
基于深度学习的非刚体三维重建
2021-08-02 07:40胡情丰
软件导刊 2021年7期
胡情丰
(浙江理工大学 信息学院,杭州 310018)
0 引言
目前,针对静态场景的三维重建技术已经非常成熟。尽管如此,最新方法依旧有着较大局限性。由于很多算法都对数据本身有一个先验假设,比如低秩,这些假设对NRSfM 技术应用于实际问题有非常大的局限性。如实际场景中最常见的多人问题、物体之间的遮挡等,都是对这项技术的一个巨大考验。
最近,基于该问题,Facebook 公司提出一套基于无监督学习的NRSfM 问题框架——C3DPO。该框架主要使用了目前最热门的神经网络代替传统因式分解,使得模型可以很好地拓展到更复杂的场景中,从而实现从二维观测矩阵到三维结构的转化。该框架在文献[1]、[2]的基础上,加入一个正则化网络,以确保因式分解的有效性。该框架不仅可以对非刚性运动场景进行有效的三维重建,而且在刚性运动场景三维重建上一样有着出色的效果。
本文创新点如下:
(1)选择将Lookahead 与RAdam 相结合的方式——Ranger 优化器,以加快神经网络训练速度。
(2)结合实验分析以及Ranger 本身的性能,采用iResNet 为基本骨干网络搭建网络模型,在保证重建效果的前提下优化网络复杂度,使其更易于训练。
1 相关工作
1.1 NRSfM
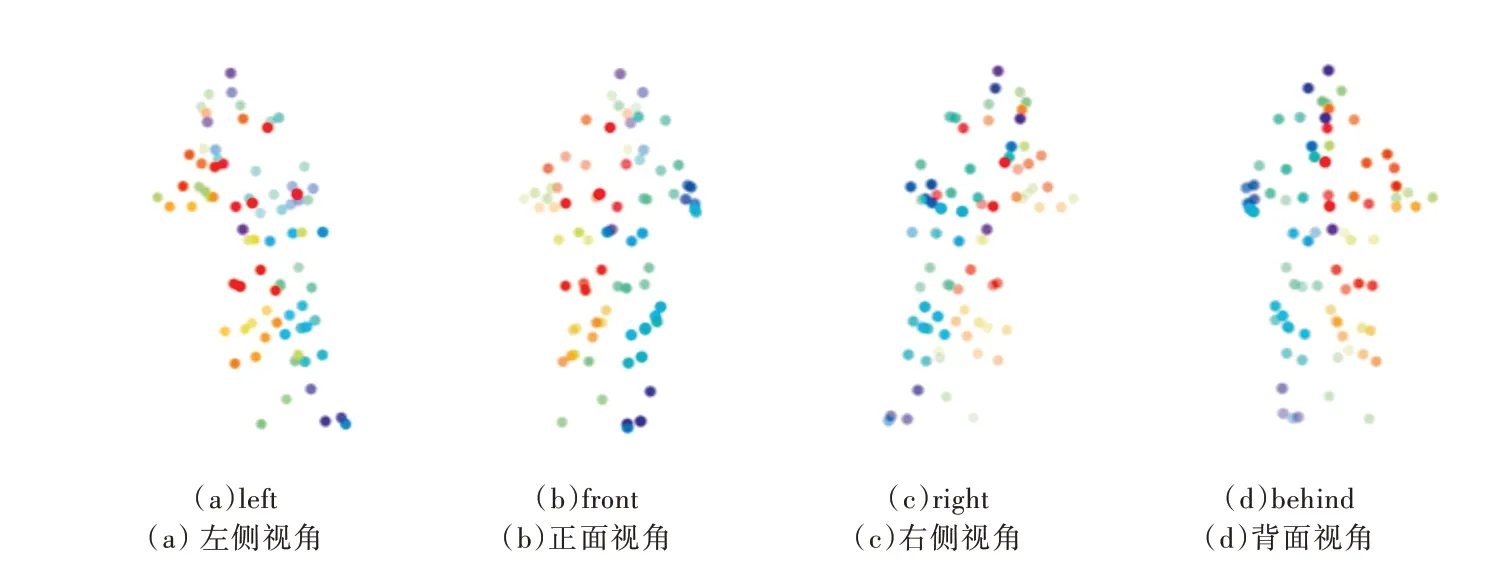
Fig.1 3D reconstruction visualization of S-Up3D data after passing through the model图1 S-Up3D 数据经过模型后的三维重建可视化
NRSfM 问题研究至今,人们已提出了许多解决方案,以实现从多帧图像的二维关键点中恢复变形对象的三维坐标及形状[3-6]。然而,由于非刚性物体在运动时会发生形变,导致NRSfM 实际上具有较多约束,这也对正确分解三维视点和形状构成了极大挑战。目前,利用对形状和摄像机运动的先验知识降低NRSfM 问题难度逐渐成为主流研究方法,例如假设在时间和空间域上使用低秩子空间[7-9],将二维特征点拟合到一组预先设计的DCT 基函数中[3-4],时空间联合模型[10-11]以及在时空间联合中加入稀疏子空间聚类等方式[8,12-13]。然而,在复杂的现实场景中,显然无法很好地利用这些先验假设,比如常见的显示场景中存在因物体本身视角问题导致的遮挡,乃至于多目标场景下存在物体与物体之间的遮挡等。
正因上述传统方案本身不具备很好的拓展性,如今越来越多研究者开始思考将现代的深度学习技术应用于NRSfM 问题处理中。然而,对于神经网络的训练而言,对大量图像进行三维姿态标注是一项非常繁重的工作。因此,文献[14]提出利用合成图像对训练数据进行增强处理,但将相关方法应用于现实场景中时,依然需要考虑到数据标注问题。人们开始逐渐从弱监督学习的角度进行考虑,通过一些简单的附加数据,如一些2D 姿态注释[15-16]、动作标签[17]等提高算法性能。最近,在无监督学习基础上,通过约束二维投影误差配合GAN 或自表达一致性误差约束的方式[18-20]辅助神经网络训练,取得了不错的效果,使研究逐渐开始往无监督学习方向延伸。
1.2 ResNet
自AlexNet[21]面世以来,深度卷积神经网络一直在计算机视觉领域处于主导地位。随着计算机视觉技术的发展,越来越多研究者将研究方向从工程手工特征转向工程网络体系架构,并建立了系列改进的网络架构。ResNet[22]的出现令神经网络研究进入到一个新层面,通过引入iden⁃tity skip connection 促进信号在神经网络中的传播,使更深的神经网络训练成为可能。如今ResNet 不仅在检测与识别中具有绝对优势,在处理NRESM 问题时也有非常不错的效果[18]。
随着时间推移,越来越多的ResNet 网络开始出现。ResNeXt[23]则是在ResBottle 块中采用群卷积的方式,将网络的多路径结构进行了统一。文献[24]使用一种预激活方式,在ResBlock 基础上,将BN 层与ReLU 激活函数放置在卷积核操作之前,使信号传播达到更好的效果,从而成功训练出比普通ResNet更深的模型。ResNeSt[25]使 用Split-attention 方式,将SE-Net[26]的思想应用于ResNeXt 的群卷积中,使其相对于SK-Net[27]更容易进行训练与优化。同时,iResNet[28]的提出将可训练的神经网络深度成功增加到3 002 层。
2 框架
对于SfM 问题,主要是从输入二维关键点的观测矩阵wn=(wn1,wn2,…,wnp) ∈R2×P获取对应的三维姿态坐标S=(S1,S2,…,SP)∈R3×P。其中,wn表示在第n 帧时P 个特征点对应的二维坐标。将共有F 帧的序列视为一个整体,整个问题可转化为:W=roS,W={w1,w2,w3,…,wF}T∈R2F×P,ro={ΨR1,ΨR2,…,ΨRF}T∈R2F×3。其中,Ψ:R3→R2是一种相机投影方式。为方便后续计算及模型搭建,本文选择正交相机,因此该投影方式可表示为:Ψ=[I20 ],其中I2∈R2×2为一个单位矩阵。同时,Rn为对应第n 帧中的旋转,而NRSfM 问题为SfM 问题在非刚体场景中的推广。不同之处在于,其通过一个简单的线性模型对结构S 进行合理约束:
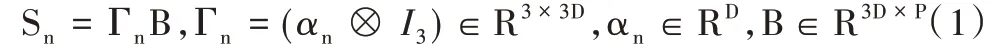
参数αn为Sn对应的视角参数,B 表示形状基,D 表示形状基的维度,在本文模型的训练中,该参数为训练前传入模型的初始参数,⊗表示Kronecker product。借此,公式(1)拓展到所有特征点和动作上,可表示为S=ΓB ∈R3F×P,其中对应Γ ∈R3F×3D。因此,从整个输入的视频序列角度考虑NRSfM 问题时,SfM 问题可进行相应的转化:。其中,roi(i=1,2,…,F)表示第i 帧对应的旋转矩阵。
图2 为本文模型工作流程,下分支通过最小化投影误差rploss进行单目视觉的三维重建,上分支通过正则损失caloss正确地学习内部形变并分解视点。

Fig.2 Workflow of model of this paper图2 本文模型工作流程
对于形状基B,本文使用一个单核卷积层学习获得,之后即可通过对W 进行分解,获取必要的三维姿态和视觉参数。在该步骤中,本文使用一个深度神经网络F 替代传统的因式分解,从而获取对应的视觉参数θ 和姿态参数α:
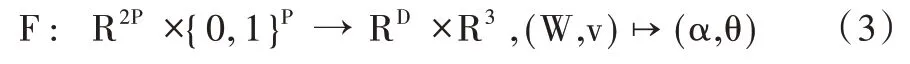
其中,参数v 是一个二值向量,用于表示该点是否被遮挡,取值为(0,1)。若该点被遮挡,则将对应的v 以及该点对应的空间坐标均置为0。该网络主要输出的元素为姿态参数α 以及3个参数θ,该参数主要用于ro计算,ro(θ)=ΛR(θ)。其中,R(θ)=expm[.]×,expm 为矩阵指数,[.]×为hat 算子。本文考虑使用重投影误差作为该模型的损失函数,具体表达式如下:
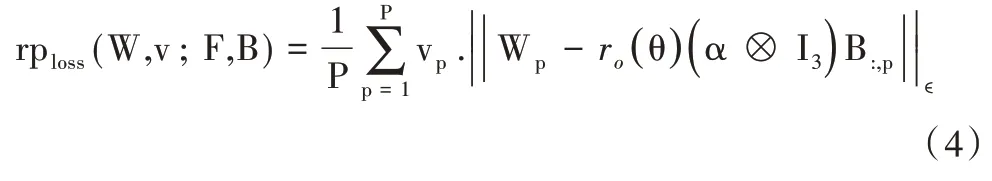
对于NRSfM 问题而言,如何正确分解视角参数θ 和姿态参数α 是非常重要的。因此,为了使深度神经网络F 具有良好表现,本文加入正则化网络ε。对于网络ε,本文选择与C3DPO 一样的损失函数进行训练:
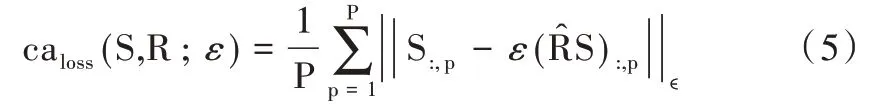
本文采用的网络架构如图3 所示,选择iResNet 为backbone,每一个网络都由Start、Middle、End 3 层基本网络块组成,其中,因式分解网络由1 个Start Block、2 个Middle Block 和1 个End Block 组成,正则化网络由1 个Start Block、4 个Middle Block 和1 个End Block 组成。Mish 激活函数表达式为:Mish=x*tanh(ln(1+ex))。
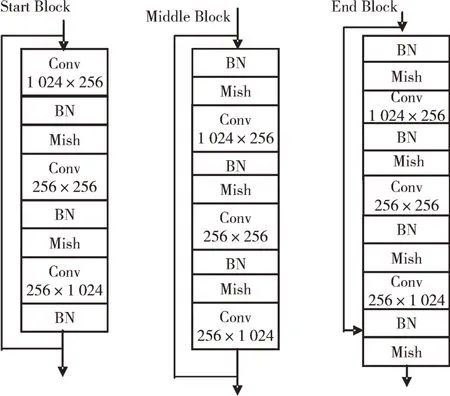
Fig.3 Architecture of neural network in this paper图3 本文模型神经网络架构
3 实验与分析
3.1 参数及数据集
H36M[29]:使用MoCap 系统获取的三维真实坐标进行标注,是目前最大的人体三维运动数据集。该数据集本身存在两种不同形式,第一种是用于训练与测试的二维真实观测点,另一种则是使用了Stacked Hourglass Network 检测网络得到的二维关键点。将数据划分为训练集和测试集两部分,选择5 个项目(S1、S5、S6、S7、S8)的数据进行训练,以及2 个项目(S9、S11)的数据进行测试,其中训练集共31 万帧,测试集共10 万帧。本文采用的性能评估方案为17 个关键节点每个位置误差的绝对平均值(Mean Per Joint Posi⁃tion Error,MPJPE)。
S-Up3D:即大型稠密的无噪声数据集Synthetic Unite the People 3D(S-Up3D),该数据集是由6 890 个顶点的SMPL(A Skinned Multi-Person Linear Model)形态模型通过正交投影得到的。与C3DPO 类似,本文将数据集分割为训练集和测试集,其中训练集共有171 090 帧数据,测试数据集共有15 000 帧数据。将SMPL 模型中的79 个对应特征点位置作为评估标准,计算对应的MPJPE,以衡量模型重建效果。
Pascal3D+:该数据集由PASCAL_VOC 图像与ImageNet图像组成[30],其使用了12 个具有稀疏关键点注释的刚性对象序列,每个序列最多与10 个CAD 模型关联。为确保2D关键点与3D GT 之间的一致性,使用正交投影对齐CAD 模型。此外,本文也使用通过HRNet[31]进行关键点检测后获得的2D 关键点作为二维坐标,传入模型中进行三维重建。
MPJPE:表示每个关节位置误差的绝对平均值。计算公式为:

其中,Sp∈R3表示第p 个特征点重建后的三维坐标表示第p 个特征点对应的真实三维坐标。
在实验环境方面,本文主要使用PyTorch 搭建神经网络,硬件配置如下:CPU 为Inter i7,内存为8G,显卡为RTX2060,操作系统为Ubuntu。
3.2 网络结构及优化器
本文在H36M 数据集上训练了两个模型,一个是正则化网络和因式分解网络协同训练的最佳模型,另一个是仅通过因式分解网络训练后的最佳模型,并从H36M 数据集中的S9、Direction 序列中随机选择一帧特征点对应的二维坐标传入到两个模型中进行三维重建,重建效果如图4 所示。其中,第一行为H36M 数据集的真实三维坐标可视化图,中间部分为H36M 数据集在网络ε协同训练下获得最佳模型的三维重建效果可视图,最后一行为H36M 数据集在没有网络ε协同训练下获得最佳模型的三维重建效果可视图。
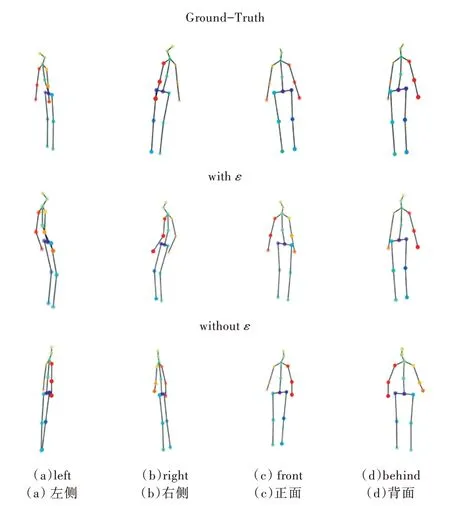
Fig.4 Reconstruction effect of the two models on the same set of experimental two-dimensional data points图4 两个模型在同一组实验二维数据点上的重建效果
从图4 中可以明显看到,仅使用因式分解网络无法很好地学习到内部形变,导致重建效果不理想,无法捕捉到动态变化。而加入正则化网络后,模型重建效果得到了很大提升,可以较好地对一些形变进行恢复。
同时,为对比所使用的优化器效果,分别使用Ranger和SGD 两种优化器在Pascal3D 数据集中进行实验,得到训练40 次epoch 时的re-projection loss 下降曲线。其中,每一个误差都为当前epoch 训练与验证的平均误差。图5 表示在Pascal3D 数据集上,优化器SGD 与Ranger 分别在train 阶段和test 阶段的re-porjection loss 下降曲线(彩图扫OSID 码可见)。
Fig.5 Training effect of SGD and Ranger on Pascal3D+dataset图5 SGD 与Ranger 在Pascal3D+数据集上训练效果
从图5 中可以看到,在同样的网络架构中,从Pascal3D数据集的训练效果来看,Ranger 的表现优于SGD。由于Ranger 是RAdam 与LookAhead 结合而成的,因此Ranger 优化器既具有RAdam 扎实的训练初期,又具有LookAhead 在整个训练期间非常优秀的向最优值探索能力。
3.3 重建对比
本章将本文模型与一些现有的baseline 及优秀的无监督学习模型进行对比。C3DPO 的实际重建效果优于其文献[18]中的展示。C3DPO 属于开源项目,因此本文对模型重新进行训练,并对训练得到的最佳效果进行记录。在本文模型的训练中,各个数据集都设置初始学习率lr 为0.001,权重衰减为0.0005,batch_size为256。参考文献[18]除H36M和H36M_Hourglass外,其余数据集都使用了一个相机转换层,该层只有一个1×1的卷积核。
针对H36M 数据集,本文整理了S9、S11数据集中的所有运动序列,并与C3DPO、PoseGAN[20]的重建效果进行对比,如表1、表2 所示(加黑的数据代表重建效果更佳)。在PoseGAN 部分,本文直接引用了文献[18]中的记录。
从表1、表2 可以很清晰地看到,本文模型在H36M 和H36M_Hourglass 数据集中都表现更佳。模型很好地学习到二维坐标与三维姿态之间的映射关系,可以比较稳定地对特征点进行三维姿态重建。
针对Up3D 数据集,为更好地体现本文模型效果,在该数据集中加入了两个比较优秀的baseline:GbNrSfM[12]、EM-SfM[32],其对应实验数据使用了文献[18]给出的数据,重建效果对比如表3 所示(加黑的数据代表重建效果更佳)。
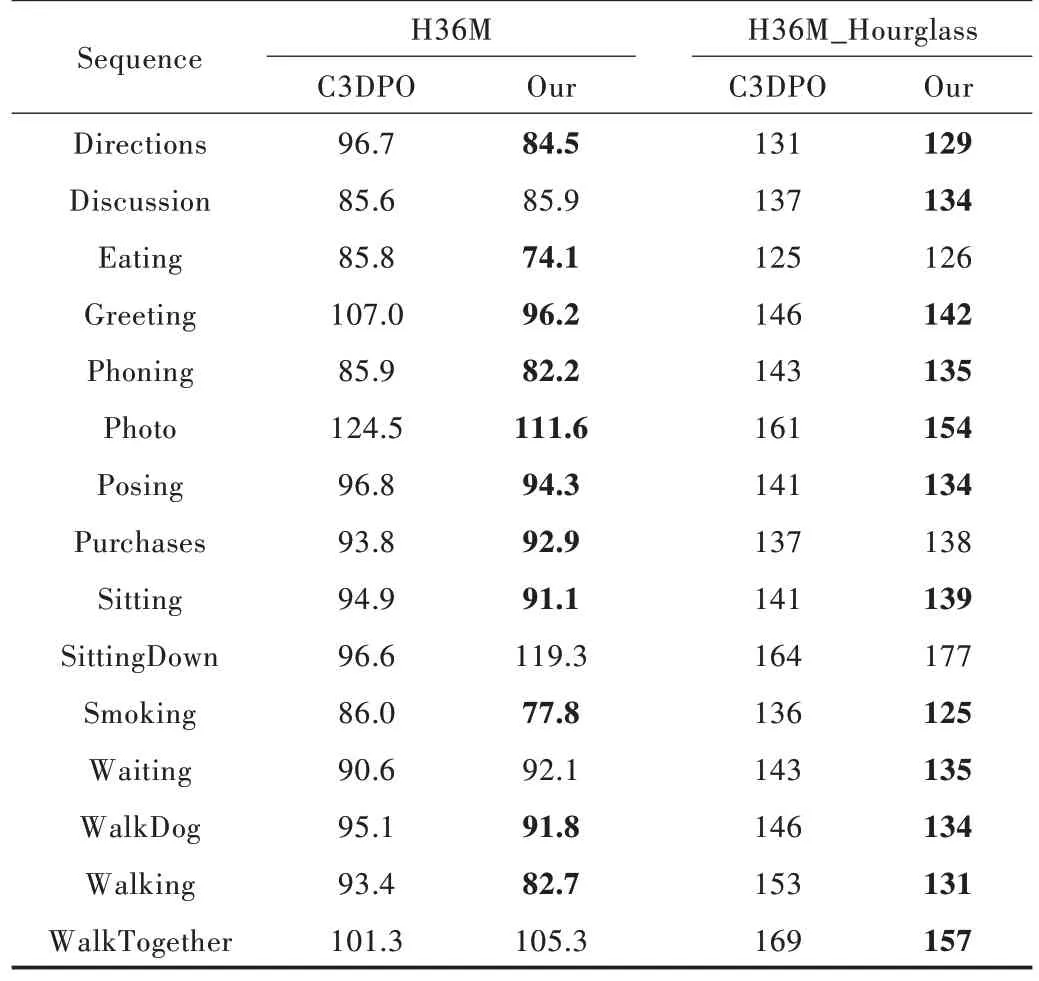
Table 1 Comparison of model in this paper with C3DPO(MPJPE)表1 本文模型与C3DPO 误差对比(MPJPE)
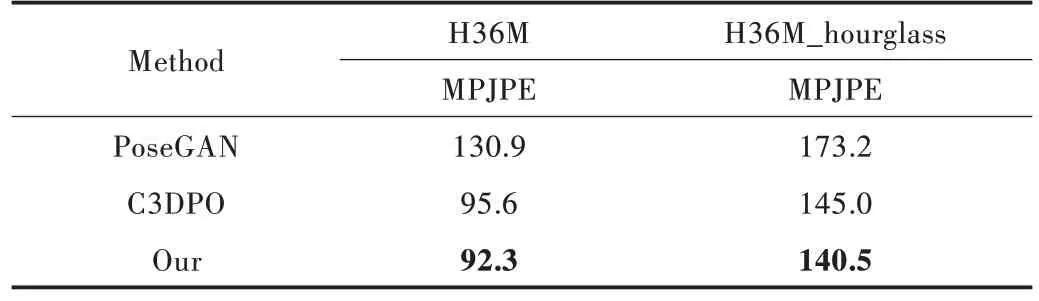
Table 2 Comparison of reconstruction effect in the H36M dataset表2 H36M 数据集上重建效果对比

Table 3 Comparison of reconstruction effect in the S-Up3D dataset表3 S-Up3D 数据集中重建效果对比
由于该数据集本身是无噪声影响的,因此模型对该数据集学习的效果都比较理想,但相比之下,本文训练出的最佳模型可得到更好的重建效果。
针对Pascal3D+数据集,在刚体场景中,本文选择Gb⁃NrSfM[29]、EM-SfM[33]及C3DPO 进行对比。GbNrSfM、EMSfM 的实验结果来自于文献[2],重建效果对比如表4 所示(加黑数据代表重建效果更佳)。

Table 4 Comparison of reconstruction results in the Pascal3D+dataset表4 Pascal3D+数据集中重建效果对比
从表4 中可以看到,无论是通过GT 还是HRNet 获取的检测坐标点,利用本文提出的框架及学习方式得到的最佳模型都表现更好。
最后,将本文框架与C3DPO 进行总结对比,对比结果如表5 所示。其中,best_model 列为模型在对应数据集训练过程中得到最佳模型所使用的Epoch(由于暂时对C3DPO在Pascal3D+和Up3D 数据集中的实验效果无法复现,因此在这两个数据集中,best_model 部分显示为“——”)。
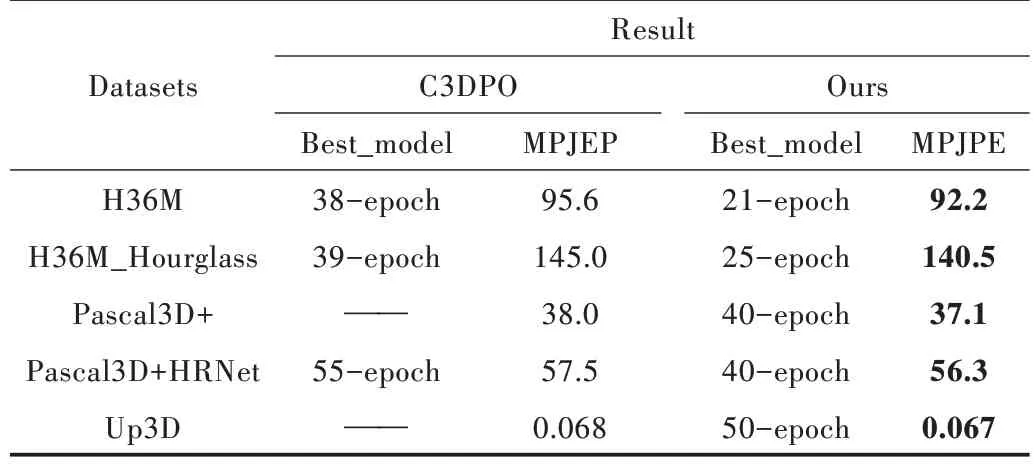
Table 5 Comparison between C3DPO and model in this paper表5 C3DPO 与本文模型对比
从表5 中可以看到,本文模型在训练时可更快速地朝最优方向前进,并且在保证学习效率和速度的前提下,获得更好的重建效果。
4 结语
本文为神经网络在NRSfM 问题上的应用。模型使用Ranger 优化器替换SGD 进行网络训练,并结合优化器性能,使用iResNet 为backbone 搭建因式分解网络和正则化网络,使模型重建效果更佳。本文不仅使用了真实坐标进行训练,而且加入了特征点检测(Pascal3D+HRNet,H36M +Hourglass),采用端到端的形式,无需任何标注数据,即可根据2D 图像进行三维重建。未来,2D 人体姿态估计算法作为三维重建的预处理操作,会成为无监督三维重建方向主要研究课题。因此,接下来将更深入地探索深度学习在NRSfM 问题中的应用。
猜你喜欢
中老年保健(2021年12期)2021-11-30
电子制作(2019年19期)2019-11-23
摄影之友(影像视觉)(2019年2期)2019-03-05
中华诗词(2018年11期)2018-03-26
光学精密工程(2016年6期)2016-11-07
Coco薇(2016年8期)2016-10-09
腹腔镜外科杂志(2016年12期)2016-06-01
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
中国医疗美容(2015年1期)2015-07-12
