
一种软件代码缺陷管理方案研究
2021-08-02 07:40曾成修
软件导刊 2021年7期
王 磊,曾成修,符 为,谢 磊
(西南电子设备研究所,四川 成都 610036)
0 引言
随着信息技术的发展,软件在业务能力生成中发挥着越来越重要的作用。为确保软件产品质量可控,软件开发组织按照工程化的方法进行软件产品研制。如何对测试验证中发现的软件缺陷进行有效管理进而推进现有产品的顺利研制及后续的持续改进,一直是软件工程关注的热点。
对软件缺陷进行管理是很多软件开发组织的重要工作。随着GJB5000A[1]等软件过程成熟度模型推广,软件缺陷文档化,软件缺陷处理分析相关工作愈加重要,但CMMI并没有指出如何具体开展这些工作,导致软件开发组织一般根据自己的理解作出不同的软件缺陷管理方案,例如模棱两可的数据解释、加入报告者主观意见等[2]。因此,有必要采用结构化方法进行缺陷文档化。缺陷数据的结构化收集和分析方法有缺陷分类法[3]、根本原因分析法(RCA)[4]以及IEEE Std 1044[5]、GJB/Z 141[6]、正交缺陷分类(ODC)[7]、Hewlett-Packard缺陷分类[8]、APP缺陷问题评论分类方法[9]等。虽然这些针对特定环境上下文设计的方法在特定需求方面有效,但是其适应性也被认为是应用缺陷分类方法的主要挑战之一[10-12]。同时,对文档化后的缺陷数据进行存储和处理分析常需要借助工具进行。目前,常见的软件缺陷工具包括Trac、Redmine、Bugzilla、JIRA、YouTRACK、Pivotal Tracker 等开源或商业工具[13],以及定制开发的系统[14-15]。这些工具作为一个独立的系统运行,导致缺陷属性值与缺陷分类内容值的准确性和一致性难以保证[16],数据录入和维护成本较高引发数据分析便利性和有效性不足,缺陷处理流程的一致性不足产生技术和管理“两张皮”现象。
目前典型的软件代码缺陷管理方案为基于GJB/Z 141附录C.3 的软件缺陷分类标准,使用类似文献[14]的定制缺陷管理工具进行缺陷管理。此种软件代码缺陷管理方案存在缺陷分类方法适应性不足和管理工具准确性、一致性、便利性不足等问题。
针对上述典型软件代码缺陷管理方案存在的问题,本文从软件代码缺陷分类方法和管理工具两方面进行研究,提出一种全新的软件代码缺陷管理方案并构建原型系统,从5 个方面对其应用效果进行评价。评价结果显示,本文方法可以明显改善现有软件代码缺陷管理方案中存在的问题,对缺陷进行有效管理并提高效率。
1 软件代码缺陷管理方案
本文提出的软件代码缺陷管理方案是在缺陷分类方法基础上通过缺陷管理系统工具实现对软件代码缺陷的管理。
1.1 软件代码缺陷分类方法
软件代码缺陷来源于软件源代码,分类方法关注源代码特性,考虑完整性、正交性以及分类一致性等质量特性,做到方便易用且真实可靠。软件代码缺陷分类方法如下:
(1)分类过程。软件缺陷的分类涉及从缺陷识别到缺陷关闭的活动序列,包括识别、调查、行动和处置。每个活动包含记录、分类和确定影响3 个步骤。
(2)分类属性。分类属性及其含义如表1 所示。
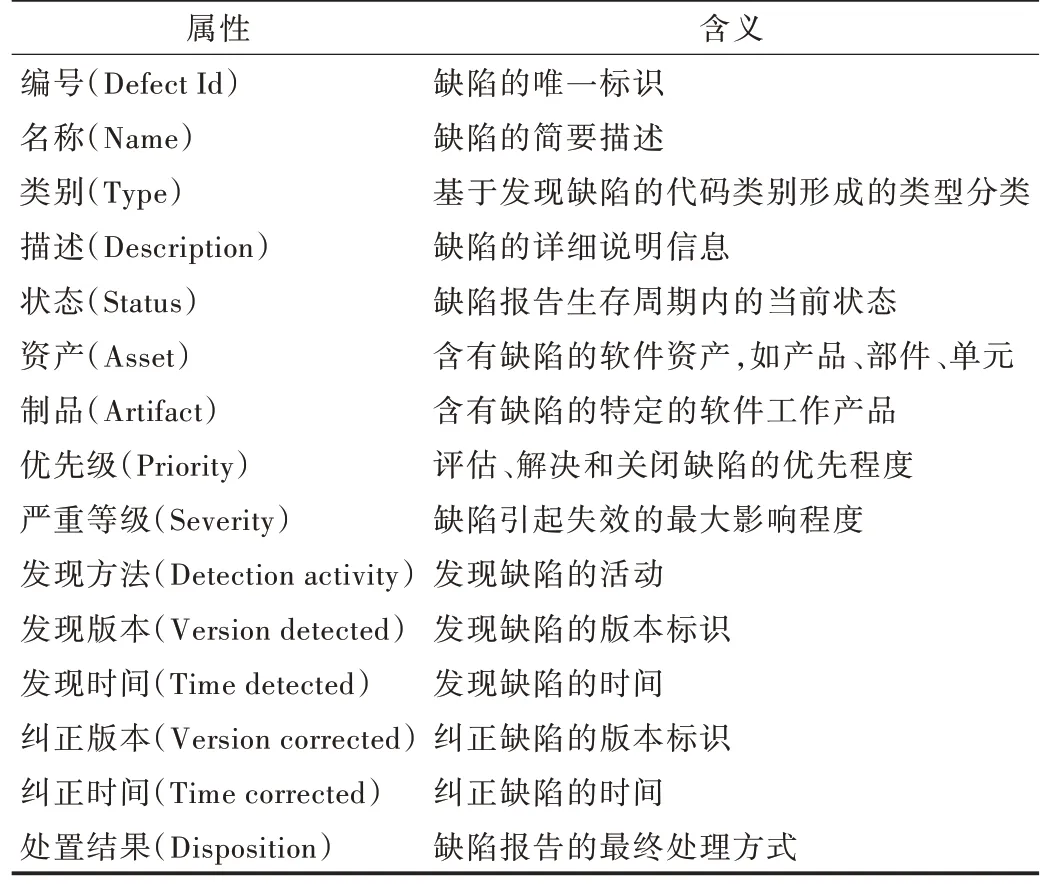
Table 1 Classification attributes and their meaning表1 分类属性及其含义
(3)细化分类属性值。可进一步细化的分类属性值为:①类别(Type):数据(Data)、接口/时序(Interface/ Tim⁃ing)、逻辑/运算(Logic/Algorithm)、描述(Description)、语法(Syntax)、标准(Standards)、其它(Other);②状态(Status):未确认(Unknown)、未闭环(Open)、已闭环(Closed);③优先级(Priority):高(High)、中(Medium)、低(Low);④严重等级(Severity):严重(Critical)、一般(Major)、轻微(Minor)、可忽略(Inconsequential);⑤发现方法(Detection activity):综合(synthesis)、审查(Inspection)、走查(Walkthrough)、评审(Review)、审计(Audit)、静态分析(Static analysis)、单元测试(Unit testing)、组装测试(Integration testing)、配置项测试(CSCI testing)、系统测试(System testing)、其它(Other);⑥处置结果(Disposition):已移除(Corrected)、未发现(Not found)、相关的(Referred)、重复的(Duplicate)。
1.2 软件代码缺陷管理系统
软件代码缺陷管理系统在设计时兼顾有效性和效率原则。基于有效性考虑,软件代码缺陷管理系统应满足:①缺陷属性管理:基于缺陷分类标准的统一规则定义缺陷属性并设置属性值;②缺陷数据跟踪和分析:实现缺陷及其属性变化的信息记录、条件查询显示和缺陷态势分析。基于效率考虑,软件代码缺陷管理系统应满足:①缺陷数据生成:缺陷数据通过缺陷分类标准与测试结果原始数据的转换规则便捷地从测试结果原始数据中直接获取,与原始数据记录内容一致,链接到原始数据及其上下文信息,能随原始数据变化实时更新;②缺陷分类过程管理:缺陷分类过程根据缺陷数据的属性值变化实时自动流转并通知到相应人员。
1.2.1 缺陷数据生成
通过数据访问引擎访问测试结果原始记录数据,通过缺陷分类标准与测试结果原始数据的转换规则直接生成缺陷数据。缺陷数据生成规则为:①从原始记录数据中逐条取出缺陷原始数据,通过缺陷身份识别(例如关键字值)判断缺陷数据库中是否存在包含此条缺陷数据的条目。如果存在则使用缺陷原始数据更新该条缺陷条目相关值,如果不存在则在缺陷数据库中增加缺陷条目并根据缺陷原始数据设置其相关值;②对于已在原始记录数据中消失的缺陷,在缺陷数据库中设置该条缺陷条目相关值为与“消失”匹配的值。
当测试结果原始记录数据变化时,缺陷数据库同步规则为:①当原始记录数据生成或再次生成时自动触发缺陷数据生成;②当对测试结果进行确认引起原始记录数据中“原始缺陷状态”标记变更时自动触发对应的缺陷条目数据更新。数据同步实现机制为:①采用第三方调度引擎(例如Jenkins)根据前置输出自动实时调度后续操作;②采用按钮触发或定时轮询方式实现操作。
1.2.2 缺陷属性管理
缺陷属性值可以通过缺陷分类标准与测试结果原始数据的转换规则获得。转换规则综合考虑缺陷分类标准的规则定义和原始记录数据使用自身规则定义,在语义转换后确保缺陷相关属性值的完整性、正交性和一致性。对于不同数据源的测试结果,转换规则需考虑共性数据的融合和差异性数据的屏蔽、筛选及补充。以“状态”属性为例,其定义为:①未确认:测试结果未经人工确认;②已确认未闭环:测试结果已经人工确认,确定为缺陷需修复但还未修复;③已闭环:测试结果经人工确认不是缺陷或经人工确认是缺陷但已修复。“状态”属性值对应的转换规则如表2 所示。

Table 2 Transformation rules corresponding to state property values表2 “状态”属性值对应的转换规则
1.2.3 缺陷分类过程管理
根据缺陷状态属性值确定缺陷处理流程所处阶段,并随缺陷状态属性值的变化进行缺陷处理流程的流转来实现缺陷分类。缺陷分类实现方式如图1 所示。
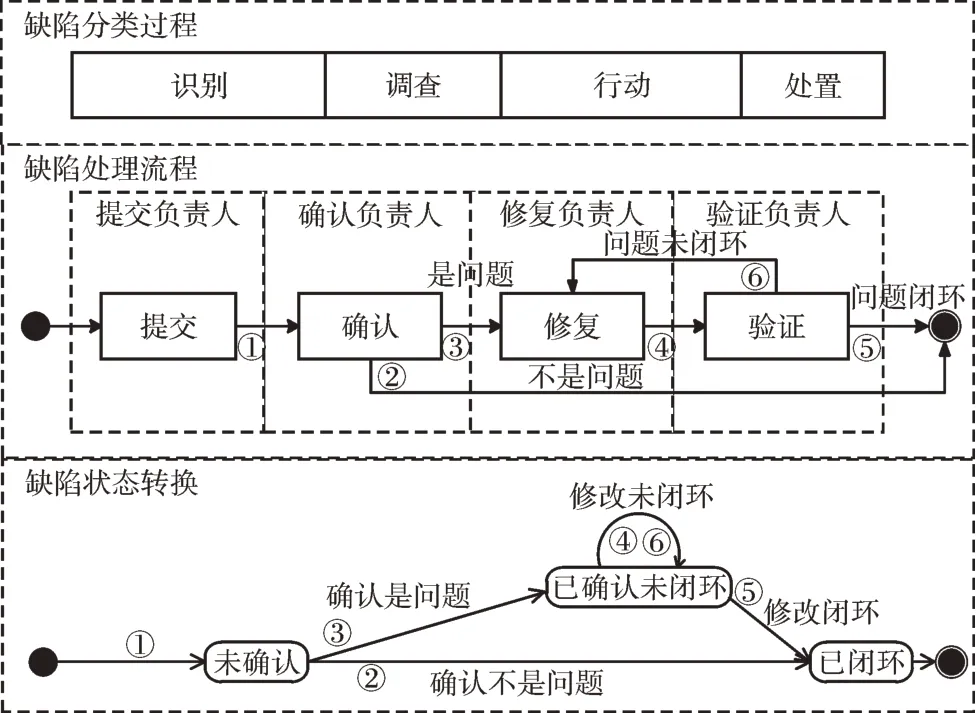
Fig.1 Implementation of defect classification图1 缺陷分类实现方式
1.2.4 缺陷数据跟踪与分析
基于缺陷属性及其变化信息的记录结果进行缺陷查询跟踪与态势分析。查询条件依托分类属性及其附属属性获得,包括时间与空间维度,例如发现时间、纠正时间、编号、名称、类别、状态、资产、制品、优先级、严重等级、发现方法、发现版本、纠正版本、处置结果等分类属性以及处理人员、所属产品、所属团队等附属属性及其组合。态势分析包括种类分析和收敛趋势分析。种类分析对查询获得的一定数量的缺陷进行分类统计,分类项为某一查询条件项。收敛趋势分析以若干个均匀的时间点为横轴,以同一类性质(如累计发现数、累计关闭数、当期发现数、当期关闭数)的缺陷数量为纵轴进行收敛趋势分析,以及以软件版本为横轴,以缺陷密度为纵轴进行收敛趋势分析。
2 原型系统及应用
2.1 原型系统设计
软件代码缺陷管理原型系统采用分层结构,分为数据层、业务支撑层、业务逻辑层和表示层,如图2 所示。数据层存储系统运行所需的数据,包括缺陷数据库和系统运行数据库,采用SQL Server 数据库。缺陷数据库存储缺陷及其跟踪数据,包括缺陷条目及其属性、缺陷状态变化及缺陷处理流程流转记录等数据。系统运行数据库存储支撑系统运行的数据,包括数据地址配置记录、业务参数配置记录及系统运行日志等数据。业务支持层对业务活动的实现提供支持,包括网络链路通信引擎、数据访问引擎、数据库引擎、邮件通信引擎、报表生成引擎等。网络链路通信引擎使用TCP 协议实现客户端与服务器端通过以太网进行通信,数据访问引擎实现对测试结果原始记录数据的访问,例如使用Web API 接口。数据库引擎使用ADO.NET 实现对SQL Server 数据库的操作,邮件通信引擎使用SMTP/POP3 协议实现邮件收发操作,报表生成引擎使用第三方Office 组件实现报表生成,业务逻辑层按照业务逻辑规则实现业务功能。业务逻辑规则包括缺陷定义规则、缺陷处理流程规则、数据同步规则和缺陷态势分析规则。表示层是人机交互界面接口,包括数据地址的配置、业务参数的配置、查询跟踪和态势分析结果呈现、报表导出等。

Fig.2 Architecture design of prototype system图2 原型系统体系结构设计
2.2 应用实例
本文应用实例如图3 所示。
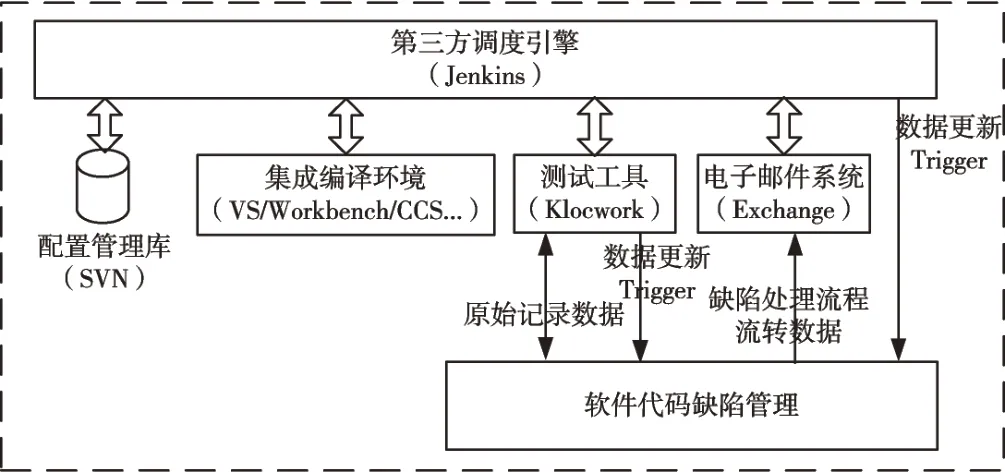
Fig.3 Composition of application example environment图3 应用实例环境组成
本实例中软件代码缺陷管理系统接入软件开发工具链。当第三方调度引擎从配置管理库中检出代码进行编译和测试后,基于原始的测试记录生成软件缺陷报告或更新软件代码缺陷属性,并通知相应负责人处理。负责人处理完相应任务后会触发软件代码缺陷属性的更新以及自动流转并通知相应负责人处理,在软件代码缺陷管理系统中进行缺陷数据的跟踪和分析。
3 效果评价
效果评价目标为评价本文软件代码缺陷管理方案及其原型系统较现有软件缺陷管理方案的问题改善程度。改善程度度量值通过使用专家评分法对比两种软件代码缺陷管理方案在同一软件配置项中进行软件代码缺陷管理应用效果获得。用于对比的典型软件代码缺陷管理方案为基于GJB/Z 141 附录C.3 的软件缺陷分类标准,使用类似文献[14]的定制缺陷管理工具进行缺陷管理。选取1 个软件产品为系统控制软件,由C/C++语言开发,代码规模约2 万行,效果评价周期为该软件产品的编码实现阶段。针对现有软件缺陷管理方案中存在的问题,选取5 个评价指标进行效果评价,分别为:①缺陷分类的细致程度及环境适应性;②缺陷分类内容值的准确性和一致性;③缺陷数据记录和维护便利性;④缺陷跟踪和分析的有效性;⑤缺陷处理流程流转的实时性。选取10 名评价专家进行打分,评价专家均为专业从事软件工程5 年以上的工程师。每项评价指标分值为0~5 分,得分由评价专家打分后求加权平均值得到。
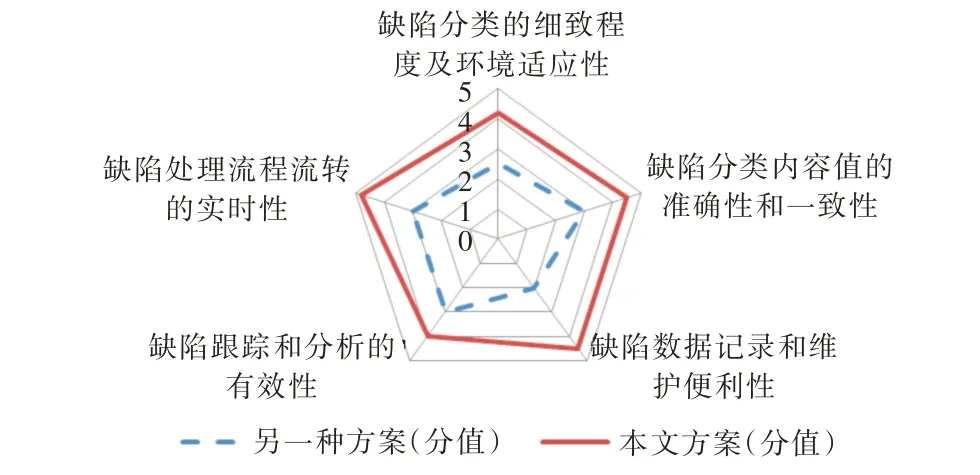
Fig.4 Comparison of application effects图4 应用效果对比
两种软件代码缺陷管理方案的应用效果评价得分对比如图4 所示。从图中可以看出,本文方案的应用效果较另一种方案在5 个方面评价指标上均有显著改善,其中,缺陷分类的细致程度及环境适应性分值提高了68%,缺陷分类内容的准确性和一致性分值提高了50%,缺陷数据记录和维护便利性分值提高了125%,缺陷跟踪和分析有效性分值提高了33%,缺陷处理流程流转的实时性分值提高了60%。评价结果表明本文方案在解决现有方案不足方面有明显改善,提高了效率。
4 结语
本文针对现有软件缺陷管理方案在工程应用中存在的问题,从缺陷分类方法和缺陷管理系统两方面展开研究,提出一种全新的软件代码缺陷管理方案。通过对比另一种基于GJB/Z 141 的软件缺陷管理方案,应用表明该方案在解决现有方案不足方面有显著效果。但由于缺陷分类方法与特定应用环境的耦合关系,本文研究成果的普适性仍有不足。另外,研究中发现不同来源的缺陷原始数据自身规则定义差别较大,如何有效对多源原始缺陷数据进行数据融合还需进一步研究。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
汽车零部件(2017年4期)2017-07-12
电子元器件与信息技术(2017年4期)2017-03-08
电脑与电信(2014年10期)2014-03-13
