
反卷积YOLOv3算法及其在刑侦领域的应用
2021-08-12 08:33胡明娣许天倚张中茂
计算机应用与软件 2021年8期
胡明娣 许天倚 张中茂 杨 洁
(西安邮电大学通信与信息工程学院 陕西 西安 710121)(电子信息现场勘验应用技术公安部重点实验室 陕西 西安 710121)(陕西省无线通信与信息处理技术国际合作研究中心 陕西 西安 710121)
0 引 言
在侦破案件中,公安人员查取汽车作为犯罪工具的作案痕迹是调查犯罪事实的有力信息和证据。目前,车牌自动识别技术与市场需求的结合已很成熟[1-2]。然而,当车辆被用作犯罪工具时,车牌必然会遭受污损、遮挡和套牌等方法处理而无法被识别,此时就需要对车辆本身进行检测。公安人员刑事侦查时获取车辆图像的渠道主要有两个:一是高空架设的交通摄像头,二是车辆行车记录仪。犯罪嫌疑人驾驶车辆势必会有意识避开交通摄像头,因此可获取来自交通摄像头的车辆图像资料中,绝大部分嫌疑车辆呈现远距离小目标特点,并且图像拍摄时受光照、环境及噪声等影响,而行车记录仪获取的图像存在拍摄质量不稳定的情况。
基于深度学习完成目标检测任务的算法大致可以分成一步算法和两步算法两大类。两步算法主要为R-CNN[3]系列算法。具体地,R-CNN采用卷积神经网络提取图像特征,使用选择性搜索方法提取候选框,创造性地将CNN用于目标检测相关任务中,R-CNN系列的巅峰之作Faster RCNN[4]在PASCAL VOC2007测试集上的mAP达到73.2%,但是两步完成目标检测任务的算法受到建议框提取阶段计算复杂度的限制,与实时检测间仍存在巨大鸿沟。为了平衡检测效率与精度,一步目标检测算法被提了出来。此类算法可以直接回归得到检测物体的坐标位置和分类得分,主要包括YOLO系列算法和SSD[5]算法。但由于SSD的网络层中只有底层的conv4_3用于检测小目标,小目标特征信息获取不足,因此SSD无法有效检测小目标。YOLOv1开创性地将目标预测框的坐标和宽高类似分类网络那样预测出来,在PASCAL VOC2007测试集上的mAP达到78.6%。但是YOLOv1因预测框个数限制,不能很好适用于密集型目标检测和小目标检测。YOLOv2将骨干网络替换为Darknet-19[6]并在v1的基础上引入批量归一化[7]和预设框机制[8]等组件优化模型,显著地提升了检测速度,但因骨干网络限制检测精度并不理想。YOLOv3[9]集v1、v2所长并利用更深层的Darknet-53网络提取图像特征,获得了目前最好的检测精度与速度的平衡。
针对刑侦领域进行车辆目标检测这一应用场景的特殊性,需要在实时检测的同时确保其准确性,因此本文以YOLOv3目标检测算法为基础,针对其远距离小目标检测效果不好的问题,提出了反卷积YOLOv3算法。该算法对Darknet-53输出的小尺度特征图反卷积后与大尺度特征图进行特征融合,提高了对小目标的表征能力,并用add代替concat进行特征融合增加了描述图像每维度信息量;采用K-means++算法聚类分析自建车辆目标数据集后重设预设框,并通过二次训练优化模型关键参数,得到更适用于刑侦领域的车辆目标检测模型。在公安部重点实验室现场勘验图片库中与YOLOv3、SSD、Faster RCNN算法进行对比实验,结果表明其精确度和召回率相较上述三种算法均有提升。
1 YOLOv3算法介绍
YOLOv3的骨干网络是Darknet-53,从第0层一直到74层,由卷积块(CBL)和残差块(res)[10]组成,卷积块由卷积层(C)、批归一化和激活函数(Leaky ReLU)三部分组成,其残差块来源于残差神经网络(Resnet)[11]的思想。每个残差块由多个残差单元组成,通过输入与两个CBL单元进行残差操作构建了残差单元,有效解决了网络层数过深可能导致梯度消失的问题。从75到105层为YOLO网络的特征交互层,分为三个尺度,在每个尺度内通过卷积核的方式实现不同尺度间特征的交互,作用类似于全连接层但是通过卷积核(3×3和1×1)的方式实现了特征图之间的局部特征交互,具体YOLOv3网络结构图如图1所示。

图1 YOLOv3网络结构图
YOLOv2采用K-means[12]聚类得到预设框的尺寸,YOLOv3延续了这种方法,为每种尺度设定3种预设框,总共聚类出9种尺寸的预设框。详细特征图与预设框的相关匹配如表1所示。

表1 特征图与预设框匹配表
2 反卷积YOLOv3车辆目标检测算法
2.1 车辆目标检测流程
反卷积YOLOv3算法分为训练阶段和测试阶段。训练阶段:用自建的具有更丰富车辆目标标注的数据集对预训练后具有初始参数的卷积神经网络进行二次训练,得到车辆目标检测模型;测试阶段:在公安部重点实验室现场勘验图片库中测试得到检测结果。反卷积YOLOv3的车辆目标检测流程如图2所示,整个流程包含以下四个步骤:(1) 设定好改进的YOLOv3算法网络结构;(2) 利用COCO数据集对网络进行预训练,得到预训练参数;(3) 利用自建数据集,对预训练模型进行二次训练,得到最终的车辆目标检测模型;(4) 采用公安部重点实验室现场勘验的图片对模型进行测试,得到检测结果。

图2 反卷积YOLOv3的车辆目标检测流程
2.2 反卷积YOLOv3
本文主要针对YOLOv3面向刑侦领域车辆目标检测时对远距离小目标检测效果不好的问题进行改进。首先根据小目标特征信息不足问题对网络结构进行改进;然后利用K-means++聚类分析自建数据集后重设预设框,使得模型在特定数据集上泛化能力更强;最后利用自建具有更丰富车辆目标标注的数据集训练模型优化关键参数,最终得到更适用于刑侦领域的车辆目标检测模型。
2.2.1网络结构设计
通过对原始图片进入YOLOv3神经网络输出的特征图可视化分析,如图3所示。可以看出,小目标检测精度不高的原因在于高层特征图的语义信息被削弱,也就是说52×52特征图的语义信息不强。

图3 原始图片可视化分析
根据分析结果采取重复利用13×13和26×26特征图的语义信息来提升特征图对小目标的表达。首先,对原网络输出得到的13×13特征图进行2倍的反卷积后与26×26输出的特征图进行特征融合,再将融合后的特征图进行2倍的反卷积后与52×52的特征图进行特征融合以得到更多小目标的特征语义信息,并将原网络中上采样[13](UNSampling)的方式替换为反卷积[14](Deconvolution)。上采样是提高图像分辨率的技术,常用的方式是重采样和插值,具体为将输入图片设定为一个需要的大于原图片的尺寸,使用如双线性插值等插值方法对空白像素点进行插值来完成上采样过程,如图4所示。反卷积是一个恢复特征图像素的过程,具体完成方式分为转置卷积和空洞卷积。转置卷积是将输入图像边缘填充0,而空洞卷积如图5所示,将原有的像素点,中间插入0,这样可以还原更高像素的图片。因此本文选择空洞卷积的方式。可以看出,图5中输入特征图尺寸为3×3,输出特征图为5×5,步长为2,填充为1,卷积核尺寸为3×3,可以得出反卷积过程中特征图的输入输出关系如式(1)所示,其中:o为输出,i为输入,s为步长,k为卷积核大小,p为填充。可以看出,相比于上采样的方法,反卷积不仅仅是临近像素的填充,还多了一步参数学习的过程,可以在增大特征图分辨率的同时,得到更充分的小目标特征信息。
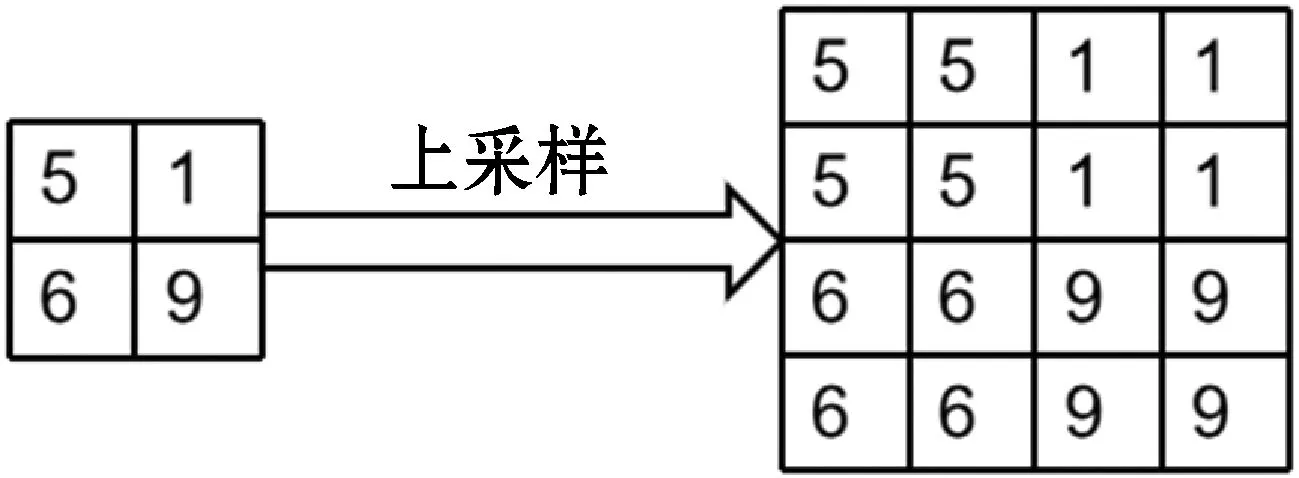
图4 上采样示意图

图5 空洞卷积示意图
o=s(i-1)+k-2p
(1)
除此之外,采用并行策略[15](add)代替系列融合[16](concat)来完成特征融合。add进行特征融合后描述图像的维度并没有增加,但每一维度下的信息量增加了,提高了描述图像特征的信息量,显然这对最终目标检测是有益的。concat仅是通道数的合并,描述图像本身的通道数增加了,而每一通道下的信息并没有增加,concat每个通道对应着相应的卷积核。而add先将对应的特征图相加,再进行下一步卷积操作,相当于增加了一个先验信息,对应通道的特征图语义类似,从而对应的特征图共享一个卷积核。对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核。由于每个输出通道的卷积核是独立的,在只看单个通道的输出时,假设两路输入的通道分别为A1、A2、…、Ac和B1、B2、…、Bc,C代表通道对应的卷积核。那么concat的单个输出通道如式(2)所示(*表示卷积操作);add的单个输出通道如式(3)所示。通过计算公式可以看出add的计算量要比concat的计算量小得多。
(2)
(3)
综上所述,反卷积YOLOv3网络结构如图6所示。
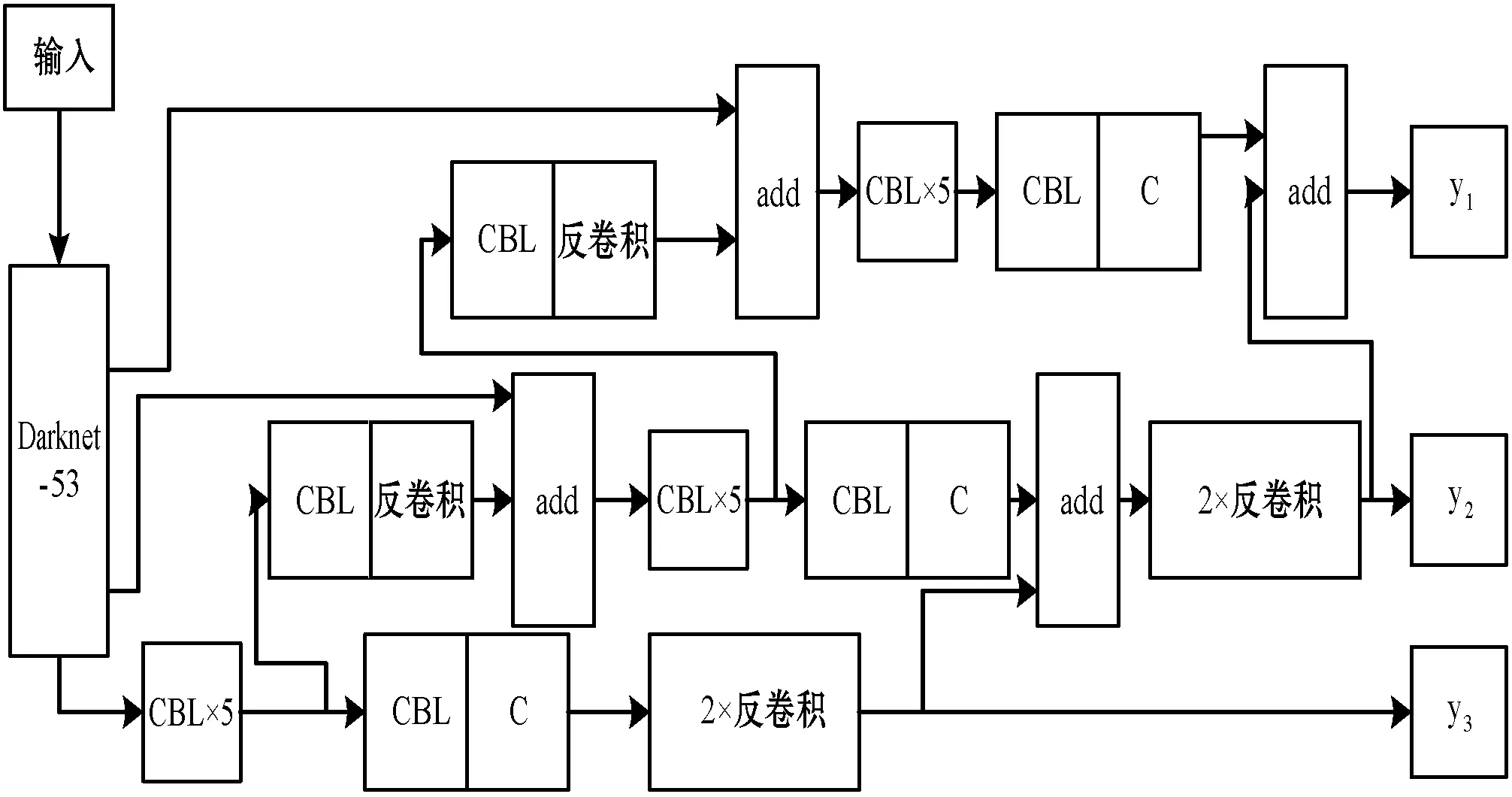
图6 反卷积YOLOv3网络结构图
2.2.2K-means++聚类重设预设框
目标检测通过预设框去逼近标注框来准确检测出图像中的目标。从YOLOv2开始引入了Faster RCNN的预设框机制,预设框是一组宽高固定的初始候选框,初始预设框设定的尺寸大小是否切合具体场景对检测精度有较大影响。YOLOv2利用K-means聚类算法对数据集中的目标框的宽高进行聚类,获得一组固定的预设框。YOLOv3原始预设框由COCO数据集聚类而得,与刑侦领域车辆目标大小存在差距,部分预设框的尺寸设置并不合理。因此在这里针对车辆目标数据集,采用K-means++聚类分析重设预设框,以提高检测的准确率。K-means++对K-means进行改进,最大化聚类中心之间的距离,使得距离当前聚类中心最远的点被选取的概率达到最大,从而减少初始聚类中心对最终聚类结果的影响。具体步骤如下:(1) 从所有数据列表中随机选择一个点作为第一个聚类中心;(2) 对于列表中的每一个点计算与最近中心的距离D(x);(3) 选择新的聚类中心,选择标准是D(x)越大,被选取作为聚类中心的概率越大;(4) 重复步骤(2)-步骤(3)选取k个聚类中心;(5) 后续步骤和K-means算法相同。采用平均重叠度(Avg IOU)作为目标k值设定是否恰当的评判标准,对自建数据集进行聚类分析,当平均重叠度趋于平稳时为最佳k值。聚类的Avg IOU目标函数为:
(4)
式中:B表示目标中心;C表示簇的中心;nk表示第k个聚类中心中样本的个数;n表示样本的总个数;k表示簇的个数;IIOU(B,C)表示簇的中心框和聚类框的交并比。
先读取数据集中目标的宽W、高H(归一化)作为待分类数据,根据实验经验设置初始化聚类中心点个数k为1~12。如图7所示,随着k值的增大,目标函数变化越来越平稳,选取平稳处的k值为预测框的个数9,此时对应聚类中心的宽和高分别为(12,10)、(19,16)、(26,22)、(32,29)、(42,34)、(55,43)、(80,52)、(139,78)、(291,173)。
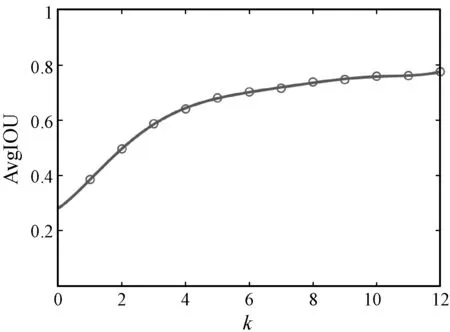
图7 k值与AvgIOU值关系图
2.3 模型训练
在目标检测网络中,底层网络一般是用于识别颜色、轮廓、纹理等特征的基础结构,显然大部分问题都由这些相同的基础结构组成,浅层的特征对于不同任务具有一致性,因此可以选择冻结这些层。通过设置各层的是否训练参数,即可控制是否冻结该层,从而节省训练时间。针对新的数据集的特点,训练较高的网络层。
本文预训练模型为Darknet-53,预训练模型参数权重来自于Darknet-53在COCO数据集下的训练结果。然后利用自建车辆目标数据集二次训练模型,在模型训练过程中,不断调整网络中的参数,使损失函数的值达到最小,完成模型训练。
3 实 验
3.1 实验条件
实验基于Windows 10系统,显卡为NVIDA GeForce GTX 1070Ti,显存8 GB NVIDIA,采用Keras框架。在训练过程中,采用小批量随机梯度下降法,每36个样本更新一次权重参数。为减少内存占用,多次实验后最终决定将64个样本分割成8个大小为8的子样本来进行训练,迭代次数为12 000次。采用动量系数使训练过程加速收敛;为防止过拟合,设置权重衰减系数,其中动量和权重衰减分别配置为0.9和0.000 5,学习率初始为10-3,最低的最终学习率为10-4。
3.2 实验数据集
大型公开数据集(如VOC2012、COCO等)的图像中目标分类较多,含有车辆目标的图片较少,对车辆目标的描述不够。因此为了训练出更适应刑侦领域下进行车辆目标检测的模型,需要制作数据集,具体步骤如下:(1) 通过互联网搜集不同型号、不同外观、不同角度拍摄的车辆图片600幅,部分图片示例如图8所示;搜集自西安市长安区西安邮电大学立交桥上与西安市雁塔区长安中路立交桥上拍摄的道路图片来模仿实际交通摄像头角度所得的刑侦图像并采集行车记录仪的图片共4 000幅,部分示例如图9所示,由图9(a)可以看出交通摄像头角度拍摄的图片远距离小目标占比突出。(2) 利用图像标注工具Labelimg对4 600幅图片中所有车辆目标进行标注,具体方法是在图像中框选出所有的车辆目标,标注图片部分示例如图10所示,并得到VOC格式的xml文件。(3) 将xml文件转换为“标签+X+Y+W+H”格式的txt文件。(4) 根据VOC数据集的目录结构放置生成的文件。(5) 训练中,随机改变图片的亮度、对比度、饱和度、色调,对图片进行随机剪切和镜像处理进行数据增强。

图8 同一款车不同角度拍摄的图片

(a) 模仿交通摄像头角度采集图片部分示例

图10 标注图片部分示例
3.3 实验结果及分析
在面向刑侦领域进行车辆目标检测时,精确度与召回率较之检测效率更为重要,因此本文使用召回率(R)和精确度(P)[17]来衡量训练得到的车辆目标检测模型的性能。召回率与精确度的取值范围均为[0,1],计算公式如式(5)和式(6)所示。测试数据集来自公安部重点实验室现场勘验图片库,包含高空交通摄像头拍摄的图片以及行车记录仪拍摄得到的图片共100幅(与训练集不重合)。
(5)
(6)
实验分为如下三个部分。
1) 对比相同场景下各种算法的检测效果。利用上述车辆目标数据集分别对YOLOv3、SSD、Faster RCNN与本文算法进行训练后测试对比检测效果。YOLOv3与本文算法加载同样权重Darknet-53预训练模型。Faster RCNN是RCNN系列算法中效果最好的算法,也是最具代表性的两阶段法;SSD同样是具有很强代表性的一阶段法。本文将目标检测转换为二分类问题,即需要尽可能检测图片中存在的车辆,且没有将其他目标检测成车辆。因此从测试集中分五组,每组随机选取10幅图片,对图片中车辆目标个数进行统计以便后续计算精确度与召回率。四种算法的召回率、精确度分别如表2和表3所示,四种算法的检测效果对比图如图11所示。
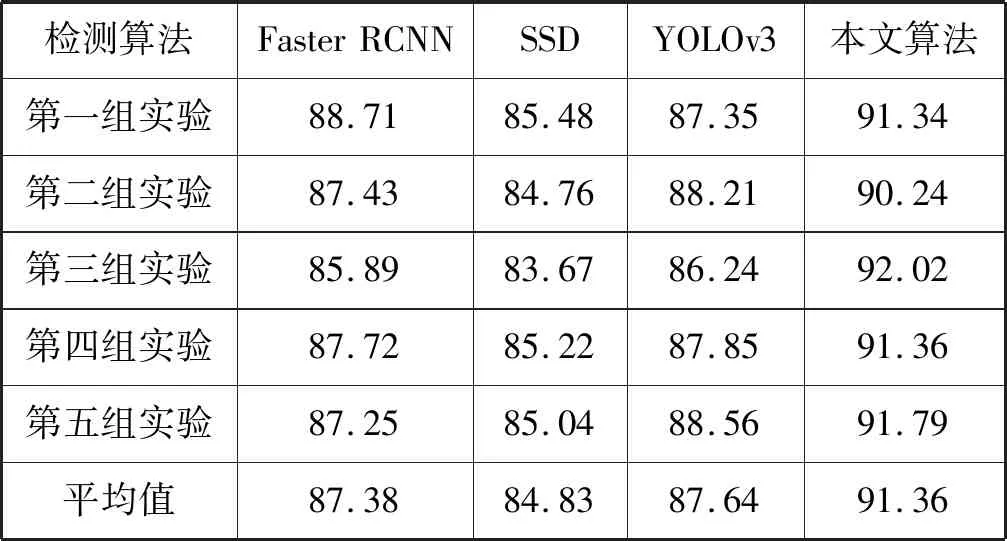
表2 不同算法检测精确度对比 %
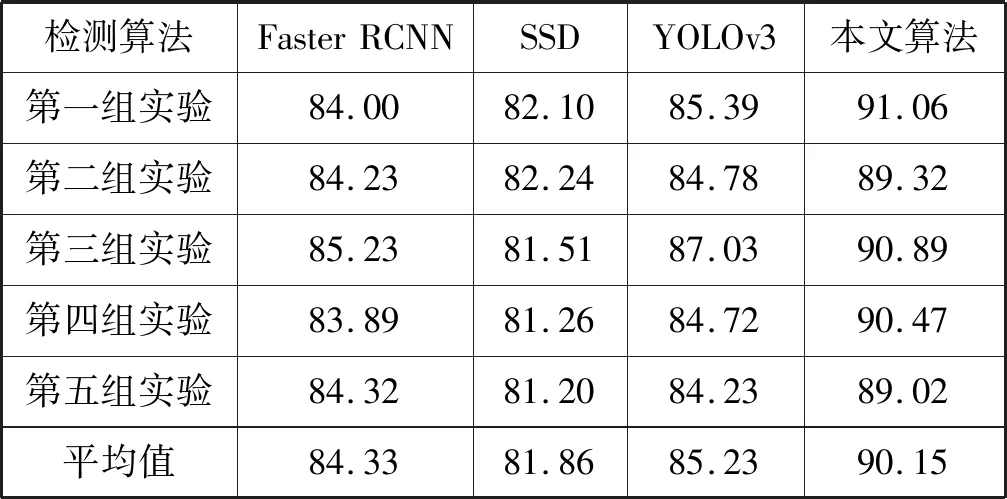
表3 不同算法检测召回率对比 %
YOLOv3利用更深层的Darknet网络提取图像特征,并参考SSD的优点而得出,在车辆目标检测时相比SSD、Faster RCNN具有更高的精确度和召回率。本文在YOLOv3基础上重复利用13×13和26×26特征图的语义信息来提升特征图对小目标的表达并对关键特征融合模块进行替换,加强参数学习,进一步提高了精确度和召回率。从表2和表3可以看出,本文算法相比YOLOv3精确度提高了约4百分点,召回率提高了约5百分点。从四种算法的检测效果图可以看出SSD对小目标检测效果不佳,Faster RCNN检测效果稍逊于YOLOv3,图11(b)黑色框为本文算法较YOLOv3多检测出的两个车辆目标。

(a) YOLOv3检测效果图 (b) 本文算法检测效果图
2) 采用不同改进点训练网络时的检测效果。为了进一步验证本文算法中不同改进点的有效性,本文分别使用不同的改进点对网络进行训练后测试。采用的改进点及训练之后的检测结果如表4所示。

表4 采用不同改进点检测效果

续表4
通过对表4中7种不同改进点的对比,发现重复利用13×13和26×26特征图的语义信息来提升特征图对小目标的表达可以对精确度有约3百分点的提高,召回率有约4百分点的提高。通过对改进点1、6进行对比,可以发现通过重设预设框使模型对车辆目标数据集泛化能力更强和对特征融合模块的替换提高参数学习量对精确度与召回率均有约1百分点的提高。通过采用不同改进点的实验证明本文算法可以有效提高车辆目标检测的精确度和召回率。
3) 不同实际条件下本文算法的检测效果。从包含100幅图片的测试集中挑选8幅不同实际条件(光线、车流量)下的图片来测试本文算法所得车辆目标检测模型的性能。
(1) 交通摄像头角度拍摄的实际不同条件图片检测效果图如图12所示。

(a) 车流量大、光线条件良好 (b) 车流量大、光线昏暗
(2) 行车记录仪拍摄的实际不同条件图片检测效果图如图13所示。

(a) 车流量大、光线条件良好 (b) 车流量大、光线昏暗
可以看出,本文在面向刑侦领域不同实际条件下进行车辆目标检测均有良好的效果,精确度和召回率均满足实际要求。综合考虑,本文算法是一个有效的面向刑侦领域的车辆目标检测算法。
4 结 语
本文通过反卷积的方式重复利用13×13和26×26特征图的语义信息并替换关键特征融合模块提高了网络对小目标的表征能力,对车辆目标数据集聚类分析后重设预设框训练模型,使模型在面向刑侦领域进行车辆目标检测时具有更强的泛化性。实验证明,该算法的精确度、召回率较YOLOv3均有提升。通过测试实验表明训练出的模型对不同车流量、不同光线下的实际刑侦领域场景均具有很好的鲁棒性,但通过大量的测试实验发现,车辆密集、光线条件等因素仍对检测效果有很大影响。接下来需在训练集着重加入车流量大、光线条件不足的图片以进一步提高模型的准确率,降低其他因素对检测效果的影响。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算技术与自动化(2022年1期)2022-04-15
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2021年12期)2021-11-02
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学课程辅导·教学研究(2017年28期)2018-02-03
