
AdaBoost算法在乳腺癌疾病预测中的研究
2021-08-06 19:49叶琳石胜源罗铁清
计算机时代 2021年7期
叶琳 石胜源 罗铁清
摘 要: 为了研究AdaBoost算法在乳腺癌疾病预测中的应用,收集乳腺癌诊断数据集并按照一定的比例拆分成测试数据和训练数据。利用AdaBoost、GaussianNB、KNeighbors算法模型分别进行测试,以准确率为评价标准来评价模型性能的好坏。当测试数据占30%时,AdaBoost算法模型预测乳腺癌疾病优于其他算法模型,准确率为96.49%。通过综合评价机制考察发现,AdaBoost算法模型能从复杂的多因素中找到预测乳腺癌的重要影响因素,这对快速识别引起乳腺癌疾病的特征以及早期病人的有效治疗具有重要意义。
关键词: 乳腺癌; 机器学习; AdaBoost; 诊断预测
中图分类号:TP391.41;TP181;R737.9 文献标识码:A 文章编号:1006-8228(2021)07-61-04
Study of AdaBoost algorithm application in breast cancer disease prediction
Ye Lin, Shi Shengyuan, Luo Tieqing
(School of Informatics, Hunan University of Chinese Medicine, Changsha, Hunan 410208, China)
Abstract: In order to study the application of AdaBoost algorithm in breast cancer disease prediction, breast cancer diagnostic data sets were collected and divided into the test data and training data according to a certain proportion, which were be used respectively in the test with AdaBoost, GaussianNB, and KNeighbors algorithm models, and the accuracy rate was used as the evaluation criteria to evaluate the performance of model. When the test data accounted for 30%, the AdaBoost algorithm model predicted breast cancer disease better than the other algorithm models, with an accuracy of 96.49%. Through the investigation with comprehensive evaluation mechanism, it is found that AdaBoost algorithm model can find the important influencing factors for predicting breast cancer from complex multiple factors, which is of great significance for rapid identification of the characteristics of breast cancer diseases and effective treatment of early patients.
Key words: breast cancer; machine learning; AdaBoost; diagnostic prediction
0 引言
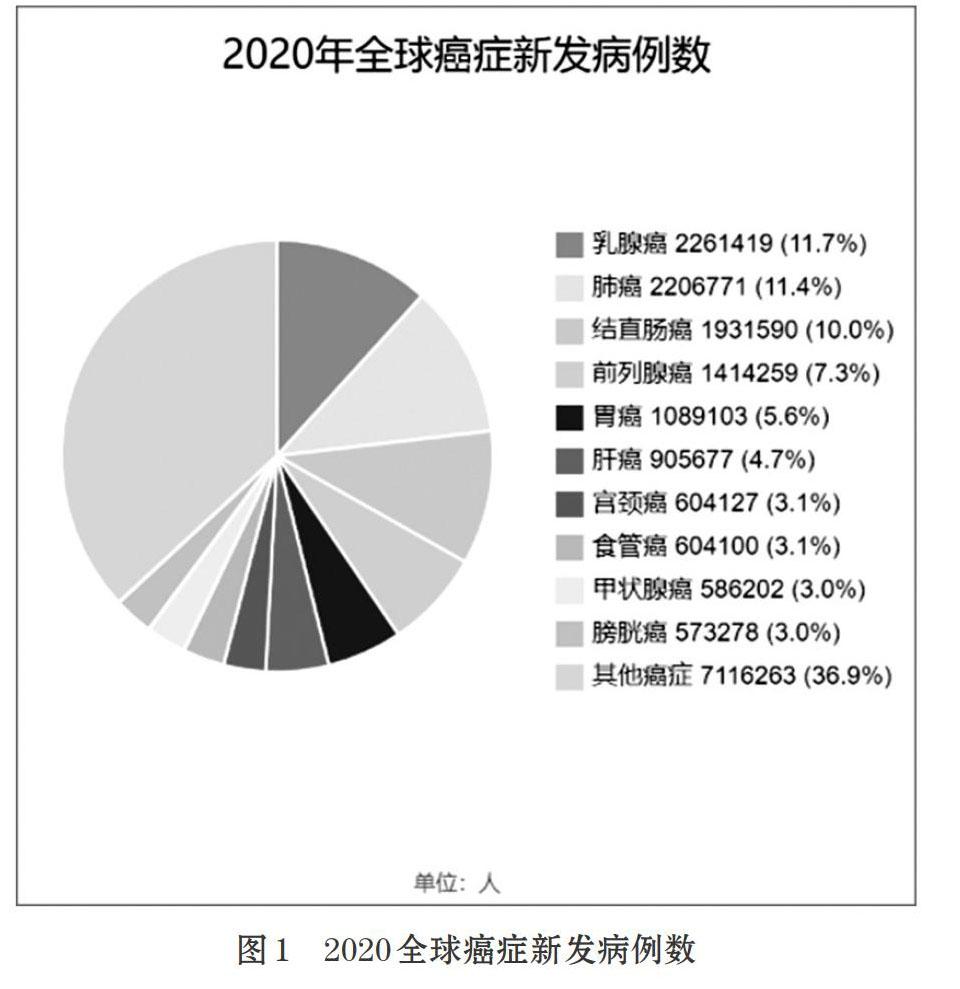
Hyuna Sung[1]等人在癌症领域顶级专刊《CA:A Cancer Journal for Clinicians》(IF≈292)发表题为《Global cancer statistics 2020:GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries》的研究论文,论文对全球癌症疾病负担信息进行了更新。2020年,全球估计有1930万新发癌症病例。全球癌症发病率前五名依次是乳腺癌(226万,11.7%)、肺癌(221万,11.4%)、结直肠癌(193萬,10.0%)、前列腺癌(141万,7.3%)、胃癌(109万,5.6%)。由此可见,乳腺癌已经成为全球第一大癌症,具体情况如图1所示。
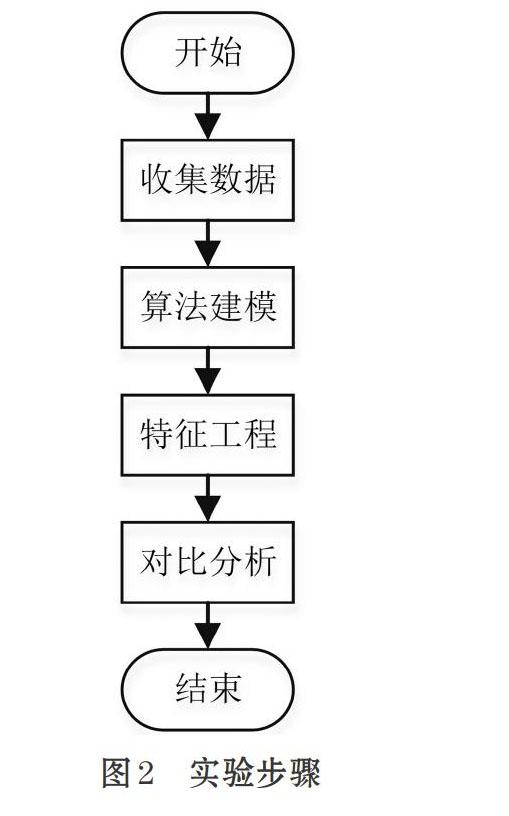
值得思考的是,第二名肺癌男女均会患病,乳腺癌患者超过99%为女性,而女性人数约占全球总人口的一半,但乳腺癌新发病人数居然超过了肺癌,这是我们必须要重视的。由于乳腺癌诊断十分复杂,因此借助机器学习相关算法模型来对乳腺癌进行准确评估和预测迫在眉睫。本文将AdaBoost与GaussianNB、KNeighbors算法模型做对比,最终发现AdaBoost算法模型相较于另外两种算法模型能够更为准确的预测乳腺癌,实验步骤如图2所示。
1 对象与方法
1.1 研究对象
本文实验所用的乳腺癌数据来源于UCI repository[2]上美国威斯康星州乳腺癌(诊断)数据集中部分数据,共计569例,数据信息包括id(标识),diagnosis(M:恶性,B:良性)以及乳腺肿块信息,乳腺肿块信息包括radius(半径)、texture(文理)、perimeter(周长)、area(面积)、smoothness(平滑程度)、compactness(致密性)、concavity(凹面)、concave points(凹点)、symmetry(对称性)、fractal_dimension(分形维数)这10个特征的mean(平均值)、se(标准差)和worst(最大值),共计32个字段。
1.2 数据预处理
实验前需要对乳腺癌诊断数据集进行清洗,在JupyterNotebook中剔除无意义字段id,剩余31个字段分别代表diagnosis以及radius,texture,perimeter,area,smoothness,compactness,concavity,concave points,symmetry,fractal_dimension这10个特征mean、se、worst维度。
1.3 AdaBoost模型的建立
AdaBoost算法是一种基础的机器学习方法,根据曹莹[3]等人总结的算法核心思想,得出实验中AdaBoost分类器利用同一种弱分类器,根据弱分类器的错误率分配不同的权重参数,最后累加加权的预测结果作为输出。实验研究的结局变量为乳房肿块良性或恶性,是研究的根本目的。解释变量为对乳腺癌发生率有影响的危险因素,如area_mean,texture_mean、concavity_mean等,用于支持结局变量的准确性。
1.4 特征选取
相关系数矩阵热力图是特征之间相关系数可视化的一种方法,用来展示特征之间的相似程度。实验在JupyterNotebook中进行演示,用相关系数矩阵热力图展示特征之间的相关性,图中系数越大说明特征越相关,如图3所示。
参考相关系数矩阵热力图可以对特征进行降维处理,将相关系数大于0.7的特征perimeter_mean,radius_mean,compactness_mean,concave points_mean,radius_se,perimeter_se,radius_worst,perimeter_worst,compactness_worst,concave points_worst,compactness_se,concave points_se,texture_worst,area_worst,area_se,smoothness_worst,concavity_worst,fractal_
dimension_worst删除,保留剩余12个特征,再一次验证可以得出降维后的相关系数矩阵热力图,如图4所示。
2 结果
2.1 特征重要性评分
实验需要将乳腺癌诊断数据集拆分成训练集和测试集,其中测试集占比30%(test_size=0.3)。计算test_size=0.3以及随机种子数为42时的AdaBoost算法模型下12个特征的重要性评分,列出排名前10的变量和分数,如表1所示。
2.2 模型预测性能评价
为了对比在test_size=0.3和随机种子数为42情况下的AdaBoost算法模型与其他两个算法模型的性能,在模型测试前需要进行参数优化,使用表1當中10个特征进行测试并比较,使用混淆矩阵进行预测结果的分类,共分为 TP,FP,FN,TN四类,如表2所示。
本文给出三种不同方法的混淆矩阵,分别对应了真恶性、假恶性、假良性和真良性四种情况下数据的分布[4],不同算法模型的数据分配如表3所示。
实验结果以准确率作为评价标准,由混淆矩阵可知,AdaBoost算法模型准确率为96.49%、GaussianNB算法模型准确率为95.91%、KNeighbors算法准确率为90.06%,如图5所示。从图5中的实验数据可以看出当test_size=0.3且随机种子数为42时AdaBoost算法模型的准确率高于另外两种算法模型。
2.3 最优特征
为了提高模型的泛化能力,实验采用5折交叉验证[5]降低泛化误差,其原理将数据集分割成5个子集,一个单独的子集被保留作为验证模型的数据,其他4个子集用来训练。交叉验证重复5次,每个子集验证一次,平均这5次的结果得到一个单一估测。这个方法的优势在于同时重复运用随机产生的子集进行训练和验证,每个子集都被验证一次。在AdaBoost算法模型的基础上经过5折交叉验证可以找到最佳特征为texture_mean,area_mean,smoothness_mean,concavity_
mean,texture_se,symmetry_se,fractal_dimension_se,symmetry_worst的同时也预示着预测乳腺癌需要的最佳特征数为8,如图6所示。
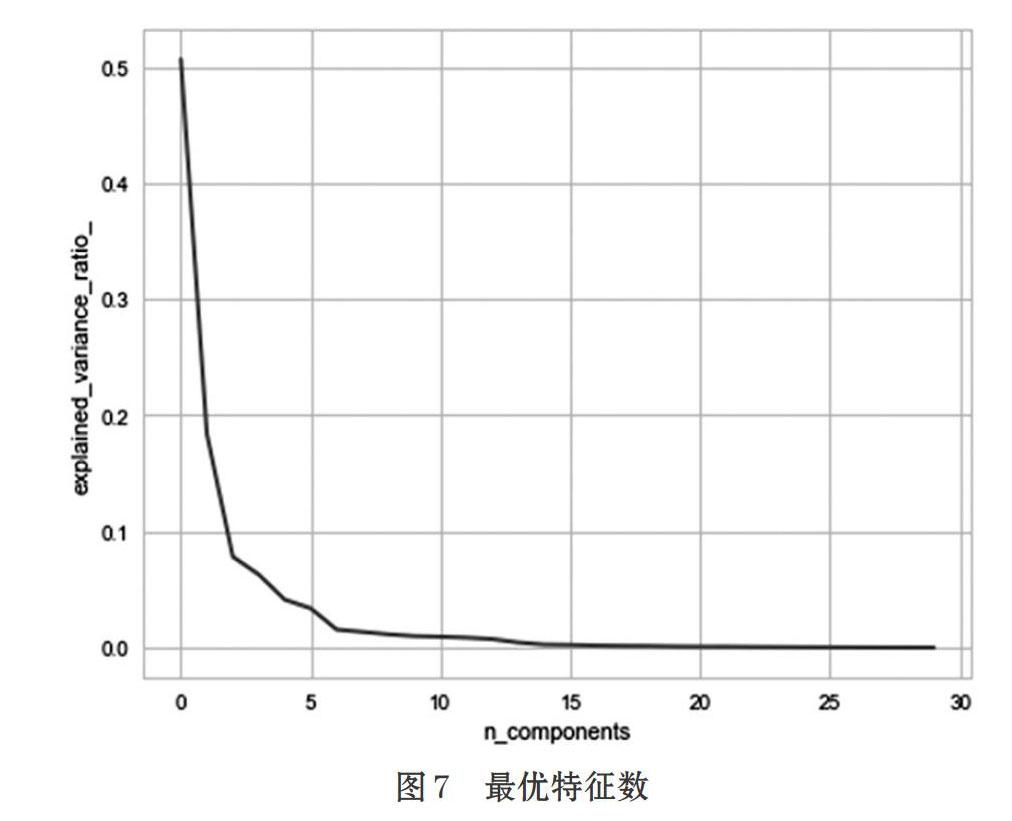
主成分分析(Principal Component Analysis,PCA)[6]是对特征进行综合评价的方法之一,其原理是通过投影的方法消除重叠信息,实现数据的降维[7]。经过PCA可知最优特征数为1,如图7所示。参照表1数据选择得分最高的变量area_mean作为最优特征,该特征预测乳腺癌准确率可达96%以上。
3 结束语
本文提出基于AdaBoost算法的乳腺癌疾病预测方法并将AdaBoost算法模型与GaussianNB、KNeighbors算法模型进行比较,证明在乳腺癌疾病诊断中,AdaBoost算法模型相对于另外两种算法模型取得了良好的效果。此研究对于识别乳腺癌患者并为其进行及时和有效的治疗有一定的现实意义。但本研究采用的是美国威斯康星州乳腺癌诊断数据中的一小部分数据,数据受地域和数量的限制使得最终实验结果具有局限性,需要进一步扩大数据来源和使用大样本数据验证结果的适用性。
参考文献(References):
[1] Hyuna Sung, Ferlay Jacques, Siegel Rebecca-L, et al.Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J].CA:A Cancer Journal for Clinicians.
[2] UCI repository.乳腺癌诊断数据集[EB/OL].http://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+%28diagnostic%29.
[3] 曹莹,苗启广,刘家辰等.AdaBoost算法研究进展与展望[J].自动化学报,2013.39(6):745-758
[4] 卢星凝,张莉.基于属性约简和支持向量机集成的乳腺癌诊断决策[J].计算机应用,2015.35(10):2793-2797
[5] 张中文,姚婷婷,张海泉等.基于交叉验证的组合诊断方法在乳腺肿瘤诊断研究中的应用[J].中国卫生统计,2020.37(2):166-169
[6] 孔浩,郭庆梅,王慧慧等.主成分分析法在中药质量评价中的应用[J].辽宁中医杂志,2014.41(5):890-892
[7] 符刚,张玥,曾强等.主成分分析法在北方某市饮用水水质综合评价中的应用[J].中国预防医学杂志,2015.16(12):955-960
猜你喜欢
中老年保健(2022年6期)2022-08-19
现代临床医学(2022年1期)2022-02-12
中国生殖健康(2019年2期)2019-08-23
中国生殖健康(2019年6期)2019-01-06
祝您健康(2018年5期)2018-05-16
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
