
基于借阅行为量化和数据挖掘的图书采购推荐系统的设计与应用
2021-08-19 08:07牛兰金
内蒙古科技与经济 2021年13期
姚 震,孔 月,牛兰金
(山东农业大学 图书馆,山东 泰安 271018)
高校图书馆如何构建全面而又富有特色的文献资源是巨大挑战。现行资源采购模式是在现行招投标体制下,由于合同定价较低,因而书商提供的图书普遍低于合同折扣,意味着对于超过合同折扣的图书,书商不可能主动提供订单,而这部分图书往往是质量较高、价值较大的图书。另外,微观上采购人员面对海量条目时对影响采访质量的因素认识不准确,宏观上采访原则缺乏可操作性、采访策略缺乏有效性、采访实践缺乏可行性等因素,都制约着图书采购的质量和工作效率。设计完成一套方便有效的自动化工具来辅助采购员筛选出适合读者使用、适应学校专业设置和教学科研需要图书是本文所做的一次探索。
该工具的设计首先考虑基于借阅行为记录的挖掘,找出真正符合本馆基本情况,并能揭示本馆特点的数据和知识。国内图书情报领域对数据挖掘的研究和应用现状、研究热点和重点,多集中在关联规则的数据挖掘,另外如决策树或贝叶斯分类、序列模式挖掘、协同过滤等算法也是常用方法。后续研究发展多以此为基础,增加诸如语义或情感分析等参考模型。高校图书馆当前主流管理系统没有数据挖掘的功能,且统计分析以借阅次数为基础,加以分类号、典藏或借阅日期等数据项计算借阅次数,缺乏灵活的数据组织方式。借阅行为虽多具有读者的主观性,但综合分析数据时更容易总结出随机性和时间规律等属性特点。利用借阅行为所包含的数据信息,借鉴网络行为的量化方法,根据借阅行为的特点和规律,设计了借阅行为的量化计算公式。计算借阅行为有效性的值,结合MARC数据中的信息,探寻有效的分析模式。最后依据B/S架构部署该服务,使Browser端实现上传书单文件,Server端处理完成后将文件以FTP链接形式返回给Browser端,采购员可根据经验调整书单后确定采购清单。
1 数据预处理与挖掘
借助Toad软件和PowerDesign软件解构从汇文LIBSYS的Oracle中导出的数据库文件,得到数据库的表结构和各表之间的关系。解构后的数据库可以看到有读者表、MARC记录表、财产表等,其中借阅历史表的部分结构,如图1所示。

图1 借阅历史表结构示例
本次实验预处理借阅记录852 874条,每条数据包含的信息有读者证件号、财产号、馆藏地、借出时间、还书时间、续借日期、续借次数、索书号等数据项。借阅历史表中包含读者证件号、财产号、馆藏地、借出日期、还书日期、续借日期、续借次数、索书号、借书地、还书地、MARC记录号等数据项。读者表则包括读者证件号、总借阅量、读者类型等数据项。财产表中则包括财产号、入藏日期、书刊状态代码、分配馆藏地代码等数据项。
1.1 数据预处理
对借阅数据的挖掘可充分发现馆藏资源的利用情况,分析借阅趋势和读者偏好。数据预处理是数据挖掘的必备步骤,主要工作包括对源数据进行再加工、检查数据的完整性和数据的一致性(包括排除重复记录、消除噪声、数据类型转换等)。首先在数据抽取时判断数据完整性,将超长时间借出未还的条目作为不完整数据剔除。然后进行冗余处理,因借阅历史中的数据冗余多以重复借阅的情形出现,所以将同一读者ID在一定时间范围(如30d)内对同一种图书的多次借阅只保留最后一次。然后处理符合要求的借阅数据的被借阅图书的索书号字段,截取对应索书号的首字符判断大类,再根据中图法子类分散情况截取对应后续字母的若干位,直到确定分类号。
在数据集成的过程中,对每条借阅历史记录的借出时间和归还时间分别与该种书的最初使用时间和最后使用时间进行比较,保留最小的借出时间和最大的归还时间。未归还图书的最后还书时间设置为做数据集成时的时间。如此便可在数据集成后计算出该书的生命周期。
另外,借阅数据集成时还需针对每条借阅记录读取读者ID,将该第N次借阅记录的图书MarcID和借阅时间写入“读者借阅行为表”中的“LendHistN”字段中。“借阅历史表”遍历完成后还将对“读者行为表”中的借阅记录字段内容按时间排序。
1.2 借阅行为的量化方法
为了定量计算出每条借阅记录的有效性,设计了基于借阅图书持有时长的量化计算方法:根据流通工作中的经验,可总结出超短期借阅行为,代表着读者判断该书不符合阅读习惯或知识所求,应赋予低有效性;另一方面,超期时间越长,也代表读者所借阅的图书越没有被充分利用(如果是高效利用图书,读者会在借期内归还并重新借阅),也应赋予低有效性。因此,总结算法为:①有续借操作则有效性值置为1;②没有续借操作且没有超期,则有效性置为1;③没有续借且超期时先求超期天数x,当x≥60(d)时置有效性为0,否则按照1-x/60求有效性值。此处60d是本馆完整借期,该参数可按照各馆实际情况设置。
1.3 探索性数据分析和挖掘
探索性数据分析(ExploratoryDataAnalysis,EDA)是数据科学过程的第一步,有助于了解数据集、检查数据集特征等。本次实验预处理借阅记录852 874条,其中有效借阅记录791 325条,涉及图书129 965种,涉及作者99 402位、出版商1 424家,平均每种书被借阅6.6次,低于平均有效借阅次数的图书有95 269种,占出借图书的73.3%(其中有38 014和20 923种书分别仅有1次和2次有效借阅),另外有1 503种书被借阅超过50次。图书有效借阅次数最多503次,是三毛的著作《倾城》,其次是王小波的《黄金时代》,出借283次,第三是东野圭吾的《信》,出借273次。借阅有效值累计>200的图书共15种,其中有11种是I大类,两种K大类(当年明月所著《明朝那些事儿》的前两卷,该系列图书属于I或K类一般依采编经验判断),R和H各一种。
以作者(作者数据中包含部分重复,如由于翻译不同造成的“褚威格”与“茨威格”,“某某著”与“某某编”,或是“孔子”与“孔丘”造成的不同。这种情况复杂多变,多因MARC记录编辑不规范和个人编辑习惯的差别造成,因此需另外的数据格式规范统一处理。本次实验过程中合并处理了一百多位知名作者信息)为单位计算该作者所著图书的总有效被借次数,以此为依据制作了作者文字云(见图2),大小和频次正比于有效借阅值的和,可见文学社科类的畅销作者为图书馆读者所追捧。因此,需考虑学科与分类对图书借阅的影响,在资源建设规划时也应对该方面的影响深入研并究综合衡量。

图2 推荐作者文字云
另一方面,按照最早借出时间和最后还回时间计算出某种书的实际流通生命周期。图书流通生命周期按天统计,不足1d则为0,最长的有8 153d,平均生命周期为489.9d,中位数为380d,标准差为451.4。在文献生命周期<30d的图书中,有1 472种是当天借阅并归还,且1 373种仅有这一次的借阅。将流通生命周期统计总结为表1。这些数据有力揭示了图书文献的利用情况。
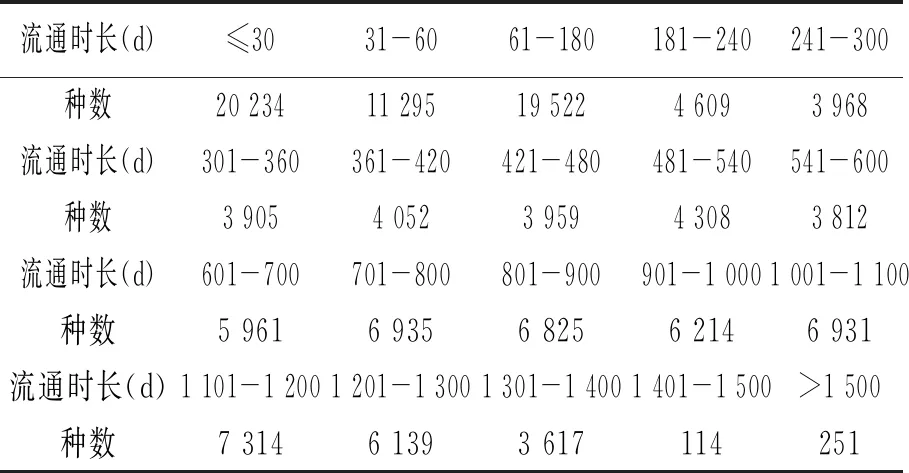
表1 流通时长与图书种数对照
数据清洗后可得到读者的借阅行为,表2是“读者借阅行为表”的结构示例。令集合I={i1,i2,…,in}是所有被借阅图书的集合,T={t1,t2,…,tm}是所有借阅行为的集合。每个借阅行为ti包含的项集都是I的子集。因此截取字符串中的MarcID子串,遍历借阅数据后可得频繁项集,这些是高利用率图书。标记时间的子字符串可用于关联时间规则的挖掘。

表2 读者借阅行为表示例
另外,令支持度S(X→Y)=δ(X∪Y)/N,置信度C(X→Y)=δ(X∪Y)/δ(X),则可得图书之间的关联规则。将计算结果记录到对应MarcID的图书表中。完成后还可以依据As=∑piSi,Ac=∑piCi,其中集合Si为和Ci某作者的图书集合的方式更新著者对应的支持度和置信度值,是该种图书对应某次借阅的有效性(根据读者ID、MarcID和借阅时间查找对应借阅记录及有效性的值)。同理计算出版社的支持度和置信度的值。
2 推荐值计算系统的设计与实现
利用频繁项集中各分类的占比、各出版社的占比、支持度和可信度计算出版商的推荐度。表3展示了是根据实验结果测算的前30名出版社及其推荐度,值越高越受推荐。例如清华大学出版的TP类的图书、中国林业出版的S7类或中信出版的I类图书会得到较高推荐值。

表3 出版社推荐度示例
2.1 网络爬虫的应用
利用网络爬虫爬取豆瓣图书中对某书的评分作为图书推荐的补充方法。利用Python的爬虫,可快速实现爬虫功能。设置爬虫URL,首先爬取豆瓣图书的检索页面,检索项设置为ISBN。利用Beautiful Soup(Python的第三方插件用来提取HTML中的数据)解析该页面,获取检索结果(精确找到了该书页面)的链接并再次爬取该页面,然后利用文本解析找到页面中的“豆瓣评分”及后面排列的数值(此为该书评分),取评分的1/2(豆瓣评分以10为满分)作为网络推荐值。读取书单后借助该爬虫获取评分,每读一条ISBN记录执行一次,而数据挖掘部分则是提前计算完成的,只需调用结果。
2.2 系统设计与实现
为了保障各学科图书采购的均衡与覆盖率,仍然需要采购参数以达到一些既定目标,例如设置各大类图书选购种数或比例、热门书的最大副本数、校区或馆藏地数量等。利用B/S架构,设计Browser页面实现文件上传,并做好格式和数据规范说明等。书单上传到部署算法的Server端,算法读取文件,读取出版社、ISBN等字段。设出版社推荐度的80%加网站爬取分值的20%作为整体推荐值。另外,还可以依据推荐度来给出推荐副本数,此处算法需配合采购参数来确保推荐副本数符合要求。
完成推荐值计算后输出到文件,最后页面跳转到该文件的FTP地址,供用户下载。按照推荐度排序的书单经本馆具有丰富采编和流通工作经验的老师审校后,认为书单质量可靠性极高。
3 结论
该工具的实现对优化资源建设有较大帮助,使新采购的图书更具实效。该系统的使用提高了图书馆采购新书的可用性和利用率,采购员也在数量巨大的书单中极大提高了选书效率,从往常巨大工作量中解放出来,转而进行专业资源建设或特色馆藏建设,提高了文献资源保障力度,补强了特色馆藏。新书典藏后利用率的提高,也证明了资源更符合本馆读者需求。另外,推荐度还可为流通工作提供参考,保留受欢迎图书,排架时也参照受欢迎著者预留更多空间,提高了流通工作效率。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
全国新书目(2021年6期)2021-08-03
全国新书目(2021年5期)2021-06-30
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
南风(2020年22期)2020-09-15
小学生优秀作文(低年级)(2019年5期)2019-04-25
少先队活动(2018年7期)2018-12-29
南方周末(2018-07-05)2018-07-05
小学阅读指南·低年级版(2017年12期)2017-12-26
