谣言的早期检测任务中,只能使用从微博原文发布的时间算起之后的若干小时内的微博信息.为了评估本文模型与其他基准方法在谣言检测早期性的表现,本文选取了以小时作为单位的9个时间点,分别为1,3,6,12,24,36,48,72,96小时.可以看出与现有的谣言检测方法相比,本文提出的模型在谣言的早期检测任务上同样表现出了更好的效果.
4)与无权图卷积神经网络模型的效果对比
为了分析连边的权重对检测效果的影响,我们将本文模型与无权图卷积神经网络(Unweighted-Graph Convolutional Network,UW-GCN)模型进行对比,实验结果如图4所示.通过比较W-GCN模型与UW-GCN模型在选取的9个时间点上谣言检测的正确率,不难看出考虑事件之间联系的紧密程度,能够对谣言检测的效果有较大提升.

图4 加权图卷积神经网络(W-GCN)模型与无权图卷积神经网络(UW-GCN)模型的谣言检测结果
5)模型训练的Epoch数量对谣言检测效果的影响
对W-GCN模型,不同的Epoch数量下训练集事件与测试集事件的谣言检测效果进行实验,设置了25个不同的Epoch数量,结果如图5所示.
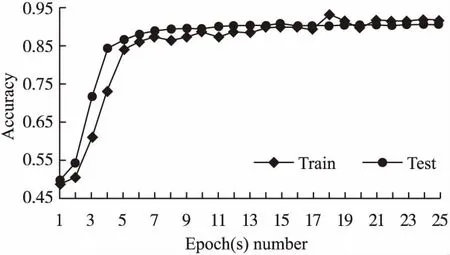
图5 Epoch(s)数量对谣言检测效果的影响
可以看出,当模型训练1个Epoch时,训练集和测试集数据的检测正确率都比较低,此时的模型无法学习到微博事件的隐层特征,模型的谣言检测效果较低.当模型训练到了第5个Epochs时,训练集和测试集数据的检测正确率均快速上升,此时的模型已经初步完成了对微博事件隐层特征的学习,模型的谣言检测效果一般.随着模型训练到第25个Epochs时,训练集和测试集数据的检测正确率在一定范围内波动,总体呈上升趋势,此时的模型已经具有比较良好的谣言检测效果.而随着Epoch(s)数量的进一步增加,模型最终会收敛,对谣言事件的检测效果会达到最优值.
5 结束语
目前传统的机器学习方法以及深度学习方法被广泛地应用于社交媒体的谣言检测中,但是这些方法忽略了事件之间的联系或者事件之间联系的紧密程度,会影响检测的效果.因此本文充分考虑了事件之间联系的异质性,基于图卷积神经网络(GCN)提出了一种新型的新浪微博平台谣言检测的方法.该方法通过将事件作为节点,事件之间的联系作为连边,并且考虑了连边的权重,构建出了一个加权图卷积神经网络模型W-GCN.接着使用BERT模型和卷积神经网络(CNN)模型得到微博事件的特征表示,并将该特征输入到W-GCN模型中,对W-GCN中的节点完成分类,最终完成新浪微博的谣言检测任务.与所选的基准方法相比,本文的方法在谣言事件的检测上取得了最好的效果,体现了本文模型在新浪微博谣言检测问题中对谣言事件检测的有效性.同时在谣言的早期检测方面,本文的方法也高于基准方法,体现了本文提出的模型在新浪微博谣言的早期检测方面的有效性.为了提高模型检测的性能,在之后的研究中,可以考虑使用其他事件之间的联系作为GCN模型中节点之间的连边,或考虑使用不同的图网络模型,在节点的特征向量中,融入一些代表性的微博事件特征等方法,来进一步增强模型的谣言检测性能.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
环球时报(2022-04-13)2022-04-13
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
小雪花·小学生快乐作文(2020年4期)2020-10-12
民生周刊(2017年22期)2017-12-12
新高考·高一数学(2016年10期)2017-07-06
高中生学习·高三版(2016年9期)2016-05-14
