
活动社交网络中活动推荐方法总结与展望
2021-08-24 06:53:14赵海燕孙俊松陈庆奎
小型微型计算机系统 2021年8期
赵海燕,孙俊松,陈庆奎,曹 健
1(上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海理工大学光电信息与计算机工程学院,上海 200093)
2(上海交通大学 计算机科学与技术系,上海 200030)
1 引 言
近年来,随着移动互联网技术的普及,一种新型的活动社交网络(Event-based Social Networks,简称EBSNs)纷纷出现,在近几年获得大量用户的追捧.以Meetup(活动推荐平台)为例,据官方数据统计,至2019年已经有超过44000000的会员,超过33万的群组以及每周超过84000的活动数.用户通过Meetup平台寻找和建立社区团体,在真实世界中进行面对面的互动.任何人都可以组织小组或参加任何主题的活动,将兴趣相似的人在现实中联系起来.
由于活动社交网络中有着大量的活动,用户搜索感兴趣的活动并不容易,因此,有必要主动为用户进行活动推荐.活动推荐可以简单的理解成向用户个性化地推荐用户可能喜欢的活动.作为推荐系统的一个分支,活动推荐已经成为新兴的研究方向.
在EBSNs环境下,向用户个性化推荐活动面临一系列挑战.冷启动问题是推荐系统常见的问题,在缺乏用户数据和评价的活动推荐中这一问题更为明显.EBSNs上的许多活动生命周期短并且前期参与反馈较少,致使活动推荐必须要求系统能在有效时间内快速推荐,不然推荐会失去意义,因此,在推荐活动的过程中遇到了比物品推荐中更严重的冷启动问题;其次,由于EBSNs中存在线上线下异构社交网络[1],需要考虑两者相互作用.相比于活动本身的属性,社会因素对推荐的影响十分显著,这也与物品推荐存在差异.
近年来,许多学者围绕活动推荐进行了研究.现有的研究主要是利用EBSNs特性以及活动的特殊属性等来缓解冷启动问题.使用的算法主要有基于协同过滤的方法、基于图的方法以及基于上下文感知的方法.深度学习在活动推荐中的文献相比于传统的方法较少.深度学习的使用在推荐中起到良好的作用,改善了特征提取并提升最终的推荐效果.同时,也有学者对于EBSNs下的活动参与率和活动组织问题进行多方位的研究.本文对EBSNs中的活动推荐的研究现状进行了总结,并对未来的研究方向进行了展望.
2 EBSNs上活动的特性及其推荐问题
2.1 活动的定义及其特点
根据百度百科的定义,活动是由共同目的联合起来并完成一定社会职能的动作的总和.活动由目的、动机、动作和共同性构成,具有完整的结构.活动的定义是宽泛的,对活动分类的方式也有很多种.研究者们探讨了不同类型活动的推荐:在文献[2]中,作者研究如何对于文娱活动进行推荐,同时也有学者对学术活动进行推荐[3]等.EBSNs下的活动推荐与一般的活动推荐有较大的差别.本文讨论的是EBSNs上的活动推荐.
根据文献[4]等的总结,EBSNs上的活动具有4个方面的主要特性:
1.生命周期:活动具有生命周期,具体是从活动的发起到活动结束的这段时间.
2.时效性:对于活动推荐来说,系统必须要在活动的生命周期内向用户推荐,一旦活动的生命周期结束,再向用户推荐该活动,是没有任何意义的.
3.短暂性:EBSNs上的活动数量非常多,同时每天也有大量的活动完成和消失.这也意味推荐系统必须能应对大量活动的出现和消失,并在活动生命周期内向用户准确推送.
4.反馈较少:一个活动在其刚发布时,用户的参与意图反馈较少,而大量的参与意图发生在活动即将发生的时候.一个活动只有在即将发生的时候才能有更多参与者,考虑到活动时效性,向用户推荐活动会变得很困难.
根据活动举办形式的不同,活动可以分为线上活动与线下活动.线上活动[5]主要是指通过互联网举办的社交活动,这些活动对于时间地点的要求较低,用户容易参与,而线下活动则恰好相反.文献[1]中的研究表明在线社交网络的活动频率要高于线下活动.在EBSNs同时包含了线上活动和线下活动的信息.
按照活动的周期性,活动又可以被分为周期性活动与非周期性活动.这种分类在推荐的过程中,可以作为依据缓解推荐中碰到的问题.文献[6]的研究表明EBSNs中存在大量的周期活动,这类活动是由某个小组长期组织的活动,对于一部分用户来说参与这些活动已经成为惯例,不会受到其他因素的影响,同时,由于他们长期参与这类活动,所以在相同时间段内推荐同类型活动常常是无用的.因此,将周期性因素考虑进推荐过程,可以提升推荐效果.
同时在EBSNs上存在线上群组,这种群组类似于同好群,用户可以通过自己兴趣加入群组,并参与这些群组织的活动.群组的存在影响了用户对活动的选择[7].图1为对上述活动分类的汇总.
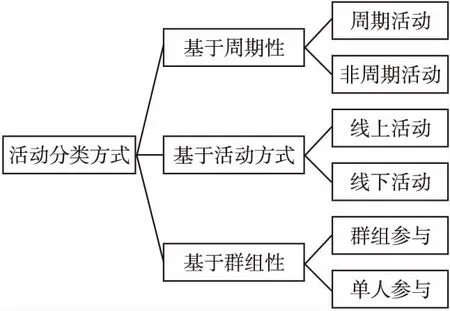
图1 活动分类结构图
2.2 EBSNs上的活动推荐
2.2.1 EBSNs 特性
EBSNs同时拥有在线社交和线下社交,它以活动为驱动,使人们通过线上组织,在线下进行社交活动.根据文献[1,6]的研究,线上社交要比线下社交密集得多,两者之间具有互相促进作用.EBSNs除网络特性以外,还具有社会特性和时空特性.
EBSNs是一个特殊的社交网络,其本身也是一个值得研究的课题.文献[8]中对离线社交与在线社交的相互影响进行了研究,发现参与线下社交的人在线上社交更加地活跃,但同时对于那些未参与活动的用户,他们的联系会因此变弱.在文献[9]中,作者研究了EBSNs中人员的关系,发现EBSNs成员的参与方式并不完全相同,并且他们在不同的情况下可能在不同的角色之间转换.在文献[10]中,作者对活动流行度进行了预测,并研究了如何提高EBSNs活动流行度问题.在文献[11]中作者提出了活动之间的时间冲突问题.
文献[1]的研究表明,EBSNs存在周期性特点,线下活动需要充足的时间,因此大部分活动的举行都会选择在休息日和节假日.在参与活动的位置选择上,81.93%的用户都选择离家10英里以内的活动,活动的参与人数以及群组的人数都服从于长尾分布,参与的人数越多的活动其数量越少.由此可知,EBSNs上的活动推荐需要考虑时间、位置、在线离线社交网络信息,在现有的研究中,这些因素也经常被用与缓解冷启动问题.线上社交网络中,基于位置的社交网络中在线服务也会通过地理位置向用户推荐活动.但不同的是,基于EBSNs的活动推荐更加复杂,它需要考虑到线上群组对于活动组织的影响.活动存在目的,动机,动作等构成部分,这与物品的定义不同,因此,活动相比于物品更为复杂,不能把传统的对于物品的推荐方法简单应用于活动推荐上.
用户在EBSNs上通过RSVP(Reply,if you please,收到请回复,以下简称RSVP)对活动进行意图反馈,RSVP信息一般只有参与和不参与两个选项.通常用户的反馈并不积极,且反馈大多数发生在活动即将举行的时间段,导致了用户的反馈稀疏问题.许多用户在活动参加后对活动进行评分,此时,由于活动已经结束,评分只能影响推荐系统日后对于向用户进行其他活动的推荐,显然,缺乏显式反馈也将影响活动推荐的效果.
2.2.2 数据集
在活动推荐研究中,多数学者基于Meetup的数据进行实验,主要原因是Meetup提供的服务较为完善,用户基数大,且每周都有大量活动更新.同时,也有一部分学者以豆瓣同城平台作为研究对象.豆瓣有许多活动涉及到剧团或公司发布的活动与展览等,其与一般的活动性质有所不同.研究人员可以从Meetup接口(1)www.meetup.com/meetup_api/以及豆瓣同城(2)www.douban.com/location/world/上直接爬取,两个网站都有提供接口供用户获取数据,主要爬取用户关系、活动文本以及地理信息.相比较而言,Meetup的接口提供较为完整,其中包含了群组及群组活动的各类详细信息,也包括了组员的公开信息.
不同的EBSNs的数据集有不同的特点,例如Meetup的数据集中没有活动的时间窗和活动时间长短这些信息,因此在活动行程的推荐中,系统无法判断一个活动的持续时间,导致无法给用户准确推荐下一个活动行程,而在文献[12]中,作者利用了数据集DEvIR(3)www.github.com/ecafidid/DEvIR,该数据源自一个著名的大型分布式事件—圣地亚哥国际漫展,它包含了活动的时间信息,因此,漫展官方自2013年起提供了一种行程软件用于规划和记录与会者行程.
2.2.3 评价指标
目前文献中评价主要以离线测试为主,将数据集分为测试集与训练集并通过测试集预测评分.相比于在线测试和问卷调查,离线实验预测速度较快,花费较低.在离线实验中使用较多的评测指标如下:
1.推荐准确度:准确度是指推荐系统预测用户可能行为的能力,又可以具体分为评分预测和前n项预测(TopN).评分测定常常使用均方根误差(RMSE).
(1)
TopN是活动推荐常用的方式中,经常以准确率(precision)、召回率(recall)、归一化折损累计增益(NDCG,Normalized Discounted cumulative gain)以及AUC(ROC曲线下的面积)等.
在活动推荐中常用的准确率指标为P@n(Precision at Position n,位置n处的准确率)和mAP(Mean Average Precision,平均准确率均值),是将所有用户的平均准确率取均值.
(2)
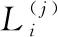
(3)
(4)
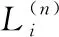
召回率(Recall)能衡量一个推荐系统是否只有顶部的部分物品被推荐.
(5)
di(L)表示推荐列表Li在top-n位置时用户i参与的活动数量,|Hi|表示用户i参与活动数量.
接受者操作特性曲线(ROC,receiver operating characteristic curve)横坐标为假阳性率,纵轴为真阳性率.公式中AUC(Area Under Curve,曲线下面积)代表ROC曲线下面积,表示分类器给正样本打分高于负样本的可能性.
(6)
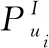
折损累计增益(DCG)能将推荐结果相关性分值累加后作为整个推荐列表的得分,而nDCG则是对DCG做归一化处理,方法是将DCG除以理想最大折损累计增益(IDCG).
(7)
其中,DCGP是位置p折损累计增益,IDCGp是位置p的理想最大折损累计增益.
2.覆盖率:指推荐对象占整个推荐池的比例,它描述了一个推荐系统对长尾对象的挖掘能力.
3.多样性:推荐系统的多样性衡量推荐结果是否能够覆盖用户的不同的兴趣爱好,在推荐系统中直接体现是被推荐物品的不相似性,因此通常使用汉明距离作为评测指标测量这种差异性.
4.新颖性:通过新颖性,系统可以向用户推荐一些非热门活动.
推荐系统除了以上4种推荐指标,还有公平性,健壮性等指标.但是在活动推荐的文献中较为常见的为第一种推荐指标.
活动推荐属于单类推荐,同时在实际推荐过程中往往会生成一个以时间为顺序的列表向用户进行推荐或是在活动下方推荐相似活动.在文献中一般都是采取TopN预测,并计算相应的准确率和召回率.P@n、mAP、NDCG与AUC都是文献较中为常见的评价指标.
3 面向EBSNs的活动推荐模型
3.1 活动推荐模型中考虑的因素
EBSNs上的活动推荐有很多模型,其中有基于协同过滤,基于图,基于上下文感知等.在大部分模型中,考虑到的因素可以分成两部分,一是考虑EBSNs本身的特性,二是考虑活动相关的因素,如图2所示.

图2 活动推荐模型考虑的因素
大部分推荐模型中都考虑了活动的属性,其中较为常见的有时间、标签、地理和社会因素.时间与地理因素主要是指活动具体时间,活动的举办位置和成员所在位置,它们的影响是显性的,例如,活动位置与参与者距离过远或者时间安排在工作日,势必会影响其参与积极性.社会因素又涉及到了多个方面.EBSNs上的活动大多数属于社交类活动,社会与人的影响对于活动相当重要.文献[13]中作者通过分析线上网络的用户行为来识别用户的社交圈与用户之间的友谊,从而推荐熟人相关的活动.现有的参与者对于尚未参与者的决定会产生影响,文献[14]将参与者影响分为3个部分,包括施加影响的用户、受到影响的用户和目标事件.作者通过泊松分布对含有参与者影响的数据建模,获得了一个概率泊松分解模型(probabilistic Poisson factorization model).
文献[15]中,作者将活动组织者作为因素加入讨论.在文献[16,17]中讨论的是用户的吸引力,当用户发布或组织活动后,用户将会提升自身的影响力,并会提升吸引其他用户参与相同活动的能力.通过对吸引力的计算能更好地表示活动之中人与人间的联系.文献[18]中,作者探讨了忠诚度对于推荐的影响,并表明稳定且繁荣的群体拥有更多的忠实用户.与推荐用户喜欢的活动不同,文献[19]中作者考虑的是哪些活动与用户是存在冲突因而不能参与的,以此分配最适合的活动给用户.
此外,有一些推荐模型对EBSNs的本身特性进行建模.文献[16]中考虑了EBSNs的异构性,所提出的模型针对EBSNs拥有线上线下两种社交网络的特性进行推荐.文献[20]中提出了一种名为HeSi的模型,在模型中综合考虑了异构性和区域倾向性,在5个地区的测试数据集上,该模型的AUC要高于传统矩阵分解方法.在文献[21]中,作者利用了EBSNs的信息,并结合地理位置以及用户评分,构造了一个贝叶斯潜在因子模型.文献[22,23]使用核密度估计(KDE)为每个用户的个性化二维位置分布建模(经纬度坐标),来学习活动的地理影响.
3.2 传统推荐模型的应用
传统推荐模型有3种,主要是基于内容的推荐算法,基于协同过滤的推荐算法以及两者结合的混合推荐算法.这些方法在活动推荐中都有应用.
3.2.1 基于内容的活动推荐
基于内容的方法是指对于用户喜欢的物品的描述和属性进行分析,为其推荐与这些物品的描述和属性相似的物品.该方法通常包括物品特征挖掘,用户偏好计算,物品相似度计算,排序等步骤.其中,物品的相似度根据物品的特征进行计算.为了做到这一点,需要有一个内容分析器,它通过关键字匹配或通过TF-IDF(term frequency-inverse document frequency,词频-逆文本频率指数)来提取物品的相关特征.
文献[24]中,作者使用LDA(Latent Dirichlet Allocation,文档主题生成模型)在每个活动和用户上生成主题分布,基于活动内容相似性和用户兴趣主题进行推荐,在该模型中同时也将社交好友以及出勤历史信息放入算法中,结果发现这两种属性可以提高推荐系统的准确率.在文献[25]中,作者对于用户近期历史记录,通过LDA主题模型获取其特征向量,并结合行为权重和时间衰减生成用户长短兴趣模型,使用户偏好预测更准确,也能更好的结合基于内容的方法进行推荐.文献[15]中,通过分析用户参与的活动的内容来获取用户偏好,同时结合组织者影响,地理特征影响,提出了一个整合用户兴趣、组织者影响和地理偏好的活动推荐模型,针对数据稀疏问题,作者提出了一个综合考虑用户偏好和组织者偏好流行感知的概率矩阵分解方法(Popularity-aware Probabilistic Matrix Factorization,PPMF)来推断缺失值.
基于内容的推荐方法可以避免活动的冷启动问题,但是它对内容表示的要求较高,而且单纯的基于内容的推荐方法忽略了社会关系的影响,而这一点恰恰是EBSNs的一个特点.
3.2.2 基于协同过滤的活动推荐
基于协同过滤的方法可分为基于用户的协同过滤算法和基于项目的协同过滤算法,其主要思想是“物以类聚、人以群分”.
文献[26]中采取了基于项目的协同过滤方法,通过项目之间的相似性预测结果,这种方法在用户个性化需求强烈的领域能应对用户不同的需求,但缺点是基于项目的协同过滤中相似矩阵计算代价过大.
矩阵分解在基于模型的协同过滤推荐算法中普遍使用.文献[27]中,作者提出了一种基于事件用户邻域的集合矩阵分解(Collective Matrix Factorization with Event-User Neighborhood,CMF-EUN)模型将基于活动和用户的邻域方法结合到矩阵分解模型中,在该模型中综合了用户在活动内容,活动地点,活动时间上的相似度来计算用户之间的相似度,实验结果表明,该方法要远好于传统的奇异值分解.文献[28]中提出了通过活动参与历史信息来表达用户偏好,通过协同过滤来推荐个性化活动的方法.在推荐过程中,利用用户评价信息可以提高推荐系统的准确性,而没有评价信息则对推荐系统性能造成影响.该方法通过矩阵分解预测特征值.为了考虑用户的潜在偏好,作者通过在有参与类似活动的用户之间进行协同过滤来选择候选用户.实验结果表明,这种方法要好于现有的基于地理特性的方法.文献[29]中,作者则使用贝叶斯概率模型对EBSNs的社会异构性进行建模.文献[21]中,作者把用户的RSVP(收到请回复)数据作为用户评分,将它与EBSNs异构性和活动的地理特征综合考虑,结合贝叶斯因子模型提出HESIG模型(Heterogenous Social Information and Geographical information,异构社会信息与地理信息模型),其AUC在Meetup休斯顿数据集上达到0.729,但是这种方法没有充分考虑推荐的冷启动问题,同时也忽略了活动的内容和组织者信息.在文献[30]中,作者进一步考虑活动的内容信息,通过LDA进行主题建模.在文献[4]中,作者提出了集合成对矩阵分解模型(Collective Pairwise Matrix Factorization Model)对EBSNs中用户的成对偏好和多重交互进行建模,并为模型学习设计了一种有效的随机梯度下降算法.在活动推荐中用户、活动和用户群组/位置之间存在三角交互.以用户、群组和活动为例,用户可以加入组,组可以组织活动,用户可以参与任意活动.而作者将上述信息的三角交互建模,同时把交互矩阵推广为整数矩阵,使用正、负、零值表示用户的偏好,使这种偏好更具层次.其在与HESIG[21]和基于上下文感知的MCLRE[31](Multi-Contextual Learning to Rank method,多语境学习排序法算法)比较中,取得更好的推荐效果.
由于EBSNs上数据的稀疏性,往往难以找到相似用户或者相似活动,导致单纯的协同过滤推荐算法往往效果不佳.事实上,上述介绍的方法中,在计算用户的相似性或者活动的相似性时也利用了活动的相关特征,因此已经不是纯粹的协同过滤方法.
3.2.3 混合推荐
文献[32]中的实验表明,单纯的矩阵分解方法在该问题上效果欠佳.由于单一的推荐系统有各自的弊端,因此结合各种模型的优势的混合模型得到了应用.
混合推荐方法如文献[33,34],将基于内容的方法和基于协同过滤的方法相结合:传统的协同过滤方法在数据缺失时有严重用户冷启动问题,而基于内容的方法则有利于克服这个问题.例如文献[35]一文中,将基于活动和基于用户的邻域方法结合到矩阵分解中,提出了一种混合的协同过滤模型,即活动用户邻域的矩阵分解(Matrix Factorization with Event-User Neighborhood,MF-EUN)模型.该模型首先考虑了用户特征信息和活动特征信息,以此发现它们的邻域.再将其与矩阵分解的方法相结合来提高准确率.邻域发现的推荐中,更重视与其相近的邻居,而忽略全局.基于矩阵分解的方法则恰好相反,两者结合可以互相补足.
文献[36]中Simon Dooms等人基于用户的实际评测从准确性、新颖性、多样性、满意度和信任度这5点进行了推荐模型效果的研究,发现混合算法要比单纯的协同过滤或者基于内容的方法要优秀,这说明混合推荐在该问题上的优越性.
3.3 基于图的活动推荐模型
在活动推荐的研究中,近年来出现了许多基于图的推荐模型.基于图的推荐方法中将数据用图模型表示,其中的节点代表了EBSNs中的实体,连接代表了实体的各种关系.
文献[37]较早将基于图的方法引入活动推荐,作者构建了一个异构图来刻画EBSNs,将推荐看作一个邻近节点的查询问题,文中提出了一个通用的基于图的推荐模型HeteRS(Heterogeneous graph-based Recommendation System model),并通过数据自动学习多元马尔可夫链(multivariate Markov chain,MMC)的参数.该模型能够完成活动推荐中的3种推荐任务:向用户推荐线上活动,向用户推荐线上群组以及向群组推荐活动标签.然而文献[37]中的方法只考虑到EBSNs中显性关联.在文献[38]中发现,只考虑显性关联会产生许多悬挂节点,这些节点影响了图的连通性以及随机游走的展开,因此作者提出了不同于异构图的混合图模型,将原先异构图中活动与属性的显性关联转化为活动与活动间的隐式关联,以减少图中节点.作者发现这样的做法不能区分不同类型的关系的优先级,于是进一步提出使用基于内容的重排序算法,从图随机游动所选择的候选活动中获得最终的活动推荐列表.
EBSNs中有大量实体和具有唯一性的活动,如果使用所有的信息会增加计算负担,十分耗时.文献[39]中提出了一种改进的基于演化图的连续推荐(evolving graph-based successive recommendation,EGSR)算法解决这种问题.在EGSR中利用一个长度可调的滑动窗口机制构造演化图.它将时间线划分为长度相等的连续槽,然后通过一个滑动窗口的最新的信息构造图.同时,作者提出了一个基于图熵的方法用以调整窗口长度,并对每个历史时间块进行加权.文献[40]中,作者提出一种反向的带重启的随机游动(Reverse Random walk with Restart,RRWR)方法,也使用滑动窗口机制来构造演化图,以连续地为每个用户推荐新活动.一些不组织活动的群组被称为悬挂组节点,在随机游走遇到这些节点会对结果产生偏差.RRWR中的悬挂节点比带重启的随机游动中的悬挂节点接收到的传输概率更小,导致更可靠的稳态概率,从而解决了悬挂节点的问题.
文献[41]一文中考虑了活动的社会属性,将活动推荐的重点放在向用户推荐活动伙伴上,为此,提出了一个通用图的嵌入模型(generic graph-based embedding model,GEM)将用户、活动、位置、时间和文本内容间的关系嵌入到一个共享的低维空间中,以解决冷启动的问题.在文献[42]中提出了基于图熵的连续活动推荐(successive event recommendationbased on graph entropy,SERGE)构建了一个主图来寻找不同实体间的关系,此外还构建了一张用户反馈图,通过在两张图上应用带重启的随机游走算法获得两组用户活动相似度得分,生成最终的推荐列表,其基本思想是在利用带重启的随机游动(RWR,Random walk with Restart)来对即将发生的活动进行排序,然后应用主题分析技术来分析活动文本建立每个用户的兴趣模型,并计算活动内容和用户兴趣之间的相似度作为每个图的边缘权重.
在算法的精度上,从早期文献中实验的准确率在0.2以下,到文献[42]一文中SERGE模型准确率接近0.3,表明基于图的方法有助于提高推荐性能.但在文献[38]一文中,作者同时对上海北京两地的数据建模,最后的准确率差距十分巨大,这也体现模型仍有不足的地方需要去改进.
基于图的方法能很好地表示关系,同时也存在很多局限性.基于图的方法聚合过去的交互历史,但会随着数据量的增加性能急剧下降.
3.4 上下文感知的活动推荐模型
上下文是用于描述实体状态的任何信息.在推荐系统中上下文定义十分宽泛.上下文可以是文本主题,时间,位置等.通过上下文感知能够获得大量有用的信息有助于缓解冷启动现象,因此,在活动推荐中,也有大量关于上下文感知活动推荐的研究.
文献[43]中,作者深度剖析了活动主持人和群体成员的社会影响,利用活动主持人和群组成员的社会影响力以及上下文(如时间、内容和位置)的影响进行推荐,提出了一种基于活动主持人的活动推荐模型,在实验中发现活动主持人和群体成员的社会影响力比活动的时间信息更为重要.在文献[31]中提出了一个混合推荐方法,利用多个上下文感知的推荐模型学习活动排序,除了基于活动描述的信息和来自用户的RSVP(收到请回复)的信号外,还利用了基于组成员身份的社会信息、基于用户地理偏好的位置信息和用户时间偏好.文献[44]中,作者将隐式反馈和各种上下文信息结合进行建模,在实验中发现,活动、用户、时间等语境特征的信息量最大,其次是社会、空间语境特征,而将它们结合在一起的方法有更高的准确率.
文献[45]关注本地冷启动活动推荐任务.作者提出集体贝叶斯泊松因式分解(collective Bayesian Poisson factorization,CBPF)模型结合贝叶斯泊松分解和集合矩阵分解的优点,首先通过贝叶斯泊松分解(Bayesian Poisson factorization,BPF)分别对社会关系、用户对活动的响应和活动内容文本进行建模.泊松分解是一种概率矩阵分解的变体,其中每个用户和物品的权重都为正,并且用泊松分布代替高斯分布.在基础的数据分布外,作者还将Gamma先验放在潜在属性和潜在偏好上,从而使得模型趋向于用户和项目的稀疏表示.此外,作者对用户和项目特定的速率参数设置了额外的优先级,以控制表示的平均大小.这种层次结构能更好地捕捉用户多样性.作者称此为层次泊松分解(hierarchical Poisson factorization,HPF),而BPF是将HPF中所有用户和项的速率参数固定为同一对超参数,属于HPF的一种子类.贝叶斯泊松分解方法结合了贝叶斯学习与泊松分解,能够很好地处理稀疏数据,并且对过拟合问题具有更强的鲁棒性.在建模完成后再通过集体矩阵分解(Collective Matrix Factorization,CMF)将上述各个单元联系起来.
文献[46]中作者发现组织者和活动的文本内容之间的相关性,同一组织者举办的活动往往有更多相似的内容,通过组织者与活动内容之间的关联可以缓解活动文本内容的稀疏性,从而更准确地提取出对活动的群体兴趣.文献[47]中,作者提出了一种基于语义增强和上下文感知的混合协同过滤的活动推荐方法,将语义内容分析和上下文影响相结合,用于用户的近邻选择,试验表明,应用活动描述语义来建立用户的兴趣模型是有用的,但也需要活动文本对于用户兴趣建模的时间衰减.
3.5 算法参数比较与分析
在各类算法中,许多使用了时间,位置等上下文信息等进行综合计算,在这些算法中,涉及到对信息以及由这些信息带来的对结果的影响的合成.经常用超参数来控制合成的方式,而由于算法中考虑的上下文不同,各个算法中的超参数也有所不同.在文献[24]中,作者将用户与活动的语义相似度,用户关系以及用户历史信息进行综合后推荐.在实验中,对这3者的权重设置了3组值(0.2,0.3,0.5;0.5,0.2,0.3;0.3,0.5,0.2),其中第一种权重设置的精度是最高的.而在利用LDA主题建模对语义进行获取的过程中,主题数从25个增加到150个时,这时的性能相对稳定.
另外,许多模型中在目标函数中加入多种误差的权重,以及模型的正则项,它们的系数也需要确定.同时,对于迭代优化过程,需要设置学习速率和迭代参数.目前这些系数通过经验和实验进行设置.如在文献[31]中,在考虑用户、群组以及活动间的多关系模型中,目标函数为:
(8)
其中,L是所考虑关系的重建误差的损失函数,α、β、γ是所考虑关系的损失的特定权重和λU、λG、λE正则化参数.对于权重值,作者分别设为0.1,0.22和0.68.作者使用了MRBPR(Multi-Relational Factorization withBayesian Personalized Ranking,贝叶斯个性化排序的多关系分解)进行算法的比较.其对于隐因子参数k设置为200,学习速率为0.1,迭代次数600.而文章作者介绍了一种结合位置信息,时间信息,群组信息等通过坐标上升法优化的基于上下文信息推荐算法MCLRE[31].同样的,在文献[44]中研究中,其将学习速率设为0.1,正则化参数设为0.01.经过实验也发现潜在因子维数k对模型性能的影响较小,在作者自己的模型中维数选择为100.
MCLRE模型是基于上下文信息活动推荐模型中有代表性的算法,它融合了文本内容、时间、位置和群组信息.该模型在活动描述上使用经典的词袋模型,每个用户被表示为从用户参加的过去活动中提取的单词的TF-IDF向量,用户u的形式定义:
(9)
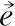
很多研究工作[4,22,43,44,46]对其进行比较与借鉴,这些算法中对信息使用上不少依旧采用MCLRE中的方法.例如在文献[43]中对上下文信息的使用上对MCLRE中的超参数进行了一定的保留与改进.其中时间衰减因子α为{0.005,0.01,0.5},其余超参数相同.文献[44]对于在群组偏好的计算:
(10)
g(e,ei)=δ·I(u∈ge)+(1-δ)·I(ge∈gei)
(11)
其中,gp(u,e)表示当用户参加活动时的群组偏好,ge是主办活动e的群组,I(u∈ge)表示u是否是ge的成员,举办事件e和ei的组是否是同一组.,Sim()是余弦相似度.δ权重设置为0.5.
从相关研究中可以看出,每个模型都具有自己的超参数,目前的超参数取值还是采用了基于经验和基于实验的方法.如何能够更好地设置模型中的超参数,还是一个具有挑战性的问题.特别是在活动推荐中,许多模型融合多方面的信息,这就必然会带来较多的超参数,这就使得这一问题更具有挑战性.
4 基于深度学习的活动推荐模型
4.1 深度学习在推荐系统的作用和意义
深度学习近几年十分流行.在文献[48]中,作者对于深度学习在推荐系统中应用进行了综述,文章主要写了深度学习如何改进传统推荐算法例如协同过滤等以及介绍了深度学习方法对于推荐系统的改进.深度学习主要可以改进推荐系统的特征提取与特征表示,使系统学习到更好的用户和项目的隐向量.嵌入(embedding)技术是深度学习得到目标的低维表示.进一步,循环神经网络可以对序列数据建模.
根据文献[49]的研究,深度学习的技术可以增加协同过滤的能力,主要的方法是通过某种形式的深度学习来代替矩阵分解.文献[50]中提出一种新的上下文感知推荐模型卷积矩阵分解(convolutional matrix factorization,ConvMF),该模型将卷积神经网络与概率矩阵分解(probabilistic matrix factorization,PMF)相结合,ConvMF能更好捕捉上下文信息并提高预测准确性.文献[51]中提出了一个层次贝叶斯模型,称为协同深度学习(collaborative deep learning,CDL),它融合了内容信息的深度表示学习和基于评分矩阵的协同过滤.文献[52]中的研究表明,协同过滤可以转化为序列预测问题,因此递归神经网络可以起到作用.
图神经网络是深度学习在图上一种新应用,主要分为递归图形神经网络、卷积图形神经网络、图形自动编码器和时空图形神经网络[53].图神经网络作为一种能够自然地集成节点信息和拓扑结构的网络,在图数据的学习中有很好的效果,已经被用于推荐系统[54].
4.2 活动推荐中深度学习的应用
文献[55]中提出了基于用户深度建模框架的活动推荐(Deep User Modeling framework for Event Recommendation,DUMER),通过挖掘用户参与活动的上下文信息来刻画用户的偏好,并利用卷积神经网络和词嵌入技术来深入捕捉用户感兴趣活动的上下文信息,并为每个用户建立用户潜在模型,再将用户潜在模型引入概率矩阵分解模型,提高推荐精度,在实验中与另外两种基于深度学习模型ConvMF[50]和CDL[51]比较,该模型在RMSE与召回率表现更优.实验也表明,嵌入与bag-of-word模型对比,使用嵌入能更好地捕获活动的上下文信息.文献[56]中,研究了一种基于卷积神经网络的用户和活动联合表示方法,以减轻冷启动影响:在第一阶段,进行联合表示学习,同时建立活动模型和用户模型,对于两个模型通过卷积神经网络进行数据预处理,将任何给定的用户和活动投影到同一个潜在空间中,实现高效和准确的匹配;第二阶段,将匹配结果作为一个特征,与其他标准特征一起,输入到基于梯度增强决策树(Gradient Boosting Decision Tree,GBDT)的组合器模型中.
深度学习除了对于特征提取上对于活动推荐有所助益,在对预测上也有很大的提升,利用循环神经网络对序列建模,可以更好地反映用户兴趣.
文献[57]中,提出了一种循环神经网络模型来解决时间异构反馈推荐,时间异构反馈推荐的任务是决定用户将来可能感兴趣的项目,而反馈的顺序反映了用户偏好的变化.在文献[58]中,作者提出了一个共同进化的潜在特征过程模型,该模型能够准确地捕捉用户和项目特征的共同进化性质,使用循环神经网络来自动学习来自用户和项目特征的漂移、进化和协同进化的影响的表示.文献[59]中运用了一个3层长短期记忆网络(LSTM,Long Short-Term Memory)的结构,在第1层中,将活动的上下文信息以非线性的方式转化为潜在的嵌入向量;在第2层中,考虑用户在不同组中的出勤行为来编码用户不断变化的独特偏好;第3层中,对用户的顺序偏好进行编码,以捕获出勤模式的时间演化特性,并与前两层生成的嵌入向量进行交互,生成语义嵌入偏好向量的多维编码,最后,输入到多层感知器(Multilayer Perceptron,MLP)中,用于预测每个用户的活动出席率.而文献[60]中,作者提出了一个基于LSTM模型DeepVenue,用于推荐举办Meetup活动的场馆.
文献[61]中,作者对神经网络RankNet进行了改进,建立了一个学习排序算法来揭示每个特征的重要性,其性能与基于多特征评分模型的MHF[62]和基于上下文感知的MCLRE[31]等算法相比,表现要更好.文献[63]中,作者提出了一个混合式深度神经网络协同过滤架构(HDNN-CF,Hybrid Deep Neural Networks CollaborativeFiltering).这是一个生成模型,它将协同训练一个堆叠降噪自动编码器(SDAE,Stacked Denoising Auto Encoder)以深度表示语义信息和一个用于表示隐式反馈的PAutoRec模型.PAutoRec是AutoRec[64](autoencoder framework for collaborative filtering,基于自动编码器的协同过滤模型)的扩展,它引入了自适应先验,通过合适的先验能自动控制模型的容量.实验结果显示,HDNN-CF在前30名推荐的召回率上比现有方法有10%以上的显著提高.
综合看来,深度学习在活动推荐中方兴未艾.两者的结合应用上还有很大的研究空间.表1所示为文章归纳的文献分类.

表1 活动推荐的方法分类
5 研究展望
1)更丰富的数据集支持更多的推荐场景
目前的许多研究工作都是基于Meetup的数据,但是Meetup数据集本身也存在一定的不足,例如其缺乏活动持续时间.如果数据集中包含更多信息,则可以支持更为丰富的推荐场景.例如文献[12]提出的展会数据集,由于展会密集的活动行程、活动冲突和充足的时间信息,能更好对分布式活动以及活动行程进行推荐.虽然该数据集的作用和本文着重讨论的EBSNs下的活动推荐有所出入,但活动行程推荐能很好帮助用户规划自己行程,尤其是在活动密集的会议和展览中效果显著,值得进一步的探索.
2)融合用户更详细的信息
现有的研究将大部分注意力都集中在活动的社会性方面,包括成员影响力,成员社交圈等.研究证明这些因素确实影响活动推荐的准确率,然而关于活动成员以及用户的研究仍可以细化与深入.目前研究的维度主要是活动与其他参与者对用户的影响,却很少有文章从用户自身因素做研究,例如用户的个人信息、经济能力等.
3)考虑平台和地点差异性
文献[38]的实验中,北京与上海两地预测的准确率差距说明了地理信息不同对于活动推荐的影响也不尽相同.这说明,在不同的地域中,用户对活动的偏好可能有所不同.进一步,在不同的平台上,用户群体也有差别,这使得某一平台上的模型并不能简单迁移到另一平台上.如何考虑由于地点、平台差别带来的异构性,是一个值得探讨的问题.
4)推荐中考虑更多的目标
目前对活动推荐很少有对于推荐公平性、多样性等测定,这是目前研究中存在的不足,也是未来研究中值得考虑的问题.
5)深度学习在活动推荐中的应用
深度学习在活动推荐中应用的文献较少,但是深度学习在推荐系统领域已经取得了很大的进展,可以预计深度学习对于活动推荐一定有所帮助,考虑到图模型在活动推荐广泛的应用,图神经网络可能是深度学习在活动推荐中一个比较好的研究方向.
6 总 结
随着Meetup、豆瓣同城等网站的流行,EBSNs上的活动推荐成为了一个热门的领域.本文对EBSNs环境以及活动特性进行描述,总结了其对活动推荐产生的影响,指出了由于活动缺乏反馈信息等而引起的严重冷启动问题以及活动属性极大地影响了用户对于活动的选择.这些问题直接导致传统的推荐方法在活动推荐中应用难以取得满意的结果.在活动推荐中较为常见评价指标是AUC、P@n以及nDCG,而活动推荐的数据集一般由作者自行在meetup等活动推荐网站爬取,文中通过分析活动推荐考虑的因素维度和活动推荐模型阐述了活动推荐的研究进展.现有的推荐模型大多是混合方法.其中,基于图的方法能很好地对EBSNs异构关系进行建模,但是图方法需要大量的数据以及计算量.基于上下文感知的推荐算法在推荐中能扩展数据,并且时间,位置以及主办人信息等能缓解冷启动问题.深度学习能够自动学习活动、用户的深度表示,一方面能够缓解冷启动问题,另一方面也能对复杂关系进行建模,在活动推荐中具有良好的应用前景.
猜你喜欢
速读·下旬(2021年11期)2021-10-12 01:10:43
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
大东方(2019年12期)2019-10-20 13:12:49
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子测试(2018年14期)2018-09-26 06:04:10
科学与财富(2017年22期)2017-09-10 13:20:02
商情(2017年1期)2017-03-22 16:56:36
现代防御技术(2016年1期)2016-06-01 12:13:27
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:42
