
基于匹配算法的藏文文本词语校对研究∗
2021-08-08 11:14王福钊周
计算机与数字工程 2021年7期
王福钊周 雁
(1.西藏大学信息科学技术学院 拉萨850000)(2.北京理工大学珠海学院计算机学院 珠海519000)
1 引言
文本校对是较为复杂的自然语言处理过程,也是自然语言处理中最为重要的关键一步。汉英文本校对研究起步较早,目前也已经取得了较好的成果。藏文信息处理研究起始于21世纪初,其起步晚,研究资源短缺,研究进展缓慢[1]。藏文文本校对占据了藏文信息处理的重要位置,是进行藏文自动分词、文本语义分析、语料库建设等的基础,具有极其重要的基础性意义[2]。藏文文本校对是一项较为复杂的工作,其包括音节校对、梵音转写校对、词语校对、接续关系校对以及语法校对[3]。随着计算机的不断应用普及,对藏文信息化的要求也越来越高。简单来看,当我们在计算机中进行藏文文本的录入时就可能存在错误,可能出现音节拼写上的错误或词法、句法上的错误等,这些错误都将严重影响之后的文本处理。因此在我们的生产生活科研中对藏文文本的校对就显得格外重要。在过去的十多年里,一些科研机构对藏文文本的校对进行了研究,大多是对藏文音节和词接续关系的研究[1~3]。本次研究的对象是藏文文本中的词语校对方法研究,并采用最大匹配算法的思想在不进行分词的情况下实现了藏文文本的词语校对。
2 研究基础
2.1 藏文基本结构
藏文创造于吐蕃松赞干布时期,属于藏汉语系语言。藏文同是拼音型文字,其拼写为一体,即书写和拼读皆通过30个辅音字母和5个元音字母(其中ཨa为省略不写)构成[4]。藏文的辅音和元音字母如表1,2所示。

表1 藏文辅音字母

表2 藏文元音字母
藏文字形结构是纵横叠加的平面结构,其以基字(一个辅音字母)为核心。现代藏字包括一般结构和特殊结构。在一般结构中,藏字至少由一个辅音字母组成,最多可由七个字母组成[4]。藏字一般结构如图1所示。
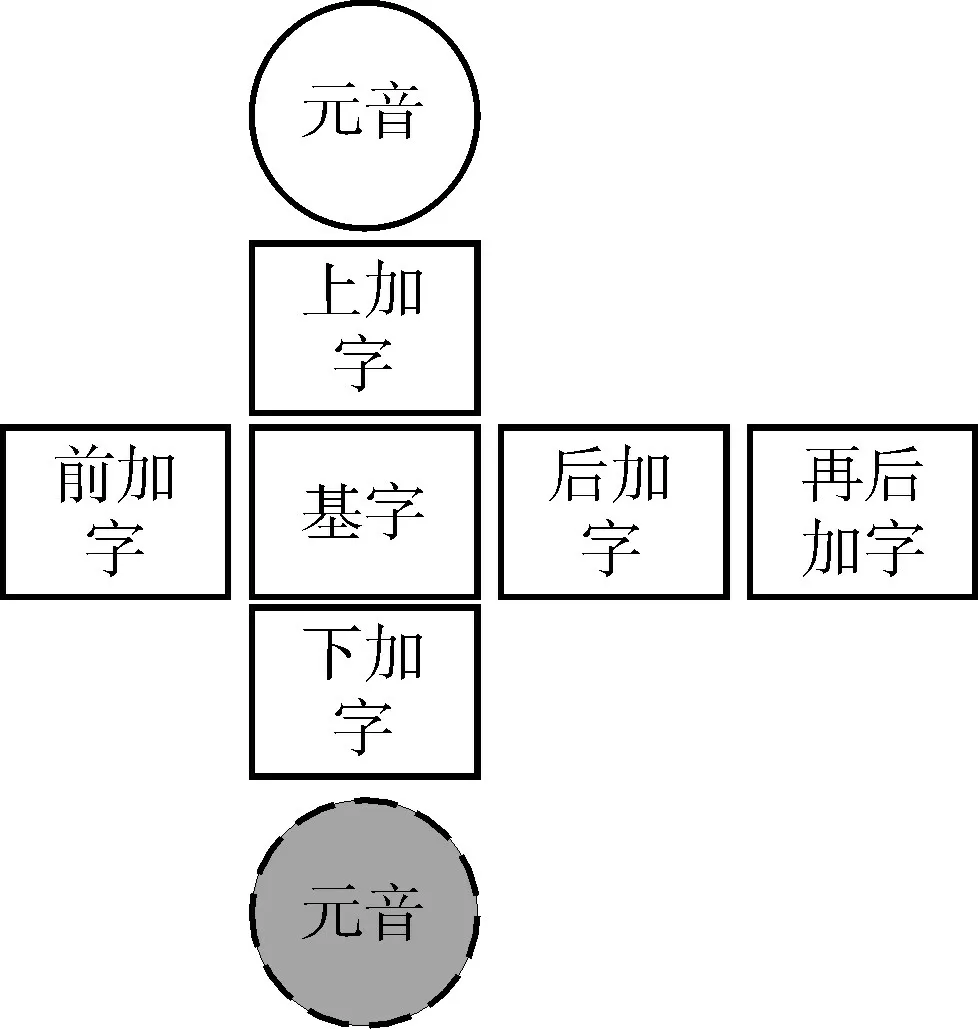
图1 藏字一般结构

2.2 藏文文本校对类型
根据藏文文本中可能出现的错误情况进行校对分类,共分为五类。具体如下。
1)藏文音节校对。主要是从藏文字的构字规则出发对音节的组成进行检查。例如,藏字

3 藏文文本词语校对
藏文文本的词语校对方法主要有机器学习的词网络匹配方法和词典匹配两种方法。基于词典匹配的词校对方法是简单而方便的词校对方法,之前的研究中大多通过文本分词,再进行词典的匹配方式实现词校对。现将使用动态组词并匹配的方式实现词语校对。藏文文本词语校对原理图如图2所示。

图2 藏文文本词语校对原理
藏文文本进行预处理。首先,将其中的非藏文特殊字符,如逗号、冒号、引号等进行处理,将文本根据这些符号进行简单分句;其次,对文本中的缩略词进行还原;最后在预处理的结果上进行文本的词语校对。
3.1 文本预处理

3.2 音节校对
藏文音节校对采用构字规则约束判断。首先对音节进行构件拆分识别,将各个构件以基字为中心拆开,然后通过构字规则的限制条件进行约束限制判断,如果构件之间不能满足限制条件则确定音节错误[8]。藏文构字规则约束较多[4],有对前加字的限制如表3所示。

表3 前加字约束


表4 上加字约束
对于下加字的添加限制如表5所示。

表5 下加字约束
对于再后加字的添加限制如表6所示。

表6 再后加字约束

3.3 词语校对算法设计
校对算法的设计采用的是在前向最大匹配算法的基础上增加了反向匹配的思想。校对算法原理如图3所示。
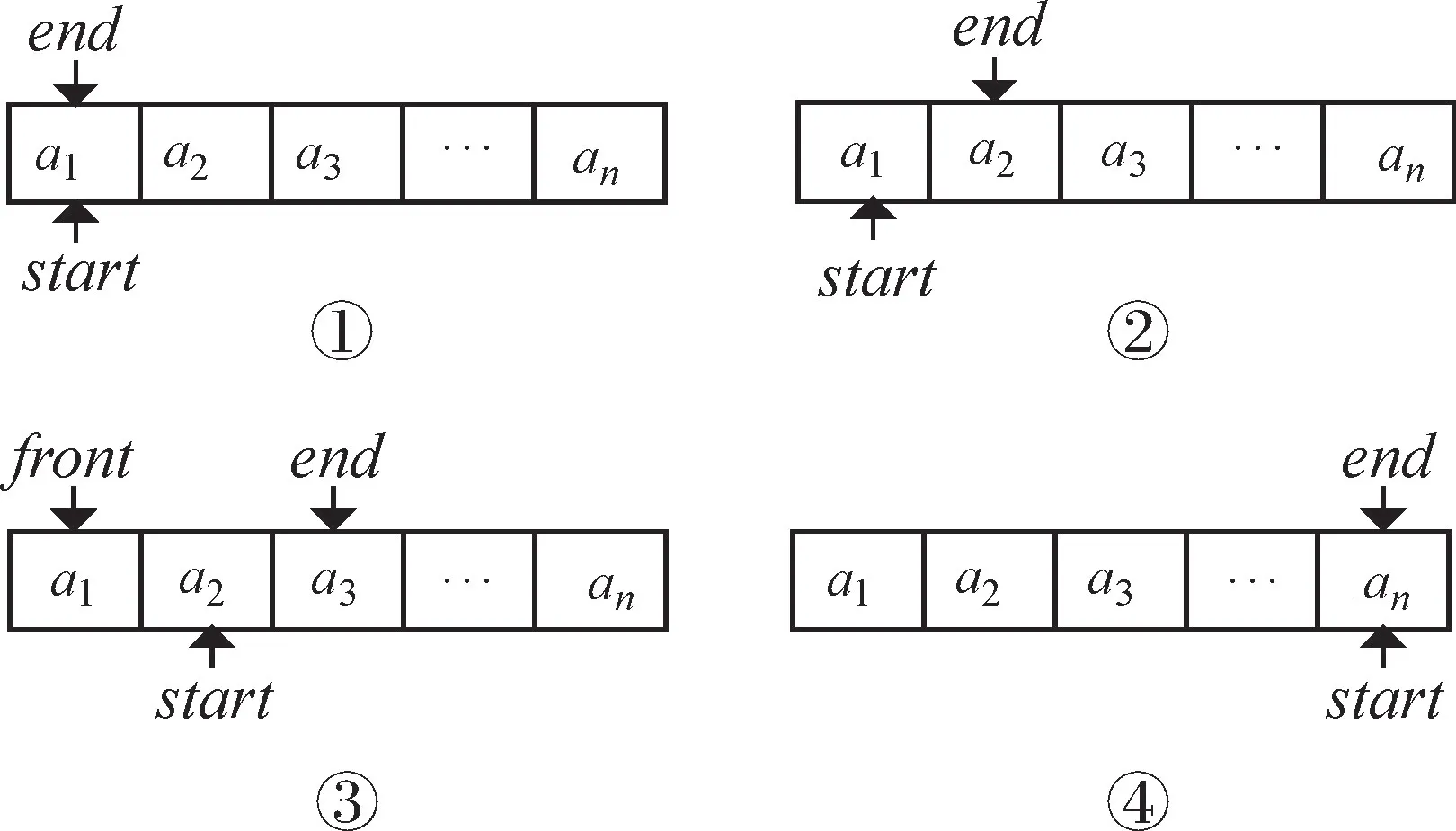
图3 词语校对算法思想
如图3中所示,藏文句子words=(a1,a2,a3,…,an-1,an)包含n个音节。算法以前向最大匹配算法的基础上融入了反向匹配的思想,在前向匹配的起止start、end游标基础上增设front游标,实现了前向-后向匹配。算法具体实现是1)初始化。先赋初值start←0,front←start,end←start;2)校对控制。start游标从0开始以1为单量递增至n+1则表示当前句子校对结束;3)前向动态组词。words[start…end]由start和end组成,end从start开始依次以1为增量递增,当words[start…end]与词典匹配成功则end递增结束并start←end+1,否则依次递增匹配至n,当end为n还尚未匹配成功,则前向匹配失败并进行后向匹配;4)后向动态组词。words[front…start]由front和start组成,front从start开始依次以1为减量递减,当words[front…start]与词典匹配成功则front递减结束并start←start+1,否则依次递减匹配至0,当front为0还尚未匹配成功,则后向匹配失败。前后向均匹配失败,则表示当前音节本身以及至少与下一个音节不能组成词语,作错误标记并进行start←start+2。
4 实验及结论
实验程序通过pycharm工具编写python3.5程序实现算法,并对人工输入共计包含28469个音节的藏文文本进行了校对测试。具体实验步骤如下:1)对文本预处理;2)将预处理的结果文本以单垂符“།”和双垂符“།།”分句;3)将分句的结果输入校对算法程序进行文本校对;4)将算法程序执行后返回的校对结果输出到文件中。通过实验验证,结果表明该方法下藏文文本的词语校对达到较好的效果,实现了在不进行分词情况下的词语校对。
5 结语
藏文文本校对不仅对藏文信息化处理的研究具有重要意义,而且对生产生活也具有重要意义。随着计算机技术和藏文基础研究的不断发展,藏文文本校对方法将会得到不断的改进和优化,其应用领域也将会越来越广阔。
猜你喜欢
农业工程学报(2022年6期)2022-06-27
中国藏学(2022年1期)2022-06-10
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
建材发展导向(2021年23期)2021-03-08
考试与评价·七年级版(2020年6期)2020-11-02
布达拉(2020年3期)2020-04-13
学校教育研究(2020年3期)2020-02-18
快乐作文(1.2年级)(2019年9期)2019-09-10
现代职业教育·职业培训(2018年10期)2018-05-14
