
基于SSN的数据集预处理框架
2021-08-23 04:00徐中伟
计算机工程与设计 2021年8期
刘 琅,徐中伟,梅 萌
(同济大学 电子与信息工程学院,上海 201804)
0 引 言
随着卷积神经网络的发展,计算机检测癌细胞成为了可能。但由于病理学数据集是由专门的医学机构提供的,不同机构所给出病理图片的染色状态却不尽相同,这就对计算机辅助诊断(computer-aided diagnosis,CAD)带来了一定的影响。Cho等[1]的研究表明,图片分类这种数据驱动类型的工作,数据集的质量对于模型的分类精度有着直接的影响。因此,在训练之前,对数据集进行精细的预处理就显得尤为重要。
现存的染色预处理算法可以分为3大类。第一类为基于颜色匹配的方法,如Liu等[2]提出的通过缩小原图片和目标图片在各个通道上的距离完成颜色的匹配。但该方法没有考虑到单个图片中由于染料本身带来的颜色差别,会存在颜色错误映射的情况。
第二类方法主要针对特定染色区域进行反卷积,如Alsubaie等[3]提出的染色反卷积算法,该方法需要知道整张切片图像(whole slide image,WSI)中每种染色的参考染色矢量(reference stain vector,RSV)。由于需要人工介入,这些基于RSV的手动估计算法的应用规模受到了限制。
第三类方法为染色分离法,在这种方法中,每一个通道被单独分离开来进行染色。Bojnordi等[4]提出了一种基于色相-饱和度-密度(hue-saturation-density,HSD)的颜色模型,对于每一个染色类别单独进行色度和密度分布的转换。但该方法没有将切片组织结构的空间特征考虑在内,且目标参考图片需要由组织病理学领域的专家进行挑选。
针对这些问题,本文提出了一种基于染色风格归一化算法(stain style normalization,SSN)的组织病理学数据集预处理框架,该框架提取图片的内容特征和风格特征构建损失函数,搭建图片转换网络和损失函数网络对大量图片进行训练,将数据集中的图片转换到和目标图片相同的染色分布。
1 基于SSN的数据集预处理框架
1.1 预处理框架
整个框架如图1所示。该框架搭建了一个由图片转换网络和损失函数网络构成的风格转换网络。在训练阶段,固定一张染色图片为目标染色图片(即风格图片),对大量不同的内容图片进行训练,将目标染色图片的染色纹理编码在模型的权重之中;在运行阶段,利用已经训练好的、权值固定的染色迁移模型,将编码好的染色风格纹理快速覆盖到输入的内容图片上,完成染色风格的归一化操作。由于模型的权重在训练阶段已经固定,在运行时,可以快速的对大量内容图片进行染色风格的归一化处理,具有较高的实时性。
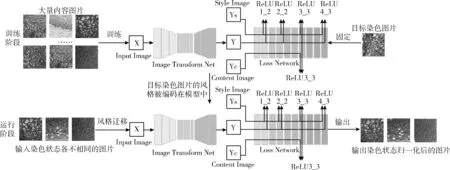
图1 基于SSN的组织病理学数据集预处理框架
1.2 染色风格归一化算法
该框架中的染色风格归一化算法是受到Gatys等提出的图片风格迁移算法[5]的启发。图片风格迁移是指,将一张图片的风格迁移到另一张图片上,同时保留该图片原有的内容信息。其中,提供风格纹理的图片称为目标风格图片(简称风格图片),提供内容信息的图片成为目标内容图片(简称内容图片)。输出的图片既保留了内容图片的结构信息,又有着风格图片提供的风格纹理[6]。
用图片风格迁移的思想,可以较好解释本文提出的染色风格归一化算法:在一个染色状态各不相同的组织病理学数据集(如图2所示)中,选定一张染色分布状态较好的病理学图片作为目标风格图片,数据集中剩余的其它所有图片均视为内容图片。对这些内容图片逐个进行染色风格迁移,那么输出的图片既包含了目标染色图片的风格信息(即染色分布),又保留了原内容图片的内容信息(即组织病理学样式),这样,整个数据集的染色状态便趋于统一,实现了染色风格的归一化处理。

图2 不同染色状态的病理学图片样例
1.3 风格转换网络
风格转换网络(style transform net)结构如图3所示,该网络由两部分组成:图片转换网络(image transform net)[7]和损失函数网络(loss network)[8]。首先,将图片输入到图片转换网络中,将输出的图片作为风格化的初始图片,输入到损失函数网络,联合目标内容图片和目标风格图片构建损失函数,通过梯度下降法不断寻找损失函数的最小值,训练图片转换网络。

图3 风格转换网络
1.3.1 损失函数网络
损失函数网络[8]包含4个卷积块,10个卷积层。在一个用于提取图片特征信息的卷积神经网络中,随着网络层次的不断深入,这些卷积层提取到的特征信息也有所不同,
根据特征信息重建后的图片也随之改变,它们从一个个具体的像素点转变成了一种更加抽象的、代表着图片内容和纹理信息的特征[5],如图4所示。我们可以从视觉上直观的看出高维特征和低维特征在表达图片信息时有着不同的侧重。我们把侧重于表达物体间排列关系的特征称为内容特征,侧重于表达图片整体纹理的特征成为风格特征。

图4 重建图片在不同网络层次的表达[5]
(1)内容特征
从图4中对内容图片的重建可以看出:对于内容特征,低层的特征信息只是准确地还原输入图片中的各个像素点,而高层的特征信息则更侧重于输入图片中各个物体间的排列关系,不会限制单个像素之间的位置。考虑到进行染色风格转化时,正是需要保持原内容图片中各个物体的排列关系、打破单个像素之间的约束从而达到风格化的目的,因此我们选取损失函数网络高层(ReLU3_3)的特征信息来表示图片的内容特征。
(2)风格特征
而对于风格特征,这里使用了一种原本被Gatys等[9]用于图片质地合成的算法[10]。该算法的主要目的是抓取图片的纹理信息,具体做法如下:在每一个block的最高层提取图片的特征信息,这些特征信息包含了卷积核在不同空间上映射出的特征响应,使用该方法可以较好提取出静态的、多维度的特征。从图4中对风格图片的重建可以看出,每一个block提取出的特征信息都能较好保留原图的色彩纹理和局部结构,图片内容的整体排列关系则被丢弃。因为图片中整体的排列关系已经通过内容特征进行抓取,所以风格特征只用专注图片的颜色纹理即可。因此,我们选取在每一个block的最高层(ReLU1_2、ReLU2_2、ReLU3_3、ReLU4_3)的特征信息来表示图片的风格特征。
关于损失函数的构建,早期的方法使用的是基于像素的损失函数[9],即计算两张图片像素之间的欧氏距离。但这种方法只能抓住图片间单个像素的差异,无法捕捉图片之间整体的感知差异。这里使用的损失函数是一种基于整体视觉感知的损失函数[11],我们称之为感知损失函数(perceptual loss),它不再专注于图片单个像素之间的差异,而是更加关注图片整体呈现出的视觉感官上的差异,即图片内容所表达出的语义差异[12]。经过预训练的损失函数网络已经可以学习编码图像的感知语义信息。而这些高级的语义信息正是损失网络用来衡量图片间风格差异和内容差异所需要的。
有了内容特征和风格特征,我们便可以构建内容损失函数和风格损失函数,两者加权之和为最终的损失函数[5]:
(1)内容损失函数
当我们进行图像风格迁移时,必须保证生成的图像在内容上与原内容图像一致。因此,要找到一个能够衡量两张图片在内容上的差异的参数,在优化的过程中对该参数进行约束。内容损失(content_loss)就是衡量原图像与内容图像在内容上差异的一个重要指标。我们在损失函数网络的 ReLU3_3层提取图片的高维特征作为内容特征,通过约束生成图像和内容图像在该层输出特征图的均方误差(means square error,MSE),可以使二者在 ReLU3_3层上输出相似的结果[5],从而保证生成图像和内容图像在 内容上的一致性。计算公式如下
(1)
其中,y′是输入图像,也就是生成的图像,y是内容图像,φ代表损失函数网络,φj(y)指的图像y输入到该网络以后的第j层的特征图,j在这里指的是ReLU3_3层,CjHjWj是第j层输出的特征图的尺寸。
(2)风格损失函数
图片之间的风格差异是通过风格损失(style_loss)来衡量的[9],我们使用Gram矩阵来定义风格损失。该矩阵的计算方法为:矩阵中某点坐标(c,c′)对应的值,就是特征图的第c张和第c′张图对应元素相乘,求和后除以CjHjWj的值,即
(2)

根据生成图像和风格图像在ReLU1_2、ReLU2_2、ReLU3_3、ReLU4_3输出特征图的Gram矩阵之间的MSE来缩小生成的图像与风格图像之间的风格差异。
1.3.2 图片转换网络
如表1,图片转换网络[7]可以分为3个部分:降维层、残差层和升维层。

表1 图片转换网络结构
先降维后升维主要有两个目的:第一,可以减小计算量。假设卷积核的大小是3×3,通道数为C,输入图片的大小为C×H×W,如果不进行下采样,进行卷积需要9HWC2次乘加运算;若是将卷积核的通道数提升至D×C个,输入图片的大小为DC×H/D×W/D,同样是9HWC2次运算,即在同样的计算代价下,网络变得更大了。第二,有效感知面积的增加[11]。通过下采样后,每一块区域连接的前一层的区域变大了,即输出图片中的单个像素点在上一层有着更大的有效感知视野。如此一来,单位面积下的像素所捕获的上一层的信息量就越大,下一层的图片就可以更好保存上一层图片的信息。大的信息量意味着生成风格化图片的每一个局部区域都是由上一层图片中更大面积的区域计算得到的,输出风格化图片的区域连续性更强。
降维层和升维层都是由3层卷积层构成的,其中两个stride不为1的卷积层是为了对图片上/下采样。这里以降维层为例,输入图片大小为256×256,第一个卷积层kernel size为9×9,stride为1,不改变输入图片的大小,通道数提升到32;第二个卷积层kernel size为3×3,stride为2,通道数提升至64,特征图的宽和高缩小为原来的二分之一;第三个卷积层kernel size为3×3,stride为2,通道数提升至128,特征图的宽和高缩小为原来的四分之一,即64×64。
升维层和降维层中间堆叠了5个残差块(residual block)。残差块的提出原本是为了解决网络的退化问题[13]。这里的目的是为保持图像在转换过程中前后的相关性,从而保证生成的图像不会和原内容图像有着较大的差异[8]。这样一来,输出的图片就不会偏离原始输入,原始图片的特征结构也在输出图片中得到保留。由于在图片风格转化的过程中,生成图片的大部分结构信息都是从先前图片那里获得的,因此残差网络非常适用于这种转换。
2 染色归一化模型的训练
实验环境配置见表2。

表2 实验环境配置
在训练图片转换网络时,需要不断调整风格权重与内容权重,二者的比值直接影响了最终生成图片的染色程度[11]。在进行染色风格迁移时,若风格权重和内容权重之比取的太小,就无法较好学习到风格图片的染色纹理,图片的染色风格改变较少,整个数据集就无法达到理想的染色归一化效果;若风格权重和内容权重之比取的太大,组织病理学图片就会逐渐趋于模糊,失去其原有的结构和纹理(即病理样式),这样的图片已经丢失了病理信息,失去了其医学价值。
图5(a)为风格权重和内容权重的比值设置过大时,生成的病理样式模糊的图片。其中,左边为目标染色图片,即理想情况下的染色状态;右边第一行是染色状态不一致的原始数据集,为输入;右边第二行是根据目标图片进行染色归一化后的图片,为输出。我们可以看到,输出的图片十分模糊,已经失去了原有的内容结构信息。经过不断测试,最终将风格权重style_weight设置为104,content_weight设置为102时,能在不改变病理学样式的情况下,得到较为染色效果较为理想的病理图片,如图5(b)所示:输出的图片染色分布状态相似且清晰地保持了其原有的组织病理学样式。通过该方法,我们将整个数据集中的图片都输入到染色迁移模型中,批量进行染色风格归一化操作。

图5 不同风格内容权重比时输出的染色图片
训练阶段和运行阶段的染色迁移时间对比见表3。由于训练是预先完成的,对时间的容忍程度较大,不需要具备实时性;运行阶段的速度达到了192 FPS,具有较高的实时性,可以应用于实际医学工作中大规模数据集的批量归一化预处理操作。

表3 训练时间和运行时间对比
3 染色归一化效果的验证
3.1 实验思路
图6展示了实验部分的主要工作:首先,使用本文提出的SSN算法对原有的14 000余张组织病理学数据集进行预处理,处理后的数据集记为数据集2,未处理的数据集记为数据集1。实验主要分为两个部分。

图6 实验思路
实验1:色彩空间的对比。将数据集1和数据集2中的图片映射到不同的色彩空间,对比两个数据集中图片颜色的分布情况。
实验2:模型分类指标的对比。为了验证染色风格归一化后的数据集是否能提高模型的分类精度,分别使用数据集1和数据集2对同一网络进行训练,得到两个不同的模型,分别记为模型1和模型2,对比这两个模型在测试集上输出的各种分类指标的优劣。根据控制变量法的思想,两个模型除了输入的数据集有差异外,其它因素均保持一致。在这里,图片分类网络由5层卷积层和一个全连接层构成。
3.2 数据预处理
首先,对数据集进行归一化和标准化处理。图像标准化可以把原始数据的不同特征映射到同一尺度,计算时对每一列数据,分别减去其均值,并除以其方差。经过标准化处理后的数据均值为0,方差为1,符合正态分布。对于归一化来说,这里采用的是最大最小值归一化,其目的是在保持原数据结构不变的情况下,将其缩放到0~1之间。
然后,将数据集划分为训练集、验证集和测试集,三者的比例为9:1:4。经过不断测试,最终模型的超参数设置如下:学习率1.5×10-4,batch size设置为64,采用Adam优化器,激活函数选取ReLu,Epoch为100。
3.3 实验评价指标
实验1的评价指标主要是图像中点的集中/分散程度,以此来判定数据集在不同颜色通道上的分布情况。
实验2的评价指标主要为ROC(receiver operating characteristic)曲线、AUC(area under the curve)面积,以及Accuracy、Precision、Recall和F1Score等。ROC曲线,又称为受试者工作特性曲线,是通过将输出样本的概率分别作为分类的门限阈值,得到一系列False Positive和True Positive的值,将这些值连起来得到的曲线,点取的越密集,曲线越平滑。AUC,即ROC曲线下的面积,是一个小于1的值,它表明了分类器预测的正样本高于负样本的概率。Accuracy、Precision、Recall和F1Score的定义如下
(3)
(4)
(5)
(6)
其中,True Positive(TP)为真正例,将正样本预测为正类的数量;True Negative(TN)为真负例,将负样本预测为负类的数量,False Positive(FP)为假正例,将负样本预测为正类的数量,False Negative(FN)假负例,将正样本预测为负类的数量。
3.4 实验结果分析
3.4.1 实验1
图7为数据集1和数据集2在RGB通道上颜色分布的对比。我们计算每张图片RGB这3个通道的数值(取值0~255),每组数值对应着三维坐标系中的一个点。遍历整个数据集,即可得到如图7所示的颜色分布。我们可以发现,右图中点的分布比左图更加密集,R、G、B这3个坐标的取值范围都更小,这表明归一化后的数据集在RGB通道上有着更加集中的色彩分布。类似的,我们将图片转化到HSL(Hue、Saturation、Lightness)通道,即可得到图8所示的HS通道颜色分布对比图。图像的HSL,即色相、饱和度、亮度,是一种将RGB色彩模型在圆柱坐标系中表示的方法。这里我们取色相H和饱和度S两个维度来绘制图像,绘制极坐标是为了更好展示图像的色相和饱和度分布情况。极坐标系的角度代表色相H,半径代表饱和度S,H和S的取值范围分别为0~360和0~1。从图中我们可以看出,就饱和度的分布情况来说,数据集2和数据集1并无太大差别;但是对于色相,数据集2比数据集1更加集中,这表明归一化后的数据集在HS通道上的色彩分布更加集中。

图7 RGB通道颜色分布对比

图8 HS通道颜色分布对比
图7和图8的结果从不同的色彩空间验证了,本文提出的SSN数据集预处理框架,缩小了数据集单个图片之间的色彩差异,使数据集在不同色彩空间上的颜色分布更加集中。
3.4.2 实验2
图9为训练过程中损失函数和分类精度随训练次数的变化曲线。其中,图9(a)对应模型1,图9(b)对应模型2。我们可以看到,在整个训练过程中,虽然训练损失、验证损失有小幅震荡,但最终收敛到一个较小值,衡量分类能力的各个参数随训练次数的增加而稳步提高。模型1和模型2在训练时并未表现出明显的差异。

图9 训练过程中参数随训练次数变化曲线
图10为测试阶段ROC曲线的对比。其中,图10(a)对应模型1,图10(b)对应模型2。ROC曲线越接近左上角,表明分类器的分类能力越好。我们可以看到,模型2得到的ROC曲线比模型1更接近左上角,有着更大的曲线下面积,二者的AUC分别为0.9835和0.9943。这表明模型2所得模型有着更高的TP和更低的FP,分类能力更优。
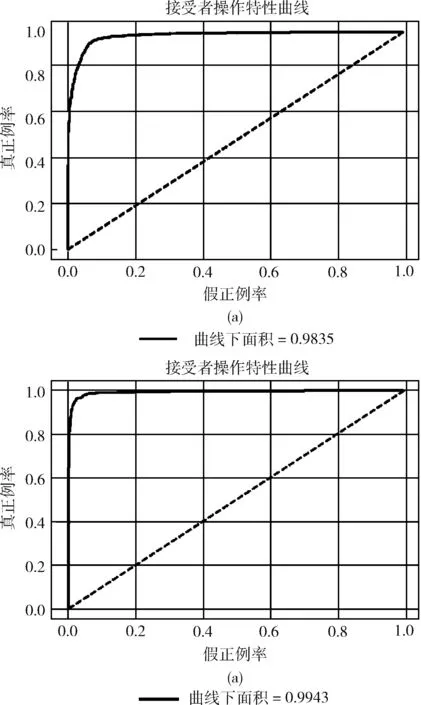
图10 模型1和模型2测试阶段的ROC曲线
图11和图12分别为模型1和模型2在测试集上输出的混淆矩阵。通过混淆矩阵可以判定模型的分类能力,聚集在对角线上的元素越多,说明模型正确分类的图片越多。可以看出,模型1在4518张测试图片中,得到True Positive 2301张,True Negative 1926张,分类的准确率为93.56%;模型2在4518张图片中,得到True Positive 2389张,True Negative 1970张,分类的准确率为96.48%,相较于模型1提高了约3%。

图11 模型1在测试集上输出的混淆矩阵

图12 模型2在测试集上输出的混淆矩阵
表4为训练阶段模型1和模型2模型的指标对比。可以看出,模型2的训练损失和验证损失均低于模型1,说明模型2的收敛情况更优。对于AUC、Accuracy、Precision、Recall和F1Score等参数,模型2均比模型1高出约0.5%~1%,说明训练阶段模型2的学习情况要优于模型1。

表4 训练阶段模型指标对比
表5为测试阶段模型1和模型2的指标对比。我们可以看出,相较于模型1,虽然模型2的AUC指标提升只有1.08%,但在识别图片的Accuracy上高出了2.93%,Precision高出4.24%,Recall高出2.10%,F1Score高出3.15%,即模型2在图片分类评价指标的各种参数上均比模型1高出约3%以上。这也验证了本文提出的组织病理学数据集预处理框架的有效性,它的确能提高数据集的质量,为图片分类网络带来更好的分类效果。

表5 测试阶段模型指标对比/%
表6和表7分别为模型1和模型2的分类报告。从这两张表中我们可以更详细看到两个模型分类能力的差别。不论是对于类别0还是类别1中的图片,模型1的Precision、Recall和F1Score均低于模型2;在宏平均(macro average)和加权平均(weighted average)参数上,模型2仍比模型1高出约3%。

表6 模型1模型的分类报告
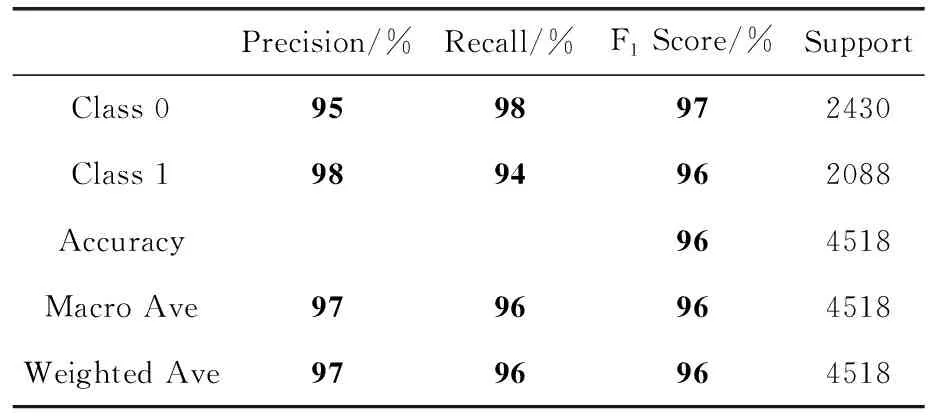
表7 模型2模型的分类报告
综上,模型2有着更低的训练损失,更理想的混淆矩阵,能够输出更多正确分类的图片,在AUC、Accuracy、Precision、Recall和F1Score等参数上,均高于模型1。这是因为本文提出的SSN预处理框架,能够缩小图片之间的染色差异,使整个数据集的染色分布趋于统一,该框架提高了数据集的质量,带来了更好的分类结果。
4 结束语
为了解决组织病理学数据集染色差异导致模型分类精度下降的问题,本文提出了基于SSN算法的组织病理学数据集预处理框架。该框架构建了一个风格转换网络,对医学数据集进行染色归一化处理,缩小了图片之间的染色差异。在实验部分,在不同的色彩空间观察处理前后数据集的色彩分布情况,并设置对比实验,分别采用处理前后的数据集对同一网络进行训练,得到两个不同的模型,从训练损失、验证损失、测试精度、AUC面积等参数定量分析染色归一化带来的影响。实验结果表明,经过该框架处理后的数据集,色彩分布更加集中,使用处理后的数据集训练得到的模型,在医学图片的良性、恶性检测工作中有着更高的识别精度。未来可以考虑扩大该框架的应用范围,将其应用到不同领域的数据集预处理操作中。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
数学小灵通·3-4年级(2021年5期)2021-07-16
作文小学中年级(2020年6期)2020-07-24
今日农业(2019年15期)2019-01-03
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
高师理科学刊(2016年8期)2016-06-15
中国组织化学与细胞化学杂志(2016年4期)2016-02-27
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
山西大同大学学报(自然科学版)(2015年1期)2015-01-22
