
基于改进的双向长短期记忆网络的视频摘要生成模型
2021-07-30 10:33武光利李雷霆郭振洲王成祥
计算机应用 2021年7期
武光利,李雷霆,郭振洲,王成祥
(1.甘肃政法大学网络空间安全学院,兰州 730070;2.中国民族语言文字信息技术教育部重点实验室(西北民族大学),兰州 730030)
0 引言
近年来,随着科技的不断进步,人们拍摄各种高质量的视频变得越来越方便,一部手机就可以满足日常的视频拍摄需求,在享受便捷视频捕获与分享时也面临一个严峻挑战:海量视频数据的理解与分析。面对这些无穷尽的视频数据,用户迫切需要一个能够快速分析视频内容的有效工具,视频摘要技术因此应运而生,成为帮助人们快速浏览视频数据的关键工具[1]。
视频摘要就是以视频的结构和内容为主要分析目标,获取其中有意义的片段,然后用特定的方法将片段拼接成能概括视频内容的视频概要。视频摘要根据不同的获取方式可以分为两类:动态视频摘要和静态视频摘要。
静态视频摘要是从原始视频中提取少部分图像作为摘要内容,这些静止帧概括了视频的关键内容,称为关键帧。静态视频摘要按关键帧提取方法不同,主要分为以下几类:
1)基于视频聚类的关键帧提取方法。聚类算法广泛应用于模式识别、音频分析、图片分割、信息检索等领域。镜头聚类以聚类的方法为基础,对每个镜头进行分析,然后将特征相近的帧划分为一类,最后从每一类中按照一定方法选取关键帧,文献[2-4]通过对图像视觉特征的提取和改进,提升了聚类方法的准确率。聚类方法对未知视频的预测效果较差,而且运算复杂度较高。
2)基于视频帧信息的关键帧提取方法。这一类方法主要考虑视频帧包含的特征信息,例如颜色、形状、纹理等,通过提取到的特征信息,计算相邻帧之间的相似性,将相似性低的帧按照需求选为关键帧[5-6]。基于视频帧信息的方法可以根据视频内容的显著性变化来灵活确定关键帧数目,但不足之处是:当镜头的变化较多时,容易导致选取的关键帧数目过多,造成冗余。
3)基于镜头边界的关键帧提取方法。这类方法首先要将源视频进行镜头划分,之后在不同镜头中选取关键帧[7-9]。Gong 等[10]提出的SeqDPP(Sequence Determinantal Point Process)方法是一个用于不同序列子集选择的概率模型,能够较好地考虑到帧之间的依赖关系和视频的顺序结构。基于镜头的方法容易设计,计算速度快,非常适合于场景变换少的情况;但当视频的镜头变换复杂且方式多样时,会导致提取的关键帧不能准确概括源视频内容。
静态摘要最大的不足是合成的摘要不具有时序连贯性,给人一种快进的感觉,而动态摘要是将镜头进行组合,在不丢失关键内容的同时保留了视觉连贯性。因此本文重点研究动态摘要。
动态视频摘要主要包括视频镜头分割、视频镜头评价、视频镜头选择。视频镜头分割是将一个完整视频切分成若干个短视频,是动态摘要的基础;视频镜头评价则是根据不同的方法计算出每个镜头的重要性;视频镜头选择是根据具体需求选择合适的镜头组合成视频摘要。
镜头划分完成后,需要选出关键镜头组合成摘要。视频可以看作具有时间连续性的图片集,目前循环神经网络(Recurrent Neural Network,RNN)在处理序列数据方面效果显著,虽然常用的卷积神经网络(Convolutional Neural Network,CNN)在提取单张图片特征方面能力较强,但往往忽视了图片间的内在关联,而RNN 充分考虑时间维度,能够描述出时间上连续状态的输出,还具有一定的记忆功能。其中长短期记忆(Long Short-Term Memory,LSTM)网络作为RNN的变体,常用于解决RNN 无法构建远程依赖的问题,对长序列数据的处理十分擅长。LSTM网络大多数用于编码器-解码器架构,这种架构可以高效率处理变长序列问题。因此,基于编码器-解码器架构的LSTM 网络应用于视频摘要领域是可行且有效的。
Zhang 等[11]首次将LSTM 网络应用到视频摘要任务,提出了VSLSTM(Video Summary Long-Short Term Memory)模型,通过双向长短期记忆(Bi-directional Long-Short Term Memory,BiLSTM)网络预测视频帧的重要性得分,同时为了提高生成摘要的多样性,还提出了DPPLSTM(Determinantal Point Process Long-Short Term Memory)模型,通过BiLSTM 网络输出帧级重要性分数和帧间相似度,然后将它们与行列式点过程结合,选择出最终摘要。Ji 等[12]将注意力机制与编码解码器相结合完成视频摘要任务,其中编码部分由BiLSTM 网络构成,解码器部分通过基于注意力机制的LSTM 网络完成解码并输出。
上述基于编码器-解码器架构的模型已被验证能有效处理长序列数据,但仍有一些不足。例如,编码器-解码器框架的预测效果虽然较好,但是计算复杂度非常高,尤其是选择了BiLSTM 网络作为基础模型时,随着输入序列增加,计算量急剧增大,模型输出的特征维度变大,使得全连接层参数过多,容易出现过拟合问题。
为了减少过拟合问题的出现,同时考虑到视频摘要具有时序性质,本文提出了基于改进的BiLSTM网络的视频摘要生成模型。该模型基于编码器-解码器框架,编码器部分由CNN 提取视频帧的深度特征,而解码器则由结合了最大池化的BiLSTM 网络构成。本文的训练是基于有监督的训练,当CNN 提取的视频帧特征传入BiLSTM 网络后,输出基于时间序列的特征,该特征输入最大池化进行特征优化后,经由全连接层输出模型最终结果。将BiLSTM网络与最大池化结合后,能够降低特征维度,突出关键特征,过滤无关特征,减少全连接层所需参数,避免过拟合问题。
本文的主要工作如下:
1)提出了一种基于改进的BiLSTM网络的视频摘要模型。通过将BiLSTM网络与最大池化的结合,有效降低了输出特征维度,降低了全连接层的运算复杂度,避免出现过拟合问题。
2)在两个公开数据集TvSum 和SumMe 上与基于LSTM 网络的方法进行了比较,结果显示本文模型的F1-score 分别提高1.4和0.3个百分点。
1 相关工作
1.1 卷积神经网络
本文使用的CNN模型是VGG(Visual Geometry Group)[13]。VGG 网络突出特点是简单,这体现在它的所有卷积层的卷积核尺寸均为3,池化层核均为2,模型由各个层堆叠而成。例如VGG 网络的经典之一:VGG16,它包含13 个卷积层和5 个池化层以及3 个全连接层,相同尺寸卷积核经过卷积后能够产生相同尺寸特征图,2×2 的池化核使得池化后的特征图大小缩减为原来一半。图1展示了VGG16的网络结构。

图1 VGG16网络结构Fig.1 VGG16 network structure
1.2 长短期记忆网络
BiLSTM 网络由一个前向的LSTM 和一个后向的LSTM 组成,能够对输入数据进行正向和反向遍历,可以为网络提供更丰富的信息,让网络能够更快、更充分地学习。
LSTM 是RNN 的一个变形,RNN 的一个显著缺点就是没办法处理较长的序列数据,会出现梯度消失和梯度爆炸问题。针对这种问题,LSTM新增了一种结构:细胞结构,这种结构由细胞状态ct和三个门组成。细胞状态可以理解为一条传送带,它在整条链上运行,通常ct是由上一个状态ct-1和一些其他数值构成,因此细胞态的改变是缓慢的。门可以让信息选择性地通过,主要由一个sigmoid 层和点乘运算构成,sigmoid层的输出中每个元素都是0~1 的实数,它的大小代表着是否让信息通过的权重,0 代表不允许通过,1 代表全部通过。细胞结构如图2所示。

图2 LSTM细胞结构Fig.2 LSTM cell structure
细胞结构中的第一个门被称为遗忘门ft,从名字上不难理解,它决定着从细胞状态中丢弃多少信息。该门首先会读取上一次输出的隐藏状态ht-1和本次的输入xt,经过处理后,输出一个0 和1 之间的数,这个数的意义就是前面提到的sigmoid输出值的意义。遗忘门计算公式如下:

式中:σ为sigmoid函数,wf是权重系数,bf是偏置系数。
细胞结构中的第二个门被称为输入门,该门控制着有多少新信息加入到细胞状态中,它需要两步来实现,第一步输入状态it决定哪些信息需要更新,决定备选用于更新的信息。第二步通过乘运算将两者结合,来对细胞状态更新。ct-1与ft进行乘运算,然后加上it与的乘运算结果,形成新的候选值。用到公式如下:

细胞结构中的第三个门被称为输出门,这个门决定最终输出哪些信息。输出的信息基于细胞状态和输出状态ot,ot根据上时刻隐藏状态ht-1和当前输入xt来决定要输出细胞状态的哪部分,然后将细胞状态经过tanh 后与ot进行乘运算得到最终输出结果,用到公式如下:
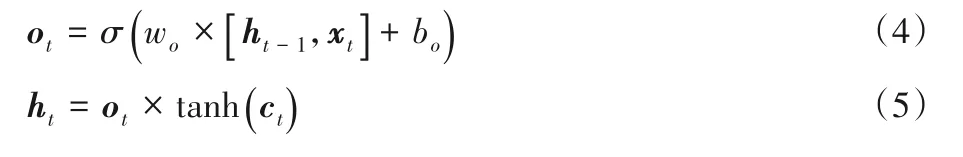
1.3 池化
池化具有两大优点:一是能够显著减少参数数量。图像经过卷积后获得图像的特征,若直接用特征进行运算,将会面临巨大运算量的挑战。但是经过池化以后特征减少,模型复杂度降低,能够极大提高运算速度,同时减少过拟合的出现。二是池化具有平移不变性,这意味着即使图像产生了小的平移,仍然会产生同样的池化特征。例如在对视频中关键人物进行特征提取时,即使两张图像中关键人物的位置不同,经过池化后依旧可以提取到相同的关键特征,更好地完成任务。
常用的池化方式有最大池化(max pooling)和平均池化(mean pooling)。两者都是提取区域特征,能够过滤部分不重要信息,使得细节上更容易识别。通常来说,最大池化能够更多地保留纹理特征,平均池化能更多地保留背景特征,根据任务不同选择合适的池化方式。图3展示了特征的池化过程。

图3 特征池化过程Fig.3 Process of feature pooling
2 模型构建
基于监督学习的视频摘要任务可以看作是序列预测问题,因此设计了一个基于改进的BiLSTM网络的视频摘要生成模 型BLMSM(Bi-directional Long short-term memory Max pooling Summarization Model),模型结构如图4 所示。该网络通过卷积神经网络VGG16 来提取图像特征,然后通过BiLSTM 网络将图像特征转换为时序特征,增加了模型可学习的上下文特征;之后创新地结合最大池化方法,将特征进行优化,更加突出中心关键特征淡化无关特征;最后通过全连接层得到视频帧的重要性得分,然后将视频帧得分转换为镜头得分,通过0/1背包算法选择出关键镜头,最后合成为视频摘要。图5展示了算法流程。
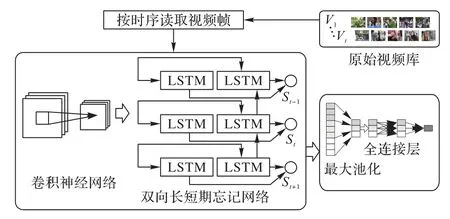
图4 BLMSN模型结构Fig.4 BLMSN model structure

图5 基于改进BiLSTM的视频摘要生成技术流程Fig.5 Flowchart of video summarization generation technology based on improved BiLSTM
2.1 图像特征提取
图像特征提取部分主要由VGG16 的卷积层和池化层完成,共13 个卷积层和5 个池化层,卷积层的卷积核大小均为3×3,池化核均为2×2。每经过一次卷积提取的图像特征便不断加深,然后利用池化层过滤部分无效特征,突出局部重要特征,通过这种反复堆叠3×3 的小卷积核与2×2 池化核,容易形成深层的网络结构来提升性能,进而提取出更加有效的图像特征。图6展示了图像特征提取过程。

图6 VGG16提取图像特征Fig.6 VGG16 extracting image features
2.2 时序特征提取
LSTM将卷积神经网络阶段输出的深度特征,以时间步的形式输入到LSTM 的网络中,并基于监督学习与深度学习进行模型训练,得到时序特征。由前面可知,VGG16 最终输出特征维度为(b,c,h,w),LSTM 中batch-first 参数设置为True 后输入张量的维度(batch_size,seq_len,input_size),因此重新定义VGG16 输出维度为(b,c,h×w)作为LSTM 输入,使得每一帧的特征信息能够完整传递。同时,为了能更好地考虑时间序列带来的影响,本文选取BiLSTM,因为当前时刻的输出不仅与之前的状态相关,还可能与将来的状态有关,因此两个LSTM 分别从正向和反向进行计算,最后对两个结果进行合并。图7展示了BiLSTM提取图像时序特征。
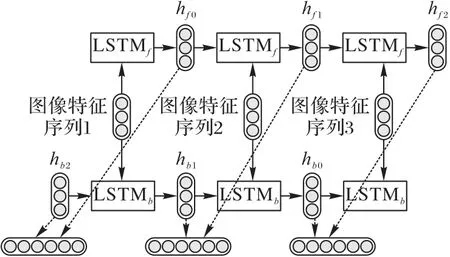
图7 BiLSTM提取图像时序特征Fig.7 BiLSTM extracting image sequence features
2.3 特征优化处理
max pooling 的应用,减少了网络参数与运算量,能降低模型复杂度,防止过拟合发生,同时对于之后的全连接层,还能减少单个过滤器的参数数量,提升运算效率。
本次max pooling 由MaxPool2d 实 现,其 中kernel_size 和stride 参数均设置为5,padding 参数置为0,dilation 参数置为0。池化的输出尺寸计算公式如下:

式中:p为参数padding,d为参数dilation,ksize为参数kernel。
特征优化处理是整个模型的核心,同时也是创新点所在,采用了最大池化的方法对LSTM 输出的时序特征进行降维压缩,提升运算速度。最大池化对于不同位置的关键特征,既可以保持特征位置信息,又具有平移不变性,因此关键特征即使出现位置不同,也能将其提出。在视频摘要任务中,关键特征十分重要,例如关键的人和物,这些关键特征的信息能否成功提取对于视频摘要的生成起决定性作用。特征优化如图8所示。

图8 特征优化过程Fig.8 Process of feature optimization
2.4 基于重要性分数的视频摘要
视频摘要最终展现出的是关键帧组合成的压缩视频,因此关键帧的选择直接影响到视频摘要的质量。本文模型输出的是帧级别的重要性得分,相比对帧集合的打分,计算复杂度明显降低,同时对于帧数的选择灵活,能够根据不同场景选择适当数目关键帧。


式(7)亦可称为经验风险,因此最优模型的策略等价于经验风险最小,最优化问题转换为经验风险最小化问题:
式中Γ为模型假设空间
2.5 帧级重要性分数转换镜头分数
本文任务基于动态视频摘要技术,最终合成的摘要应当是视频镜头的合集,由于模型输出结果是帧级别重要性得分,因此需要将帧级分数转化为镜头分数。首先要对视频进行镜头划分,本文使用在镜头分割方面效果优异的内核时间分割(Kernel Temporal Segmentation,KTS)算法[14]。对视频执行变点检测并将视频进行镜头分段。然后根据镜头中每帧的分数加和求平均得到镜头的分数ci(式(9))。此外,根据Fajtl等[15]的建议,生成摘要的长度限制为原始视频长度的15%,本文任务需要选择最大化分数的镜头,选择满足条件的镜头等价于NP 难问题,因此使用0/1 背包算法来选择合适镜头组成摘要(式(10))。

其中:ci为第i个镜头,Ni为第i个镜头包含的帧数,si,j为第i个镜头中第j帧的分数;ui∈{0,1}表示是否被选为关键镜头;K表示镜头的数量,L表示视频的总帧数。
3 实验结果与分析
3.1 实验设计
3.1.1 数据集
本次实验主要在TvSum[16]和SumMe[17]两个数据集上进行,表1展示了它们的具体信息。

表1 两个标准数据集的详细信息Tab.1 Details of two standard datasets
TvSum 数据集是视频摘要领域常用的数据集。它包含了50 个视频,所有视频均来自YouTube,这50 个视频共分成10个主题,每个主题包含5 个视频。该数据集还包含了每个视频的标注得分,这些得分来自20 个不同人使用亚马逊仪器进行标注,标注从1(不重要)到5(重要)进行选择。图9 展示了数据集部分图像。

图9 TvSum视频图像示例Fig.9 Video image examples of TvSum
SumMe数据集是验证视频摘要技术的一个常用基准。它由25 个视频组成,视频包含假日外出、美食鉴赏、运动挑战等多个主题。每个视频由15~18个人进行标注。图10展示了数据集的部分图像。

图10 SumMe视频图像示例Fig.10 Video image examples of SumMe
3.1.2 评估指标
为了与其他方法进行比较,本文按照文献[14]中的评价方法,即通过对比模型生成的视频摘要和人工选择的视频摘要的一致性来评估模型的性能,衡量指标采用计算F1-score值。假设S为模型生成的摘要,G为人工选择的摘要,O为S和G重叠的部分,精准率和召回率计算如下:

由式(11)、(12)可以计算出用于评估视频摘要的F1-score。

3.1.3 实验设置
选取数据集的80%作为训练集,剩下20%作为测试集。TvSum 数据集共50 个视频,其中40 个视频用于训练,10 个视频用于测试,视频帧速率均为30 帧/s(Frames Per Second,FPS);SumMe 数据集共25 个视频,20 个视频用于训练,10 个视频用于测试,视频帧速率为30 FPS。由于视频分辨率不同,实验时将分辨率统一设置为224×224。考虑到视频进行镜头划分后,同一个镜头中的帧是非常相似的,同时相邻帧包含的信息量也是相同的,因此对每个视频进行子采样,每15 帧选取一帧,使得模型训练速度大大加快。
该次实验使用的两个基准数据集数据量较小,同时为了减少过拟合现象的出现和提升模型泛化能力,本项目对数据集使用5 折交叉验证。此外,根据文献[16-18]中的相关研究,对TvSum 评估测试时,选取每个用户F1-score 值的平均值作为最后结果;对SumMe 评估测试时,选取每个用户F1-score值中最大值作为最后结果。
3.2 结果对比与预测
3.2.1 对比实验
本文选择了两种基于LSTM 算法的视频摘要模型进行对比,对比数据均来自原始论文:1)VSLSTM[11]使用双向LSTM为基础,建立过去和将来方向上的远程依赖,最后与多层感知器相结合;2)DPPLSTM[11]是在VSLSTM 的基础上新增了行列式点过程,能够增加生成摘要的多样性。
根据表2 数据可知,本文方法在两个基准数据集上相比其他两种LSTM 方法取得了更好的效果。在TvSum 数据集上,本文的方法F1-score 值提高了1.4 个百分点,在SumMe 数据集上,本文的方法F1-score 提高了0.3 个百分点。分析可知,本文的方法(BLMSN)将BiLSTM 与max pooling 结合,在保留前面方法优点的同时,通过max pooling保留了重要特征,过滤了部分无关特征,同时达到了降维的效果,减少了全连接层参数数量,避免了过拟合的出现,提高了摘要选择准确性。

表2 BLMSN模型与其他模型的F1-score比较 单位:%Tab.2 Comparison of F1-score between BLMSN model and other models unit:%
3.2.2 定性结果与分析
为了更好地直观展示本文模型生成的视频摘要质量,以数据集TvSum 中的视频4 为例,绘制它们真实分数与预测分数如图11 所示,实线表示人工选择的真实分数,点线表示模型预测分数。从图11 可以看到本文方法预测得分与人工打分变化趋势基本一致,说明了方法具有可行性,但在第90 帧与第200 帧附近预测不够准确,说明方法还有提升空间。总的来说,本文方法与人工摘要之间具有明确的关联性,证明了该方法的有效性。
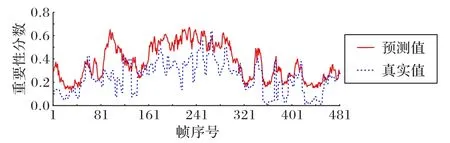
图11 视频4预测分数对比Fig.11 Comparison of prediction scores in video 4
3.2.3 效果预测
本文提出的BLMSN 模型可用于制作视频摘要,能向用户快速展示一个较长视频的整体内容。为了检验模型的泛化性能,本文选取数据集UCF-crime中第10个视频进行测试。
原始视频“Crime_10”时长约为2 min 12 s,描述了一伙人用车撞开防护进行偷盗的事件,提取到的关键镜头如图12 所示。

图12 本文方法提取视频“Crime_10”中的关键镜头Fig.12 Key shots extracted by the proposed method in vi deo“Crime_10”
原视频是监控摄像头下拍摄到的犯罪事件,通过视频摘要技术能够将数分钟的视频压缩至数十秒甚至数秒,同时不丢失关键信息。这也是将来打算更深一步研究的方向,将视频摘要技术同公安领域结合,使数百小时的监控视频缩短至几十分钟,帮助办案人员提高效率,快速锁定目标。
4 结语
本文提出一种基于改进的BiLSTM的视频摘要生成方法,该方法通过CNN 提取视频帧的深度特征,然后利用BiLSTM获得时序特征,将时序特征经由最大池化进行特征优化,有效降低了特征维度,突出关键特征,减少无关特征,同时减少了后续全连接层所需的参数数量,提升了运算速度,避免了过拟合问题。虽然模型预测分数基本与人工选择分数变化一致,但部分分数转折段的预测仍不够准确,导致最终F1-score 值较低,如何构建又快又准的视频摘要模型,同时跨场景应用时仍然能保持优异的效果是今后主要的努力方向。
猜你喜欢
计算机应用(2022年9期)2022-09-25
农业工程学报(2022年12期)2022-09-09
现代计算机(2022年4期)2022-04-24
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
导航定位与授时(2019年3期)2019-05-16
智能计算机与应用(2018年2期)2018-05-23
软件导刊(2018年4期)2018-05-15
