
基于注意力机制的文本作者识别
2021-07-30 10:33江铭虎
计算机应用 2021年7期
张 洋,江铭虎
(清华大学人文学院,北京 100084)
0 引言
互联网时代,海量数据涌现,人们在享受信息服务的同时也饱受信息泛滥的困扰。作者识别技术可以准确而及时地识别不良信息,追踪垃圾信息的源头并阻止其传播,对于维护互联网生态健康具有重要的意义。作者识别,又称为作者身份识别(authorship identification)或者作者身份归属(authorship attribution),是自然语言处理(Natural Language Processing,NLP)领域里的一个重要分支。顾名思义,作者识别是识别文本作者的一类研究,它最初源自人们深入阅读的传统。作者识别的主要思路是将文本中隐含的作者无意识的写作习惯通过某些可以量化的特征表现出来,进而凸显作品的文体学特征或写作风格,以此确定匿名文本的作者[1]。从其发展历程来看,最初的研究是确定散轶文献的来源或作者,后面又逐渐发展至确定某一文学作品、法律文档或者电子文本的作者。根据是否使用数学方法量化文本风格,可以将作者识别分为传统作者识别和现代作者识别[2]。传统作者识别多基于文学和语言学的相关知识,依靠专家的经验进行判断;而现代作者识别则基于数学建模,依靠模型的结果确定作者归属。
本文主要研究基于中文文本的现代作者识别,通常可以分为提取文本特征和建立预测作者的数学模型两个步骤。这两个步骤分别被研究者称为作者风格分析(authorship style analysis)和作者身份建模(authorship modeling)。具体来说,作者风格分析是提取能够量化作者写作风格的文本特征的过程,比如字符特征、词汇特征、句法特征、语义特征等。通常需要设计一个特征提取器,生成相应的特征向量,以便于在接下来的步骤中进行建模。而作者身份建模则是根据提取的这些文本特征或者已生成的特征向量建立相应的模型,进而预测文本作者的过程。有时,作者身份建模也指由文本建立预测作者归属模型的过程。通过构建特征集进行作者识别的研究都可以用以上这两个步骤来描述。相比之下,极少数不需要借助特征集识别作者的研究则缺少第一个步骤。此类研究通常直接利用原始文档进行建模,而无需额外的特征提取,比如基于压缩方法的作者识别[3]等。
从大的层面来分,作者身份建模主要分为基于轮廓的建模(profile-based modeling)和基于实例的建模(instance-based modeling)[4]。二者都是由训练文本构建作者归属模型的过程,它们的主要区别在于:在基于轮廓的建模中,每个作者的所有文本都会被累计处理。换句话说,特定作者的所有文本会被整合成一个大文档,根据这个大文档提取相应表示,构建该作者的轮廓。这样,每个测试文本只需跟特定作者的轮廓比较一次就能确定与该作者的相似程度。而在基于实例的建模中,每位作者的所有文本都会被单独处理。换句话说,每个文本都有自己的表示。在这种情况下,每个测试文本需要跟特定作者的所有文本进行比较才能确定与该作者的相似程度。因此,当语料相对比较充足,每个作者都有足够数量的训练文本时,通常采用基于实例的建模;反之,当仅能获得有限数量的训练文本时,常常采用基于轮廓的建模[5]。基于实例的建模通常会与机器学习算法搭配使用,因此研究者一般认为其准确率要高于基于轮廓的建模方法[6]。
1 相关研究
作者识别领域里常见的建模主要有基于概率的建模、基于向量空间的建模和基于相似度的建模等,下面简要叙述这几类建模以及它们通常搭配的分类方法。
1.1 基于概率的建模
基于概率的建模通过引入概率模型来描述不同随机变量之间的数学关系。作者识别领域最早的基于概率的建模是Mosteller 等[7]利用贝叶斯方法研究联邦党人文集的作者归属问题。贝叶斯方法是一种建立在条件概率基础上的概率模型。具体来说,贝叶斯方法是在类条件概率密度和先验概率已知的情况下,通过贝叶斯公式比较样本属于两类的后验概率,将类别决策为后验概率大的一类,这样可以使总体错误率最小[8]。
有些研究者利用贝叶斯方法进行相关的研究。Zhao等[9]选择功能词和词性(Part-of-Speech,POS)标签作为特征,使用朴素贝叶斯方法识别作者;Raghavan 等[10]为每个作者构建概率上下文无关文法,并使用该文法作为分类的语言模型进行作者归属;Boutwell[11]使用朴素贝叶斯分类器,选择基于字符的n元组合(n-gram)的特征构建作者集统计模型识别短信的作 者;Savoy[12]利用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)把每个文档建模为主题分布的混合,每个主题指定单词的分布,根据文本距离确定相应的作者归属。
1.2 基于向量空间的建模
基于向量空间的建模把对文本内容的处理简化为向量空间中的向量运算,同时以向量空间中向量的相似度衡量文本中语义的相似度,简洁直观。作者识别领域的向量空间模型通常搭配支持向量机(Support Vector Machine,SVM)和神经网络等机器学习方法,本部分着重介绍这两种方法。
1.2.1 支持向量机
SVM 是作者识别领域常见的一种方法,它的基本原理是找到一个最优的分类面,使得两类中距离这个分类面最近的点和分类面之间的距离最大[13]。SVM 的复杂度与样本维数无关,学习效率和准确率较高,适合应用于高维文体特征数据集,因此受到很多研究者的青睐。Diederich 等[14]利用SVM 研究德国报纸文本的作者识别;Schwartz 等[15]利用SVM 研究微小信息在推特语料上的作者识别;Mikros 等[16]结合多级ngram,利用多类SVM 研究希腊推文中的作者识别;Posadas-Duran 等[17]选择句法关系标签、POS 标签以及词根的句法ngram等特征刻画文本风格,并利用SVM识别相关作者。
1.2.2 神经网络
神经网络是简单处理元件、单元或节点的互连系统,网络的处理能力体现在通过适应或学习一组训练模式的过程中获得的单元间连接强度或权重上[18]。因此,从本质上来说,神经网络是模拟动物脑中神经元网络的简化模型。从理论上来说,神经网络算法能够逼近任意函数,具有很强的非线性映射,以及分布存储、并行处理、自学习、自组织等优点[19]。所以,针对一些实际情况复杂、背景知识不清楚、规则不明确的问题,神经网络算法具有很强的处理能力。
有些研究者利用神经网络研究作者身份识别。Bagnall[20]使用循环神经网络(Recurrent Neural Network,RNN)同时对几个作者的语言进行建模;Ruder 等[21]利用卷积神经网络(Convolutional Neural Network,CNN)处理特征级别信号,并对大规模文本进行快速预测;Shrestha 等[22]选择字符n-gram 作为特征,利用CNN 对推文进行作者识别;Jafariakinabad 等[23]使用句法循环神经网络从词性标签序列中学习句子的句法表示,同时利用CNN 和长短期记忆(Long Short-Term Memory,LSTM)网络研究句中词性标签的短期和长期依赖性。
1.3 基于相似度的建模
基于相似度的建模的主要思想是计算未知文本和所有文本之间的相似性度量,然后根据相似程度估计最可能的作者[24]。这是分类任务中最直观的一种思路,该思路的代表算法是K-最近邻(K-Nearest Neighbor,KNN)算法。KNN 的基本原理为:根据某个距离度量找出训练样本中与测试样本最接近的k个样本,再根据它们中的大多数样本标签进行预测。因此,衡量样本相似程度的距离度量是KNN 或者其他基于相似度的分类方法的关键。KNN 不需要使用训练数据来执行分类,可以在测试阶段使用训练数据[25]。
有些研究者利用基于相似度的模型研究作者识别。Jankowska 等[26]选择通用n-gram 相异性度量作为距离度量参与网络测评竞赛,获得了较优的结果;Burrows[27]提出了Delta方法,该方法通过计算未知文本与语料库的Z 分数和Delta值,把文本分配给具有最低Delta 值的作者;Eder[28]使用基于KNN的Delta方法研究文本尺寸对作者归属的影响。
2 注意力机制
近年来,注意力机制(attention mechanism)被广泛应用在图像识别、机器翻译、语音识别等各种深度学习任务中。顾名思义,注意力机制是模仿人识别物体时的注意力焦点的数学模型。人在识别物体时,先通过视觉系统获得物体的图像信息,而后由大脑对这些信息进行加工和整理,最终分辨物体的类别。大脑在对这些信息进行分析时,会格外关注一些局部信息,而忽略或者部分忽略其他信息。这种机制就被称为注意力机制。深度学习中的注意力机制利用Encoder和Decoder模型有效地赋予不同模块不同的权重,从而使得整个模型具有更强的分辨能力。
本文采用基于注意力机制的深度神经网络进行作者识别,整个作者识别流程如图1 所示。原始文本经过降噪、分词、词性标注后提取其词性标签n元组合(POSn-gram)得到特征序列,特征序列经过Embedding 层转化成相应的向量,然后在池化层取平均,再经过Attention 层被赋予不同的权重,最后经过输出层得到分类结果。其中,Embedding 层、池化层、Attention层和输出层构成了深度神经网络。

图1 作者识别流程Fig.1 Flowchart of authorship identification
2.1 Embedding层
神经网络的第一层是Embedding 层,也叫输入层。它的输入是batch_size个POSn-gram 序列,这些序列以数字编号(索引)的形式呈现,并且每个序列含有seq_length个索引。Embedding层将每个索引映射成emb_dim维的向量,以便于刻画不同特征之间的相互关系。
2.2 池化层
神经网络的第二层是池化层,主要用来对样本特征进行叠加平均。由于一篇文档被转化为seq_length个索引,每个索引又被映射成emb_dim维的向量,较多的特征数量会不可避免地引入很多噪声。鉴于此,可以利用池化操作对样本特征进行分组平均,通过设置pool_size的值可以控制分组大小。假设一个句子平均有N个词,设置pool_size的值为N,意味着每N个词进行一次叠加平均。这样,池化操作在降低噪声的同时赋予神经网络快速阅读的能力——从逐词阅读变为逐句阅读。
2.3 Attention层
神经网络的第三层是Attention 层。池化层进行了特征的平均,这样能在很大程度上减小噪声的影响,避免过拟合,从而提高神经网络的准确率;然而处于不同位置的向量组合对分类的贡献不同,池化操作对此无能为力。因此本文引入注意力机制来给不同位置的向量组合分配不同的权重。注意力机制的示意图如图2所示。

图2 注意力机制示意图Fig.2 Schematic diagram of attention mechanism


Score 函数用于计算每个输入向量和查询向量之间的相关性。常见的Score函数有以下几种形式:


根据注意力权重可以计算原序列状态的权重均值,它等于注意力权重αts与隐藏层状态点乘后求和。原序列状态的权重均值也被称为上下文向量(context vector),计算公式为:

最终的注意力向量(attention vector)需要将上下文向量ct和目标序列的隐藏层状态ht连接后生成。Dense2是激活函数为tanh 的全连接神经网络,用来对拼接后的向量进行tanh 变换。注意力向量的计算公式为:

2.4 输出层
神经网络的第四层是输出层,用于最终的分类。本文直接采用激活函数为softmax 的全连接神经网络完成分类。输出层的输出是样本属于不同类别的概率:

本文没有采用快速文本分类(fastText)[29]中的层次softmax,因为对于具有10 位候选作者的作者识别任务,普通的softmax 即可完成快速而高效的分类。此外,式(5)也可以写成:

其中:N表示样本的个数;xn表示第n个样本归一化后的特征向量,或者也可以理解为第n个样本的特征序列经过Embedding 层生成的向量;yn为第n个样本对应的类别标签;权重矩阵A、B和C分别表示池化层对应的分组平均的权重矩阵、Attention 层对应的分配权重的权重矩阵以及输出层对应的使用已学习的表示正确预测标签的权重矩阵。
3 实验及分析
本文选取莫言、路遥、贾平凹等10 位作家的多部小说作品(共48.7 MB)作为语料进行研究。不同作者的语料规模如表1所示。

表1 作者语料规模表Tab.1 Scale table of author corpus
首先把同一位作家的多部作品进行合并,然后按照每个文档1 000字的长度进行分割。每位作家抽取1 000个文本进行实验,其中实验集、验证集和测试集的比例分别为:54%、6%和40%。作者的写作风格主要反映在其遣词造句的方式上,换句话说,作者排列词语、组织句子的方式在很大程度上决定了其写作风格。因此,本文选择POSn-gram 来进行作者识别。POSn-gram 在很大程度上反映了作者词语选用和搭配的方式,进而体现作者的写作风格。之前关于n-gram 的研究大多基于离散的特征,采用统计和机器学习模型相结合的分类方法,这些方法没有考虑特征之间的相互关系。本文采用连续n-gram特征,构建示例:
1)POS标签序列:pnvnfxdvrnux。
2)连续2-gram特征:pn、nv、vn、nf、fx、xd、dv、vr、rn、nu、ux。
3)连续3-gram 特征:pnv、nvn、vnf、nfx、fxd、xdv、dvr、vrn、rnu、nux。
每一篇文档都会被转换成这样一串POSn-gram 序列,然后又被转换成相应的数字序列,从而得到特征序列。特征序列会通过Embedding 层转化成相应的向量,然后参与训练和分类过程。由于POSn-gram 被转化成向量后,向量之间的距离可以反映这些POS 组合的相近程度,因此这样的n-gram 特征被称为连续特征[30]。普通n-gram特征可以表征作者词性搭配的频繁程度,但却无法表征语序信息;而连续n-gram不仅可以充分表征语序信息,还能通过向量之间的距离体现不同词性搭配之间的关系。换句话说,本文所采用的连续n-gram 特征同时结合了n-gram 特征和连续表示的优点,它既可以反映作者遣词造句的方式,又能够捕捉到不同词性搭配的差别。
本文实验以文档为单位进行训练,文档中的词汇和标点符号均用POS 标签的形式进行呈现。为了更好地训练模型,使用网格搜索来确定初始化向量维度、小批量大小、周期数、学习率等参数的最优组合。最终设置初始化向量维度为100,小批量大小为30,周期数为20,学习率为0.001。为了确定何种POSn-gram 更能体现作者的写作风格,令n取1~5。特别地,当n=1时,意味着以单独的词性标签作为分类特征。分别使用文本卷积神经网络(Text Convolutional Neural Network,TextCNN)、文本循环神经网络(Text Recurrent Neural Network,TextRNN)、LSTM、fastText 和本文模型对连续的POSn-gram 特征进行训练和分类。表2 展示了5 种分类模型在不同n值下的实验结果,使用准确率进行评估。
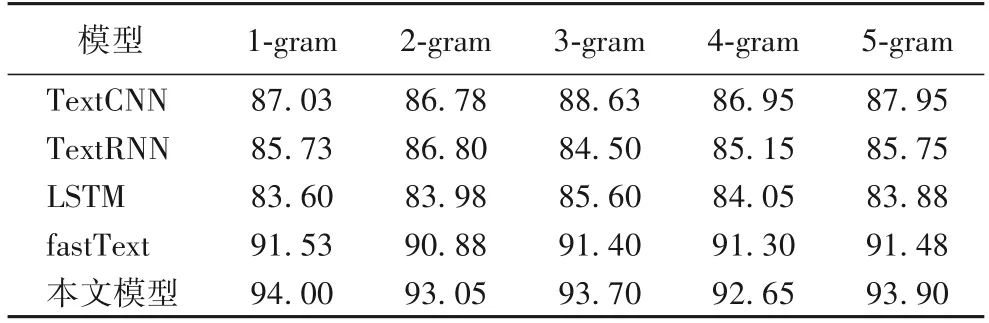
表2 不同模型的准确率对 单位:%Tab.2 Comparison of accuracy of different models unit:%
从表2 中可以看出,不同模型的预测准确率从低到高排序依次为:LSTM、TextRNN、TextCNN、fastText和本文模型。换句话说,针对不同的POSn-gram特征,本文提出的基于注意力机制的识别模型均获得了最高的准确率。对于同一模型,不同n值对应的准确率差别不大,这说明对于采用连续POSn-gram特征进行中文小说作者识别的研究而言,n值的贡献远小于分类器对作者风格的捕捉。可以换一个角度进行理解,连续POSn-gram特征已经涵盖了文档的全部序列信息和词语搭配信息,此时n在1~5 变化,并没有带来信息结构的变化。在这种情况下,分类器捕捉特征关联的能力主要取决于模型的训练,而并非初始特征组合的建构。
本文的基于注意力机制的神经网络分为输入层、池化层、Attention 层和输出层四层结构。如果进行消融实验,去掉Attention 层,则模型只剩下输入层、池化层和输出层三层结构。这是一个类似fastText的网络结构,区别在于该网络的输出层使用了普通的softmax,而fastText的输出层采用的是层次softmax。这个差异仅会对程序的运行时间产生影响,而不会影响作者识别的准确率,因此可以直接借用fastText的实验数据进行对比分析。与fastText的结果进行对比可以发现,加入Attention 层后,不同POSn-gram 特征对应的准确率平均提高了2.14 个百分点。这是由于Attention 机制给处于不同位置的向量组合分配了不同的权重,进而使得整个网络能够捕捉文档不同部分所反映出的作者风格,从而提高了准确率。因此可以得出这样的结论:注意力机制能够有效提高中文小说作者识别的准确率。
4 结语
本文提出一种基于注意力机制的神经网络,该网络通过在fastText 的池化层和输出层之间添加Attention 层得到。借助注意力机制,该网络能够捕捉文档不同部分所体现的作者风格,同时又保留了fastText快速而高效的特点。在结合连续POSn-gram 特征进行的10 位作者识别实验中,本文模型的准确率超过了TextCNN、TextRNN、LSTM 和fastText 这四种常见模型,比不添加注意力机制的fastText 平均高出2.14 个百分点。实验结果表明,神经网络中引入注意力机制能够有效提高中文小说作者识别的准确率。以后可以在以下几个方面继续改进原有工作:
1)尝试利用其他文本特征搭配注意力机制神经网络进行研究;
2)分析影响注意力网络的因素,例如文档长度、嵌入维度等;
3)改进注意力网络模型,比如由基于词语的Attention 改为基于句子的Attention。
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
电脑爱好者(2021年9期)2021-05-12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
电脑爱好者(2017年7期)2017-05-06
