
基于NLA-EAST的自然场景文本检测方法∗
2021-08-08 11:13姚焙继朱玉全岑燕妮
计算机与数字工程 2021年7期
姚焙继 朱玉全 岑燕妮
(江苏大学计算机科学与通信工程学院 镇江212013)
1 引言
随着计算机技术的发展,文本检测已经成为计算机视觉的热点,自然场景中文本检测在一些例如目标地理定位、人机交互、图像搜索、汽车自动驾驶等领域存在重要的应用价值。因此利用自然场景文本检测和识别提供图像中的文本信息,成为计算机视觉领域中热门课题之一。
但在自然场景中定位文本位置是非常困难的事情。与传统书本或者文件中的文本字体规则、颜色单一和大小一致不同,自然场景图像中的文本可能具有完全不同的字体、颜色和大小等。自然场景图像中的背景也可能非常复杂,有些背景物体和文本实际上是很难区分的,比如一些带棱角的符号,甚至一些排列整齐的砖头都很容易与文本造成混淆。并且在自然场景中各种干扰因素层出不穷,噪声、分辨率、光照和文本模糊等也会导致场景文本检测的失败。
针对上述问题,大量的方法被提出。ShaoQing Ren在2016年 提 出 了Faster R-CNN[1]通 过 引 入RPN网络并且整合特征提取模块来共享特征,提升了检测速度和准确率。同年Zhi Tian等提出了连接文本区域建议网络CTPN(Connectionist Text Pro⁃posal Network)[2],通过小的垂直的锚来检测出所有的文字区域,再合并为一个文本框,在速度和准确率上得到了质的提升。XinYu Zhou等在2017年提出了一种高效、准确的文本检测器EAST(EAST:An Efficient and Accurate Scene Text Detector)[3],通过简单的网络,可以快速的在自然场景图像中检测到文本位置,并且采用旋转框来检测任意方向的文本。Dan Deng等 于2018年 提出PixelLink(Pixel⁃Link:Detecting Scene Text via Instance Segmenta⁃tion)[4],对文本或者非文本区域的相邻8个像素预测连接关系,确定是否为文本区域或者非文本区域并直接获取边框。
然而这些方法确实有较高的精度,但是一些文本的像素级特征过于稀疏,导致对文本检测不全。此外现有的方法在检测较大和较长的文本方面也存在不足。基于以上问题,本文提出NLA-EAST网络模型,采用非局部注意力机制来改进EAST中使用每个像素来预测顶点坐标。通过ASPP空洞卷积[5]来提升获取上下文信息的能力,并提出边界重定函数来指导网络学习更详细的边界定位信息。
2 相关工作
2.1 基于候选区域提案的文本检测方法
基于候选区域的文本检测方法依赖于候选框的选取,此类方法拥有两个派系,一类是Fast⁃er-RCNN系列,另一个是SSD[6]系列。其中Fast⁃er-RCNN的代表方法是CTPN等方法,通过更改RPN的锚为水平序列,根据每个相邻锚之间的关系提取特征,再利用后处理将每个锚连接形成文本框。SSD系 列 中 典 型 的 网 络 是Textboxes[7]等 方法。SSD是多类目标检测网络,Textboxes改进了SSD。这些方法主要依靠锚的选取,但是文本的尺度并非一成不变,因此不得不产生较多的锚,降低了效率。同时由于锚的匹配机制会对推荐区域生成一系列的锚,筛选合适的作为正负样本的标签。但对于较长而密集的文本行而言,锚宽高比会变得很高,此时对网络感受野的需求变大,网络会变得更复杂。
2.2 基于图像分割的文本检测方法
基于图像分割的方法通常利用语义分各种的全卷积网络(FCN)[8]等方式来对文本或者非文本进行像素级分割后再加上回归,或者单独的分割接后处理的形式。这类方法基础网络一般为U-net[9]或者FPN[10],而U-net和FPN提升了对小物体的检测效果,因此这类方法对小目标分割具有一定的优势。例如EAST、Pixel-Link等。EAST在回归时预测每个像素点的四条边或者四个顶点的绝对距离[3],但是网络的感受野不足,会导致在检测长文本或者较大文本时容易出现误检或者漏检。Pix⁃el-link含有两个预测任务:一是对当前像素预测其属于文本还是非文本,二是会对当前像素周围的8个像素预测像素之间的连接关系,如果关系密切则直接获取文本边框。但是此类方法对分割的结果图准确性的要求非常高。如果分割不够精准,像素周围的噪声会对像素造成较大的影响,导致出现错误的预测结果。
3 基于NLA-EAST网络的场景文本检测
本文提出一种新颖的基于NLA-EAST网络,通过非局部注意力机制更新特征,在新特征图上根据权重系数来重新定位文本的位置,并且提出一种边界保留损失,来指导网络学习更详细的边界定位信息。模型如图1所示。

图1 NLA-EAST网络结构
3.1 ASPP空洞卷积
上下文信息对文本检测有着非常重要的作用。然而,自然场景下文本在尺度,形状和位置上有很大变化。以前的方法一般都是通过连续的pooling或者其他的下采样层来整合上下文信息,这种方式会损失分辨率。EAST在感受野不够大的情况下,会使在检测较长文本或者较大文本时,预测值不能达到文本的边界而出现文本框断裂的情况,因此本文使用空洞卷积,来获得相同比例但不同感受野的特征。为了最终提取的高级特征包含尺度和形状不变性的特征,许多方法[5,11]都采用了不同扩张率的空洞卷积,本文的空洞率分别设置为3,5和7(原ASPP为6、12、18)来获取多感受野的上下文信息,然后通过跨通道连接组合来自不同空洞卷积的特征映射,并使用1*1的卷积来降低维度。ASPP空洞卷积模块如图2所示。
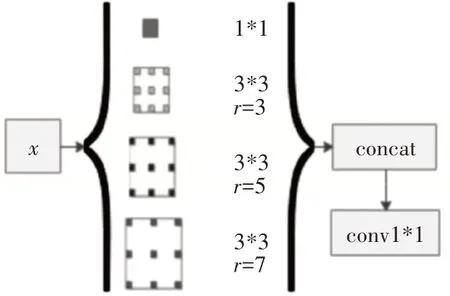
图2 ASPP空洞卷积
3.2 非局部注意力模块
非局部注意力模块分为两部分,空间注意力[12]和通道注意力[13],低层特征使用空间注意力,使用通道注意力来关注高层特征。
3.2.1 空间注意力
在自然场景文本的检测中,同一个文本行区域内,相邻文本之间具有宽度、高度、颜色、以及像素值相似的特点。因此,采用空间注意力机制(SA,如图3所示),来捕获文本像素位置之间的全局空间依赖关系,对于特征图上的每个文本位置特征进行attention调整,通过加权求和所有位置的聚合特征来更新特征,并聚焦到文本区域上。其中权重由相应的两个位置间的特征相似性决定,具有相似特征的两个位置可以相互促进改进。以图1为例,将降维后的特征输入空间注意力模块,通过三步来获取空间的上下文信息的特征,第一是生成空间分数矩阵,该矩阵模拟特征的任意两个像素之间的空间关系。第二在分数矩阵和原始特征之间执行矩阵乘法。第三对上面的乘法结果矩阵和原始特征执行逐元素和运算,以获得反映上下文信息的最终表示。

图3 空间注意力SA
如图3所示,将提取的图像特征X大小为H*W*C,通过三个1*1的卷积来生成新的三个特征映射为A、B、C,将通过reshape后的A、B转置做矩阵乘法再通过soft-max得到空间特征图Y,其中i,j是像素坐标,Yi表示像素j对像素i的位置的响应,ωa、ωb为要学习的权值矩阵,Y中每个元素Yi:

接着将Y转置与C做乘积再乘以权值系数再reshape为原始形状,最后与原始特征X相加得到输出O,每个位置的结果特征O是所有位置和原始特征的加权和。它具有全局上下文视图,并根据空间注意力图选择性地聚合上下文。其中ωc为要学习的权值矩阵,并逐渐地学习分配到更大的权重。其中每个元素Oi:
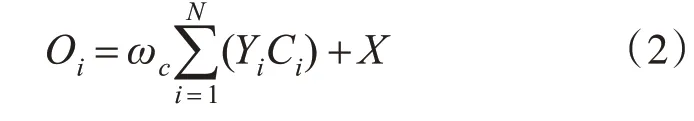
3.2.2 通道注意力
CNN对于高层特征只产生一个粗略的结果,一些关键区域往往会被忽略,因此引入通道注意力机制(CA,如图4所示),这里的通道注意力机制采用非对称卷积的方式,逐步压缩通道改变卷积方向,为文本区域表现出高响应的通道分配更大的权重。

图4 通道注意力CA
如图4所示,高层特征X大小为H*W*C,首先对每个通道的特征进行平均池化操作来获得通道的特征向量。接着使用两个全连接层来获取通道依赖信息,最后通过sigmoid归一化处理,最终映射到通道特征向量。
3.3 边界重定函数
输出由两个模块组成,旋转回归框和注意力分数图。对于旋转回归框,直接采用IoU和旋转角度来指导回归任务的学习,然而IoU在预测框和边界框不重合时没有办法做出优化效果,而且在边界框的不同重叠区域的情况下IoU会出现相同的情况。因此采用一种新的IoU计算方式,先计算任意两个轴对齐的矩形框的最小闭包区域a和b的面积,再计算IoU,再计算闭包区域中不属于两个框的区域面积占两个区域并集面积的比重,最后用IoU减去这个比重得到新的IoU'。由此可见IoU只关注重叠区域,而IoU'在关注a与b重叠区域时还关注在最小闭包区域a与b不重叠的区域。此时边界回归损失函数记为LIoU'。

则最终的损失函数L为

4 实验结果与分析
4.1 数据集
为了验证方法的有效性,在三个公开的场景文本检测数据集上进行了实验:ICDAR2011,IC⁃DAR2015以及天池数据集。本文进行了三组对比实验,分别是EAST、Pixel-link和本文方法,基础网络都采用VGG16。学习率初始值为10−3迭代10−5为止,整个实验在深度学习框架TensorFlow上进行,为了保证效率,将图像调整为384*384的尺寸大小,每个模型在GPU为GTX1070上训练,训练到性能停止改善为止。
4.2 实验结果与分析
本实验分别采用EAST、Pixel-link和本文改进的方法在三种数据集上进行了对比实验,图5展示了三种方法在三个数据集上的测试结果,不难发现对于EAST而言,长文本和较大文本的检测不够准确。Pixel-link虽然可以检测很长的文本行。然而,这种方法后处理步骤非常复杂,容易受到复杂背景的干扰,导致检测准确率反而下降。而改进的方法在一定程度上避免了上述问题,可以从图中看出,改进的方法在检测文本上准确率进一步提升,有效地提高了对长文本的检测准确率。

图5 EAST、Pixel-link以及本文方法分别在三个数据集上的测试结果
本文采用自然场景文本检测的三个标准评价指标:准确率(precision)、召回率(recall)以及F值(F-measure)来比较三种方法的优劣[14]。其中F值表示准确率和召回率之间的目标检索平衡度,准确率(P)的计算方式为

召回率(R)的计算方式为

F值与准确率(P)和召回率(R)之间的关系为

其中M(P,G)表示检测正确的文本框的集合,G表示真实文本框的集合,P表示网络检测出的文本框结果的集合。
如表1~3所示,本文方法相较于其他两个方法在三个数据集上均获得了稳定的提升,从表中可以看出,本文的方法在三个数据集上F值均达到了84%以上,提升了效率。

表1 三种方法在ICDAR2011数据集上的评价指标

表2 三种方法在ICDAR2015数据集上的评价指标

表3 三种方法在天池数据集上的评价指标
5 结语
本文提出一种基于EAST改进的自然场景文本检测器。通过加入ASPP来提升网络的感受野,提升网络对上下文信息的获取能力。同时通过加入非局部注意力机制和边界重定函数,在不牺牲速度的前提下,扩大感受野,对文本边界进一步精准定位,极大地改善了EAST对于长文本和较大文本的误检和漏检。实验证明,改进的方法在精度上明显优于以往的方法,F值在ICDAR2011、ICADR2015以及天池三个数据集上的F值均达到了84%以上。一方面由于本文的方法与EAST一致都是检测整个文本框的整体方向,从而检测多方向的文本,但是对于竖直文本检测效果的性能较差,因此未来的研究方向可能会是结合本文方法与文本方向来检测竖直文本。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
计算技术与自动化(2022年1期)2022-04-15
计算机研究与发展(2022年1期)2022-01-19
上海师范大学学报·自然科学版(2019年5期)2019-12-13
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
