
基于深度学习的低精跨模态人脸识别
2021-08-06 05:48:30王铖东
现代计算机 2021年16期
王铖东
(四川大学计算机学院,成都610065)
0 引言
人脸识别是一项匹配同一个人面部图像的任务,随着深度学习的出现,该问题发展迅速。通过深度卷积神经网络的多个隐藏层提取的特征包含有代表性的信息,可以有效地区分不同个体[1]。随着人脸识别问题的发展,研究者们开始关注于其中更富有挑战性的问题:如姿态、光照、表情、年龄等的人脸识别问题[2-3]。与上述问题不一样的是,跨模态人脸识别用于比对识别的人脸图像差异更大,且目前的跨模态人脸识别相关的数据集规模小,为识别带来了巨大的困难。
跨模态人脸识别的目的是识别数据分布或外观差异较大的不同模态人脸图像[4]。常见的如:近红外光与可见光、远红外光与可见光、素描与照片、正面与侧面,低分辨率与高分辨率的人脸识别等问题都是跨模态人脸识别问题。跨模态人脸识别问题主要应用于安防、刑侦等场所。最为典型的应用场景是:安防部门系统库里的人脸图像是质量良好的可见光图像,而监控所拍摄得到的图像相对而言质量差,且有很多夜间拍摄的近红外图像。受制于数据模态间的巨大差异,已有的人脸识别模型准确率下降显著。
跨模态人脸识别问题的主要难点在于两点。一是不同模态下的数据差异大,也可以说是数据分布的差异大,而这种差异很可能会导致类内距离超过类间距离。因此,如何有效减少这种数据分布上的差异是跨模态人脸识别问题面临的主要难点之一。另一个难点是,相对于一般的人脸识别任务来说,跨模态人脸识别任务目前所拥有的数据集规模小,因此直接使用一般的人脸识别方法很容易过拟合。
在跨模态人脸识别问题中,目前研究者们主要针对单个的跨模态因素的研究,对于实际的场景仍有一定的差距。如监控拍摄的人脸图像通常不仅是近红外的图像,而且其分辨率低,姿态差异明显。针对该问题,本文进一步引入了低精跨模态人脸识别问题。该问题面临的困难与挑战同跨模态人脸识别问题类似,但更为巨大,而其更为接近于实际的应用场景,是具有研究意义的研究问题。
本文依据目前主流的跨模态人脸识别方法,针对低精跨模态人脸问题,提出了一种基于图像合成与模态不变特征表示相结合的方法。该方法先利用基于图像合成的方法,将低精数据(信息量匮乏)转换为高精数据(信息量充足),再通过模态不变特征表示的方法减小近红外与可见光之间的模态差异,完成最终的低精跨模态人脸识别任务。使用这种方法,主要是考虑到不同信息量差异下,不同方法的适用性与表现会有所不同。相比较而言,基于合成的方法有助于跨越信息量差异大的模态差异,而基于模态不变特征表示的方法更适宜于信息量差异不大,但数据的分布不一致的情形。
1 方法
1.1 身份保持循环生成对抗网络
低精度的图像信息量相对于高精度的图像信息量差异巨大,相关的跨模态人脸识别算法在面对现实场景下大量的低精数据,难以达到预期的效果。本文基于循环生成对抗网络的基础结构[17],将低精数据转换为对应的高精数据,并且在转换过程中保持其身份信息。实验证明,通过该转换过程后的数据在跨模态人脸识别方法上能够达到更好的效果。
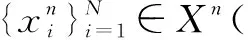
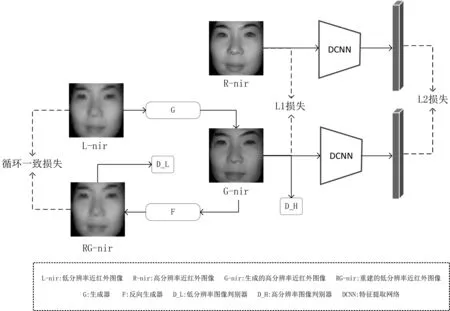
图1 身份保持循环生成对抗网络低分辨率转高分辨率网络结构图
为了在进行图像生成的过程中保持身份信息的不变性,本文在循环生成对抗网络的基础上引入了生成图像与其对应的高分辨率图像的L1损失,以及它们在特征层上的L2损失。同时,在整个过程中,特征提取器的参数是固定的,网络只训练生成器G和F的参数。且特征提取器的参数已在原始的近红外与可见光数据集上进行了微调,以保证图像合成的过程中,L2损失函数所依据的身份信息更加真实、准确。
在该网络的所有损失函数上,除了原始的循环生成对抗的网络的判别器损失、生成器损失,循环一致损失,本文进一步引入了像素级L1损失和特征级L2损失,用于进行身份保持的任务。这两个损失函数的具体表示分别为:像素级L1损失L_pixel:
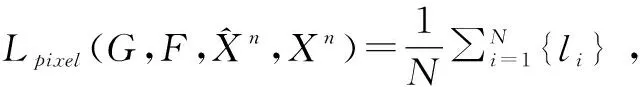
(1)
以及特征级L2损失Lfea:
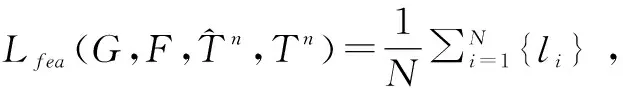
(2)
最终的损失函数为:
(3)
据此,我们可以得到最终的优化问题为:
(4)
通过对上述优化问题进行训练,网络中的生成器不断优化自身以用于“欺骗”判别器,而判别器则不断提高自身的判别能力,通过两者这样的不断对抗优化,生成器能够生成与真实高分辨率数据类似的数据分布,以使得判别器难以分辨。另外需要注意的是,由于在生成的过程中我们引入了身份保持的两个损失函数,这会使得生成器在整个过程中都会约束自身生成的数据与真实的数据身份信息相一致。通过这种方式,最终生成器能够将低分辨率图像在身份保持的情况下,转换为信息量更为丰富的高分辨率图像,为后面进行模态不变特征提取提供更为良好的条件。
1.2 基于三元组损失的模态不变特征提取
在经过本文提出的身份保持循环生成对抗网络的图像合成后,信息量匮乏的低分辨率数据已转换为了信息量更为充分的高分辨率数据。然而,通过网络合成的方式并不能得到与真实数据完全一致的数据分布。这种偏差本质上也是模态差异,但可以发现,尽管数据分布仍存在差异,但数据间的信息量的差异已经通过图像合成的方式大大减小。本文针对这种情形,在使用文献[9]作为特征提取网络的基础上,使用三元组损失函数,用于减小生成数据与可见光图像的模态差异。
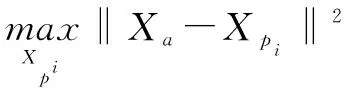
(5)
同时:
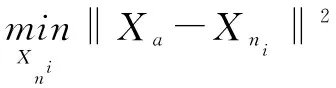
(6)
因此,对于每个小批量而言,最终的三元组样本对可以记为:
在上述情况下的样本对下,得到最终三元组损失函数为(本文取margin=0.3):
Ltriplet(Xa,Xp*,Xn*)=max(‖Xa-Xp*‖2-‖Xa-Xn*‖2+margin,0)
(7)
在生成数据与真实数据间的模态差异下,可能导致不同模态下的类内距离大于相同模态下的类间距离。通过对公式(7)的损失函数进行优化,可以有效地减小模态间的差异,从而使得特征提取网络能够提取到与模态无关的身份信息,进而能够有效提升生成数据与可见光数据上的跨模态人脸识别准确率。至此,通过上述两种方法的结合,我们能够有效地实现低精跨模态人脸识别任务。
2 实验
本部分介绍使用的数据集,数据集的处理,以及对实验的结果的细致分析。最后,将会对比本文提出的方法在近红外与可见光跨模态人脸识别问题,以及本文提出的低精跨模态人脸识别问题上与近期的其他方法的一些对比结果,以证明方法的有效性。
2.1 数据集描述
CASIA NIR-VIS 2.0数据集[6]是目前最大的跨模态人脸识别数据集之一,该数据集包括近红外人脸图像数据与可见光人脸图像数据。总共包含有725个个体,由4次采集得到。每个个体有1-22张可见光图像与5-50张近红外图像。这些图像包含不同的分辨率、光照条件、姿态、年龄、表情和是否带眼镜等变化因素,这些因素使得识别任务具有了更大的挑战性。在实验中,本文遵循文献[6]中的测试协议。在该协议中,实验的测试部分包含图库集和探测集,其中图库集中每个个体一张可见光图像,而探测集中的每个个体有多张近红外图像。本文通过对整个图库集计算相似度矩阵,计算并记录了识别准确率与验证准确率。
2.2 数据预处理
在该本部分的工作中,为了规范化输入数据,本文首先对数据集进行了剪裁工作。通过使用MTCNN[7]对数据进行人脸检测,并设置剪裁大小为128×128,得到剪裁后的数据集。为了进行低分辨率近红外图像和高分辨率可见光图像的识别工作,本文进一步使用双线性插值的方法对数据进行下采样,下采样的数据大小为22×22。
2.3 消融实验
2.3.1 身份保持跨模态生成消融实验
为了分析身份保持模态生成方法的有效性,本文对比了基准、只使用L1损失函数、只使用L2损失函数,以及同时使用L1和L2损失函数的性能情况。在性能评估过程中,通过对低分辨率近红外数据进行身份保持的跨模态生成得到对应的高分辨率近红外图像,再计算生成图像与高分辨率可见光图像的相似度矩阵。在严格遵循文献[6]中的视图1测试协议的情况下,得到的实验结果如表1所示。
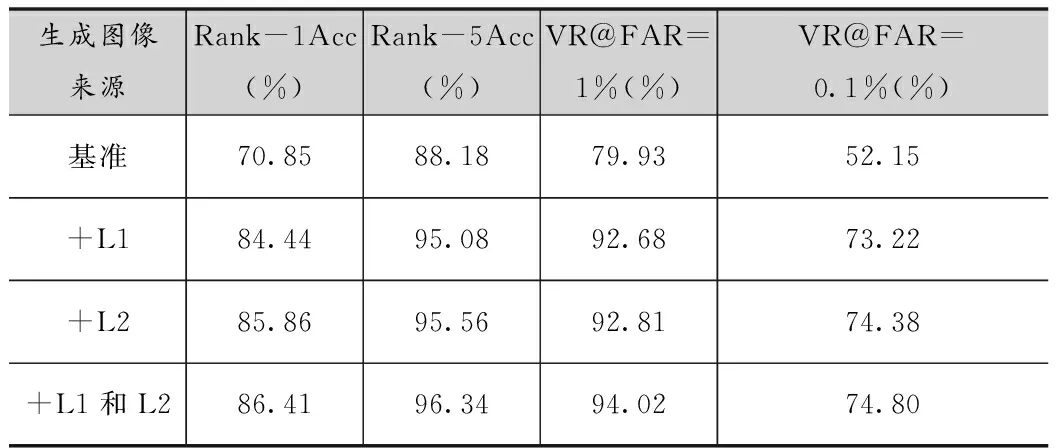
表1 在CASIA NIR-VIS 2.0数据上的身份保持跨模态生成消融研究实验结果
通过表1,可以发现,原始的循环对抗生成网络本身是不具有良好的身份保持性能的,它的主要工作是进行模态的转换与图像生成。由于在实验的数据构成中,我们具有良好的一一对应的低分辨率与高分辨率数据,而像素级别上的L1约束与特征级别上的L2约束本身的目标上一致的,因此它们均能够对身份保持起到较为接近的有效结果。但从我们的身份识别的最终目标上来说,L2约束从身份特征上的约束更接近我们的目标,可以看到它也的确起到了更好的效果。另外,在同时使用两者的情况下,相对于单个约束,仍有小幅度的提升。
2.3.2基于三元组损失的模态不变特征表示方法
在这一部分,本文主要通过从两个不同的模态差异去进行评估。首先是在近红外到可见光的跨模态人脸识别问题上,通过计算CASIA NIR-VIS 2.0数据集中的近红外与可见光人脸图像的相似度矩阵,并在严格遵循文献[6]中的视图1协议的情况下,得到的实验结果如表2所示。
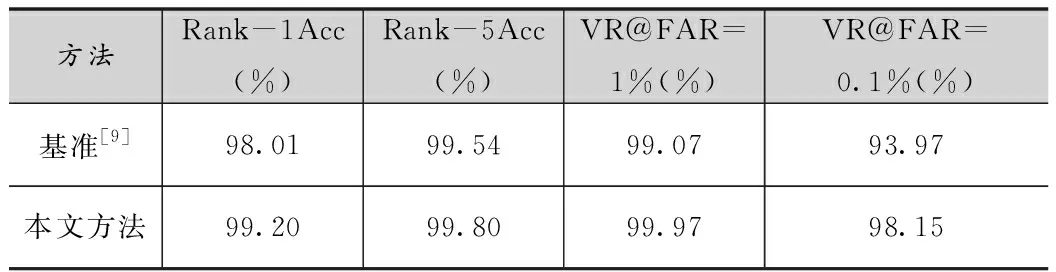
表2 在CASIA NIR-VIS 2.0数据集上的三元组损失函数实验结果
通过表2可以看出,通过三元组损失函数,确实能够有效的减小近红外与可见光之间的模态差异,提升跨模态人脸识别的性能。除此之外,为了验证该方法能否在本文中的生成数据上生效,同样对生成数据进行了实验验证,其结果如表3。
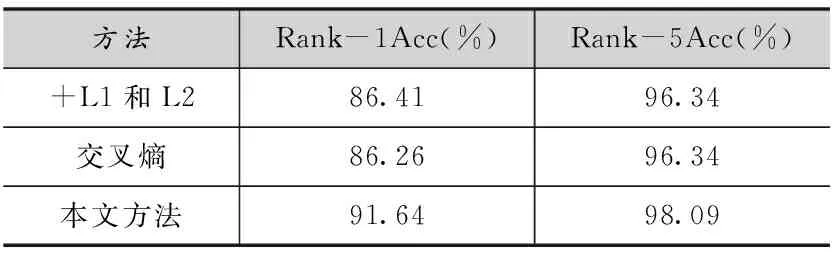
表3 在CASIA NIR-VIS 2.0生成数据集上的三元组损失函数实验结果
通过表3可以看出,该方法的确能够有效提升生成数据的识别性能。至此,通过本文提出的方法,在低分辨率的CASIA NIR-VIS 2.0数据集上,成功将Rank-1识别准确率提升到了91.64%。实现了一个完整的低精跨模态人脸识别问题的解决方案。
2.3.3 三元组损失函数正样本数s评估实验
在三元组损失函数的设计中,本文引入了正样本数s,为了找出合适的正样本数s,本文在生成数据上对参数s进行了评估实验,得到的实验结果如表4所示。
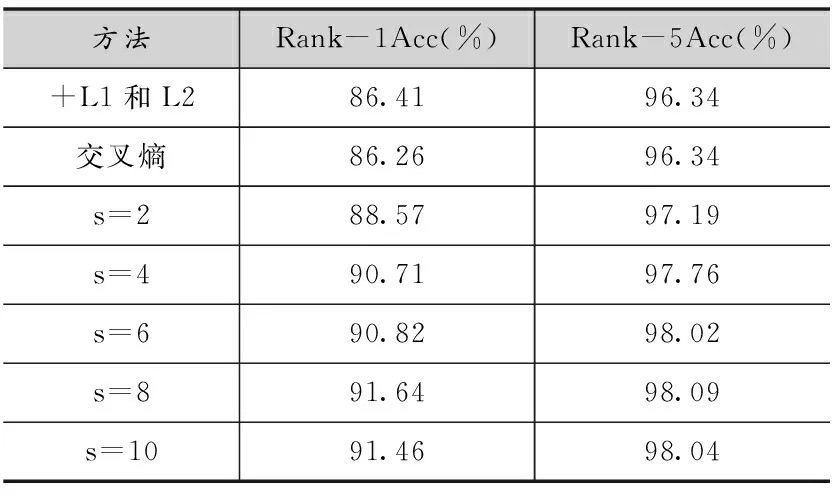
表4 在CASIA NIR-VIS 2.0数据集上的生成数据的三元组损失函数正样本数s评估实验结果
通过表4可以看出,随着正样本数s的增大,可以找到更为困难的三元组样本对,但受限于数据规模,以及过于困难的样本对会引入额外的噪声,因此随着s的大小超出一定范围,性能反而会出现衰减,在本文的实验场景下,当s=8时,能够达到最好的识别性能,为Rank-1准确率91.64%。
2.4 对比实验
2.4.1 基于三元组损失函数模态不变特征表示的方法与其他现有方法对比实验
在表5中,本文在严格遵循文献[6]中的视图2协议的情况下,与其他的基于深度学习的跨模态人脸识别算法进行了对比,其中包括HFR-CNN[10]、TRIVLET[11]、ADFL[12]、CDL[13]、WCNN[8]、DSU[14]、RM[15]、RDFL[5]。其中RDFL通过图像内的相关关系来优化学习模态不变特征,可以看到,本文提出的方法相对于RDFL在Rank-1的准确率上提高0.33%,进一步逼近100%的准确率,在表中的方法中,识别性能与验证性能均达到了最高。
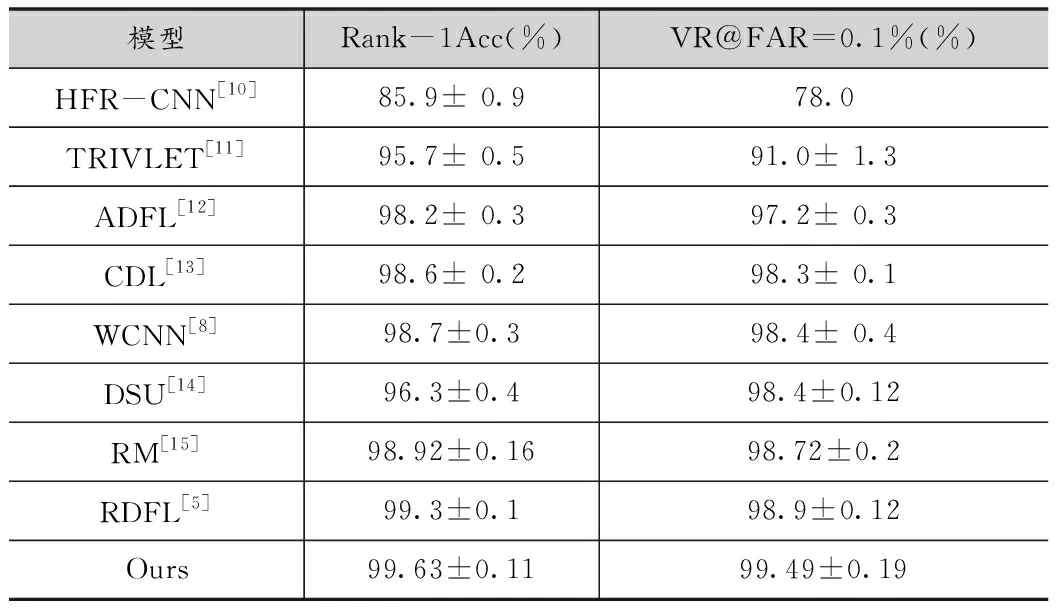
表5 使用三元组损失函数在CASIA NIR-VIS 2.0数据集上的十折交叉验证与其他方法对比
2.4.2 多重跨模态人脸识别问题与其他方法对比实验:
在表6中,本文在严格遵循文献[6]中的视图1协议的情况下,对比了低分辨率图像、通过插值的超分图像,通过SICNN[16]进行超分的图像的性能情况。可以看出,在低分辨率与近红外光的两种因素的影响下,识别任务已经变得十分困难。本文提出的方法能够有效地减少这一巨大的模态差异,得到的Rank-1准确率91.64%相对于CycleGAN[17]提升了超过20个百分点,为低精跨模态人脸识别问题打开了一个良好的开端。
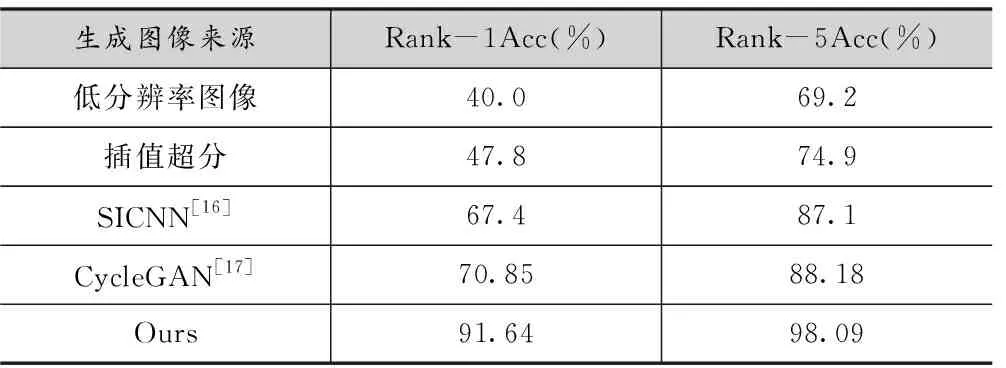
表6 在CASIA NIR-VIS 2.0数据集上的多重跨模态人脸识别问题性能对比
3 结语
本文提出的方法的贡献点主要如下:
(1)提出一个新的具有研究价值与意义的问题:低精跨模态人脸识别问题,并得到了一个完整的解决方案与网络模型。
(2)提出基于图像合成与模态不变特征表示相结合的方法,能够有效地进行模态转变与模态不变特征提取。
(3)本文在CASIA NIR-VIS 2.0数据集上进行了实验,在近红外与可见光跨模态人脸识别问题上达到了Rank-1准确率99.63±0.11%的结果,且在低精跨模态人脸识别问题上得到了目前最好的识别性能。
但可以看到,该方法限制了低精度与近红外两种跨模态问题的解决顺序,同时,在最终的性能表现上仍然有一定的提升空间。在未来的工作中,我们将针对这些问题,改进相关的网络结构,得到更为简洁与高性能的解决方案。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
江西教育·职教版(2022年9期)2022-04-29 00:44:03
作文中学版(2022年1期)2022-04-14 08:00:34
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
学生天地(2020年31期)2020-06-01 02:32:06
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
今日农业(2019年15期)2019-01-03 12:11:33
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
计算机工程(2015年8期)2015-07-03 12:19:07
