
边缘环境中目标检测算法的应用研究
2021-08-19 11:11王云峰黎作鹏
计算机工程与应用 2021年16期
王云峰,黎作鹏
1.河北工程大学 信息与电气工程学院,河北 邯郸056038
2.河北工程大学 河北省城市公共安全信息感知与处理重点实验室,河北 邯郸056038
物联网技术的快速发展实现了对人们生产生活中无处不在的信息数据的获取,云计算与大数据技术则为物联网产生的海量信息数据的精确处理提供了计算资源[1]。“物联网+云计算”构成了一种能够实现普适多媒体服务[2]理念的计算系统架构。但随着安防网络规模的不断扩大,采集和传输的数据量激增,这种媒体数据处理模式面临重大的挑战:(1)海量数据传输使网络带宽资源不足;(2)海量数据处理使云端计算资源面临挑战,且难以满足安防信息处理的实时性需求;(3)海量数据存在的价值密度低但整体蕴藏的价值高,高价值数据难以获取。
为了满足公共安全行业对媒体数据处理的需求变化,需要对“物联网+云计算”的数据处理体系架构进行必要的改进,提高数据处理的实时性,缓解云中心的计算压力。此外,为使数据利益最大化,需要从大量的低价值密度的数据中准确高效地获取到高价值的数据信息。
边缘计算[3]作为一种分布式计算模式,通过充分利用边缘网络的计算和存储资源,能够极大地降低海量数据传输对网络带宽资源的需求,并满足安防对媒体数据处理的实时性需求。而基于深度学习的目标检测[4]是计算机视觉领域的一个重要技术,它可以快速对视频或图像中的物体进行分类识别,对于准确提取高价值的数据信息有重要意义。
1 国内外研究及相关技术概述
1.1 边缘计算相关研究
从计算的角度看,边缘计算是网络计算体系的一部分,是对云计算在边缘网络应用中的补充[5-6]。目前,边缘计算的研究主要集中在边缘计算体系结构、边缘计算资源虚拟化、任务卸载算法和深度学习在边缘计算系统的应用等方向。
深度学习作为计算密集型任务,需要大量的计算资源,而边缘网络中资源受限,因此如何将深度学习任务部署到边缘计算环境中是值得研究的问题。文献[7]提出了对终端节点上的深度学习模型进行分割,将计算子任务卸载至边缘服务器中,以此减缓终端节点的计算负担,但是网络阻塞的情况时有发生,这种方式可能会造成子任务丢失或超出任务的截止时间。通常情况下,边缘服务器相对来说拥有更加丰富的资源,因此可以考虑将计算密集型的任务放在边缘服务器。Ren等人[8]提出了一种基于边缘计算的监控应用目标检测体系结构,首先在终端设备对数据进行预处理,将深度学习算法Faster R-CNN在云端进行训练,然后在边缘服务器进行识别,实现了监控应用中的分布式、高效的目标检测。该研究充分利用了服务器端的计算资源,使终端仅处理一些预处理任务,但其所选用的算法在检测速度上较另一种算法有差距,此外该算法对小目标的检测效果并不能使人满意。鉴于此,本文使用更加优秀的SSD(Single Shot Multibox Detector)算法替代了之前的算法。
1.2 显著性区域检测
显著性区域检测是一种针对图像的预处理操作,即在图像被识别之前就能在某种程度上探知到其中的潜在对象。它所检测的对象是无类别的一般物体,且要求该物体有完整、闭合的边界。其研究领域主要分为局部区域检测、显著性对象检测、对象建议状态。其中,由Cheng等人[9]提出的BING(Binarized Normed Gradients)是一个数据驱动的对象边界生成算法,它可以在资源轻量级终端上以300 frame/s的速度检测到潜在对象的边界框,利用该算法可以轻松地区分出图像中的对象和背景,但是在实际应用中会存在定位偏离的情况。基于此,本文增加了对定位框的矫正过程,提高了定位的准确性。
1.3 基于深度学习的目标检测算法
目标检测的任务是找出图像中所有感兴趣的物体(目标),并确定它们的位置和类别。基于深度学习的目标检测有两类主流的算法:一类是基于候选区域的RCNN系列的算法(two stage),包括R-CNN[10]及其改进算法Fast R-CNN[11]、Faster R-CNN[12]、Mask R-CNN[13],这些算法均采用“候选区域+卷积神经网络+分类”这一基本思路,不断在检测精度和速度上进行改进。但整体而言,这些网络的实时性较差,很难满足实际需求。另一类则是将目标检测转换为回归问题的算法(one stage),例如YOLO[14]及其相应的算法改进YOLO9000[15]和YOLOv3[16],其基本思想是把生成候选区域的步骤省略,直接将特征提取与目标分类在同一回归网络中加以实现,使得检测速度有了大幅度提升,但其定位精度和召回率较低。Liu等人[17]借鉴了YOLO和Faster R-CNN的优势,提出了SSD目标检测算法,网络结构如图1所示,其中主干网络结构是VGG16。SSD继承了YOLO将检测转化为回归的思想,一次性完成目标的检测与分类,又基于Faster R-CNN中的anchor机制,提出了相似的Prior Box,另外加入了特征金字塔,可以在不同感受野的特征图上预测目标。因此,SSD可以满足实时高效的检测要求。
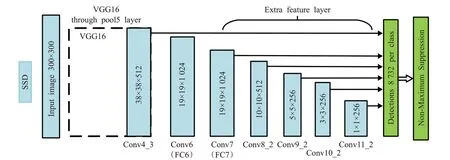
图1 SSD网络结构图Fig.1 SSD network structure
但是SSD仅仅依靠浅层网络Conv4_3层来提取小目标特征,该层几何信息较为准确,但缺乏深层网络所具备的语义信息,因此SSD对于小目标检测效果不佳[18]。Fu等人[19]针对这个问题提出了DSSD算法,将SSD中的主干网络VGG16改为ResNet-101,增强了网络的特征提取能力,其次采用反卷积操作提取到深层次特征,然后与低层特征进行融合,有效地提高了小目标的检测能力。但网络深度的增加和复杂的反卷积操作,使计算量大幅度提高,严重降低了检测速度。Li等人[20]基于SSD提出了FSSD算法,将Conv7与Conv9_2提取的特征与Conv4_3进行拼接,使高维信息与低维信息进行融合,在不严重影响检测速度的情况下提高了检测的精度,但是Conv7层引入了较多的背景噪声。文献[21]为了选择合适的融合层,利用反卷积操作对不同层的有效接收域进行了探索,认为Conv5_3和Conv6的有效接受域较大,然而Conv6层比Conv5_3层引入更多的背景噪声,因此选择将Conv5_3层与Conv4_3层进行融合,但是网络结构中仍然没有引入高层网络的语义信息。借鉴前人的研究,本文对于小目标检测的改进策略以SSD算法为基础,利用特征融合方法融合不同层之间的信息以增强小目标的检测率。
综上所述,如何充分地利用边缘计算体系中的各类资源来提高图像处理的实时性以及对小目标检测的精确性是本文的重要研究方向。为此,首先提出了基于边缘环境的安防图像处理系统架构,在此基础上针对不同架构层的计算特点提出了不同的图像处理方式。尤其在边缘服务器层,提出了针对安防图像中小目标检测的实时性算法,并最终通过实验验证了算法的性能。
2 边缘环境中的目标检测算法研究
2.1 边缘环境中目标检测应用体系架构
边缘计算的体系架构多依据应用的不同而有所侧重。针对安防图像中的目标检测应用,为了能够有效地利用边缘网络体系的各种计算资源,本文依托“终端网络层-边缘服务器层-云层”这样的边缘网络体系架构开展目标检测的研究,并设计出该应用的体系架构,如图2所示。由于安防中图像数据量巨大,且无线通信环境存在不稳定性,容易造成数据丢失。因此,在终端网络层对采集到的图像首先进行初步的显著性检测,然后对图像中的不同检测区域采用不同的压缩率进行数据压缩,以降低网络传输的数据量;在云层,负责执行深度学习算法的训练任务,并将训练结果交付边缘服务器用于运行目标检测算法;在边缘服务器层,执行深度学习算法对终端节点上传的图像进行识别,并将需要进一步挖掘计算和长期存储的数据通过核心网络上传至云层。
该框架的优势主要体现在以下三方面:(1)显著降低部署成本。在网络边缘,终端设备与服务器通过无线或局域网连接,不必部署专用的高速光纤网络。(2)提高检测任务的实时性。与将数据发送到遥远的云端相比,不需要经常通过主干网络与云交互,在本地就可以实现实时检测。(3)充分利用终端冗余的计算能力。在有冗余计算能力的终端设备上对图像预处理,减轻了服务器的压力。本文在此基础上开展目标检测的算法研究。
2.2 终端网络层算法设计
2.2.1设计思路
由图2可知,边缘终端设备需要将采集到的数据通过无线网络传输到边缘服务器。但由于无线传输存在不稳定性,可能会造成数据丢失,为了不影响图像的识别精度,需要选择合理的方式对图像进行选择性压缩。边缘服务器的目标检测主要针对图像中的目标区域进行分析,因此本文在终端网络层区分图像的目标区域和背景区域(非目标区域),对于目标区域不压缩或少量压缩,而对于背景区域则进行充分压缩。通常情况下,目标区域在图像中占比较少,因此对图像进行选择性压缩能够在保证服务器检测精度的同时减少数据传输量。

图2 基于边缘计算的目标检测应用架构Fig.2 Object detection application architecture based on edge computing
虽然终端设备上资源受限,但仍存在冗余的计算能力,在这些冗余的计算能力上首先选择轻量级、高速率的BING算法进行显著性对象检测,然后采用可以指定图像上任意压缩区域的JPEG2000标准对图像中的对象区域和背景区域进行不同程度的压缩。BING算法在对图像进行检测时存在检测框与真实目标偏离较远的问题,由此造成了检测框定位偏移的情况。在本应用中可能会导致部分目标区域被充分压缩,影响后续的目标检测,难以满足实际场景中的应用需求。因此,为了能够对复杂场景下的目标区域与背景区域进行准确区分,本文增加了对BING算法定位矫正的过程。
2.2.2改进策略
本文对BING算法的改进主要体现在检测框的位置矫正。检测框的偏移一般可分为水平偏移和垂直偏移,借鉴文献[22]的思想本文将BING算法提取到的目标区域扩大至原来的2.25倍(长宽分别扩为原来的1.5倍),对该区域进行中值滤波,除去噪声干扰,利用Sobel算子提取该区域的边缘信息,并根据矩不变自动阈值分割算法得到使分割前后的图像前三阶矩都相等的最佳边缘分割阈值T,然后分别在阈值分割后的图像的水平和垂直方向进行投影,如式(1)、式(2)所示。

其中,f(x,y)为该点的像素值;G(x,y)为1表示该点为目标像素点,为0则表示该点为非目标像素点;S为该区域内的边缘响应值;xi、xj为滑动窗口的左右边界,yi、yj为滑动窗口的上下边界,且满足式(3):

其中,W与H分别表示检测框的宽度和高度;xa与xb分别表示扩大区域的左右边界,ya与yb分别表示扩大区域的上下边界,如式(4):

将检测框在扩大后的区域内从点(xa,ya)进行水平方向和垂直方向的平滑移动,根据式(5)计算其在不同方向坐标下的响应值。响应值最大表示该区域内包含有最多的目标像素,最有可能为目标区域。

其中,S(Δx)、S(Δy)分别表示检测框在水平方向和垂直方向上分别移动Δx、Δy像素后该区域内的边缘响应值。
计算出检测框在水平方向和垂直方向的偏移量,可以得出矫正后检测框的位置坐标,即为(xa+Δx,ya+Δy)。
2.2.3数据传输建模
考虑到实际网络中可能会存在数据延迟和数据丢包等现象,本文在终端网络层建立了图像压缩率与信道传输性能以及数据延迟之间的关联模型。
设网络中的数据延迟为:

其中,τ1表示反应延迟,即数据从产生到开始传输之间的延迟,一般为微秒级;τ2表示传播延迟,每3 km延迟10 μs;τ3表示发送延迟,为待传输的数据量与传输带宽之间的比值;τ4表示路由和排队的延迟,正常范围在毫秒级别,当发生网络拥塞时会突增。
由此可见,正常网络中的数据延迟主要受发送延迟的影响,当网络负载过大时,排队延迟也会增加,因此当发生数据延迟过大时,可以动态调整数据的压缩率来减少数据的传输量。
设S(T)={Si,i=1,2,…}代表在时间段T上需要向边缘服务器传输的图像总数。这里Si=Oi+Ni,其中Oi代表图像Si中目标区域的数据量,Ni代表非目标区域的数据量。进一步,γ代表Si中目标区域图像的压缩率,η代表非目标区域图像的压缩率,则目标区域压缩后的数据量为O×γ,非目标区域压缩后的数据量为N×η,图像Si经过压缩后的数据量如式(7)所示:

网络中的可用带宽为C,则:

当网络中的数据延迟过高(阈值T=2 000 ms)或丢包率过大的情况下,可以根据式(9)动态调整图像的压缩率,减少数据传输量。

2.3 边缘服务器层算法的设计
2.3.1设计思路
为了能够在边缘服务器上实现高效的、实时的目标检测应用,一种合理的方案是采用基于深度学习的SSD算法。SSD算法与Faster R-CNN算法相比具有明显的速度优势,且检测精度能够和YOLO媲美。SSD虽然在VOC数据集上取得了不错的效果,但它对于小目标(像素区域小于30×30的目标)的检测效果不佳。如果直接将其应用在安防图像的目标检测中,极有可能会造成目标漏检的问题。SSD采用的多层检测每一层的输出信息都是独立的,忽略了不同层之间的信息传递,且浅层网络中缺乏高语义信息,因此通过将卷积前向计算中捕获的高语义信息传递回较浅的特征层将提高小目标的检测性能。基于这一原理,本文设计了一种基于特征融合的2FSSD(Feature Fusion-SSD)算法。
2.3.2改进策略
为了进行特征融合,需要解决三个问题:(1)选用哪些特征层进行融合?(2)采用何种方式进行融合?(3)不同特征层之间如何融合?
本文算法采用的基本策略:
(1)由于Conv5_3特征层具有较大感受野而Conv10_2特征层具有较强的语义信息,本文将SSD主干网络中的Conv5_3特征层和Conv10_2特征层与原本提取小目标特征的Conv4_3层进行融合,形成新的特征提取层Conv'4_3来增强对小目标特征的提取能力。
(2)常用的特征融合方式有两种,一种为拼接融合(Concatenation),一种为元素求和(Element Wise-Sum)[23]。拼接融合要求待融合的特征图有相同的分辨率,通过将原始特征直接拼接增加特征图的深度,融合过程中原始信息不会丢失,但是带来的计算量大。元素求和的方式要求特征图分辨率和深度全部相同,通过将各个对应元素相加求和得到能反映出原始特征的新特征,但是可能会损失原始特征的部分信息。由于能够有效地降低计算代价,本文采用该方法进行特征融合。
(3)为了保证待融合的特征层之间分辨率和深度都相同,要对Conv5_3和Conv10_2特征层进行调整。
特征融合的示意图如图3所示,操作步骤如下:
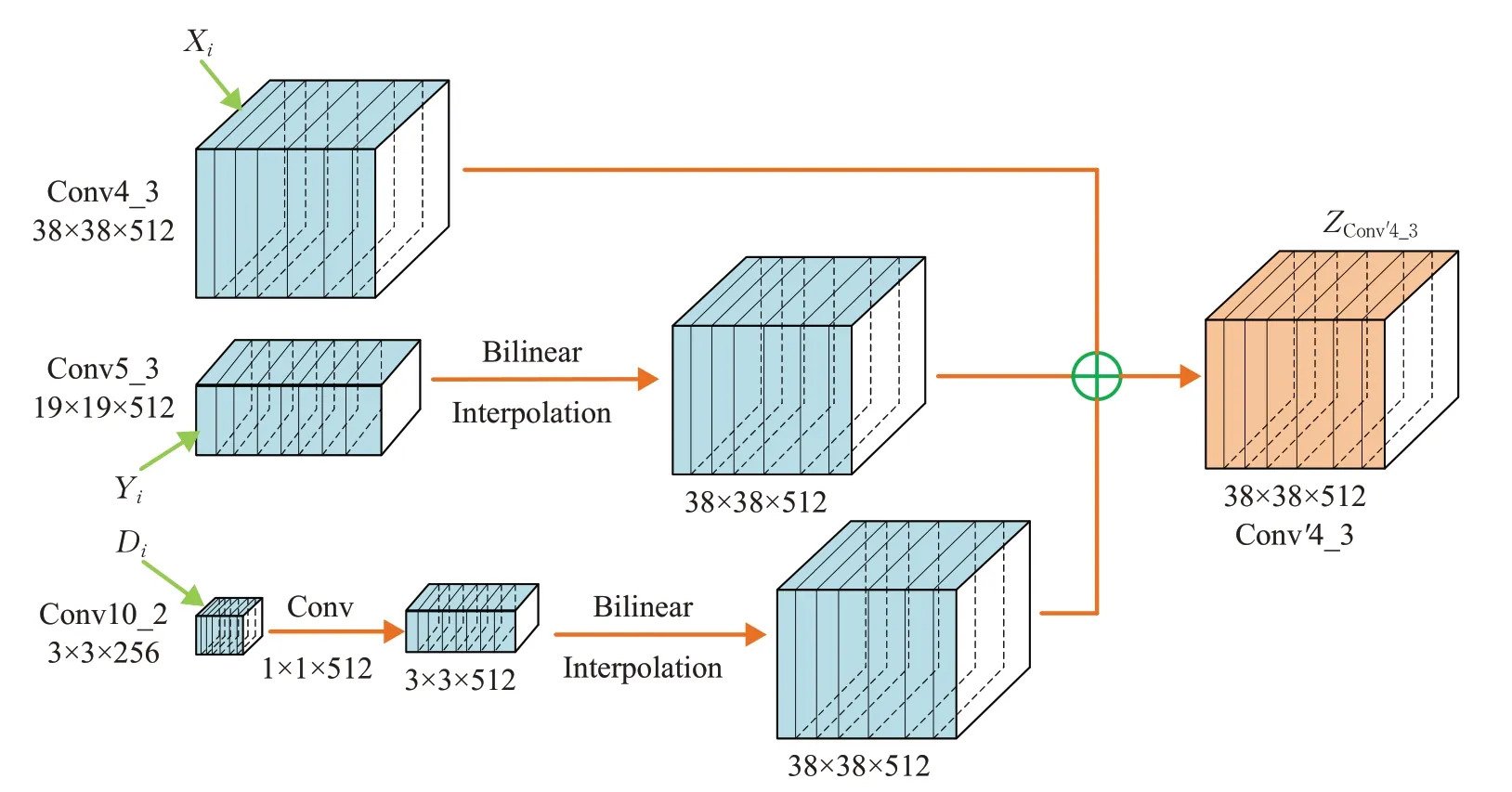
图3 2FSSD网络特征融合示意图Fig.3 2FSSD network feature fusion diagram
步骤1使Conv5_3特征层与Conv4_3特征层分辨率相同。双线性插值(Bilinear Interpolation)[24-25]是一种计算速度快、插值特性好的特征图放大方法,其核心思想是在两个方向分别进行一次线性插值。本文将Conv4_3层提取的图像特征作为目标图像,将Conv5_3层提取的图像特征作为原图像,对Conv5_3特征层的图像进行插值。
假设已知原图像的大小为srcW×srcH,Conv5_3特征层的srcW=srcH=19;目标图像的大小为dstW×dstH,Conv4_3特征层的dstW=dstH=38。则通过式(10)可以计算目标像素在原图像的位置。

设待求像素点的坐标为Q(x,y),则与其相邻的像素点坐标分别定义为M11(x1,y1),M12(x1,y2),M21(x2,y1),M22(x2,y2),其中x1=x-1,y1=y-1,x2=x+1,y2=y+1,如图4所示。根据式(11),首先在x方向对点M11、M21进行一次线性插值,可以求出点R1的像素值f(R1),对点M12、M22进行一次线性插值,可以求出点R2的像素值f(R2);再根据式(12),在y方向上对R1、R2进行一次线性插值,进而可以求出目标点Q(x,y)对应的像素值f(Q)。

图4 双线性插值原理示意图Fig.4 Schematic of bilinear interpolation

式(10)确定目标图像像素点与原图像像素点的对应关系,式(11)、式(12)确定目标图像像素点的值,由此可以完成图像的插值过程。然后对Conv5_3特征层采用双线性插值将其分辨率变换为38×38,再进行批归一化(Batch Normalization,BN)处理来增强网络的鲁棒性,防止网络的权重偏置溢出。
步骤2Conv10_2特征层的分辨率为3×3,深度为256,为了保证能够与Conv4_3层融合,先对Conv10_2特征层采用1×1的卷积核进行卷积,将其深度变换为512,然后采用双线性插值和批归一化处理,变换后网络层可以保证与Conv4_3有相同的特征图尺寸和深度。
步骤3以元素融合方式对Conv4_3层、Conv5_3层和Conv10_2层进行融合,如式(13)所示。

式中,ZConv′4_3为新形成的Conv'4_3特征层;Xi为Conv4_3层提取的feature map;Yi为Conv5_3层提取的feature map;Di为Conv10_2层提取的feature map;Ki为卷积核参数;c为各层的通道数。由此,可以得到基于SSD改进的网络2FSSD,其网络结构如图5所示。

图5 2FSSD网络结构图Fig.5 2FSSD network architecture diagram
3 实验
3.1 实验介绍
本文使用VOC2007和VOC2012数据集的训练部分共16 551张图片作为训练数据集,使用VOC2007的测试部分共4 952张图片作为测试集。
根据本文设计的边缘计算目标检测架构,将检测算法的训练过程在云端进行。训练参数设置bich_size为16,初始学习率lr为0.001。在80 000次迭代训练之后,每隔20 000次,将学习率调整为原来的1/10,总迭代次数设置为120 000。使用均值平均检测精度和检测速度作为模型的评价指标。平均精度(AP)表示算法对某一类别识别的好坏程度,均值平均精度(mAP)表示算法对所有目标类别识别的平均好坏程度;检测速度用来衡量算法的实时性。
3.2 图像处理效果对比分析
本文选取了图像在各个阶段的处理效果图,并进行了对比分析。图像在不同阶段的处理效果如图6所示。
从图6(b)可以看到,BING算法能检测出图像的目标区域,但存在位置偏移。图6(c)由于对检测框进行了矫正,避免了这种情况。图6(d)是在图6(c)的基础上压缩形成,可以看到图6(d)中图像的背景区域较为模糊,因为本文以选择性压缩的方式,对背景区域采用了60%的压缩率,减少了原始图像的数据。从图6(e)中可以看出,SSD算法可以准确检测出图像的目标,并能够对其进行准确的分类,但是图中红衣女孩和带帽的老人因为目标区域较小造成了漏检现象。图6(f)是采用特征融合的2FSSD算法进行检测的效果,小目标的信息表达更加充分,因此检测出了图像中的小目标。图像中的红衣女孩由于在终端层被作为背景进行了压缩,造成了图像数据损失,因此识别度不高。

图6 图像处理效果对比图Fig.6 Comparison of image processing effects
3.3 实验结果与分析
3.3.1终端层算法结果与分析
本文对终端层算法的性能从检测时间与准确率两方面进行了对比,如表1所示。

表1 终端层算法性能对比结果Table 1 Algorithm performance comparison results of terminal layer
算法1直接使用BING算法,算法2在BING之后增添了对检测框矫正的过程。本文使用了这两种方法对VOC数据集进行检测,并计算出平均检测时间。另外,从这两个检测结果中分别抽取了同样的300张图片来统计检测框是否完全选中了目标。从表1可以看出,检测框的矫正过程相比BING算法计算量稍大,消耗的时间较多,但却使得检测的准确率得到了提高。
3.3.2边缘服务器层算法结果与分析
将本文算法与原始算法SSD[18]及其典型的改进算法DSSD[19]、FSSD[20]作为对比实验,比较了不同算法在检测精度与检测速度方面的差异。检测准确率对比图如图7所示。

图7 不同算法对不同目标的检测精度对比图Fig.7 Comparison of detection accuracy of different algorithms for different objects
从图7可以看出,本文提出的2FSSD算法由于采用了特征融合的方式,与原始的SSD算法相比,检测精度提高了2.3个百分点;与DSSD算法相比,检测精度仅提高了0.7个百分点;与FSSD相比,本文算法所融合的特征层含有更加丰富的语义信息,且终端层对图像的预处理减少了一定的背景信息,因此在检测精度上也略有提升。另外,由图中数据可以看出,本文所提算法在鸟、船、瓶子、椅子、盆栽、电视等6类小目标上的平均检测精度为66.9%,相比于其他算法分别提高了3.8个百分点、1.1个百分点、1.8个百分点,其中鸟和瓶子的检测精度提升较为显著。可见,本文算法对小目标的检测精度有明显的提升。
在检测速度方面,本文算法与SSD、DSSD、FSSD算法的检测速度分别为27.3、35.7、9.3、29.5 frame/s。与SSD算法相比,增加了特征融合操作,因此在检测速度上有所下降;与DSSD算法相比,没有采用网络层次更深的ResNet-101网络,也没有采用复杂的反卷积操作,因此检测速度有大幅度提升;与FSSD算法相比,仅是融合了不同的特征层,因此检测速度相差不大。
综上所述,本文算法与其他相关算法相比,在检测精度上(尤其对小目标的检测)有明显提高,而在检测速度上也能够满足实时性检测的要求(>25 frame/s)。因此本文算法满足了安防领域中对图像数据实时高效的检测要求。
4 结束语
本文针对利用深度学习算法在边缘计算环境中对安防图像进行目标检测的应用,提出了边缘环境下的目标检测分层架构。在此基础上,对终端层的显著性区域检测算法BING改进,提高了其定位准确性;在边缘服务器层提出了针对安防图像中小目标漏检问题的改进算法2FSSD,并测试了其在小目标检测方面的性能,结果表明该算法在检测准确率方面相较于其他算法有所提高,并能够达到实时性检测的要求。因此,本文算法可以适用于安防中的图像目标检测。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
作文小学中年级(2020年6期)2020-07-24
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
通信产业报(2016年44期)2017-03-13
河南科技(2014年23期)2014-02-27
自然资源遥感(2014年3期)2014-02-27
意林(2011年10期)2011-05-14
雕塑(1999年2期)1999-06-28
