
基于计算机技术在医院信息化管理系统设计
2021-08-04 08:37张志彬
计算机测量与控制 2021年7期
张志彬
(中国人民解放军陆军第八十二集团军医院,河北 保定 071000)
0 引言
随着社会快速发展逐渐步入数字信息化的新时代,计算机信息化技术逐渐进入我们的生产生活之中,对于复杂多变的医院信息管理工作也同样需要引入计算机技术的辅助进行信息管理工作,通过引入计算机信息管理技术可以大大提高医院信息化管理工作的执行效率,同时提高医院信息化管理的水平。如文献[1]中采用引入计算机数据仓库技术进行决策分析,但是不能合理对医疗数据进行合理应用[1];在文献[2]中通过云存储技术对信息进行管理,但是没有建立一个完整的管理方案[2];在文献[3]介绍了对计算机信息管理系统的维护进行分析,但是仅对维护方面提出方案,无法使医疗信息管理更高效的应用[3]。
针对于上述文献对医院信息管理技术改进的不足,本文设计了一种医院信息管理系统,并针对与医院信息数据采用数据挖掘技术对医院管理信息进行处理。下文是针对于医院信息管理方案进行设计一种管理系统和对医院信息进行数据挖掘的详细论述[4]。
1 医院信息管理系统设计
1.1 管理系统需求分析
由于在医院信息管理系统中不但包含整个医院的与企业信息管理相类似的管理信息,同时还包含以患者信息为主进行的教学、科研以及整个治疗过程的相关数据。在实际的医院信息管理系统的设计中,对系统设计的需求主要是提高医疗水平、加强企业事务管理、提高整体的医疗服务质量以及增加医院经济效益[5-6]。其中对于信息管理系统所需要达成的目标如图1所示。

图1 信息管理需求目标
如图1所示,由于医院是一个特殊的环境,需要7天/24小时稳定提供服务的系统,以此需要绝对安全可靠性;由于医院是一个多部门协调合作完成的工作,需要能够提供稳定的联机事务处理的能力。
1.2 信息管理系统设计
为实现对医院信息进行管理,需要对医院进行业务的流程进行了解,如在医院中看病进行的过程中,有着一定的操作流程,通过这个流程在各个部门中进行不同的操作,来完成具体的诊断和治疗[7-8]。其医院的业务的流程图如图2所示。

图2 业务流程图
如图2所示,患者首先需要在挂号处进行排队挂号,通过所挂号码在需要诊断的门诊科室由门诊医生进行诊断,如果病情很轻,很容易诊断,可以直接缴费、领药后就可以出院了;但是如果病情比较复杂或严重就需要医技科室对患者进行验血等检验,通过简易结果对其再进行诊断,分析其是否需要住院治疗,通过这一套流程实现对患者疾病的检验[9]。
本文设计的信息管理系统不但包含常规企业的人事、财务等信息,更包含每一个患者之前的病历、本次患病情况、治疗方案、用药情况以及主治医师等信息,其中以医院中各个不同部门工作进行分类所产生的医院信息管理系统的数据流向图如图3所示。

图3 医院信息流向图
如图3所示,本文设计的医院信息管理系统是为了实现完成对病人病历信息的多层次的管理。门诊管理主要管理进行治疗相关的信息,其中包含的病历、治疗方案、检查报告等信息较多;住院管理主要是对床位安排、护士人员安排以及相关收费等信息;药品管理主要对医院中各种药品的使用情况、剩余情况以及采购情况等信息;财务管理是对医院的每笔药品和器材采购、每个患者的缴费情况以及每笔支出与收入信息记入系统;院长决策是对医院的决策信息进行记录;系统维护主要是对医生护士等人员对该系统权限开放问题、信息的备份、维护以及配合医生对病人数据进行查询等相关问题[10-11]。本文设计的医院信息管理系统软件设计采用C/S三层结构,其结构如4所示。
如图4所示,本文设计的事务管理系统结构采用三层C/S结构,其将管理系统的功能分成了表示层、功能层以及数据层三部分组成[12]。表示层主要安装在用户端,其主要特点是操作简单,方便用户的使用,用户通过该端口封装好的操作对底层数据和应用进行操作;功能层是应用的主体,在该处完成应用的逻辑,用户的操作权限等功能都需要在该处实现;数据层是主要为DBMS,主要负责完成对数据库的增删改查,其通过功能层调用设计好的SQL语句对数据库进行操作[13-14]。

图4 信息管理系统C/S三层结构
随着信息技术的发展,医院信息管理系统中包含着大量的有用数据,其中就包含患者的检查信息、治疗方案及治疗结果、药物的使用等信息。主治医生通过从病人以往的病历入手,以病情发展顺序进行查询,通过对病情发展研究,对这个病人设计更具有针对性的治疗方案;也可以通过对某种病症为依据进行查询,通过对医院历史上病人的病征、治疗方案以及治疗结果等数据进行研究[15-16]。
2 医院数据挖掘分析
本文采用关联法则算法和分类算法对医院系统中的数据进行分析,其中针对于(1)建立疾病、处方和药品的联系,以此来对药房药品进行合理的排放;(2)通过全年各种药品的使用情况,合理的选择各种药品的采购数据;(3)使检查结果与治疗方案建立联系,提高医生诊治病人的效率和质量;(4)对单一病种的处方用药信息进行分析,提高对单一病种的治疗合理性等方向进行研究,可大大提高医院管理和治疗的效率。
2.1 改进Apriori算法
为研究医院信息之间的关系,本文通过关联法则算法对医院信息管理信息进行分析,从中发现医院信息间的关联性,建立医院信息管理数据关系网,在医院信息管理的信息数据量非常大,各种属性丰富,在经过关联法则算法进行计算后可以给出准确度高的预测和建议。其中在进行关联法则进行数据挖掘时常采用Apriori算法来进行分析,其拥有运行简单、使用方便等优点,但是Apriori算法同时也存在着一些问题:第一点是Apriori算法在进行运算时需要频繁的对数据库进行扫描;第二点是Apriori算法运算过程中会出现大量的候选项集,同时会出现多次检查同一项集的现象。针对于上述两项不足,本文提出增加标识和剪枝两种改进方案[17]。
针对于该算法需要进行频繁扫描数据库的问题,本文采用对计算中产生的项集增加标识的方法减小对数据库中数据进行扫描的次数。当算法需要进行计算支持度的时候对项集增加0、1标识,其中不包含此项集的标识为0,包含此项集的标识为1,这样在对信息进行扫描时就可以先判断其标志是否为1来判断是否需要扫描,再对需要扫描的数据进行扫描[18]。针对于算法运算时出现大量候选项集的问题本文通过剪枝的方式进行解决。在算法进行计算中,其中频繁项集的子集同样也是频繁的(其中不包含空集),在算法计算过程中,通过删除掉频繁项集中的频繁项集的子集就可以大大减小该项集所包含元素数量,提高反映速度。其算法运行所需的伪代码如下所示。
算法:改进Apriori
输入:数据库D,最小值初度阈值min_sup。
输出:Result=中的频繁项集
Result:={ };
for(x=1;x≤|DB|;x++)
begin
设项集为{a1,…,an}
for(y=1,y≤n,y++)
begin//进行判定
ifay首次出现,计数器cnt=0;
ay归为Result;
continue;
else
cnt++;
end:
ifcnt=min_sup then
Result:=Result∪{ay};
end;
end;
如图5所示,采用循环操作来实现算法的运行,直到没下新的项集产生。首先算法读取数据库的第一项的数据,生成项集并把所用可能产生的所用组合形式标志为1;然后进行读取下一项的数据,进行标识其可能的组合,组合里面为k-项集。若无k-项集标示为1,略过标识过的k-项集,若k-项集出现却小于最小支持度阈值就在支持度技术加1。循环上述步骤就是算法的运行过程。

图5 初步决策树算法示意图
2.2 增量决策树算法
分类算法就是通过建立合适的对医院信息数据进行分类的标准来实现的,通过判断不同标准使不同信息分入不同的类别之中[19]。在分类算法中常使用决策树算法来对数据进行分析,但是常规的决策树算法针对新增加的数据处理能力很差,为解决该问题,本文通过引入概率统计学中的贝叶斯分类方法来实现增量决策树算法。
在增量决策树算法中首先将医院数据样本分离成n个小数据样本,这些小数据样本在决策树生成结点,决策树通过把产生的节点分成普通叶结点和贝叶斯结点两点两种来进行划分。其中进行产生决策的初步决策树算法示意图如图5所示。
如图5所示,通过将此种决策树算法与贝叶斯分类相结合可以得到新产生的增量决策树算法。在增量决策树算法进行增量学习的两个阶段是产生初步决策树和在初步决策树上进行学习[20]。其中进行的增量决策树算法的伪代码如下所示。
算法:增量决策树算法
输入:决策树T1,新增样本b。
输出:决策树T
决策树T1与新增样本b进行匹配得到叶结点M;
{if 叶结点M为贝叶斯结点,
则新增样本b修正贝叶斯结点参数,
返回决策树更新为T2。
{if 叶结点为普通叶结点:
新增样本b与该节点分类相同返回决策树T1,
新增样本b与该节点分类不同,
比较该节点贝叶斯分类准确率F1和决策树分类准确率F2。
{ifF1>F2,本节点更改为贝叶斯结点,
返回T,反之返回T1}}}
增量决策树算法的流程示意图如6所示。
如图6所示,第二个阶段中出现新的训练样本,此算法会将数据书中的属性与新的数据样本匹配,在叶结点处结束匹配。如果到达普通叶结点,判断是否分类错误。如果进行分类时发生分类错误就进行对比贝叶斯分类和决策树分类的准确率,若贝叶斯分类准确率高则把该节点转换为贝叶斯结点,分类正确则不变。如果到达贝叶斯结点,通过样本修正贝叶斯参数。通过递归的方式不断建立决策树,可以修改贝叶斯参数或者增加贝叶斯结点,从而实现在数据样本中的增量学习。

图6 增量决策树算法
3 试验过程和分析
为了验证本文设计的进行医院信息管理系统对于数据挖掘技术研究的优越性,针对于两个方面分别设计了模拟仿真实验[21]。在本次实验中采用进行模拟试验分析环境的参数设置为:选用Windows 10作为操作系统平台,设置计算机内存为8 G,Intel Xeon W-2145 CPU 3.70 GHz,其中模拟仿真的数据库数据采用仿真医院档案数据,试验软件为数据挖掘工具怀卡托智能分析环境(weka)。
3.1 相关法则算法验证试验
为了说明改进Apriori算法在相关规则算法中的高效性,特设计本对比试验,对比对象为Apriori算法,通过使用两个算法来处理相同的医院信息数据得出试验数据,分析数据得出实验结论。首先在数据挖掘工具怀卡托智能分析环境(weka)中置入Apriori算法和改进Apriori算法,其次从数据库中提取医院信息数据并从并分为五组,数据量分别为1 000,5 000,10 000,50 000,100 000。最后通过weka分别使用两种算法对五组数据进行数据挖掘,得出实验数据,其算法耗费时间统计图如图7所示。

图7 算法耗费时间统计图
由图7可知,在医院信息处理上改进Apriori算法处理时间比Apriori算法处理时间减少了90%。为表明改进Apriori算法的剪枝作用统计实验中剪枝前后对比如表1所示。

表1 剪枝前后数据统计表
由表1可知改进Apriori算法剪枝的效果非常明显,可以有效地减少对数据库的扫描,以免造成不必要的算法操作。通过相关规则算法试验过程可以得出结论,使用改进Apriori算法在医院信息管理中进行数据挖掘能够极大的提升医院信息的处理效率。
3.2 增量决策树算法验证试验
为了验证本文改进的增量决策树算法在进行分类算法中的高效性,特设计进行对比实验,本次对比实验中的对比对象为常见的分类算法ID3算法和C4.5算法,通过使用3个算法在相同条件下处理相同的医院信息数据得出实验数据,分析实验数据得出实验结论[22]。首先在数据挖掘工具怀卡托智能分析环境(weka)中置入新型增量决策树算法、ID3算法和C4.5算法3种算法,其次从数据库中提取医院信息数据并从并分为5组,医院信息数据表如表2所示。

表2 医院信息数据表
首先用3种算法分别进行不含增量学习的处理的结果如表3和表4所示,进行增量学习的处理的结果如表5和表6所示。其中新型增量决策树算法简写为ZD。

表3 非增量分类算法准确率统计表

表4 非增量分类算法耗时统计表
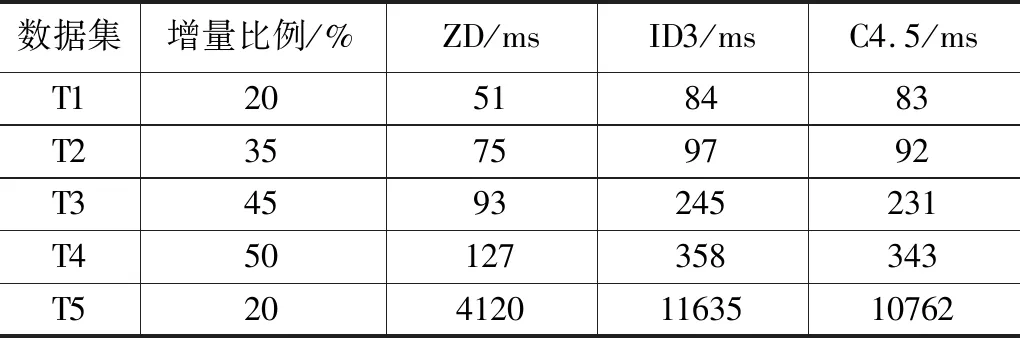
表5 增量分类算法耗时统计表

表6 增量分类算法准确率统计表
由表3和表4可知,在处理不含增量学习的数据集时,新型增量决策树算法、ID3算法和C4.5算法3种算法在耗时上相差不大,但是在分类的准确率上新型增量决策树算法明显优于另外两个算法,新型增量决策树算法的分类准确率比C4.5算法约高3%,比ID3算法约高6%。
由表5和表6可知,在处理含增量学习的数据集时,新型增量决策树算法的耗时比ID3算法和C4.5算法少60%以上,准确率比C4.5算法约高6%,比ID3算法约高8%。
通过分类算法实验过程可以得出结论,使用新型决策树算法在医院信息管理中心进行数据挖掘可以大幅度提升医院信息数据的分类效率,新型增量决策树算法分类的准确率比C4.5算法和ID3算法高5%以上,并且在进行增量学习中耗时是C4.5算法和ID3算法的40%以下。使用新型决策树算法作为数据挖掘中的分类算法可以使医院信息管理的准确率大幅提升。
4 结束语
为了解决医院信息管理中人力耗费大、数据关系网不全面、数据调取缓慢等问题,本文通过改进一种医院信息管理系统,并将数据挖掘技术应用到医院信息管理中,利用数据挖掘技术模块对医院信息进行分类、处理、管理等应用。使医院信息管理更加高效,建立医院信息数据关系网,减少了人力的投入[23]。虽然本研究有一定的技术创新性,但是仍旧存在很多不足,比如改进Apriori算法的稳定性,系统对该算法的兼容性等,都是要研究的课题,这需要进一步的探索和研究。
猜你喜欢
信息化建设(2022年6期)2022-08-04
河南科技(2022年12期)2022-07-14
北京航空航天大学学报(2022年5期)2022-06-06
财会月刊·下半月(2022年4期)2022-04-25
当代陕西(2022年6期)2022-04-19
科学与信息化(2019年28期)2019-10-21
数码世界(2019年7期)2019-09-16
妇女生活(2019年1期)2019-01-17
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
