
结合注意力机制的火灾检测算法
2021-08-23 09:02彭煜民岳鹏超
计算机测量与控制 2021年8期
彭煜民,岳鹏超,张 丹,陈 乐
(1.南方电网调峰调频发电有限公司,广州 510630;2.广州市奔流电力科技有限公司,广州 510700)
0 引言
火灾一直以来都是全世界的重大威胁和灾害,早期预防以及快速检测出火灾是减少火灾发生及蔓延带来的严重危害的重要手段之一,因此能够及时并准确地预警火灾变得尤为重要。火灾的检测任务可分为火焰和烟雾两种目标的检测任务[1]。最初,探测火灾的方式是以感温探测器和感烟探测器的响应值作为探测结果,但感温探测器和感烟探测器的探测具有一定的滞后性[2],达不到早期预测火灾的目的,并且对环境变化不够鲁棒易受电磁干扰出现误报[3]。
近年来,基于计算机视觉的火灾检测取得了显著性进展[4-6],相对于单目标检测,火灾检测不仅需要检测出图像中的火焰目标,还需要检测出图像中的烟雾目标。早期的基于计算机视觉火灾检测方法将任务分解为火焰检测和烟雾检测两个任务,其利用火焰和烟雾在火灾发生过程中所表现出的静态外观信息如:颜色[7]、纹理[8]、形状[9]等或者利用火焰和烟雾在时序上的运动信息[10-13]构建出火焰或烟雾目标的判别性特征,然后依靠这些判别性特征检测出火焰和烟雾目标。大部分原有的火焰和烟雾检测方法依赖于手工制作特征,在早期数据量小的单类别数据集上取得了不错的效果,但在现实场景中火焰和烟雾表现出的颜色、纹理和形状等特征并不稳定且具有一定的差异性,使得手工设计特征任务更加艰巨[14],另外手工制作特征主要依赖于目标的先验信息,并不具有高抽象性和不变性,从而其检测准确率受到限制。另外,大多数火焰和烟雾检测方法是针对单火灾类型或固定场景提出,鲁棒性不佳,在光照、场景和火灾类型发生变化时其检测准确率明显降低,无法满足实际场景下应用的需求。
随着大规模图像分类数据集ImageNet的提出以及卷积神经网络在图像分类任务中的大放异彩,研究者们将卷积神经网络引入火灾检测任务中[15],文献[16]设计了一种用于森林火灾识别的12层卷积神经网络,其方法是先利用ImageNet数据集预训练网络,再利用自建数据集(训练集500张,测试集100张)进行训练和测试并且在训练过程中对网络的隐藏层进行dropout操作来降低过拟合的概率,其在自建的数据集上取得了不错的效果,但其自建数据集只有600张图片,利用迭代训练的方式去训练网络,仍然存在过拟合的可能,然后其数据集场景单一,在通用场景下鲁棒性不佳,另外,其最后的输出只是有火灾和无火灾的概率,并不包含火焰和烟雾目标的其他信息。文献[17]采用经典的卷积神经网络并结合了卷积和最大池化,其分类目标是确定图像是否包含火焰或烟雾,其通过12×12的滑动窗口在特征图上的移动,提高了检测的速度,相比文献[18]的方法而言其训练的数据集更多,覆盖的场景更广并且其网络更加轻量级,速度更快,但其分类的类别只有(火焰、烟雾、正常)3种类别,对于既有烟雾又有火焰的场景分类并不友好,另外最后的输出也不包含火焰及烟雾目标的位置信息,无法更精确感知火灾的状态。文献[18]通过分别对图片全局及局部的进行火灾检测,进一步提高了分类的精细程度,但其只是将火焰的检测结果作为火灾分类的依据,并没有识别出烟雾,在浓烟遮挡火焰的场景下的效果受到很大的影响,另外其也只是进行了分类工作,不包含火焰及烟雾目标的位置信息。
上述的火灾检测算法在火灾检测任务中取得了不错的效果,但也存在上述的一些局限性。为了缓解这些局限性,本文构建了一个多场景大规模且贴合现实场景的火焰和烟雾图像数据集,并且对火焰和烟雾目标的位置和类别进行了精细标注,其次本文提出了结合注意力机制的火灾检测算法用于火焰和烟雾检测,本文的模型先对烟雾和和火焰的颜色信息进行分析,在图像送入检测网络前,对火焰和烟雾目标的疑似区域进行关注,区分图像不同区域对检测结果的不同贡献,其次本文提取火焰和烟雾的多尺度特征,以捕获更加丰富的火焰和烟雾目标的信息。本文的方法在自建的多场景火焰烟雾数据集上取得了杰出的效果,验证了深度学习在火焰和烟雾检测任务上的可行性,同时也说明了本文工作的有效性。
1 方法
在可见光图像中,火焰和烟雾所表现出的颜色与周围环境对比往往具有显著的差异性,在现实场景中,诸多客观因素如燃烧物的材料、温度、燃烧的程度等影响着火焰和烟雾的颜色,使得火焰和烟雾的颜色具有特殊的分布规律。火焰在可见光图像中大部分呈现出明亮且突出的黄色和红色,而烟雾在火灾发生的初期大多数呈现出灰白色或者淡蓝色,随着火灾的延续,烟雾的颜色会从灰黑色变化成黑色。火焰和烟雾呈现出的颜色信息在火灾检测中起到了极其重要的作用[19-21]。但深度网络并不能充分利用火焰和烟雾表现出的丰富的颜色信息,为了充分捕获到火焰和烟雾的颜色信息,本文设计了注意力模块,先对图像进行火焰和烟雾疑似区域检测,在输入检测深度网络模型之前对火焰和烟雾疑似区域进行关注,最后由检测网络得到检测的结果。
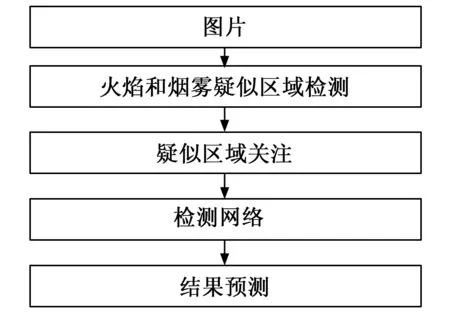
图1 本文火灾检测方法的流程
1.1 疑似区域检测
疑似区域的检测由火焰疑似区域检测和烟雾疑似区域检测两部分构成。
1.1.1 火焰疑似区域检测
利用火焰表现出的颜色规律,在RGB颜色空间中设置颜色过滤范围,对图像进行颜色过滤,将不在颜色范围内的像素点的像素值设置为0,将在范围内的像素点值大小保持不变,从而得到RGB颜色空间过滤的火焰图像。其在RGB颜色空间的过滤范围如式(1)所示:
(1)
式中,R0为像素点R分量的阈值,T0为|G-B|+|R-B|的阈值。将图像中满足式(1)规则的图像区域记为RFIRE,即为火焰疑似区域。
1.1.2 烟雾疑似区域检测
利用烟雾表现出的颜色规律,对图像进行过滤。烟雾区域在YUV颜色空间中的U和V分量之间的差异比其他非烟雾区域大得多,非烟雾区域像素值范围被压缩,所以采用YUV颜色空间像素滤色规则对图片进行过滤,像素滤色规律如公式(2):
Icolor(x,y)=
(2)
式中,U(x,y)和V(x,y)是(x,y)处像素点在YUV颜色空间上U分量和V分量的值;IRGB(x,y)为(x,y)处像素点在RGB颜色空间中的像素值;Tmax、Tmin为阈值。将图像中满足式(2)规则的图像区域记为RSMOKE,即为烟雾疑似区域。
1.1.3 火焰和烟雾疑似区域
通过颜色过滤后得到烟雾疑似区域RSMOKE和火焰疑似区域RFIRE合并得到颜色分析后的火焰和烟雾疑似区域Rcolor,其计算方式如公式(3):
Rcolor=RSMOKE∪RFIRE
(3)
1.2 关键区域关注
利用1.1节中得到的火焰和烟雾疑似区域,得到输入特征提取网络的重点区域,对重点区域进行注意力机制计算如公式(4):
Ii-attention=wiIi
(4)
式中,Ii-attention表示经过注意力机制后像素点i的值,Ii代表原图片像素点i的值,wi代表权重参数。
1.3 检测网络
YOLOv3算法是YOLO系列中应用最为广泛的算法。YOLOv3在采用残差的跳层连接的方式设计了一个全卷积网络(Darknet-53网络)来进行特征降采样,提取了多个尺度(不同大小)的特征图用作目标的检测,因而能更好的学习到小目标的细粒度特征,进一步提高了检测的效果。本文的检测网络基于YOLOv3,网络结构如图2所示。
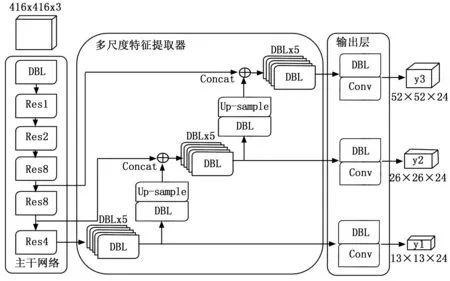
图2 检测网络的结构
K-means聚类算法旨在缩小类内数据的差异和扩大类间的距离,是一种应用广泛的无监督学习算法。本文采用K-means聚类算法针对于烟雾和火焰样本生成出初始化锚框。原有方法获得锚点的方式是通过计算欧几里得距离得到的,其锚框尺寸会影响到检测的效果,为了减少这种影响,本文通过IOU(intersection over union)距离公式来计算出预测框和实际框之间的距离,其计算方式如下:
d(box,centroid)=
1-IOU(box,centroid)
(5)
式中,IOU表示预测边框和实际边框的交并比值,box为实际边框值,centroid为K-means聚类算法计算出的聚类中心值。
为了获取更加丰富的目标边缘信息,本文摒弃原有公共数据集上聚类生成的锚框参数,而是通过在本文自制的烟雾和火焰数据集上聚类生成,以获得更加适用于火灾检测的锚框参数。根据本文设定的待检测目标类别的数目,计算通道数为3×(4+1+3)=24,其中括号内的“4,1,3”分别表示中心点坐标的4个预测量、1个置信度和3个目标类别的得分,最终输出的3种尺度特征图的大小分别为13×13×24,26×26×24,52×52×24。
2 实验结果与分析
2.1 数据集
当前火灾检测任务并没有开源的标准数据集,本文通过网络上采集到的开源的火焰和烟雾视频和图像以及结合自己拍摄一些特定场景的火焰和烟雾视频和图像,再对视频分解成帧之后,总共获得了50 000张包含火焰和烟雾的图像,经过筛选得到贴合现实场景的火焰和烟雾图像5 000张,以用作本文方法训练和测试的数据集。图3为本文数据集的部分数据示例。

图3 火焰和烟雾样本示例
本文对经过筛选过后的火焰和烟雾图像进行了精细的人工标注,标注的内容包括了火焰和烟雾两个目标的类别和定位信息,并以xml文件格式进行处理存储,然后将所有图像按照4∶1的比例进行随机划分,其中训练集为4 000张图片,测试集1 000张图片,图4为本文数据集的部分标注后的数据示例。

图4 标注后的样本示例
2.2 实验步骤与方法
实验数据主要来源于网络上采集到的开源的火焰和烟雾图像以及自己拍摄的图像,一共5 000张。实验的具体步骤为,首先将输入图片尺寸固定为416×416的大小;然后对图片中的火焰和烟雾疑似区域进行检测,其具体方法为将公式(1)和公式(2)中的R0设定为135,T0设定为20,Tmin设定为63,Tmax设定为178;
接着对检测出的火焰和烟雾疑似区域进行关注,其具体方法为对于关键区域的注意力参数设置为wi=1.5,即像素点i属于图像火焰和烟雾疑似区域,则wi=1.5,反之wi=1;
最后将进行火焰和烟雾疑似区域关注后的图像送入本文的检测网络进行检测,在检测网络中的训练过程中,学习率设为0.001,批尺寸(batch size)设为64。实验设备使用NVIDIA 1080 Ti GPU计算平台,在UBUNTU 18.04操作系统下使用Darknet深度学习框架搭建YOLOv3目标检测模型。
2.3 评价指标
为了评估检测模型的有效性,本文统一采用目标检测常用的评价指标mAP,其代表多个类别的AP(average precision)的平均值,其中AP为每个类别由召回率(recall))和查准率(precision)绘制的一条曲线下的面积。本文使用的AP默认为AP50,即预测框与目标实际边框(ground truth)的交并比(intersection over union)在大于50%前提下的单类别的平均准确率。mAP的值越大表示检测模型的总体识别准确率越高。
2.4 实验结果及分析
本文将数据集划分4 000张图片作训练集和1 000张图片作测试集。在模型训练过程的损失曲线图和测试过程的AP曲线如图5和图6所示。
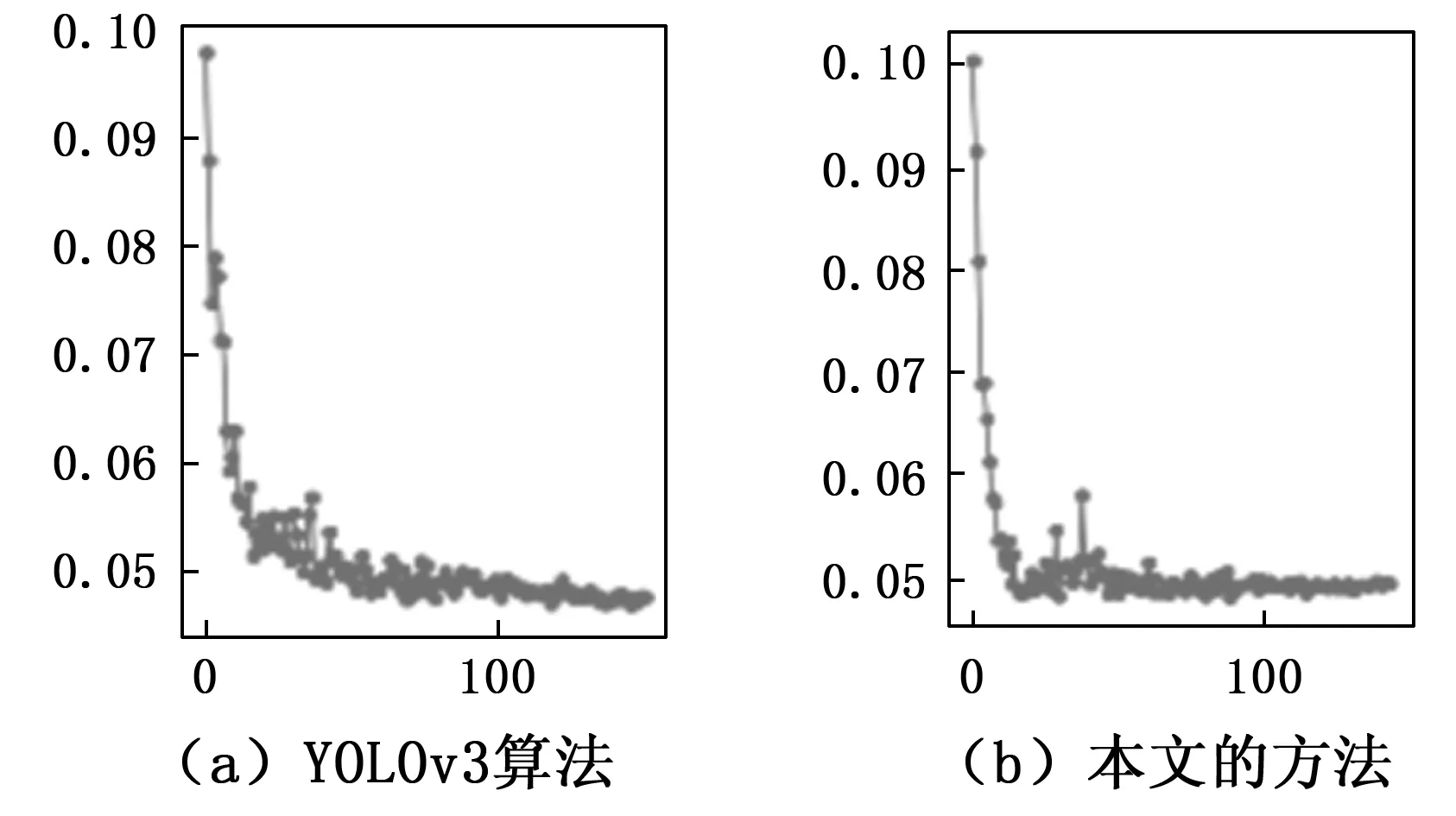
图5 模型训练过程的损失图,图中横轴为训练迭代的次数,纵轴为损失的大小
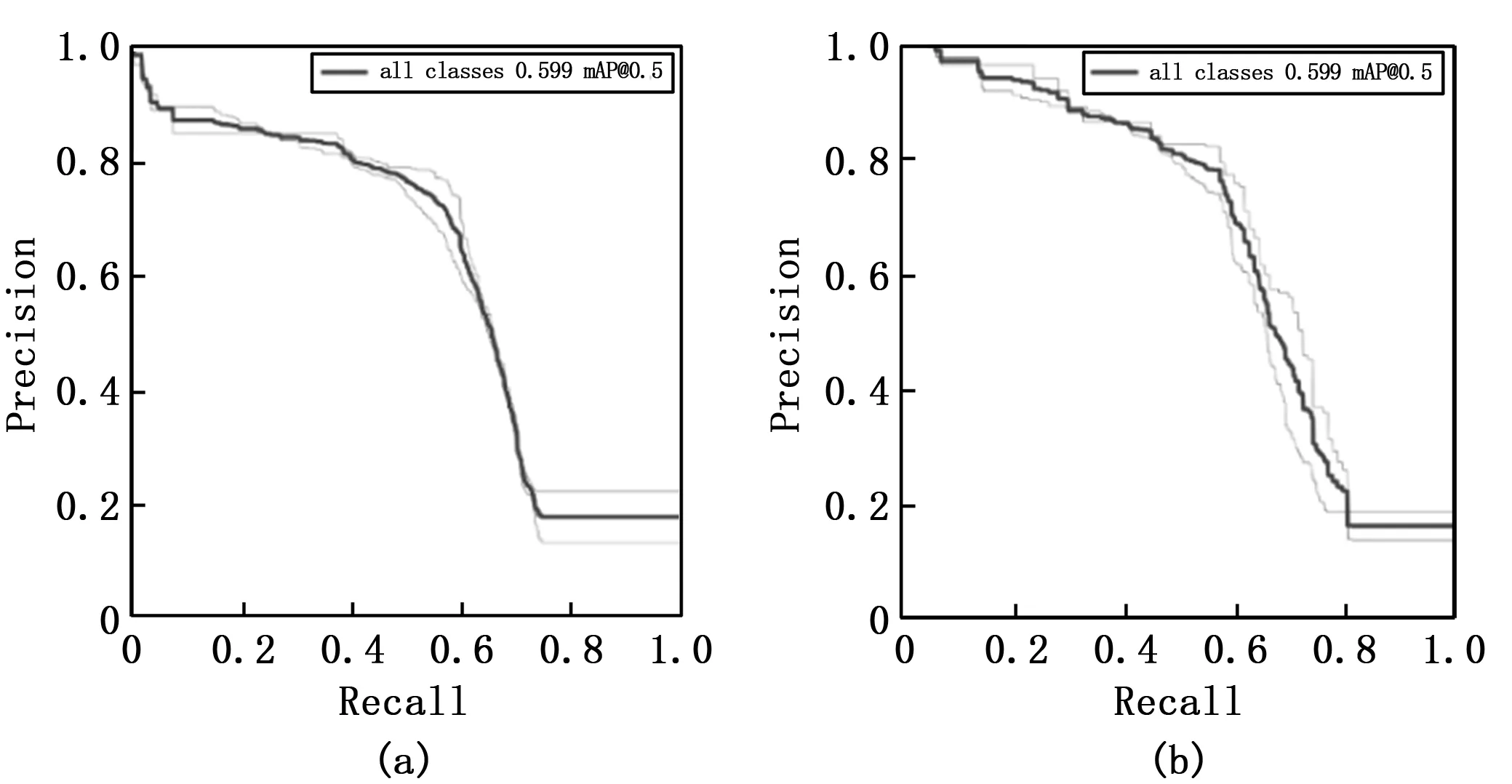
图6 测试过程中网络的AP曲线图,其中横轴为召回率,纵轴为查准率
从图5(a)和图5(b)的对比中,可以发现本文的方法相比于经典YOLOv3方法损失函数收敛的速度更快,也说明本文方法对于烟火疑似区域关注的有效性。
分别利用经典YOLOv3和本文的方法,在测试集上进行测试,分别计算各类目标的平均准确率,图6(a)代表的是传统YOLOv3算法,图6(b)代表的是本文的方法,并计算火焰和烟雾两类目标的mAP,测试结果如表1所示。
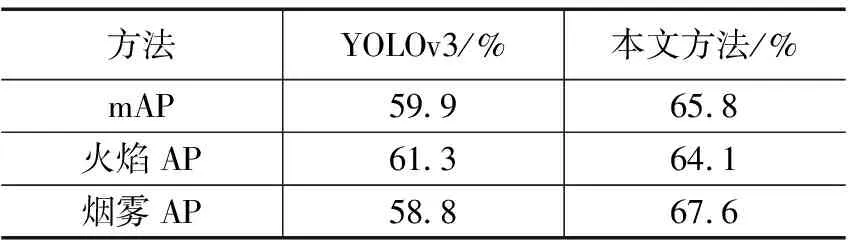
表1 测试结果
实验结果表明本文的方法在火焰和烟雾两类检测任务上均有良好表现。相比于经典的YOLOv3网络,本文的方法在火焰和烟雾目标检测的mAP由59.9%提高到65.8%,尤其是对烟雾目标的检测上AP提高了8.8%,验证本文方法对于火焰烟雾疑似区域的关注对于检测结果的有效性。
另外,在各种场景的火灾图像中,小尺寸的火焰目标较多,而烟雾对象由于其自身具有的扩散特性,往往比较难检测。但本文的方法在对于比较稀薄的烟雾也能实现准确检测,说明了本文的方法对于烟雾疑似区域的关注具有有效性,其次在图像中存在小目标的情况下本文的方法也能实现准确检测与识别,整体检测效果较为理想,测试结果示例如图7所示。

图7 测试效果
3 结束语
本文提出了一种结合注意力机制的火灾检测算法,本文的方法先对烟雾和和火焰的颜色信息进行分析,在图像送入检测网络前,对火焰和烟雾目标的疑似区域进行关注,区分图像不同区域对检测结果的不同贡献,其次本文提取火焰和烟雾的多尺度特征,以捕获更加丰富的火焰和烟雾目标的信息,本文的实验验证了结合注意力机制火灾检测算法在检测火焰和烟雾目标上的有效性,同时在本文构建的火焰和烟雾图像数据集上取得了较好的性能,尤其在小目标检测和稀薄烟雾上有显著提升,并且在检测速度上也满足了实时检测的需求。但火焰和烟雾属于非刚性目标,形状并不具有固定性,固定锚点的方式影响了目标检测框的准确性。如何提高火焰和烟雾目标检测框的准确性,将是未来的主要研究方向。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
小学阅读指南·低年级版(2021年3期)2021-03-19
学苑创造·A版(2021年2期)2021-03-11
华人时刊(2019年13期)2019-11-26
动漫星空(兴趣百科)(2019年5期)2019-05-11
当代陕西(2017年12期)2018-01-19
文学港(2016年12期)2017-01-06
文理导航·趣味课堂(2016年6期)2016-09-09
科学启蒙(2014年12期)2014-12-09
故事作文·高年级(2009年7期)2009-08-20
