
基于卷积神经网络的桥梁裂缝检测方法
2021-08-23 04:00廖延娜
计算机工程与设计 2021年8期
廖延娜,李 婉
(1. 西安邮电大学 电子工程学院,陕西 西安 710121;2.西安邮电大学 理学院,陕西 西安 710121)
0 引 言
造成桥体结构产生裂缝的原因很多,包括荷载过重、化学反应、施工及环境因素等[1,2]。在实际桥梁检测中,从最初的人工检测、桥梁检测车,到各种结构的无损检测,再到现在的智能化检测,都是在实践中发现问题并解决问题[3]。近年来,越来越多的检测算法被用于桥梁检测,这些算法主要分为传统图像处理和深度学习处理两大类[4-6]。叶琰通过采用滤波、多种阈值处理、形态学算法等基本图像处理算法进行桥梁裂缝检测[7];J.Peng等设计了一种结合BP和SOM的网络算法用于识别桥梁图像表面的缺陷[8];x.JIA等提出将数字图像处理与卷积神经网络相结合通过调整卷积神经网络的结构,提高图像分类精度[1]。尽管近年来基于桥梁裂缝检测的算法层出不穷,但是将经典目标检测网络应用到桥梁裂缝检测中的仍为较少,且桥梁裂缝由于其地理位置和自身特征的特殊性,对检测算法的轻便性、可移动性有一定要求。
综合多种因素,引入检测速度和精度较为均衡的YOLOv3目标检测网络[9]用于桥梁裂缝检测研究,并对YOLOv3多尺度预测模块进行改进,充分利用浅层特征改善小裂缝不易及检测的问题,并使用聚类算法对自建桥梁裂缝数据集的先验框进行聚类。数据集方面引入生成对抗网络进行数据集扩增。最后通过实验验证改进后裂缝检测网络的检测性能。
1 桥梁裂缝图像数据集采集与处理
1.1 桥梁裂缝数据集采集
深度学习中,丰富的数据集是保证一个模型精确度的先决条件,一个质量和数量可观的数据集可以很大程度上提升模型的实际性能。由于桥梁裂缝图像没有相应的公开数据集,因此人工拍摄1000张尺寸2500*1900的桥梁裂缝图片作为原始数据集,如图1所示。并通过旋转、缩放、翻转、对比度增强等操作进行数据集增强。原始数据集尺寸较大,若直接输入到网络中会被随机改变输入尺寸而减小分辨率,导致某些细小特征丢失,故将增强后的数据集图片再通过切割函数分割成多个416*416尺寸的裂缝图片,使得尽量裁剪到裂缝,并从裁剪处理后得到的图片中滤除不含裂缝或只含裂缝极少量特征的图片。

图1 原始桥梁裂缝图像
1.2 基于生成对抗网络的数据集扩增
数据是深度学习的重要组成,当数据不足以训练庞大网络的大量参数时,容易产生过拟合,影响准确率[10],为使得网络模型有更好的泛化能力,需要使用大量数据不断进行训练。目前所拥有的数据集数量十分有限,训练所得模型很容易过拟合,因此需要创建新的有效数据对原有数据集进行扩增。此处选取生成对抗网络并在上一步处理好的数据集基础上加以训练,生成有效的桥梁裂缝图像来扩充数据集。图2为传统生成对抗网络工作流程。

图2 生成对抗网络流程
生成对抗是小数据学习面对庞大网络训练的有效举措,其在已拥有的少量数据基础上让机器自动生成样本数据并不断学习已有数据的特征来生成更大量更真实的数据。因此引入DCGAN(deep convolution generative adversarial networks)生成对抗网络进行数据集扩增,该网络包括生成网络(generator,G)和判别网络(discriminator,D)两部分,且由全为卷积层的卷积神经网络构成[11]。DCGAN网络为了生成虚假数据和真实数据很接近,一方面让G网络学习到较好的一组参数,由噪音数据转换为生成数据;一方面要将生成的数据输入D中进行判别并且尽可能的让D网络判别不出来由G网络生成的数据是真还是假,其目标是让G网络生成的数据更真,让D网络的判别能力更强,两网络互相促进。D网络输入图像,并进行特征压缩,输出真假分类,整个可看作一个下采样过程,因此D网络可以学习自己的空间下采样;G网络输入噪音向量,输出为生成的虚假图像,整个过程可看作是一个上采样过程,因此D网络可以学习自己的空间上采样,从而学习到D网络和G网络各自最好的一组权重参数,即可得到最优的DCGAN网络。D网络和G网络损失函数公式如下:
D网络
LossD=log(D1(x))+log(1-D2(G(z)))
(1)
G网络
LossG=logD2(G(z))
(2)
式中:D1(x)为对真实数据x的判别结果,D2(G(z))为对生成数据G(z)的判别结果,D网络对x的判别结果应尽可能为真实的1,即log(D1(x))=0;而对生成数据G(z)判别结果应尽可能为虚假的0,即log(1-D2(G(z)))=0,两部分相加结果接近为0,即可使得LossD尽可能最小,此时D网络判别能力非常强。当D网络对G网络生成的数据G(z)判断结果越接近真实的1时,可使得LossG尽可能最小,此时G网络生成的数据越真实。最终的DCGAN网络损失函数如下式,其目的是最大化D网络的区分度,最小化G网络和原始数据集的数据分布
minGmaxDV(D,G)=Ex~Pdata(x)[logD(x)]+Ez~Pz(z)[log(1-D(G(z)))]
(3)
2 检测网络结构及原理
目前常见的卷积神经目标检测网络主要分为两阶段和单阶段两大类,主流的两阶段检测器包括R-CNN系列,如:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN等[12],其基本思想是将分类和检测当作两个不同的分支进行优化,由于网络结构繁琐,导致模型复杂,训练速度变慢;单阶段检测器主要包括YOLO系列和SSD系列,如:YOLOv1、YOLOv2、YOLOv3、SSD等,其基本思想是实现端到端训练,采用直接回归的方式直接计算出所需要检测的目标的类别和位置。由于桥梁裂缝检测算法常用于高架桥梁等力无法到达之处,对算法的实时性、轻便性、可移动性有较高要求,同时也要保证网络模型的检测精度,当模型体积较大时,难以进行移动端部署。综合以上因素,引入单阶段的YOLOv3目标检测网络进行桥梁裂缝检测技术研究。
YOLOv3采用主干网络DarkNet-53对输入裂缝图像提取特征,并输出13*13、26*26、52*52这3个不同尺寸的特征图,再利用YOLOv3网络的FPN模块通过锚点(Anchor)机制在输出的3个不同尺寸特征图上分配对应9个尺寸的先验框,用于在训练阶段与真实值计算损失函数优化网络和在测试阶段预测检测框。由于深层特征感受野较大,提取整体特征,有利于大目标的检测,但同时也丢失了细节信息;而浅层特征感受野较小,有利于小目标的检测[13]。桥梁裂缝图像中常有较细小的裂缝,因此对YOLOv3的FPN模块增加104*104尺寸特征图的预测,通过将104*104尺寸特征图与原始FPN模块融合来改善低分辨率下较小目标的检测,提高细小裂缝检测精度。图3为改进前后的FPN模块。

图3 FPN模块结构
YOLOv3网络原FPN模块使用的9个Anchor尺寸依赖于COCO公开数据集,而桥梁裂缝图像与COCO数据集中的对象有很大区别,因此使用K-means聚类算法对自建桥梁裂缝数据集进行重新聚类。聚类分两组进行,一组是基于原FPN模块得到13*13、26*26、52*52这3个不同尺寸特征图上共9个尺寸的Anchor,平均每个尺寸特征图分配3个不同尺寸的Anchor;另一组是基于改进后FPN模块得到13*13、26*26、52*52、104*104这4个不同尺寸特征图上共12个尺寸的Anchor,同样平均每个尺寸特征图分配3个不同尺寸的Anchor。表1为原FPN模块和改进FPN模块使用聚类算法前后不同尺寸特征图的Anchor参数分布。
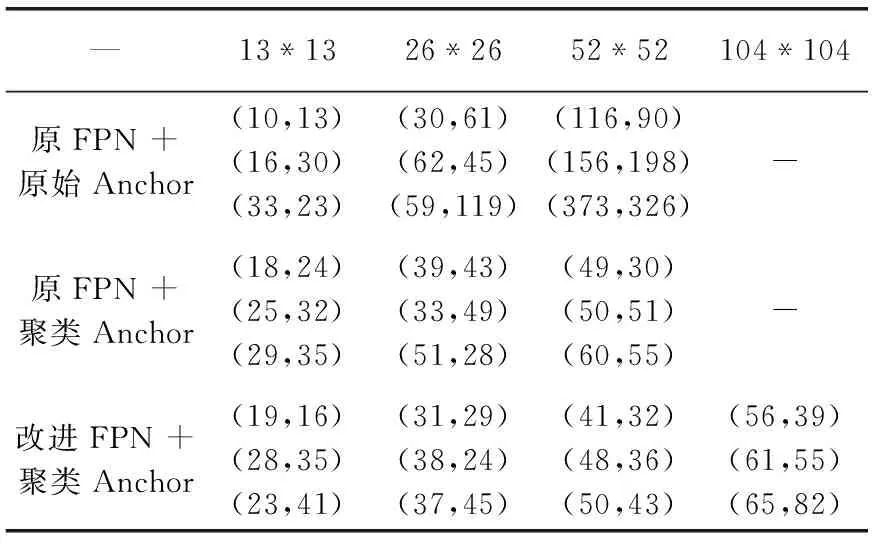
表1 Anchor参数分布
图4为使用以上措施后改进的YOLOv3网络结构配置图,其主要包括特征提取和目标预测两部分,主干网络用于裂缝图像特征提取,改进FPN模块用于目标预测。结构图中,Convolutional模块由卷积核(Conv)、批归一化处理(batch normalization,BN)、Leaky ReLU激活函数组成[14];Convolutional Set由5个不同尺寸的Convolutional模块组成;Up sampling为上采样模块,用于对13*13、26*26、52*52尺寸的特征图进行上采样并与26*26、52*52、104*104尺寸的特征图进行特征融合,增加细粒度特征;Concatenate为连接模块,用于连接相同尺寸、不同通道数的特征图。由于桥梁裂缝检测类别只有一类,因此每个尺寸特征图在每个网格中输出预测框向量的通道数为(5+1)>*3=18,其中5为预测框位置(x,y,w,h)和置信度(Confidence),1为类别数,3表示每个尺度的特征图预设的3种不同尺寸Anchor。

图4 改进YOLOv3的网络结构配置图
在改进YOLOv3网络模型训练阶段,主干网络提取输入裂缝图像的特征,得到4个不同尺寸的特征图,然后分别对不同尺寸特征图上的每一点使用Anchor机制分别得到3个不同大小的先验框,并选择与真实值交并比最大的先验框作为某个裂缝的预测结果,最后综合真实值与预测框得到模型损失函数,通过优化算法对网络不断训练提升精度。改进YOLOv3网络的裂缝检测流程大致分为以下3个步骤:
步骤1使用主干网络对输入裂缝图像进行特征提取;
步骤2通过改进FPN模块进行检测框的预测;
步骤3依据阈值处理算法和非极大值抑制滤除部分不合格预测框,最终得到裂缝图像预测结果。
改进YOLOv3网络的损失函数由预测框坐标误差、置信度误差、类别误差3部分组成,预测框坐标使用均方误差损失,置信度和物体类别使用二值交叉熵损失,其设计目的是通过优化策略使得这3部分达到平衡,损失函数尽可能小,网络检测精度尽可能高。在对模型损失函数进行优化时采用自适应矩估计Adam(adaptive moment estimation)算法,Adam是一种为每一参数计算自适应学习率的方法,其利用梯度的一阶矩估计和二阶矩估计对每个参数的学习率进行动态调整,经过偏置校正后每一次迭代学习率都有确定范围[15,16],Adam优化器公式如下
xt=μ*xt-1+(1-μ)*gt
(4)
(5)
(6)
(7)
(8)
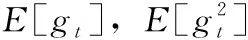
3 基于改进YOLOv3的裂缝检测
本实验基于Python语言在GPU版Tensorflow框架下进行。自建桥梁裂缝数据集包括采集裂缝图像和DCGAN网络生成图像共5960张,并按照7∶2∶1的比例划分训练集、验证机、测试集,最终得训练集4172张,验证集1192张,测试集596张。训练过程中采用动态学习率且初始学习率设置为0.001,模型迭代次数设置为warmup_epochs=2、first_stage_epochs=50、second_stage_epochs=3000三阶段进行。网络采用多尺度训练(multi-scale training),训练时每迭代 10 次,就会随机选择(320,352,384,416,448,480,512,544,576,608)这几种分辨率图片其中之一作为网络的输入图片尺寸。
图5为使用DCGAN网络生成的桥梁裂缝图像,学习率设置为0.0002,优化器使用Adam。基于生成效率的目的,设置DCGAN网络相关参数使得能同时在一张生成图像上包含16张裂缝图像,图5为直接生成的同时包含16张桥梁裂缝图片的原始生成图像,其中图5(a)为初期生成的裂缝图像,图5(b)为后期DCGAN网络的D模块和G模块损失函数最小且趋于正常波动时生成的裂缝图像,可以看出网络模型后期生成的裂缝图像已经十分接近正常采集的原始裂缝图像。图6为后期生成的原始生成图像切割之后得到的单个桥梁裂缝图像。

图5 原始生成图片

图6 裁剪后的生成图片
目标检测中,通常用精确率、召回率、误检率、漏检率、准确率这5个指标来衡量不同目标检测算法的好坏,以下选用精确率(precision)和召回率(recall)组合的精确度(mAP)作为评价指标对YOLOv3网络改进前后的性能进行评价。mAP为多个类别的平均检测精度,由于只有裂缝一个类别,因此AP等同于mAP。表2为数据集聚类Anchor、FPN模块改进前后YOLOv3网络模型检测精度对比。可看出,原YOLOv3网络检测精度低于通过数据集聚类、FPN模块改进之后的网络精度,由于通过k-means算法对自建桥梁裂缝数据集聚类后可以得到更适用于裂缝图像的Anchor尺寸,检测精度提升0.0018;再在原始FPN模块中增加104*104尺寸的特征图并重新聚类Anchor,检测精度比原YOLOv3提升了0.0137,验证两种举措都能有效提升YOLOv3算法对桥梁裂缝图像的检测精度。

表2 YOLOv3改进前后精度对比
图7为改进的YOLOv3网络训练集和验证集的损失函数(Loss)可视化曲线,横坐标为迭代次数,纵坐标为Loss。从图中可以看出,验证集的Loss高于训练集,且偶尔会有较大波动,但训练集和验证集的Loss整体都呈下降趋势,并且在迭代次数在3000次附近时,两损失函数曲线整体呈平稳波动,损失函数已经收敛。此时停止训练,得到的网络模型检测精度达到0.9302。

图7 改进YOLOv3网络训练集与验证集损失函数曲线
使用改进的YOLOv3网络对不同类型的桥梁裂缝检测效果进行对比,如下图。桥梁裂缝类型分为4组,图8为DCGAN网络生成的裂缝,图9为细小且有背景干扰的裂缝,图10为普通裂缝,图11为复杂分布的裂缝。(a)、(b)、(c)分别为原图、使用原YOLOv3网络、使用改进YOLOv3网络得到的检测结果。

图8 DCGAN网络生成裂缝检测
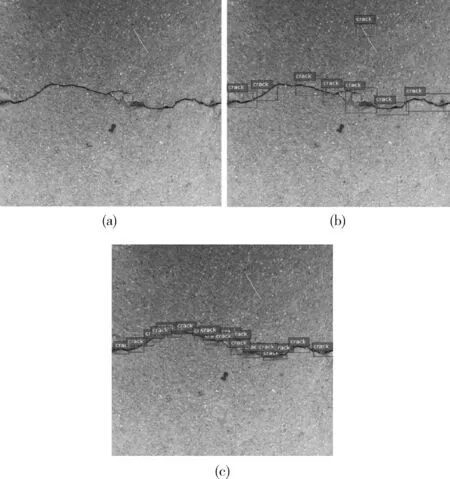
图9 细小有背景干扰裂缝

图10 普通裂缝
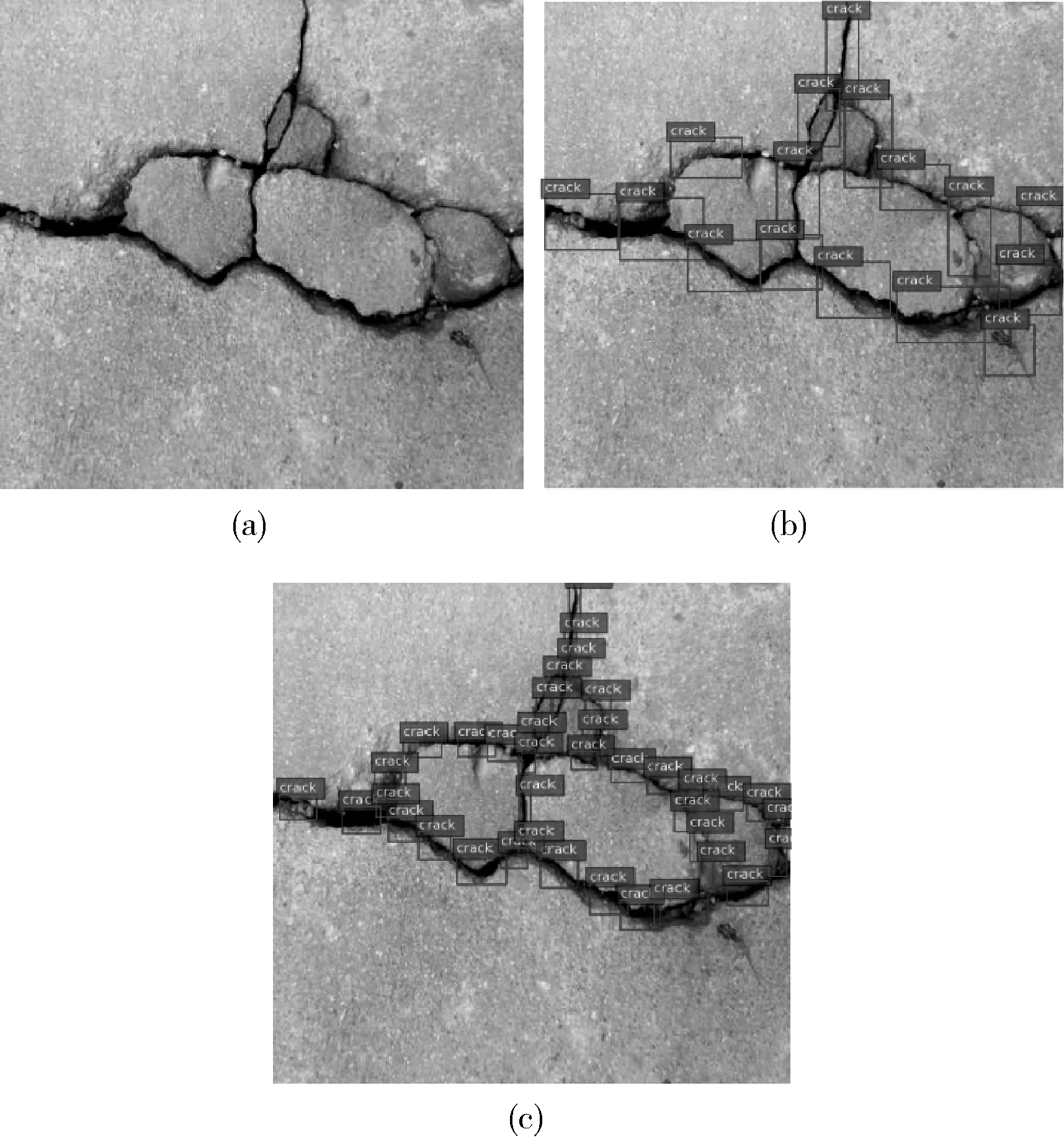
图11 复杂分布裂缝
通过以上检测结果可看出,对于图8的生成裂缝和图10的普通裂缝,YOLOv3网络改进前后的检测效果十分接近,整个裂缝都可以检测出来,没有误检或漏检的情况;对于图9的细小且有背景干扰的裂缝,原YOLOv3网络有一小部分裂缝未被检测到,且出现了将非裂缝目标检测为裂缝的误检状况,而改进YOLOv3将该裂缝很完整地检测了出来;对于图11的复杂分布裂缝,使用改进前后的YOLOv3网络都有一小部分裂缝未被检测到,即无论是使用原YOLOv3或改进YOLOv3网络都有漏检的情况,但相比较来说,改进YOLOv3比原YOLOv3漏检的情况少得多。
为验证改进网络裂缝检测的可靠性,采用横向对比手段对YOLOv1、SSD、YOLOv3、改进YOLOv3这4个网络的检测精度进行比较。以Recall为横坐标,Precision为纵坐标可将算法性能用P-R曲线直观表示出来,图12为4种网络P-R曲线图,P-R曲线与横纵坐标围城的面积即该网络的mAP值,面积越大则检测精度越高。由图可知,YOLOv1网络检测精度最低,SSD介于YOLOv1和YOLOv3之间,而改进YOLOv3网络检测精度最高,充分说明了改进后的YOLOv3网络性能较好,对于桥梁裂缝检测任务有较高的实用价值。

图12 不同网络P-R曲线对比
4 结束语
针对桥梁裂缝自身特征因素影响和传统算法裂缝检测效果不佳的问题,实现了基于卷积神经网络的桥梁裂缝目标检测方法。引入检测速度与精度较为均衡的YOLOv3目标检测网络,其突破了传统桥检算法。针对YOLOv3原Anchr尺寸不适应于桥梁裂缝的问题提出通过k-means聚类算法对自建数据集进行聚类,得到适用于桥梁裂缝的Anchr尺寸,并改进YOLOv3网络中的FPN模块,更利于小目标裂缝检测,从而提升YOLOv3网络整体的检测精度。但由于复杂分布裂缝特征较为杂乱,如何提升该类裂缝的检测精度还有待进一步研究。
猜你喜欢
China’s foreign Trade(2021年6期)2021-12-26
石油与天然气地质(2021年3期)2021-06-29
少儿美术(快乐历史地理)(2020年5期)2020-09-11
湖南教育·A版(2019年4期)2019-05-10
小学生学习指导(低年级)(2019年4期)2019-04-22
意林·全彩Color(2018年7期)2018-08-13
汽车与新动力(2017年3期)2017-06-29
山东工业技术(2016年15期)2016-12-01
中华奇石(2015年5期)2015-07-09
电子设计工程(2014年18期)2014-02-27
