
基于众源数据的铀矿地质知识建模研究
2021-07-30 08:55杨波赵英俊
铀矿地质 2021年4期
杨波,赵英俊
(核工业北京地质研究院 遥感信息与图像分析技术国家级重点实验室,北京 100029)
知识是智能的基础,人类智能往往依赖有意或无意地运用已知的知识[1]。以此类推,社会的发展无法离开人工智能的推动作用,有需求就会促进知识图谱的发展[2]。这里有两个核心问题:如何建模众源知识?如何在计算机中高效地存储与收集众源数据?本研究主要关注前者。
众源数据的铀资源知识表示即使用何种工具和方法对感兴趣领域进行知识建模,以便达到众源数据的知识为我所有[3-5]。在数据网络图谱方面,知识图谱是一种新型的互联网络,即一种运用关联节点和弧来代替知识的模型[6]。在将社会网络抽象化为语义网络的过程中,出现了网络聚集的现象,所以,需要定义一些基本的网络基础单元,如,本体、属性和案例。同时,这些基本单元之间也有相关关系,在语义网络中用边的属性表示基本单元的联系和纽带,这些边的属性是语义网络中的核心[7-8]。为了给这些关联设定步骤,前人学者设计了系列学术术语,并进一步提出了表达逻辑,他是一种对语言处理简化的规则,推理复杂度在置信区间内[9-12]。万维网标准委员会(World Wide Web Consortium,W3C)推出了以表达规范为基础原则的本体规则Web 本体语言(Ontology Web Language,OWL)并宣布为网络术语的官方语言。W3C 还推出了除上之外一种用于搭载Web 本体的规则资源描述框架(Resource Description Framework,RDF)。目前,利用向量来刻画知识图谱成为主流,其基本设定是将众源数据定义为一个具有初始节点、连接属性和结尾节点的知识建模方法。本文将详细阐述对众源数据的知识场景构建方法,进而探讨如何基于该方法对铀矿能源场景有效建模。
1 知识表示简介
20世纪90年代,麻省理工人工智能实验室的罗伯特·戴维斯定义了知识表示的几个用途和特点[13-15]:
1)现实世界的符号化,即众源数据应该要按照既定的规则和语言规范进行机器编码。
2)虚拟本体库,即众源数据要提前收集和挖掘相关的知识库和标准目录。
3)人机交互的媒介,即除了相关的语法规范,还需要对其进行标准化和数据模型的构建和应用场景的扩展。
简而言之,与传统人工智能比较,大数据时代的众源数据研究领域已经发生了翻天覆地的变革。
2 铀资源知识建模方法
2.1 核电弧边属性法
弧边属性是公理领域的权威规范逻辑,在属性逻辑里,可以用谓词和变量表示知识,设定,用(x)表示是中国核电站。这里,中国核电站是一元谓词,x 是变量,中国核电站是(x)的一个原子公式。“¬中国核电站是(x)”是一个否定公式。在上面的例子中,若x 为某核电站,中国核电站是(x)为第一个命题p。若x 为某核电站,中国核电站是(x)为第二个命题q。
2.2 核能网络节点法
语义网络这个概念由奎利恩等人提出用于阐释人类语义数据同时也可以进行推理[16-17]。语义网络类似于互联网,可以用各种形式进行表示,其具体的可视化展示类似带有属性的流程图。这些流程图中的各类“关节点”用以标识各种事实、概念、事件等。这些图中的关键点都至少带有一个属性,两个关键点之间,如果存在关联就用一个带有方向的链接联系起来,这些关联可以代表属性。表示众源数据的单元是三元组:关键点1,联想弧,关键点2,例如“某核电站,属于,某国家”“某核电站反应堆,类型,压水堆”是三元组。因为语义网络的节点是使用关联弧进行耦合,所以可以通过节点间的操作进行知识推理。
1)语义网络的优点
衍生性:语义网络是由人类生物群体的社会性特征衍生而来。
易用性:语义能够便利地把主客观时间运用节点和属性阐述清楚,因此,客观社会和语义网络很便捷地实现了符号化转换,所以,语义网络规则在人机交互的产品领域运用的最合适。
结构性:语义网络的特征是模块化的数据描述策略,这种方法对小模块,特别是铀资源领域的应用,效果非常好。可以把客观世界的众源数据利用节点间的关系进行显示。
2)语义网络的缺点
纷繁复杂的语言规则:利用语义网络来表示众源数据的铀资源图谱模型非常的灵活,而且用一种方法和另一种方法进行图谱建模差别较大,与此同时,由于不同的建模规则和方法,给后期的数据融合与知识推理增加了业务负担。例如,“全球在建的核电机组65 个”可以表示为多种不同的语义网络(图1)。由图1 可见,CN 是一个综合接单,指的是对一个领域的综合统称,像核电站一样。c是实体节点,他将描述CN 的一个确数,而g 是一个全称变量,是全球这个概念的一个个体,b 和nps 都是存在变量,其中b 是在建这个概念的一个个体,nps 是核电站这个概念的一个个体,F指c覆盖的范围及案例,而∀代表全称量词。核电作为铀资源的应用场景之一,可以把“全球建成442 座核电站”表示成:所有全球的s1都有属于建成442 座核电站这个概念的元素(图1)。
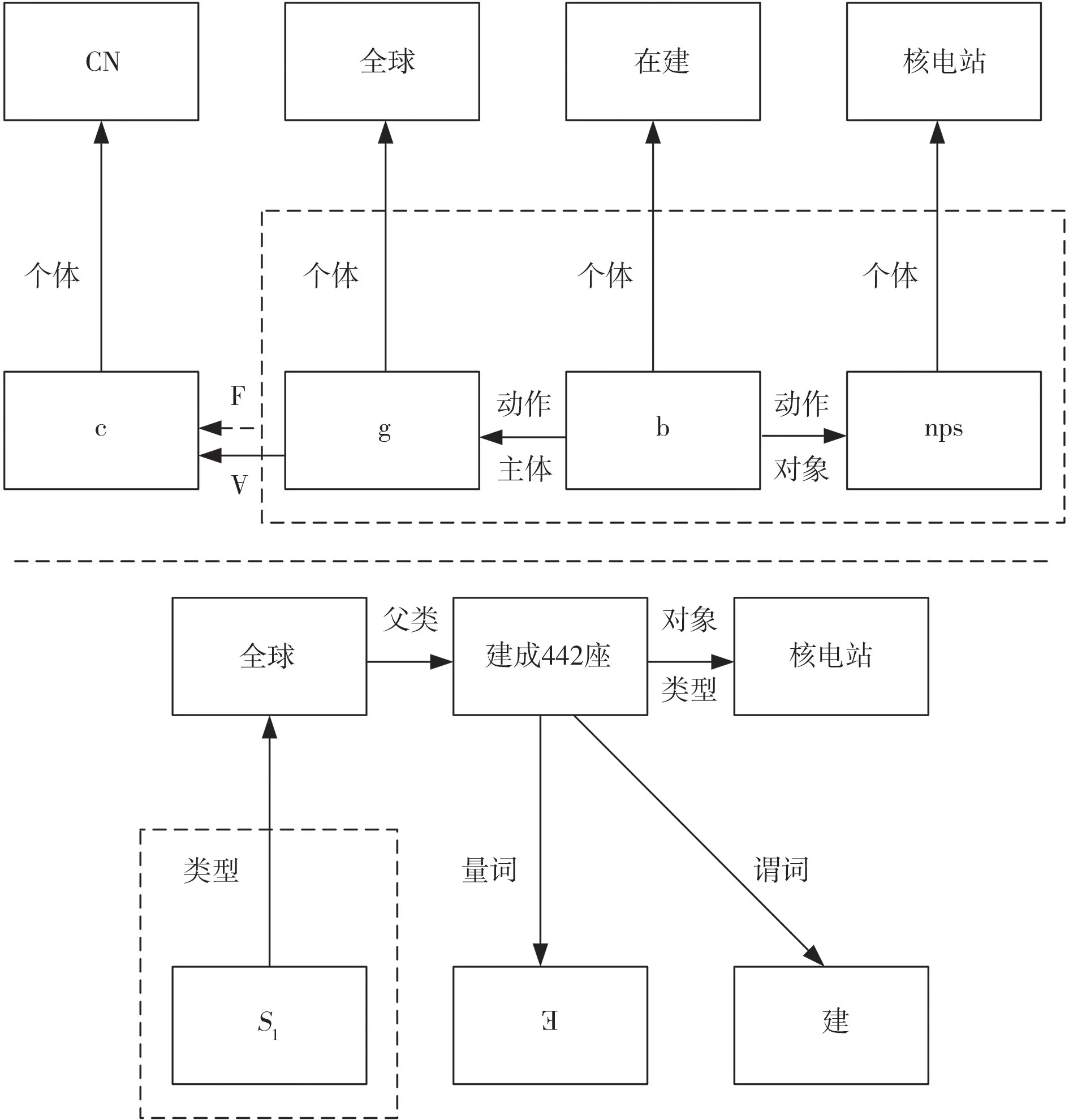
图1 众源数据组织的语义网络Fig.1 Semantic network of crowdsourcing data utilization
纷繁复杂的歧义:该方法与上一个方法比较,缺点是无认可的语言规则。在每一个专业领域,都有其特定的语义网络。并且,本文对众源数据进行知识推理的过程中,研究发现在多级推理后,该网络的准确性与推理层级成负相关关系。与此同时,本文所使用的量词和其他领域出现的量词无法统一,容易造成语义歧义。
2.3 铀事件框架法
框架(Frame)最早由马文明斯基在1957 年提出,作用是为了将计算机领域的自然语言处理更好的流程化[18-19]。该框架的核心内容是,表示人类社会的发展与进步是基于一种循环式前进,螺旋式上升的过程,当人类在生产与生活中遇到困难时,就会利用原有的社会经验积累,从以往的经历中挖掘可用的知识储备加以应用,这个过程需要对众源数据进行收集、加工、改进并利用到新的困难中,最后就会形成标准的流程解决思路,从而促进社会的进步。
基于铀事件框架的提出是为了解决铀语义网络中出现的纷繁复杂的问题,将原有的复杂逻辑描述成具有特点对象的知识结构。其基本原则是,规定类是其框架的原始单元。其中,类也有自己的元数据,元数据本身具有初始属性值。槽是用来刻画框架的属性信息,其中,槽的侧面用于表示槽的元数据信息,槽的属性是具体的领域数据,侧面的属性同样有领域值。除此之外,框架还允许给属性设默认值,以及设立触发器以维护框架。
1)框架基本组成的一个示例


2)变量赋值框架模式
只要把框架“铀资源”的变量赋值,就构造出框架模式(表1)。其中该模式的特征是按照领域知识的构建需要来定义变量名和变量赋值过程。

表1 带变量框架实例Table 1 Example with variable frame
3)框架的优点
体系化的将客观世界的物质联系用框架和可视化知识构建出来,可以完整地抽取核电站数据,并且支持默认值以及触发器。
4)框架的缺点
构建一个理想和高质量的框架体系不但需要大量的人力和物力,而且还需要专业化的理论知识作为基础。同时,默认值会增大推理的复杂度,也缺失对于非统一数据的整理。
3 众源数据中铀矿知识建模框架
随着知识图谱的日新月异,大数据为众源数据的知识建模提供了一把双刃剑。双刃剑的优势在于为众源数据的挖掘开拓了新的铀资源知识场景,双刃剑的劣势在于之前的学者并没有相关的铀知识建模研究。当前的互联网知识建模框架无法满足铀矿知识场景的应用需求,因此本文采用互联网成熟的规范语言,如RDF、RDFS(RDF Schema)和OWL,创立一种新的铀矿核电站知识表示模型。以上的几种描述逻辑都可以和XML 耦合,本文以RDF为例,利用RDF 来构建基于众源数据的铀资源本体知识。
3.1 铀资源描述框架法
RDF 规定,标准知识模型是一个三元组。在一个众源数据的铀资源案例中,知识的表示模型是:主语、谓语、宾语。在中国核电信息网中,“目前中西部已形成3 个万吨——十万吨级铀资源基地,对提高我国铀资源保障程度有重大意义”可以写成以下RDF 三元组:(铀资源基地,十万吨级,中西部),(铀资源,基地,中西部)。从案例中可以发现,RDF 是拥有主节点的一个独立事件。RDF 中的谓语是一个属性。每一个弧有两个节点连接,当然,也可以用一个弧连接节点和节点的实例。换言之,RDF 中的宾语可以是一个个体,例如(铀资源,基地,中西部)也可以是一个数据类型的实例,例如(铀资源,位置,“107.091525,41.070502”^xsd:location)。
只要把一个案例的核心内容抽取,主语和宾语就构成了知识图的节点,三元组的谓语看成边,那么一个RDF 知识库则可以被看成一个图或一个知识图谱。三元组则是图的单元。RDF 不仅需要抽取案例中的主语节点、谓语节点与宾语节点,还需要符号化其寻址编码的统一资源标识符(Uniform Resource Identifier,URI),包括以上的铀资源基地、十万吨级和中西部(图2)。

图2 铀资源三元组Fig.2 Uranium resource triad
全局标识URI可以被简化成前缀URI(图3)。RDF允许没有全局标识的空白节点(Blank Node)。空白节点的前缀为“_”。例如,铀资源基地是某一个级别关于中西部的铀矿基地。

图3 铀资源前缀节点Fig.3 Uranium resource prefix node
RDF 是抽象的数据模型,对于具体的实际案例,可以有不同的案例模型,像常见的RDF/XML 和Turtle 等(图4)。

图4 铀资源序列化规范Fig.4 Specification for serialization of uranium resources
3.2 铀资源定性知识表示法
在实际项目和科学研究中,研究者们都会根据具体的研究领域来确定最合适的众源数据知识建模框架。因为不同的知识建模框架会在具体的内容和表现形式上有所区别,但从根本上来看,他们之间的底层思路是相似的。常见的最典型的开放域知识图谱有Freebase、Wikidata、ConceptNet,这里以Freebase 为例,尝试构建知识表示框架,并总结影响知识表示框架选择的主要原因。为便于比较分析,以RDF、OWL 的描述术语和表达能力为主要比较对象。
Freebase 和以上几个知识图谱建模框架一样,都需要定义基础类与基础原生要素及属性,而且每个基础类都有与之对应的字符编码,类似于身份证编码,用于确定其位置及路径信息。每一个实体类知识有一个案例类,例如,天山铀资源基地就是一个对象类,而其寻址编码是:“01068513720”。同时,该铀资源属性划分为国家级类,其铀矿空间地理地址为:“81.246346,43.590763”,其中,本文使用多重复合类(Compound Value Type,CVT)作为连接中心,用于处理多类型资源与空间位置的复合信息。示例的CVT 提出了关于铀资源的多元关系(图5)。

图5 铀矿知识结构Fig.5 Uranium knowledge structure
3.3 铀资源定量知识表示法
与前面所述的表示方法不同的是,下面要构建的方法是利用定量的方法把铀资源网络构架抽象到数学公式中,而不是使用基于离散符号的表达方式。根据相关知识建模定量方法的文献调研,本文将利用语义模型来进行知识的网络的定量化研究,该方法的核心模型是RESCAL。基本原理是首先将所有的语义知识编码成三维知识符号,然后利用数据的张量关系,将前面的知识符号分解为主张量和副张量,最后通过设定误差概率函数来保证自动获取的知识图谱的正确性。其中,得分函数为:

式中:h为知识模型中的头实体;t为知识模型中的尾 实体;Mr为由h和t构成,且数量为r的关系矩阵。
因该算法的模型是矩阵相乘,为防止相乘的结果为空,需要防止Mr的对角化。但因为是对角矩阵,所以存在hTdiag(r)t=tTdiag(r)h,也就是说这种简化的模型只天然地假设所有关系是对称的,显然这是不合理的。后期需要针对该算法进行进一步的数学原理的文献调研,找到更加合理的定量化算法来为众源数据的知识挖掘提供数据基础。
4 铀矿床本体知识建模
4.1 简介
本文采纳Protégé工具将对众源数据构建知识模型,Protégé 以Java为底层开发语言,是目前最受欢迎的知识建模开源工具之一[20]。其中Protégé 与其他众源数据知识建模相比,除了操作简单、用户友好之外,其典型特点是在和传统的知识建模中的工具对比后,Protégé 不仅方便易操作,而且还支持中文知识建模。Protégé 的常见功能包括:类建模、实例编辑、模型处理和模型交换。
4.2 本体建模
1)铀矿抽象建模类
Protégé的首页有基本的常用工具栏和标签页(图6)。首先,选择Web 本体语言类添加新的抽象类,然后创建想要的本体类,如在对话框中,“Name”一栏输入名字“铀矿”本体知识。
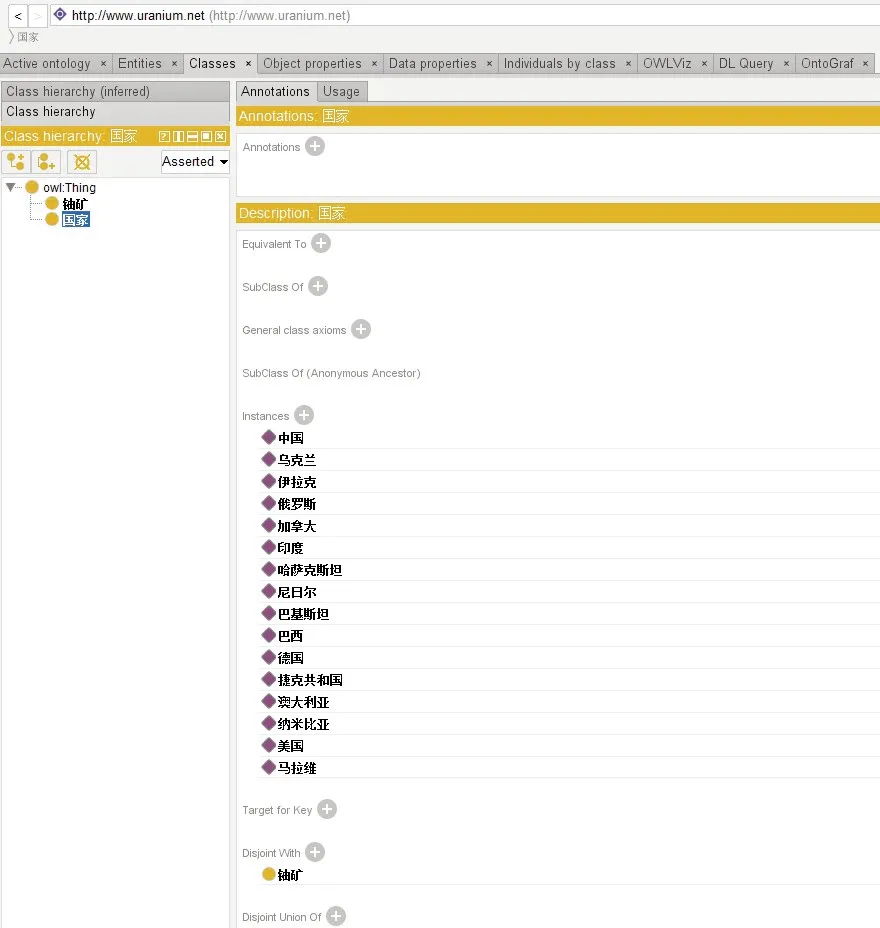
图6 建模类Fig.6 Modeling class
2)建立铀矿实体类节点与属性
右击主节点,点击添加子类,将名字改为“中国”,然后以该子类为节点继续创建子类的铀矿床节点,最后建立矿床的子类33 铀矿(图7)。同样,建立属性与建立子类类似,先选择一个对象属性,如定义某矿床的的遥感影像、地点、国家、坐标、产品、发现、开采以及开采公司等属性信息。
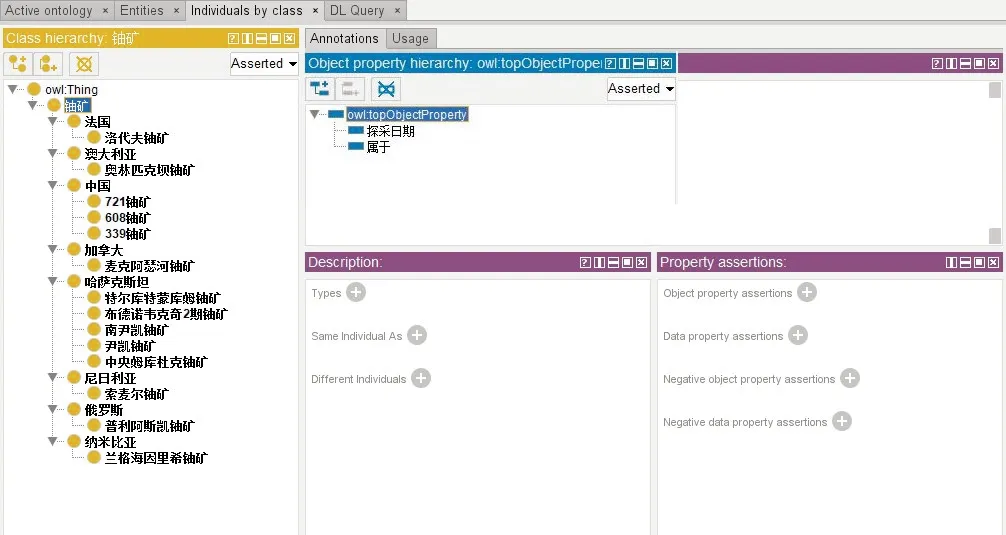
图7 建立子类与属性Fig.7 Create subclasses and attributes
5 结论
本文比较全面地利用知识图谱技术对铀矿地质知识信息进行建模,目前大部分开放知识图谱的表示语言基于RDF、RDFS 和OWL,前面几个本体建模语言是万维网联盟官方推荐的知识建模规范。除了这些标准语言,本文还测试通过利用知识图谱的数据检索规范SPARQL 进行众源数据的铀矿地质知识查询与建模。最后,提出了利用众源数据进行知识图谱的嵌入式方法,并以全球铀矿资源的开采地为实例,利用Protégé 开源工具构建基本的知识建模方法及步骤。本文提出的基础知识建模方法为后续的知识储存及融合打开了技术及创新思路。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
少先队活动(2020年12期)2021-01-14
数学物理学报(2020年3期)2020-07-27
开放教育研究(2020年2期)2020-03-31
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
现代语文(2016年21期)2016-05-25
燕山大学学报(2015年4期)2015-12-25
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
大连民族大学学报(2015年2期)2015-02-27
