
一种改进YOLO v3的货车车轮检测算法*
2021-08-18 09:20周睿璇汪俊霖何秋生
山西电子技术 2021年4期
周睿璇,汪俊霖,孙 宏,何秋生
(太原科技大学,山西 太原 030024)
0 引言
传统识别货车超重的方法主要是检测人员用眼睛观察,根据经验判断是否超重,但是这样误差大。现在可以用视觉识别的方法来解决这一问题。根据国家货车车型对应标准(GB1589),货车车轴的数量以及分布与货车的型号相关联,可以通过检测货车车轴的数量和分布分辨货车车型判断其核载重量,再结合货车实际载重量判断是否超重。YOLO系列算法是比较成熟的神经网络算法,但也有不足之处,比如在检测特定的物体时算法中原先设定的先验框有的就不适用了,本项目以识别货车的车轮为例,对YOLO v3算法进行改进。
1 YOLO V3原理
1.1 检测过程
经典的YOLO算法中输入的图片经过Darknet-53输出三种尺度特征,分别用于检测小、中、大的物体,每个特征层有3个先验框。每个网格点预测出与所在层三个先验框对应的三个预测框,每个预测框包含C+5个信息,其中C是物体的类别数,5包括中心点的偏移量tx和ty、长宽th和tw、置信度[1]。这时的tx、ty、th、tw并不能直接反应预测框的空间信息,还需要经过下面公式获取预测框的长宽bh、bw和中心位置bx、by。
bx=σ(tx)+cx
by=σ(ty)+cy
bw=attw
bh=aheth
(1)
其中:cx、cy是网格点在网格中的坐标;ah和aw是先验框的长和宽[2]。iou是预测框和真实框的交集和并集的比,可以反映出两个框的重合程度,计算每个预测框和真实框的iou,与真实框iou值最大的预测框为最终的检测结果。
1.2 损失函数
损失函数可以作为深度神经网络对误检测样本惩罚的根据,YOLO v3的损失函数采用二交叉熵的形式[3]。损失包括坐标损失、置信度的损失和类的损失,其中坐标损失包括中心点的损失、宽高的损失。损失函数公式如下:
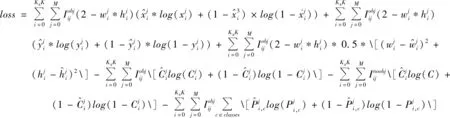
(2)
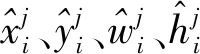
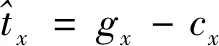
(3)
其中:gx、gy、gw、gh、是真实框的中心点的偏移量和长宽;cx、cy是真实框所在网格点的坐标。
坐标损失函数的不足之处在于:中心点位置并不是0或1而是0和1之间的某个数,但当预测结果与实际结果相同时坐标损失并不为0。
1.3 激活函数
激活函数能加入非线性因素,提高神经网络对模型的表达能力,YOLO v3采用的是Leaky ReLU激活函数,其公式为:
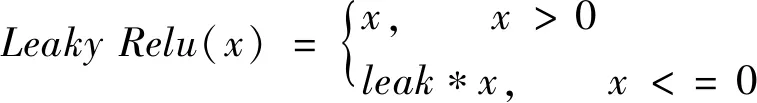
(4)
其中leak是一个很小的正数。
LeakyReLU激活函数的特点是在输入为负值时只有很小的坡度且并不光滑,可能导致基于梯度的学习很慢,使得检测的效率降低。
2 改进算法
2 .1 优化先验框参数
传统的YOLO v3算法的先验框尺寸是固定的,可能导致先验框与数据集中物体的大小并不匹配,从而影响检测精度。以货车车轮的检测为例,数据集中车轮的体积偏小,如果先验框设定过大可能导致预测框与真实框的iou的太小从而造成物体的漏检。图1是先验框和数据集中真实框尺寸的分布图。
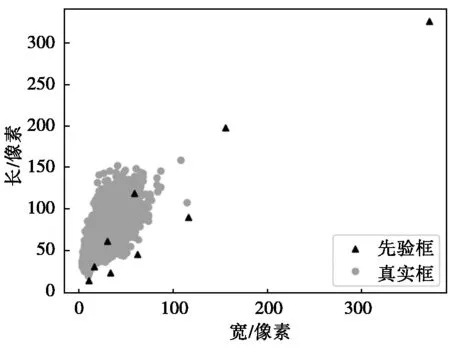
图1 改前先验框和真实框尺寸的分布
从图1可以看出有的先验框并不在真实框的集中范围内,先验框并不能代表数据集中车轮的总体特征。所以对先验框的尺寸进行改进。根据实际场景中货车车轮特征,本文采用K-means算法确定代表样本特征的几个先验框。
K-means聚类能够在一组数中找到具有相似特征的数并把它们分在一起从而得到聚类的中心点,这些中心点能代表这些数的总体情况。本文用iou来衡量两个框的相似程度,其度量公式如下:
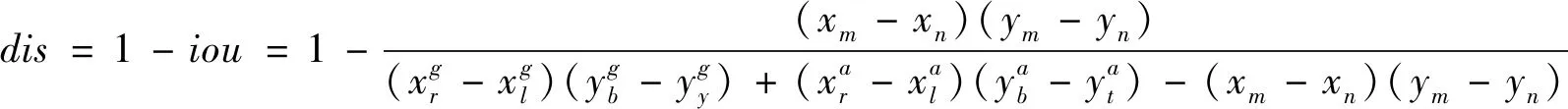
(5)
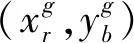
(6)
重复操作,直到新的先验框不变。预选框的生成和真实框的解码受先验框变化的影响,公式(1)变为:
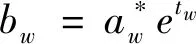
(7)
公式(3)变为:
(8)
2.2 改进损失函数
传统的YOLO v3采用的二交叉熵并不适用于中心点偏移量处于0到1之间的情况,考虑到本文检测对象的特殊性,将坐标损失函数替换为LossCIOU。LossCIOU采用的是预测框和真实框的中心点的欧式距离与包含预测框和真实框的最小闭包区域的对角线距离的平方之比来衡量中心点的误差,为保证真实框和先验框长宽比的一致性,LossCIOU定义α和υ两个参数以衡量长宽的损失,还把两个框没有重叠的部分纳入考量范围。LossCIOU的公式如下:
(9)
其中:ρ2(b,bgt)为预测框和真实框的中心点的欧式距离;c是能够同时包含预测框和真实框的最小闭包区域的对角线距离;α和υ的公式如下:
(10)
其中:wgt、hgt是真实框的宽和长;w、h是预测框的宽和长。
2.3 更改激活函数
由于Leaky ReLU是单调、不光滑的函数,在检测过程中容易导致梯度学习缓慢。Mish是一种光滑、非单调的函数。非单调性有助于负值的时候允许较小的负梯度流入,Mish函数不仅能加快学习速率还能得到更好的准确性和泛化能力。Mish函数公式为:
Mish(x)=x×tanh(ln(1+ex))
(11)
3 实验结果及分析
3.1 实验环境及实验结果
实验对本文提出的改进后的算法与原YOLO v3算法进行对比分析。配置有英特尔E5-2660 v CPU、三星64G内存和三星500G固态硬盘,还搭建了Keras、python、0penCV-python等常用环境。实验采用1140张货车图片作为测试集,检测效果如图2和图3所示。

图2 改进前检测效果

图3 改进后检测效果
从图2和图3可知:改进前检测出的三个预测框的平均得分为0.847,更改后的三个预测框平均得分为0.94,可见更改后的检测效果更好。
3.2 结果分析
对于改进前后的检测效果从模型的收敛速度,先验框与真实框的匹配程度,检测精度这几个角度进行分析。
1) 从模型的收敛速度看,图4可以看出更改后的Loss值比更改前的Loss值小,说明模型收敛地更快,这是由于先验框相当于把统计上的先验经验加入到模型中,对预测的对象范围进行约束,有助于模型快速收敛,LossCIOU使得目标框回归变得更加稳定,Mish函数使得权重能继续更新。
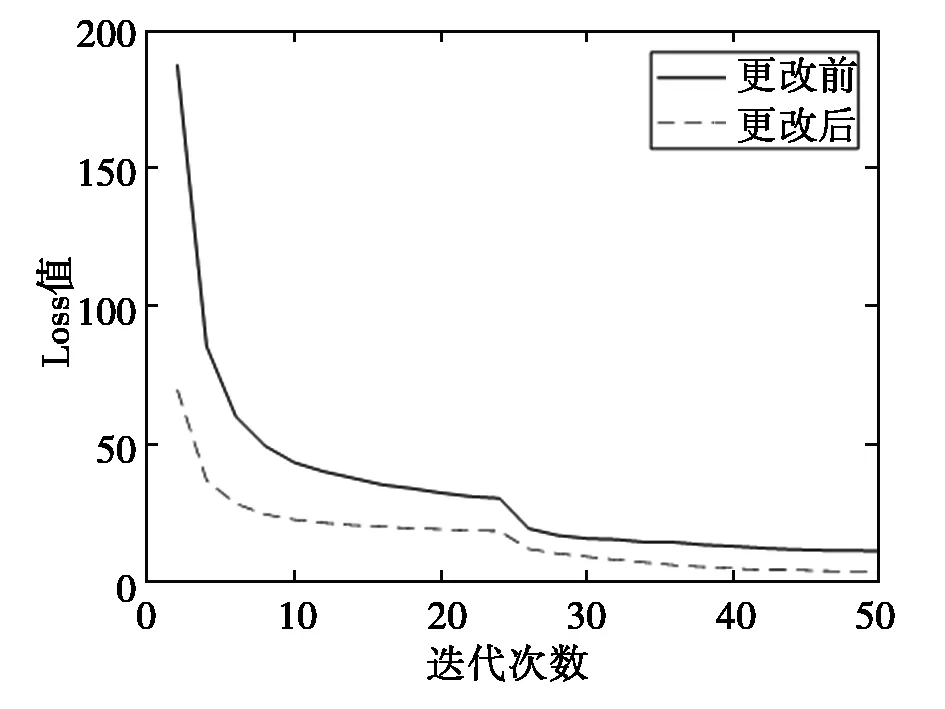
图4 Loss曲线图
2) 从先验框与真实框的匹配程度看,通过K-means聚类得到与车轮大小特征相符的三个先验框分别是[39,97],[53,102],[39,67],将这三个框代替原来第二层的三个框,由图5可以看出更改后的三个先验框在真实框主要集中的范围内均匀分布,与图3作比较可以看出更改后的框更适合识别货车车轮。
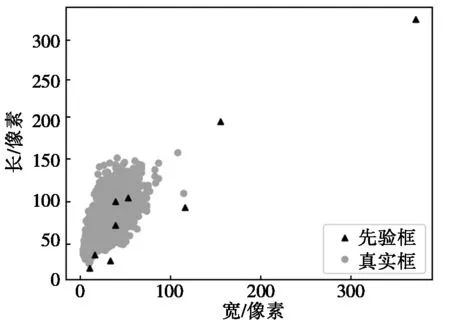
图5 更改后先验框和真实框分布
3) 从检测精度看,图6中更改后的PR曲线在更改前的上方,即更改后mAP的结果会更高,最后表1的检测结果也表明更改后的mAP提高到了90.16%,漏检率降低到了9.23%,说明更改后的检测结果更精确。
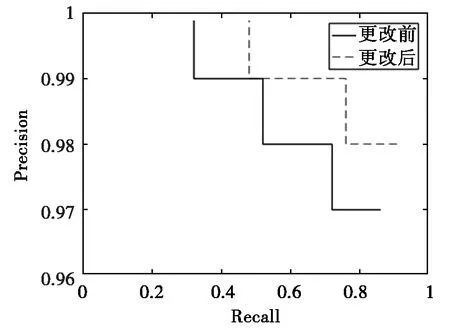
图6 PR 曲线

表1 检测结果对比
4 结语
本文提出了一种改进YOLO v3算法的货车车轮检测方法。通过K-means聚类,采用更好的位置损失函数和激活函数的方法改进YOLO v3网络。在1140张测试集上进行验证,结果表明改进后模型的收敛速度更快、准确度提升、漏检情况也有所改善,说明改进后的YOLO v3算法更适合检测货车车轮。
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
哈尔滨铁道科技(2021年3期)2022-01-19
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
矿山测量(2020年2期)2020-05-17
铁道通信信号(2020年11期)2020-02-07
电脑报(2019年4期)2019-09-10
岁月(2016年5期)2016-08-13
专用汽车(2016年9期)2016-03-01
专用汽车(2016年9期)2016-03-01
