
百度迁徙规模指数构造方法反演
2021-08-04 03:46:12王聪,严洁
电子科技大学学报 2021年4期
王 聪,严 洁
(1. 四川警察学院计算机科学与技术系 四川 泸州 646000;2. 四川警察学院道路交通管理系 四川 泸州 646000)
作为分析人口迁徙规律的重要工具,百度迁徙网站[1]提供了城市和省区间迁徙的人口比例和总体迁移规模估计,为COVID-19疫情防控提供了重要参考。然而,百度迁徙规模指数作为一个无量纲数,其构造方法并未公开,仅能从有限的信息推知该指数与实际迁徙人口可能存在正相关特征。目前国际疫情防控形势仍不乐观,输入性疫情在国内仍时有局部性传播。考虑到人类迁徙行为是COVID-19迅速传播的主要驱动力[2],从防范疫情全国性二次蔓延的立场出发[3],分析百度迁徙的数据构造方法及与真实人类迁徙行为的对应关系,从中反推出迁徙行为的确切人数,可以为研究总结疫情防控规律提供有益参考。
来自移动通信网络的数据是公共卫生管理的重要研判依据[4]。文献[5]利用复杂网络理论拟合人类迁徙与流行病学传播的关系,发现相对于节点间的经纬度距离,疫情传播与节点的等效距离相关性更强,而节点间的人类迁徙流量是等效距离的核心构成部分。因此,在COVID-19疫情爆发初期,考虑人类迁徙特征的流行病传播研究就得到了广泛关注。文献[6]利用城市间航空流量数据和腾讯人类迁徙数据,以种群传播模型进行建模。由于航空并非中国大陆出行的首选工具,该研究对疫情初期传播过程的解释能力存在缺陷。曾在区域经济学[7]、城市经济学[8]和人口地理学[9]等领域得到应用的百度迁徙网站也已重新开放,公开了百度依托移动互联网采集的全国300余个地级市和30余个省(直辖市,自治区)的人类迁徙状况。百度迁徙网站的数据陆续更新至2020年5月初,并保留1月10日-3月15日的数据以供参考。文献[10]利用百度迁徙的数据初步调查了湖北省外部分城市迁入人口与疫情数据的关系,然而该分析仅局限于百度标注的流量较大的50个城市,相对于全国300余个地级市而言,覆盖面有所欠缺。文献[11]从百度迁徙数据中发现,各地累积确诊量和自武汉流入的人口总数高度相关,且次生传播链基本被斩断,因此提出了一种考虑输入病例和地区人口效应的定量化评估新型冠状病毒地区防控效果的近似方法。文献[12]利用百度迁徙的数据,对国内前50天疫情管控措施的有效性进行了细致分析,评估了旅行限制和社会疏导措施在防止传染病传播方面的效果。文献[13]以百度迁徙数据为依据,分析了限制城际人口流动,筛查/诊断/隔离/疑似密切接触者,以及社交隔离与个人安全防护等非医学干预手段的效果。该研究指出,此类措施在付出高昂经济代价的同时,可能使得患病人数减少了67倍。文献[14]使用了百度迁徙公布的包括武汉市历史与实时人口流动数据,以说明病例输入在疫情城际传播中的作用,并评估了防控措施的效率。文献[15]则使用从百度迁徙数据中提取出武汉到河南的记录,将河南省的输入性病例视为对武汉市的无偏抽样,以此估算出COVID-19在武汉的传播情况。文献[16]利用百度迁徙的数据,结合我国疾控中心的每日确诊病例数据训练SEIR模型,参考SARS的部分流行特征,利用LSTM神经网络预测了COVID-19疫情在国内的峰值和演化趋势。文献[17]利用2020年1月10日-23日的百度迁徙数据分析了中国大陆的疫情空间格局特征,指出在省域层面疫情严重程度主要受邻近特征与人口迁徙强度的影响。文献[18]利用百度迁徙数据分析了疫情对中国城市人口迁徙的影响和城市的恢复能力。以上工作存在的一个共同问题是将百度迁徙规模指数假定为每日铁路、公路和航空人口流量的近似拟合,而这一假设目前并没有明确的依据。因此,本文前期工作[19]利用公开新闻报道中的春运数据,证实了迁徙规模指数与实际迁徙人数呈粗略线性关系,并给出了一个线性系数的大致估计,以此为依据分析了COVID-19在早期的时空传播特征。
随着疫情在全世界的蔓延,部分研究人员也利用人类迁徙数据研究疫情在国外的传播与控制。文献[20]使用了包含547 166次航班,总计101 455 913名乘客的人类迁徙数据集,分析了遍及六大洲22个国家的人口迁徙与疫情流行状况的潜在关联性,并建议在限制高感染地区人口流动的同时,亦应对全球范围内的人口迁徙进行必要管控。涉及具体国家和地区的人口迁徙与疫情防控研究也普遍展开。文献[21]使用了由Teralytics提供的2020年1月1日-4月20日匿名手机漫游数据捕获美国每个县的实时移动趋势,利用这些数据来生成社交隔离评价指标,并结合流行病学数据来探索COVID-19的疫情增长规律;文献[22]利用超过2 700万个移动设备的漫游记录,结合社交网站公开的数据,估计了美国不同区域社交隔离政策造成的地理和社会网络溢出效应;文献[23]将移动迁徙数据与人口普查统计数据相结合,建立了COVID-19在波士顿市区的精细传播模型。文献[24]利用一个包含意大利107个大区的人类迁徙网络数据集估计了改进SEIR传播模型的参数后指出,对人类迁徙与社交隔离的有效限制已将该国疫情严重程度降低了45%。文献[25]利用社交网站提供的近似实时的意大利人口迁徙数据进行了大规模分析,以研究交通管制策略对个人和地方政府经济状况的影响;文献[26]则关注了另一个疫情严重的国家巴西:通过航空数据的分析显示,约76%的巴西毒株可能在2020年2月22日-3月11日期间自欧洲传入,并主要在本地和本州内传播。此后尽管航空旅行人数急剧下降,但大型城市的输出效应不容忽视,当前该国的干预措施仍不足以控制疫情传播。文献[27]利用巴西数百万匿名移动漫游数据分析了COVID-19在巴西各州内最可能的传播方式,为公共管理计划制定与资源分配提供了参考。人类迁徙数据同样被应用于英国[28]和印度[29]等国家的疫情防控研究。
概览近期文献和成果,百度迁徙提供的数据已成为COVID-19疫情传播研究的核心数据来源之一。然而可能出于商业原因,百度迁徙提供的反映迁徙人口绝对规模的指数仅为无量纲数,公开的信息仅能表明该指数的构成与人口迁徙量正相关,仅能回答如“区域A的在某日的迁徙规模指数相对于区域B高约1.25”,该指数代表的物理意义不够明确,对于迁徙人口的绝对数量刻画存在缺陷。考虑到流行病学模型对参量的敏感性,这一概要性质的表述限制了相关研究的可靠性。因此,有两个问题是不得不回答的:1) 百度迁徙的数据与真实人类迁徙流量满足什么映射关系?2) 如何从百度迁徙数据反推出真实的人口迁徙流量?
为了解答这两个问题,本文首先概要阐述了百度迁徙的数据来源与获取,然后以一个具体行政区划为例,挖掘了百度迁徙数据中内蕴的一个恒等关系。在此基础上,从理论上反演了实际迁徙人口和百度迁徙指数的函数表达式。基于费马 - 欧拉定理(Fermat-Euler theorem)证明得到了真实迁徙人数的高概率互质特征,以此为基础对映射函数的参数进行了有效估计,最终得到了一个自洽的线性函数映射模型。真实数据集上对内蕴恒等式的验证结果支持了该模型的有效性。
1 百度迁徙数据概览
百度慧眼是百度推出的一个商业地理智能数据平台。作为商业数据中面向公众开放的部分,百度迁徙网站展示了中国大陆省市两级全部行政区划的迁入/迁出迁徙规模指数以及与上一年度同一时间节点的对比,并针对每个行政区划,分别按照地市级和省级级别提供了最热门的100个迁入来源区划和迁出目的区划,以及迁自/迁入对应区划的人口百分比。其迁徙边界定义为某一区划的行政管理地域,包括该行政区划所管辖的所有下级区划。
百度迁徙数据总体可以分为两部分:迁徙规模指数和热门迁徙区划的迁徙人口百分比。百度将这两个参量解释为:1) 迁徙规模指数:反映迁入或迁出人口规模,城市间可横向对比;2) 热门迁入/迁出地比例:迁入/迁出到某城市的人口与全国迁入/迁出总人口的比值。
典型的百度迁徙数据的核心内容可以整理如表1和表2所示。

表1 人口迁徙百分比

表2 特定日期迁徙规模指数列表
其中,表1的核心数据是特定区划迁徙人口的百分比。如表1的第一条目可解读为:2020年1月1日自上海市迁入北京市的人口占北京市总体迁入人口的1.62%;表2的值项是指定区划和指定方向的迁徙指数。如表2的第一条目表明,天津市在2020年1月1日的迁入规模指数为2.480 868。
2 百度迁徙数据中的内蕴等式

即迁徙规模指数与实际迁徙人数正相关。将迁徙规模指数的构造方法定义为真实迁徙人数的函数:


式中,以区划 α的视角统计迁至区划 β的人口数量,应等同于以区划 β视角统计的自区划 α迁入的人口数量。然后从真实数据中观察是否存在其他等式。对美元流通数据[30]、手机信令数据[31]、GPS漫游数据[32]和小样本的问卷调查[33]研究证实,群体视角下人类出行距离呈现出显著的幂律分布,或带指数截断的幂律分布特征,出行人数随出行距离增长将显著衰减。因此同省内的区划更有可能出现于彼此的Top100迁徙目的地中。宁夏回族自治区仅辖有5个地级市,是全国下辖地级市最少的省区之一,为缩短行文,在此将其作为示例进行考察。抽取2020年1月1日宁夏及所辖地级市的人口迁徙情况如表3~表5所示。
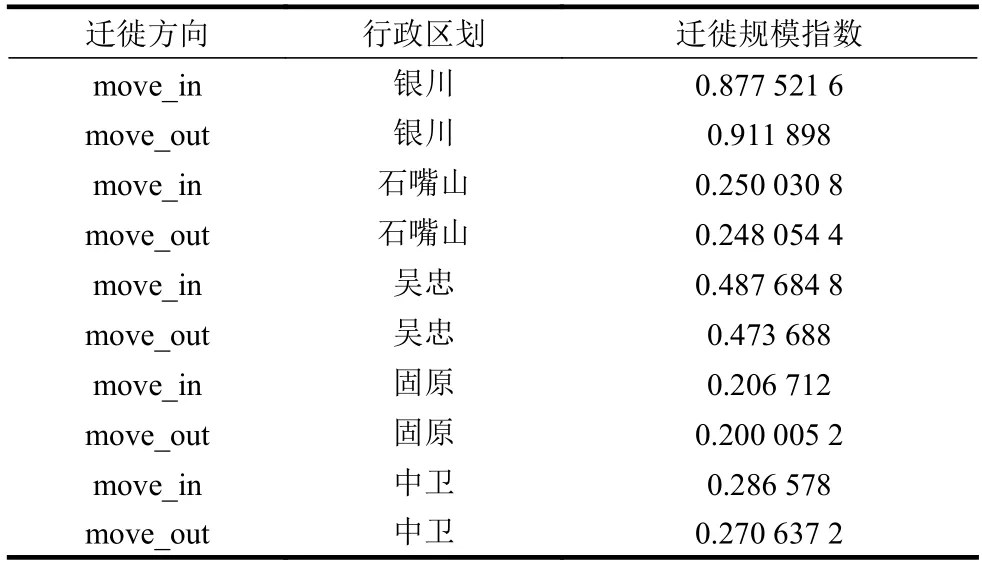
表3 宁夏所辖区划2020年1月1日迁徙规模指数统计
其中表3可解读如:2020年1月1日,银川市迁入规模指数为0.877 521 6,迁出规模指数为0.911 898;表4可解读如:银川市迁入人口中有18.13%来自石嘴山市,有31.06%来自吴忠市;表5可解读如:银川市迁出人口中有17.32%前往石嘴山市,有32.04%前往吴忠市。
观察发现,表3~表5中的内蕴等式为:
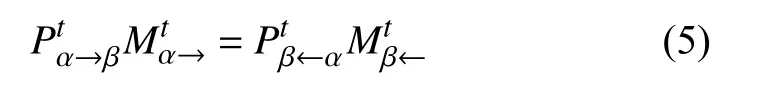
为校验该内蕴等式是否成立,首先定义相对误差RE(relative error):
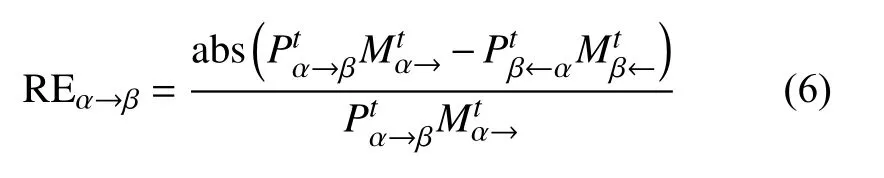
相对误差RE的作用是评价迁徙数据相对于式(5)的偏离程度。将表3~表5的数据代入式(6),以迁入数据为基准,得到以百分比表示的相对误差统计如表6所示。
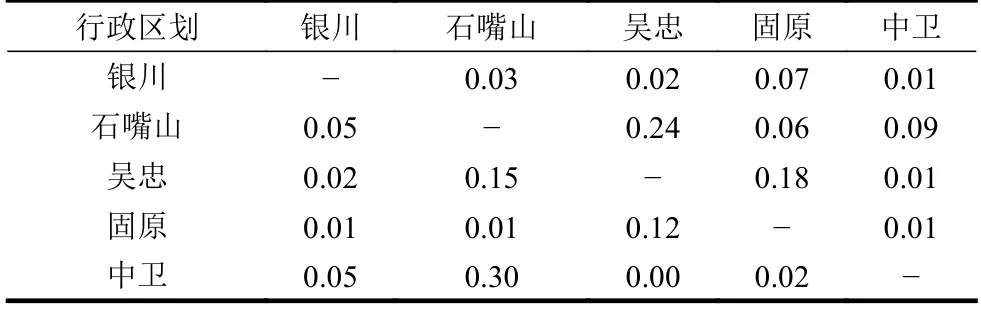
表6 宁夏所辖区划2020年1月1日迁徙指数相对误差统计 %
表中可见,最大的相对误差值仅为0.3%,平均相对误差也仅为0.07%。因此,从小样本数据来看,可以认为内蕴等式得到了有效验证。
3 迁徙规模指数构造反演与参数估计
3.1 迁徙规模指数构造过程推导
注意到式(1)对迁徙规模指数特征的刻画仍是极为粗略的,满足该式的函数形式也不是唯一的。因此有必要推导出迁徙规模指数的确定表达式,即式(2)的确切形式。
将式(2)代入式(5),可得:
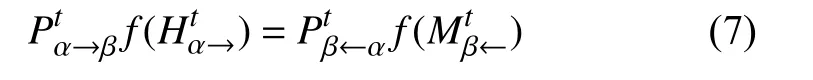

即,迁徙规模指数可表达为实际迁徙人数的线性函数。
3.2 参数估计
在爬取的数据中,迁徙指数至多保留至小数点后7位,因此首先排除迁徙指数上的舍入误差问题。考虑人口迁徙的随机性,若指数存在舍入误差,则尾数的最后一位的取值应近似服从均匀分布。抽取2020年1月-4月迁徙规模指数共95 590条,最后一位实际取值分布如表7所示:
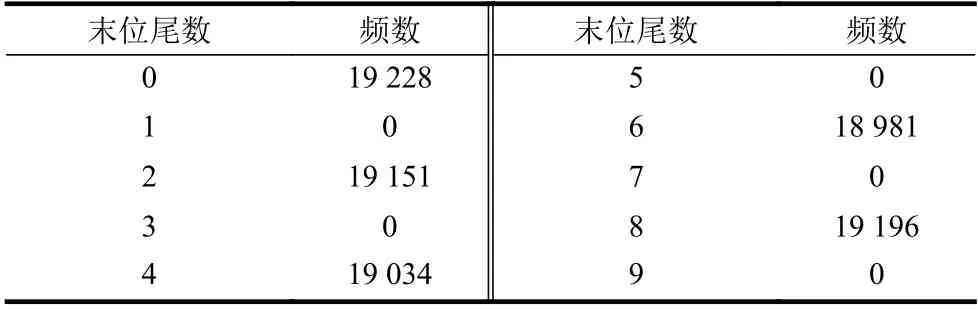
表7 迁徙规模指数尾数统计
其中,原生数据中小数点后有效数字不满7位的取值,以0补足。表中可见末位尾数全部为偶数,难以满足均匀分布推论,不应认为是偶然因素所致。因此有理由认为爬取的指数是一个精确的数值,可以排除舍入误差问题。

对181 701条迁徙规模指数记录(包含2020年数据,及对应的2019年历史数据)进行统计,其中仅包含44 703个不同的取值。因此有理由认为,该指数的取值是离散的,即推论1是成立的。于是将44 703个出现过的指数值进行排序并取级差,结果如图1所示。
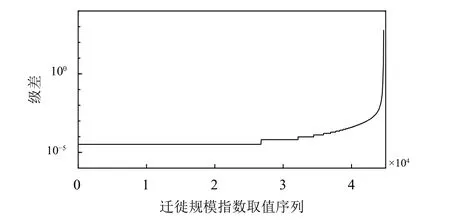
图1 迁徙规模指数取值级差
图中可以看到鲜明的离散特征,即不同取值之间的差值集中在有限个离散的值上,这为推论2的成立提供了可靠的依据。更为关键的现象是,无论是级差还是迁徙规模指数取值,都是最小间隔3.24×10-5的正整数倍,有理由认为是一个或多个自然人在迁徙规模指数上映射的结果。
接下来讨论实际迁徙人数的互质特征。根据费马-欧拉定理,s条记录值互质的概率P(s)可利用黎曼 ζ函数(Riemann ζ function, 当s为正整数时,ζ(s)退化为欧拉乘积公式)表示为[34]:
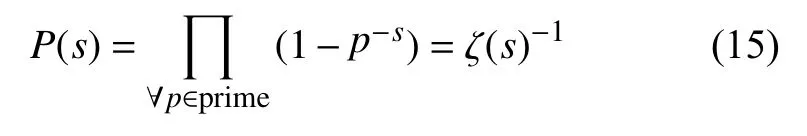
式中,p的值域被定义为质数集合。根据 ζ函数性质可知,当s≥1时 ,P(s)单调递增。特殊地,当s为正偶数时,ζ (s)的取值可解析地表达为:
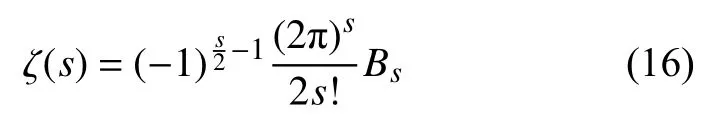
式中,Bs为第s项伯努利数(Bernoulli number)。
当s=10时,P(s)的值收敛至约99.9%;当s=14时,P(s)收敛至高于99.99%。即随机抽取不少于14条不同的迁徙人口值,其互质的概率超过99.99%,且随着抽取记录数量的增加,这一概率仍会进一步提升。而统计得到指数的取值高达4万余条,因此有理由认为,迁徙指数记录所代表的实际迁徙人数极高概率是互质的,其最大公约数为1。因此,可以认为当一个自然人映射到迁徙规模指数上时,有:
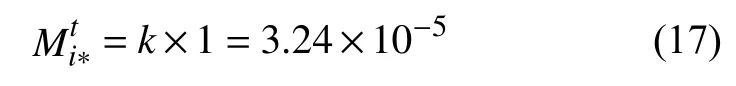
于是,将斜率k代入式(13),可得任一方向上百度迁徙规模指数的构造方法为:
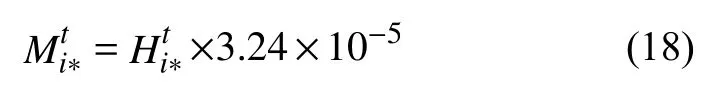
4 数据获取方法
4.1 数据访问接口
通过对百度迁徙网站Web页面的分析可知,迁徙规模指数数据来自接口:http://huiyan.baidu.com/migration/historycurve.json,该接口以HTTP GET方法访问,并携带必要参数如表8所示。

表8 迁徙规模指数数据访问必要参数
其中的id参数定义为以国家标准GB/T2260-2007定义的中华人民共和国行政区划代码[35],涵盖了所有省级区划及其(除直辖市)直管的下级区划。正常情况下返回JSON格式文本形如:

其中的有效数据为list字段,记录了2020年春运期间特定区划在特定日期的迁徙规模指数,以及以农历日期对齐的2019年同期数据作为对比。
地级市迁徙人口比例数据来自接口:
http://huiyan.baidu.com/migration/cityrank.json
省级迁徙人口比例数据来自接口:
http://huiyan.baidu.com/migration/provincerank.j son
以上接口以HTTP GET方法访问,并携带必要参数如表9所示。

表9 迁徙百分比数据访问必要参数
正常情况下返回JSON格式文本形如:


其中有效数据为list字段。"city_name"等字段以Unicode转义字符形式编码,使用时应进行解码。
4.2 数据污染与有效性校验
百度迁徙网站一种可能的反爬虫策略为随机投放污染数据。举例而言,本文初次爬取的三亚市在2020年2月2日迁出至地级市的数据即可能存在污染。与真实数据对比如表10所示。
限于篇幅,表10仅枚举前3位数据。因此为了确保爬取数据的准确性,采用了一种主-从爬虫框架,首先确保主从节点使用不同的IP地址,由主节点按日期爬取数据并进行校验。对于校验失败的数据,交由从节点重新爬取,以避免主从节点同时被远程主机屏蔽。
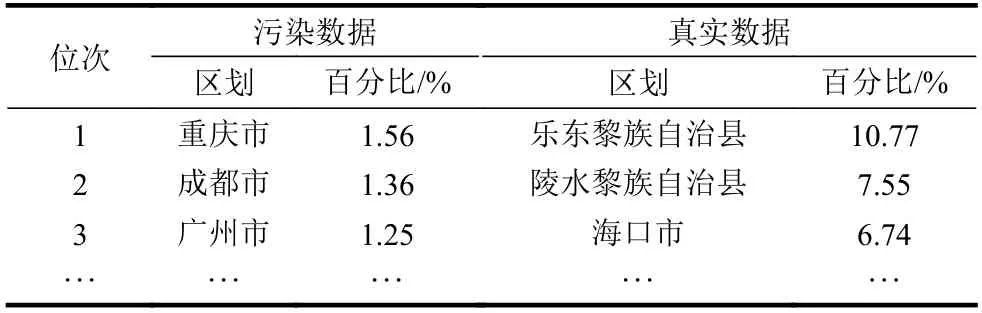
表10 污染数据与真实数据对比示例

5 内蕴等式有效性验证


首先考察市际迁徙流量是否满足本文提出的线性关系。在数据中,北京、上海等4个直辖市,以及湖北省潜江市、天门市和新疆维吾尔自治区石河子市、图木舒克市等直辖县级行政区划均被纳入城市区划进行采集和统计。数据中,约93.81%的记录误差位于舍入误差区间内,异常记录仅占约6.19%。意味着在城市间交通流量这个层面,线性映射模型的基本假定可以得到满足,数据测量误差对于函数映射模型有效性的影响是有限的。正常记录、异常记录和全部记录的相对误差累积分布如图2a所示。图中可见,大约81.2%的记录相对误差在5%以内;而由于异常记录占比较低,过滤异常记录后,这一指标微升到82.8%。对于异常记录而言,这一百分比则有51.1%。然而仅仅考察相对误差是不够全面的,误差的绝对差值,抑或就本文述及的模型而言,误差的绝对人口数,也是评价模型有效性的重要指标。定义绝对误差AE(absolute error):

迁入流量的绝对误差与式(19)类似,不再赘述。绝对误差的含义显然是经由线性映射模型换算后城市 α和 β统计视角下迁徙人口的差值。图2b是正常节点绝对误差统计直方图。图中可见,对于正常记录而言,当不考虑舍入误差时,有约87.44%的记录绝对误差不多于3人;约93.44%的记录绝对误差不多于5人。绝对误差的极值出现在1月20日:当日汕头视角下自深圳迁入人口及对应的反向记录的误差达到了79人的极值,但对应的相对误差仅为0.48%。因此有理由认为,相较于测量误差,舍入误差具备压倒性的影响。当考虑舍入误差时,迁徙人数的取值将松弛为某个特定区间,因此记录的绝对误差显著减小。图2c统计了异常记录绝对误差人数。图中可以看到,即使是异常记录,其最大绝对误差人数相对于舍入误差区间也仅偏出36人。在异常记录中,有82.98%的记录误差人数在3人以内,有98.65% 的记录绝对误差人数在10人以内。可见,少量的违例现象对线性映射模型不产生本质影响,将其假定为数据测量误差是自洽的。
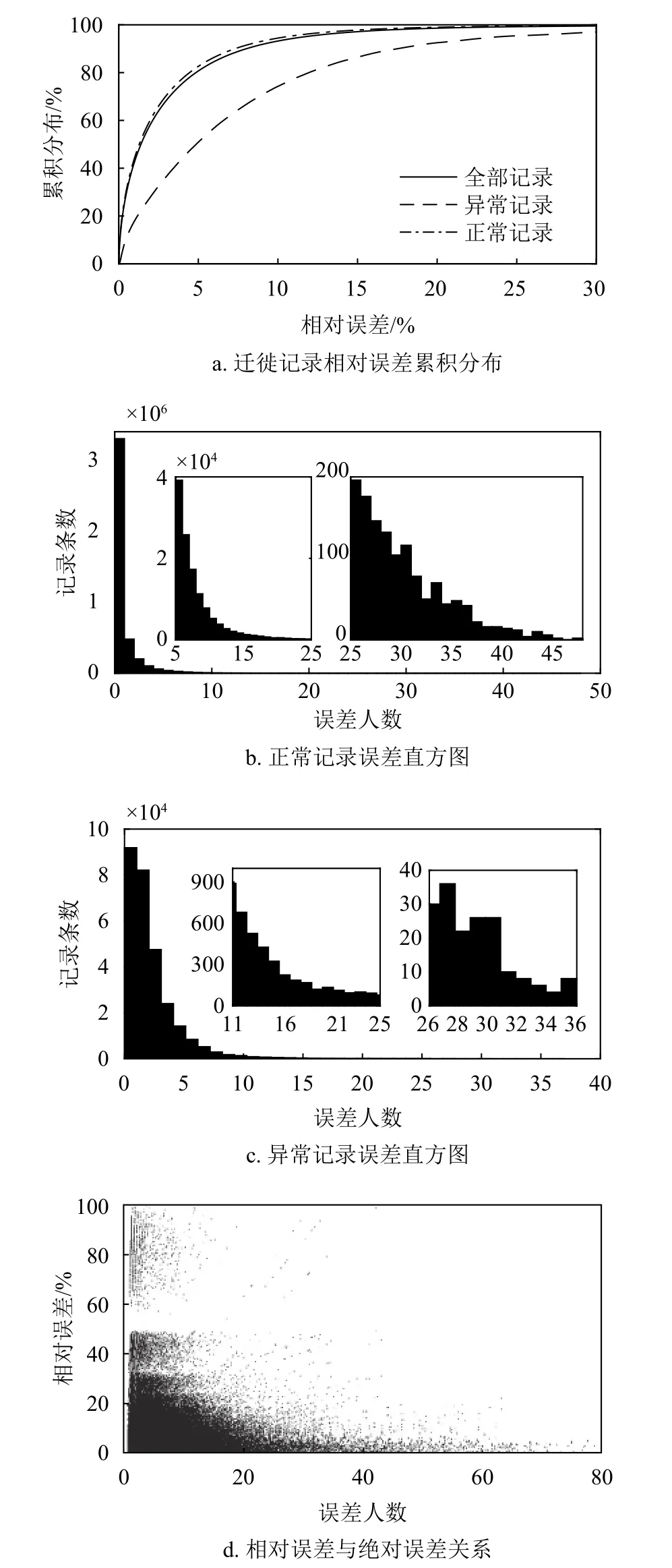
图2 市际迁徙流量校验
注意到一个现象,即较多的绝对误差人数未必对应于较高的相对误差。因此,通过图2d分析异常记录的相对误差和绝对误差的对应关系。该图可分为4个逻辑象限:高相对误差高绝对误差;高相对误差低绝对误差;低相对误差高绝对误差和高相对误差高绝对误差。在图中,高相对误差高绝对误差区域几乎为空白。此外,除在低相对误差低绝对误差象限集中了大部分记录外,另外两个象限也存在一定比例的记录分布。分析可知,当两地人口迁徙流量悬殊时,以低流量区划视角统计的记录易出现高相对误差低绝对误差的情况:而两地人口流量均较大时,则易出现低相对误差高绝对误差的违例数据。
市-省间迁徙流量数据同样可以印证线性映射模型的有效性。利用与市际迁徙流量相同的统计方法进行分析。如图3a,有82.65%的数据记录误差位于舍入误差区间内。该数据虽较城市间流量数据偏低,但全部记录的相对误差同时亦有显著降低:有约92.06%的记录相对误差不高于5%;这一指标在正常记录中达到了97.13%,在异常记录中同样达到了77.3%,说明在市省流量层面的测量误差影响同样是有限的。图3b是正常记录的绝对误差统计。其中有73.86%的绝对误差人数在3人以内,有95.77%的绝对误差人数在10人以内。在正常记录中误差人数极值为97人,出现于1月20日北京市视角下自广东省迁入人数,此时相对误差为1.32%,仍处于舍入误差松弛区间。如图3c,当将考察视角迁移到异常记录时,发现擦除舍入误差后最大误差人数为250人,出现于1月17日濮阳市视角下自山东省迁入数据,此时对应的相对误差也仅为2.64%。注意到即使仅考虑异常记录,也有约98.6%的绝对误差人数仍不多于50人——对于少则数百万,多则近亿人口的省级行政区划而言,可以认为这个量级的测量误差影响仍是有限的。相对误差与绝对误差的对应关系如图3d所示。可见在市-省层面表现出了与市际迁徙相似的分布特征,但其低相对误差低绝对误差象限的记录更加贴近相对误差坐标轴。一个合理的解释是,省级区划的迁徙记录来自下辖市级区划对应记录的简单加和,因此下属区划间测量误差的累积会抬高绝对误差;但由于测量误差存在部分相互抵消的现象,而市级区划的流量基数不变,因此随着迁徙流量的累加,相对误差反而会有所下降。

图3 市-省迁徙流量校验
将同样的分析方法应用于省际迁徙数据进行验证。在图4a中,有84.87%的记录误差可被舍入误差区间覆盖。同时,由于记录两端的节点均为省级区划,人口迁徙基数较大,降低了迁徙记录的相对误差:有50.73%的记录相对误差小于0.5%;89.43%的记录相对误差小于5%。图4b与4c分别统计了正常记录与擦除舍入误差后异常记录的绝对误差。可以看出,即使在省级区划这个层面,绝对误差仍可控制在相对很低的水平。对4个月的迁徙记录统计显示,正常记录中的极值出现于1月12日江西视角下自广东迁入记录,与其对应的反向记录差值为107人,对应的相对误差仅为0.05%。异常记录中的极值出现在1月23日北京视角下迁往山东的记录及对应的反向记录,此时绝对误差达到357人。相对于两地当日该方向上70 871~71 337人的迁徙人数而言,其相对误差仅为约0.5%。如图4d所示,相对误差与绝对误差的关系也体现出与市际流量和市省流量相似的特征。但随着流量基数的增加,低相对误差高绝对误差象限汇聚了相对更多的记录。总的来看,省际迁徙流量的数据同样可以给予线性映射模型有力的支持。

图4 省际迁徙流量校验
6 结 束 语
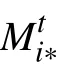
猜你喜欢
Defence Technology(2020年4期)2020-07-02 03:16:58
成都信息工程大学学报(2019年6期)2019-08-13 03:31:12
四川环境(2019年6期)2019-03-04 09:48:54
西南石油大学学报(社会科学版)(2018年5期)2018-11-08 10:55:44
能源(2018年7期)2018-09-21 07:56:14
青年与社会(2018年2期)2018-01-25 15:37:06
汽车零部件(2017年2期)2017-04-07 07:38:47
IT时代周刊(2015年8期)2015-11-11 05:50:22
现代企业(2015年5期)2015-02-28 18:50:09
太空探索(2014年4期)2014-07-19 10:08:58
