
面向多用户的微观交通仿真实验系统设计
2021-08-04 03:46:12吴春江周世杰陈鹏飞
电子科技大学学报 2021年4期
吴春江,周世杰,陈鹏飞
(电子科技大学信息与软件工程学院 成都 610054)
随着大数据、人工智能、物联网等新兴技术的发展,智慧交通已成为智慧城市建设的关键环节,面向智慧交通的虚拟仿真实验也成为国家虚拟仿真实验教学项目的重要组成部分。在城市管理、交通工程、交通运输等专业的教学实验中,往往需要开展单路口、单道路、区域路网甚至城市路网的复杂交通实验。然而,通过在实际交通环境中调整交通信号灯、改变路网结构、增减车道数量等路网参数来开展以上实验,成本高、影响大,绝大多数情况下不可行。为此,往往需要借助道路交通虚拟仿真系统,运用计算机仿真技术,模拟道路交通复杂状况,揭示交通流时空变化规律,有利于用户掌握道路交通设计、预测、控制、诱导等知识与技术。
目前的交通仿真软件如Aimsun next[1]、Trans Modeler[2]、 Paramics[3]、 Vissim[4]、 CORSIM[5]、Matsim[6]、MITSim[7]等都只是对具体场景进行仿真,不能满足虚拟仿真教学实验需求,即使是开源的SUMO[8]也不支持实时在线仿真以及在指定路网中进行不同类别的仿真实验。
1 研究进展
交通仿真作为计算机仿真的一个分支,起源于20世纪50年代[9],该技术能够在计算机上实现对真实路网及车流状况的模拟,用以对交通态势随时间和空间的变化进行跟踪描述。
本文对10个具有代表性的交通仿真系统从仿真类型、代码开源、仿真功能、仿真地图、车辆行为模型、在线仿真、仿真控制等几个方面进行比较,结果如表1所示。目前的交通仿真软件[10-20]都只是对具体场景进行仿真且功能较少,并不能满足虚拟仿真教学实验的要求,不支持实时在线仿真以及在指定路网中进行不同类别的仿真实验,并且这些仿真系统操作起来都非常复杂。

表1 交通仿真系统对比
针对以上这些问题,本文首次研究并设计了一种面向多用户的微观交通仿真实验系统(http://its.uestc.cn),具体贡献如下:
1)设计并实现了一种微观交通仿真引擎,该仿真引擎具有消耗低、易扩展等特点,支持独立运行和分布式通信;
2) 设计并实现了一种面向多用户的微观交通仿真实验系统,该系统采用分布式计算、分布式消息通信等技术,支持多个仿真引擎、多个仿真任务并发执行;
3) 本文对面向多用户的微观交通仿真实验系统进行了性能测试,测试结果表明微观交通仿真引擎的性能与仿真车辆数和仿真加速比成正比,并且在单台服务器上,该仿真实验系统能够支持多个仿真引擎、多个仿真任务的并发执行。
2 系统设计
2.1 系统架构设计
本文所设计的一种面向多用户的微观交通仿真实验系统的架构如图1所示。

图1 面向多用户的微观交通仿真实验系统架构图
在面向多用户的微观交通仿真实验系统中,每个交通仿真引擎执行独立的仿真任务,各个仿真引擎之间相互独立、互不干扰。单台仿真引擎服务器可以创建出多个仿真引擎,支持多个仿真任务的并发执行。再通过分布式计算技术和分布式消息通信机制,将多台仿真引擎服务器进行统一管理,实现对每台服务器上的每个仿真引擎的统一管理。通过仿真引擎服务器数量的增加,可以实现更多仿真引擎的管理与并行计算,达到面向多用户的交通仿真任务并发执行的目的。
2.2 仿真引擎调度
本文所设计的面向多用户的微观交通仿真实验系统,以仿真任务为功能单元,每个仿真引擎执行独立的仿真任务,各个仿真引擎之间相互独立、互不干扰,再通过微观交通仿真实验系统统一的任务调度和仿真引擎管理,创建多个仿真引擎执行不同的仿真任务,从而实现面向多用户的并发仿真任务。
如图2所示,在面向多用户的微观交通仿真实验系统中,每个仿真引擎都是一个独立的进程或安装在Docker容器中,仿真引擎管理模块负责仿真引擎进程或Docker容器的创建及回收。
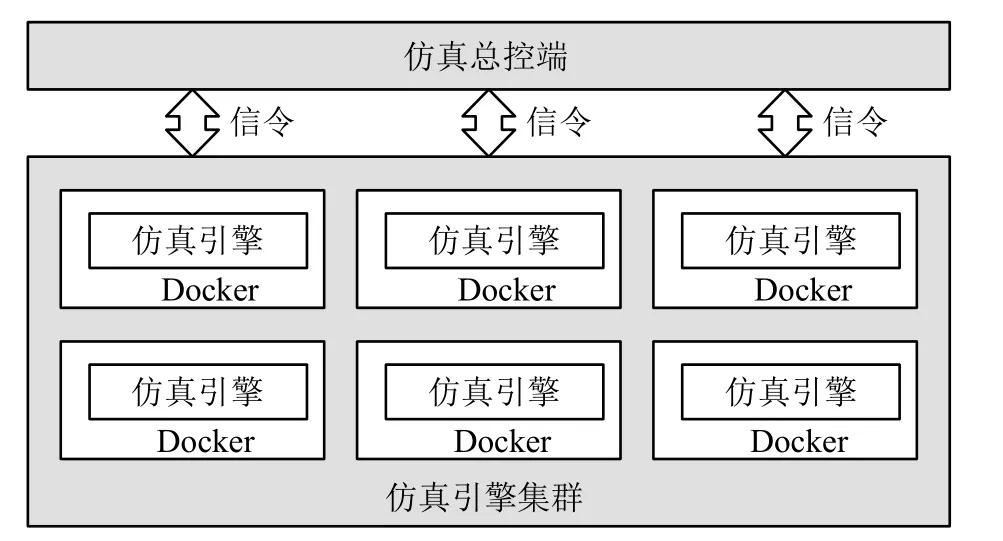
图2 仿真引擎集群示意图
当有新的仿真任务创建时,仿真引擎管理模块会根据仿真任务的规模来预估仿真任务所需要的计算资源。如果系统中空闲的计算资源满足仿真任务的需要,仿真引擎管理模块则会分配一个仿真引擎去执行仿真任务。如果系统中没有足够的计算资源,仿真引擎管理模块首先会将仿真任务放到等待队列中,等待其他仿真任务执行结束释放出足够的计算资源,再分配一个仿真引擎去执行该仿真任务。等待队列中的仿真任务按照先来先得的顺序分配仿真引擎和计算资源。并且,根据前面所设计的系统架构,本文设计的实验系统可以通过增加仿真引擎服务器的数量来扩展计算资源,用以满足多个不同规模仿真任务的运行需求。
2.3 仿真任务通信
本文所设计的面向多用户的微观交通仿真实验系统采用kafka作为任务管理端和仿真引擎之间的通信方式,以满足高吞吐量的分布式消息通信。
当仿真引擎和计算资源分配成功后,任务管理模块会将创建仿真任务需要的参数数据放入kafka消息队列当中,仿真引擎会从kafka消息队列中获取参数数据,进行任务创建。同时,仿真引擎在执行完一定步数的仿真计算后,也会将仿真结果放入kafka队列中,以供仿真总控端提取仿真数据,如图3所示。
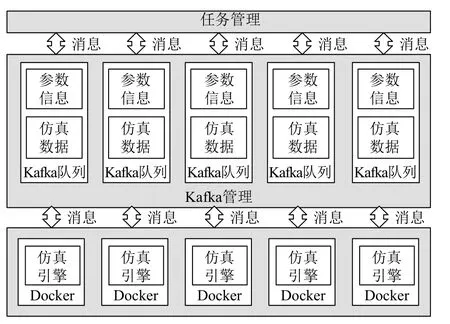
图3 分布式交通仿真引擎消息通信
在面向多用户的微观交通仿真实验系统中,仿真数据分为车辆仿真数据和信号灯仿真数据。为了区分这两种实验数据,仿真引擎在发送到kafka队列的时候,会对数据加以处理,对于车辆仿真数据,数据是以“vehicle_”加上16位的仿真ID号组成;对于信号灯数据,数据是以“phase_”加上16位的仿真ID号组成。当kafka队列收到这些数据之后,可以通过数据的标志进行车辆仿真数据和信号灯仿真数据的判断。
3 性能测试
根据本文所提出的微观交通仿真实验系统设计思路,需要达到面向多用户并发执行仿真任务的目的,为此,本文首先对该微观交通仿真实验系统进行性能分析。
根据所描述的仿真引擎设计,在本文微观交通仿真引擎设计中,所有仿真车辆的每一步仿真计算方式都是相同的。由此可以分析出,本文所设计的微观交通仿真引擎的计算消耗与仿真车辆数强相关,仿真车辆数越大,每一步仿真计算的消耗就越大,其时间复杂度为step×O(n),其中,step为仿真加速比(即仿真步数),n为仿真车辆数。同时,在本文所设计的微观交通仿真引擎中,每个仿真车辆占用的内存为100 B左右,100万仿真车辆占用的内存仅100 M。
根据以上分析,本文所设计的微观交通仿真引擎对CPU的计算消耗需求大,对内存的消耗可忽略不计。同时,本文所设计的微观交通仿真引擎的计算时间复杂度为step×O(n),即与仿真加速比和仿真车辆数相关。因此,本文设计了单仿真引擎仿真车辆数变化、单仿真引擎仿真加速比变化和多仿真引擎并发执行3种实验来测试性能。
本文所设计的微观交通仿真引擎性能测试的实验环境如表2所示。

表2 微观交通仿真引擎性能测试实验环境
3.1 单仿真引擎仿真车辆数变化性能测试
单仿真引擎仿真车辆数变化主要测试仿真车辆数对计算资源的消耗。本文选取双向8车道的9个十字路口地图作为仿真地图,该仿真地图的最大容量为2 400辆仿真车辆。在单仿真引擎仿真车辆数测试实验中,车辆生成速率设置为50,仿真加速比固定设置为20,通过仿真车辆数的变化观察单仿真引擎的CPU资源消耗变化。测试结果如表3、图4、图5、图6所示。

图4 仿真车辆数变化
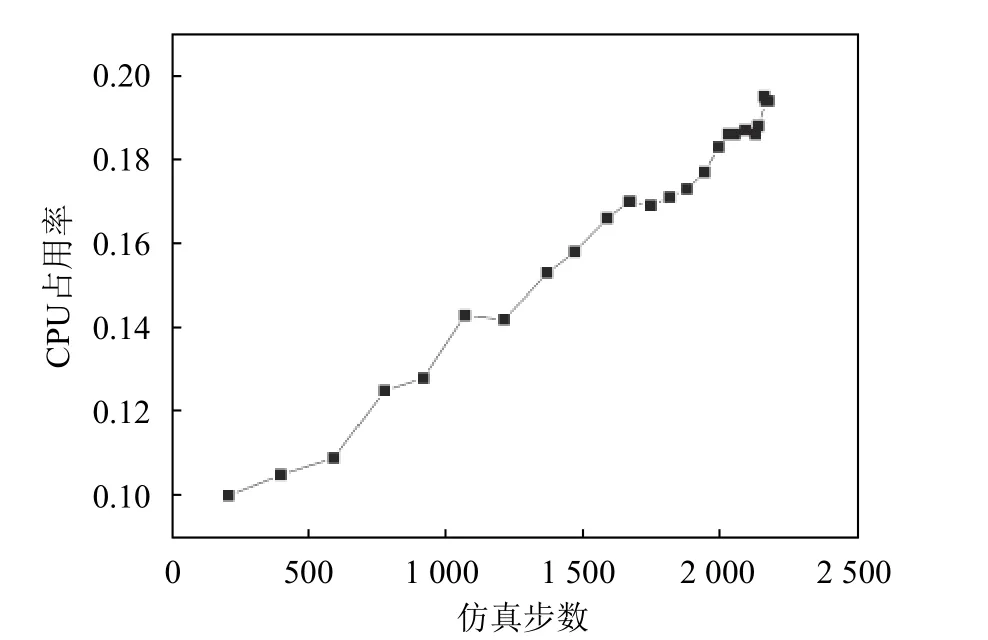
图5 随仿真车辆数的CPU占用率

图6 随仿真车辆数变化的计算耗时

表3 单仿真引擎仿真车辆数性能测试
可以看出,随着仿真车辆数的增加,单仿真引擎所占用的CPU与仿真计算耗时也随之增加,增长趋势基本相符,与仿真引擎的性能分析结果一致。
3.2 单仿真引擎仿真加速比变化性能测试
单仿真引擎仿真加速比主要测试仿真加速比对仿真计算资源的消耗。本文选取双向8车道的十字路口地图作为仿真地图,该仿真地图的最大容量为380辆仿真车辆。实验中,仿真车辆生成速率设置为50,当仿真车辆数达到仿真地图最大容量时,通过调整仿真加速比来观察CPU资源消耗的情况。测试结果如表4、图7、图8所示。

表4 单仿真引擎仿真加速比变化性能测试
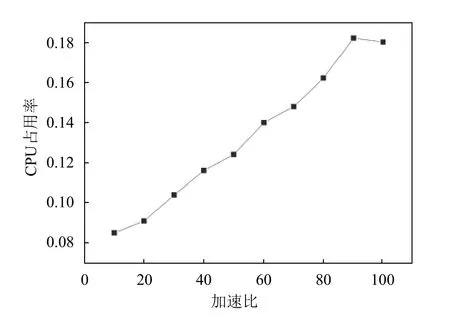
图7 随仿真加速比变化的CPU占用率
从表4、图7、图8所展示的结果可以看出,随着仿真加速比的增加,单仿真引擎所占用的CPU与仿真计算耗时也随之增加,与仿真引擎的性能分析结果一致。

图8 随仿真加速比变化的计算耗时
3.3 多仿真引擎并发执行性能测试
本文在如表2所示的单台服务器上,对面向多用户的微观交通仿真实验系统进行了多仿真引擎并发执行的性能测试。本文选取双向8车道的单十字路口地图作为仿真地图,该仿真地图的最大容量为380辆仿真车辆,通过对仿真引擎数的增加来观察仿真任务并发执行数对服务器CPU资源消耗的影响,测试结果如表5、图9所示。
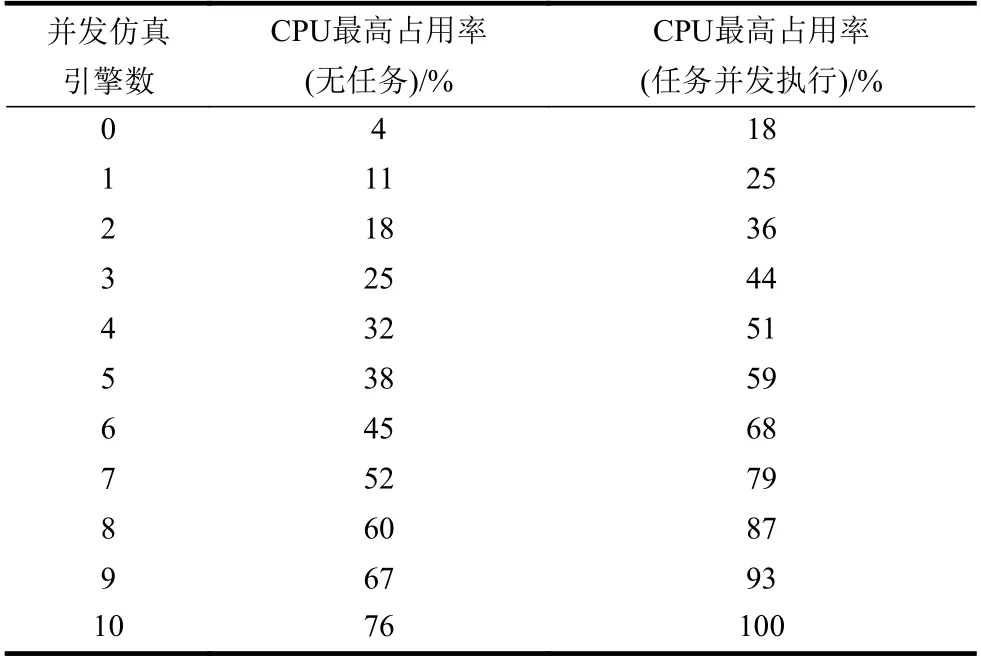
表5 多仿真引擎并发执行性能测试
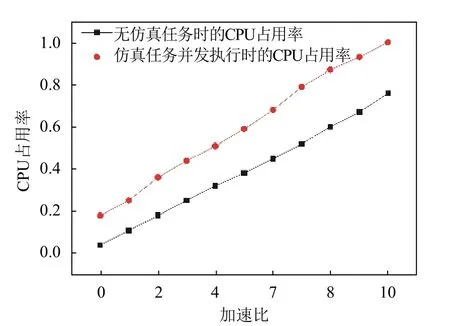
图9 多仿真引擎并发执行的CPU占用率
从表5、图9所展示的结果可以看出,在无仿真任务和仿真任务并发执行的情况下,CPU占用率与仿真引擎的数量成线性比例增长。在单台服务器上,本文所实现的一种面向多用户的微观交通仿真系统可以支持多个仿真引擎、多个仿真任务的并发执行。并且,还可以通过增加服务器的数量来支持更多的仿真任务并发执行。
同时,由于仿真引擎只有在请求仿真任务的时候才会增加对CPU的消耗,而且仿真任务的执行时长是根据仿真请求步数确定的,不会无限地执行下去,会有一定的空闲期。因此,在实际的应用过程中,出现多个仿真任务并发执行的情况相对较少,从理论上讲,单台服务器可以支持更多的仿真引擎和仿真任务执行。
4 结 束 语
本文从仿真类型、代码开源、仿真功能、在线仿真、仿真控制等几个方面对多种交通仿真系统进行了横向比较。其次,针对道路交通虚拟仿真实验的多用户、多并发、可操作等特性,提出了一种面向多用户的微观交通仿真实验系统,并从系统架构和仿真引擎方面对该仿真系统进行了设计。最后,对面向多用户的微观交通仿真实验系统的性能进行了分析,并从单仿真引擎仿真车辆数变化、单仿真引擎仿真加速比变化和多仿真引擎并发执行3个方面对该系统进行了测试。测试结果表明,本文所实现的一种面向多用户的微观交通仿真系统可以支持多个仿真引擎、多个仿真任务的并发执行,并且可以通过增加服务器的数量来支持更多的仿真任务并发执行,能够满足多用户的同时在线仿真需求。
猜你喜欢
中国金属通报(2022年14期)2023-01-06 01:51:18
中国金属通报(2021年12期)2021-11-02 03:56:30
中国金属通报(2021年6期)2021-07-01 05:46:28
中国金属通报(2020年14期)2020-04-22 06:22:26
制造技术与机床(2017年5期)2018-01-19 02:48:59
商周刊(2017年22期)2017-11-09 05:08:31
诗选刊(2015年6期)2015-10-26 09:47:10
河南电力(2015年5期)2015-06-08 06:01:46
皖西学院学报(2015年5期)2015-02-28 17:52:46
浙江人大(2014年8期)2014-03-20 16:21:15
