
基于多尺度加权特征融合网络的地铁行人目标检测算法
2021-07-29 03:36:32董小伟曲洪斌高国飞陈明钿
电子与信息学报 2021年7期
董小伟 韩 悦* 张 正 曲洪斌 高国飞 陈明钿 李 博
①(北方工业大学信息学院 北京 100144)
②(中国石油管道局工程有限公司国际事业部 北京 065000)
③(北京城建设计发展集团股份有限公司城市轨道交通绿色与安全建造技术国家工程实验室 北京 100037)
1 引言
近年来,公共安全已成为热点问题被社会各界高度关注,城市的各个角落均安装了较为密集的监控装置,确保市民的出行安全。地铁交通受外界环境干扰小,行车速度稳定,是市民主要的出行方式之一,但地铁多建设于地下,环境复杂具有特殊性。当发生突发事件时,人员疏散和救援困难,极易发生踩踏事故。因此需要更精准的行人检测技术,对地铁中的复杂环境进行实时监控,避免群体突发性事件,确保市民安全。随着深度学习的发展,行人检测任务已经取得了很大的进步,但地铁中由于摄像头架设角度高、人流量大且不断运动,因此拍摄行人目标小、遮挡等问题极大地影响了检测结果。
早期目标检测方法大多基于手工特征,在底层特征中构建复杂模型提升精度,但人工提取的特征对于复杂场景而言鲁棒性不足。随着卷积神经网络(Convolutional Neural Network, CNN)、区域建议神经网络 (Region-CNN, R-CNN)[1]等深度学习模型的提出,以卷积网络为代表的目标检测方法迎来了前所未有的飞速发展,卷积神经网络从原始像素中学习高级语义特征,对背景噪声中具有复杂姿势的行人目标具有更强的识别力。目前主流的目标检测算法主要分为基于区域的两阶段算法,如Ren等人[2]提出结合目标候选框的检测模型更快速区域卷积网络(Faster Region-CNN, Faster-RCNN),设计了候选区域提取网络 (Region Proposal Network,RPN),提高了候选框提取质量。另一种是基于回归的单阶段目标检测算法如只需看一次网络(You Only Look Once, YOLO)[3]、单镜头多核检测器(Single Shot multibox Detector, SSD)[4],这类算法只经过一次前馈网络,因此检测速度更快,实时性更强。2016年Liu等人[4]提出了SSD方法,结合多尺度的概念在6个不同特征尺度上进行预测且设定了多种尺度的检测框,设计了不同尺寸不同长宽比的默认框,其采用全卷积网络进行连接,通过多个卷积层的信息来检测不同尺寸的目标。SSD算法虽然检测精度高、速度快,但是它仅将含有较少语义信息的底层特征图用于小目标检测,比如在以VGG16作为主干网络的检测模型中所选用的最低卷积层是Conv4,这样一些具有更低级别的信息层就被忽略掉了,包含的特征信息少,因此对于小中目标的检测效果不佳。针对这一问题,特征金字塔网络 (Feature Pyramid Networks, FPN)[5]设计了一种自顶向下的连接结构,同时利用低层特征的高分辨率以及高层特征的语义信息,通过对特征层的融合得到最终的输出结果。
本文结合FPN[5]的特征融合思想构建了适用于地铁车站的行人头肩检测网络,在原来的SSD网络的基础上增加多尺度加权特征融合模块,充分利用低层网络信息提高对于小目标的检测性能。同时,针对地铁行人数据中小目标样本数量少、分布不均衡的特点,本文提出了一种针对小目标数据的过采样增强算法,有效扩充了小目标样本数量,增加了小目标的训练权重。结合以上两种策略,并通过大量试验验证,本文提出多尺度加权特征融合网络(Multi-scale Weighted Feature fusion Single Shot multibox Detector, MWFSSD),在保证速度的前提下,有效提高了小目标的检测精度,提升了整体模型的检测性能。
2 多尺度特征加权融合模型
2.1 SSD网络
SSD模型是采用VGG为特征提取网络的端到端卷积网络,采用多尺度方法进行目标检测,在保证准确率的同时,可以更快速高效地完成实时检测任务,图1是SSD网络流程图。原始SSD模型在进行地铁行人头肩目标检测时出现以下问题:大量小尺寸目标难以识别;一些背景区域如人像海报等被误识成目标对象;目标的重复识别问题。针对以上问题,本文改进了SSD模型,将相互独立的特征层进行特征融合,充分利用上下文信息[6]。
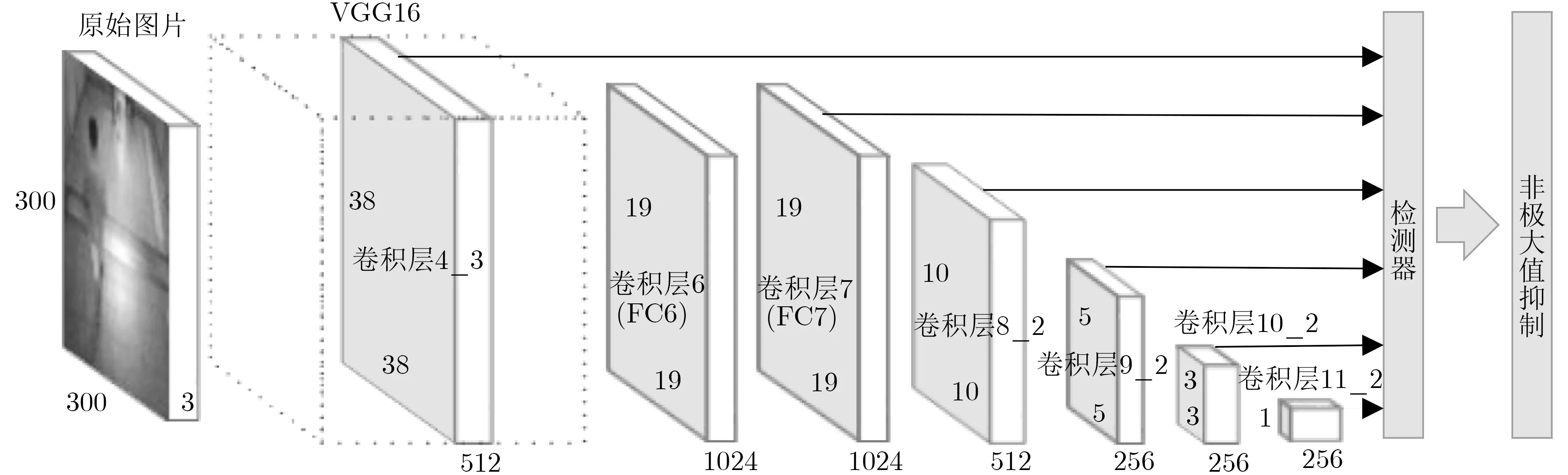
图1 SSD网络检测流程
2.2 多尺度加权特征融合网络MWFSSD
SSD目标检测算法经过多个下采样层来提取特征,而每经过一次下采样,网络的分辨率就会被压缩,从而损失不同分辨率的特征图信息,这样使得网络在最后很难提取到针对小目标的特征,另外,每个特征图对小目标的贡献程度不同,网络浅层提取目标边缘和纹理等细节特征,网络深层提取物体轮廓的特征。根据FPN,浅层特征图对小目标检测更有利,因此要想提高小目标检测精度就要增加底层特征信息,针对这一情况,本文改进了特征提取网络,选取VGG16的4个不同尺度的特征层分配权重进行加权融合处理,使每个特征图都能融合不同特征尺度的信息[7,8]。特征融合的结果由式(1)得到

其中,xi是用于融合的原始特征层,wi为每一层特征图的权重,σi为激活函数,i代表4个不同的特征层。
本文在VGG16网络中选择conv3_3, conv4_3,fc_7和conv7_2作为特征提取层;在融合之前每一个原始特征层都需要经过一个类似于激活函数的变换函数σi,对特征图的尺寸进行统一,使用1×1的卷积核来降低输入通道,FC7和Conv7_2使用线性插值的方法,将所有特征图转换成相同尺寸(38×38×256)[9]。最终为每一层特征图分配权重wi后经过Θf融合函数进行Concat操作[10],为保证特征数据尺度一致性,对不同尺度特征进行归一化处理,添加了批标准化层 (Batch Normalization,BN),其作用是在网络训练时,使得每一层的输入保持相同分布,防止过拟合,简化调参过程,以提高收敛速度。最后,将处理后的特征图送入SSD网络中,更好地提取出小目标的位置及类别信息[11–16]。多尺度加权特征融合网络原理图如图2所示。
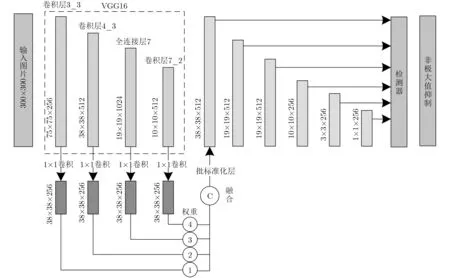
图2 MWFSSD检测流程图
3 实验结果分析
3.1 实验数据及其预处理
本实验的硬件配置采用Intel E5-2603 v4处理器,NVIDIA Titan XP显卡,软件环境是Ubuntu16.04,Python3.7和TensorFlow深度学习框架。
本文实验所用的地铁行人数据集采集自北京地铁主要换乘站,共43954个头肩样本以及3933个难分样本,包含了地铁中的很多场景如车站、出入口、上下扶梯等,并且涵盖了地铁运营各个时间段的客流情况。图3为训练集及测试集中部分样本图像。

图3 地铁行人样本库示例
地铁行人样本库中,行人目标在镜头的近处和远处尺寸差别很大,这就给准确检测带来了困难。COCO[17]数据集是2014年微软提出的专门用于计算机视觉领域较权威的数据集,其对于面积小于32×32的目标,就认为是小目标;对于中目标的定义是32×32<面积<96×96。图4展示了COCO数据集和地铁行人数据集目标尺寸的分布情况,其中横纵坐标分别代表目标框高和宽的尺寸,可以看出COCO数据集图4(a)中不同尺寸目标分布均匀,大中小目标都有,而我们的地铁行人数据集图4(b)目标尺寸集中在96×96以内的小、中尺寸目标,几乎不存在较大的目标,这就需要我们的模型对于小尺寸目标具有更强的检测性能。

图4 COCO数据集和地铁行人数据集目标尺寸分布
小目标在地铁行人数据集中非常常见,而它们在不同图像中的分布是不可预测的。在整个数据集中,包含小目标的图片数量极少,然而却存在个别图像中几乎所有的目标都是小目标。这种数据分布的不平衡严重妨碍了训练进程。小目标数量少且尺寸相对较小,因此在训练中对于网络的优化作用较小,这种不平衡的网络参数优化导致检测性能不佳。根据这一发现,本文提出了一种数据增强的方法,使用过采样方法构造并扩充小目标样本,将小目标占比低的图像尺寸缩小到原来的1/4,并将4张缩小后的图像拼接成与原图像尺寸相同的图片送入网络,从而增加小目标数据的权重。
图5是小目标过采样增强算法的原理图。首先统计出地铁行人数据集中每幅图片中的小目标(尺寸小于64×64)占总目标的比例Rs,若比例小于阈值τ,则说明小目标占比小,应该增加小目标的数量。因此,本文设计了小目标增强预处理模块,将这些图片做拼接处理,并添加新的目标框节点坐标到新的数据文件中最终与原图片一起送入设计好的检测网络进行训练,指导网络更新[18]。假设原始图片高和宽分别为h和w,则拼接后的图片高和宽变成2h,2w。设原始图片中目标位置为(Xmin,Ymin,Xmax,Ymax)则该目标扩充后的4个新目标坐标分别为
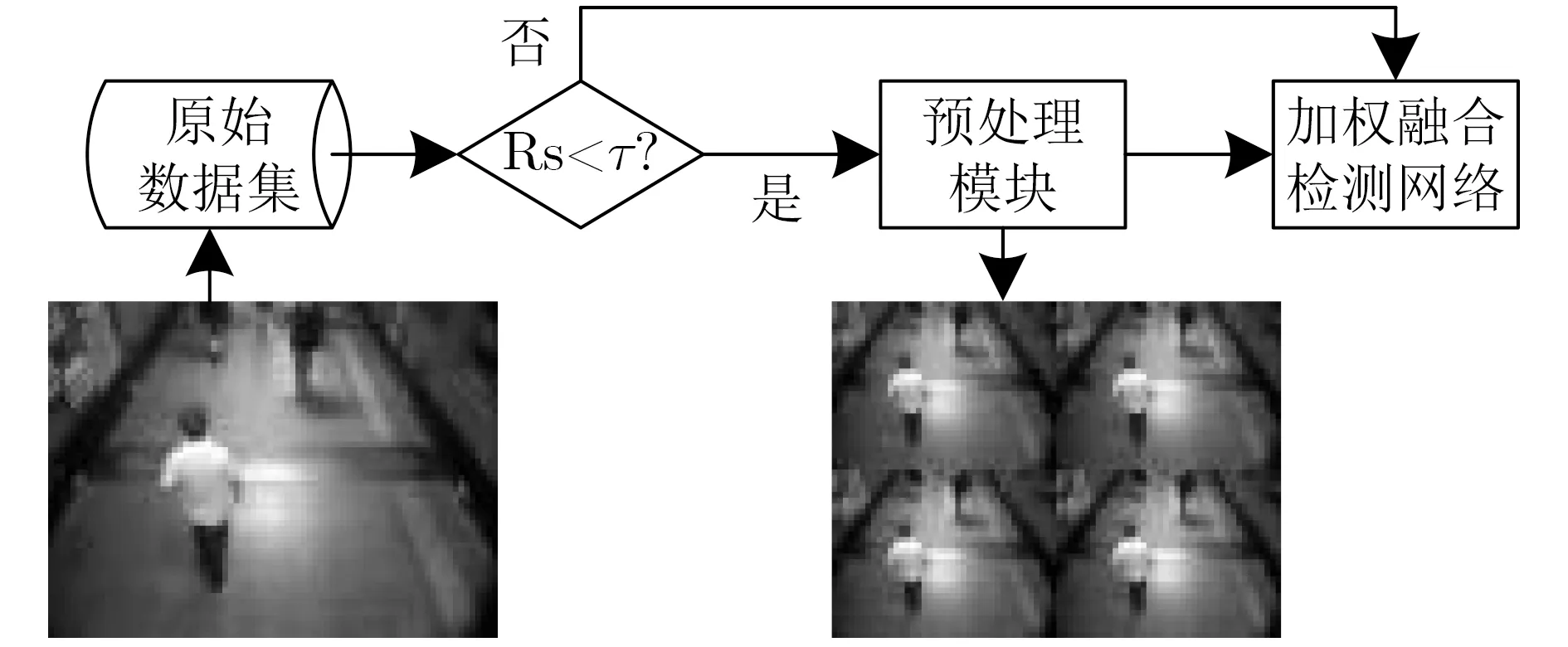
图5 小目标过采样增强算法
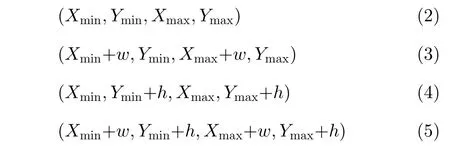
3.2 模型的评价指标
本文采用准确率(P)、召回率(R)、平均精度均值(mean Average Precision, mAP)、每秒帧率(frame per second, fps)对算法进行性能评价。其中,平均精度均值mAP定义为所有类别检测的平均准确度,通常用mAP作为评估算法精度的最终指标。目标被成功检测出认定为正样本,未被成功检测出则认为是负样本。IoU阈值设为0.5,大于0.5则认为是检测正确,记为T;否则记为F。实验结果中,IoU小于等于0.5的记为FP, IoU大于0.5的记为TP。
准确率计算公式为

召回率计算公式为

除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这在地铁行人检测应用中极其重要。评估速度的常用指标是每秒帧率,即每秒内可以处理的图片数量。在实际应用中,每秒帧数不能低于20 fps,否则会影响录像视频的流畅度[19]。
模型的时间复杂度可以用浮点运算次数(floating-point operations)即FLOPS衡量。单个卷积层的时间复杂度计算公式如式(11)所示

最终,经过计算,MWFSSD相对于SSD网络而言,时间复杂度增加了31.31GFLOPs,没有大幅增加网络的时间开销。
3.3 特征层选择结果
本文实验均基于地铁行人头肩数据集,选用VGG16网络的Conv3_3(Conv3), Conv4_3(Conv4), FC7(Conv7), Conv7_2(Conv8), 4层特征层进行不同方式融合,与原始SSD网络进行对比,得到不同特征层融合后的模型及其模型精度mAP的对比实验结果。部分实验结果如表1所示。
由表1可知,当由Conv3, Conv4, Conv7,Conv8 4层特征图一起融合后的模型精度可以达到86.48,比原始SSD高出2.58,说明融合底层特征的信息对模型精度的提升有很大影响。
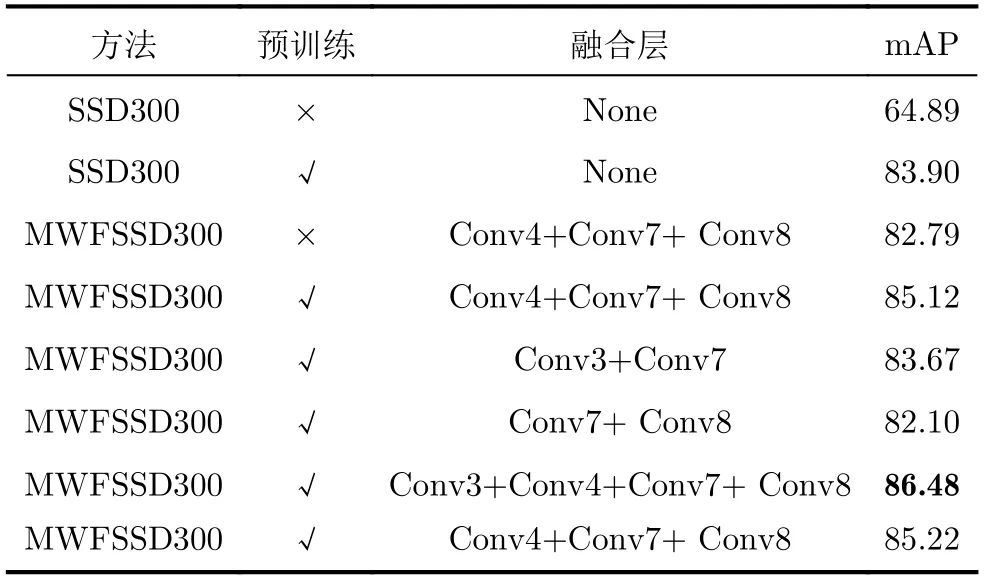
表1 特征层融合精度结果比较
3.4 本文网络MWFSSD实验结果
本文在Conv3+Conv4+Conv7+Conv8的融合模型基础上,分别为4个特征层分配不同权重w1,w2, w3, w4再进行融合,并且w1+w2+w3+w4=1,融合公式如式(1)。
本文做了大量实验,验证了不同权重分配方式的检测精度。表2记录了本文选择的分配权重与无权重进行比较的检测结果。结果证明,浅层特征更有利于中、小目标检测,加入权重进行融合比不加权重融合的模型mAP提高了1.44,有效提高了模型精度。
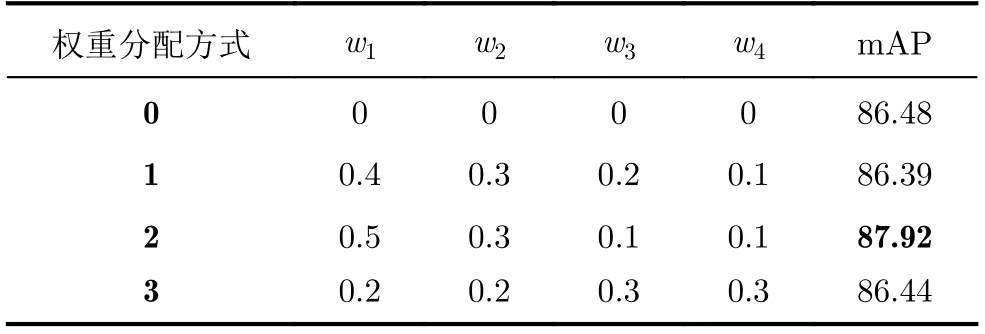
表2 不同权重分配的检测结果
最终,结合小目标过采样增强算法与多尺度特征加权融合网络进行实验验证,表3记录了本文模型与主流目标检测模型SSD, Faster-RCNN, YoloV3在精度和速度上的对比结果。本文所提模型在检测精度上较原SSD模型提升了5.82,相较于其他模型也有不同程度的提高,速度上SSD每秒检测43帧图像,本文模型MWFSSD每秒检测32帧图像,速度有轻微下降是因为模型深度有所增加,但与精度较高的Faster-RCNN相比,速度上有明显优势,并且仍能满足实时性的要求。图6是部分SSD与MWFSSD检测结果对比图,可以看出本文方法有效改善了地铁行人检测中漏检、错检的问题。实验证明,我们的方法在提高精度的同时,可以满足实时性需求[20,21]。
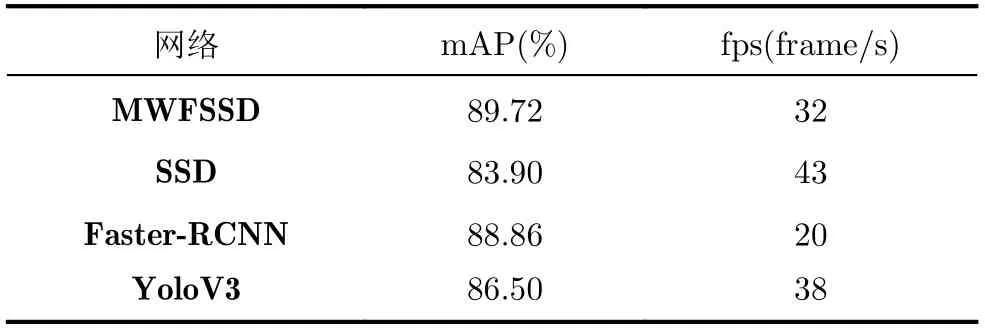
表3 MWFSSD与主流检测方法检测结果对比

图6 SSD与MWFSSD检测效果对比图
4 结论
本文针对地铁行人检测中小尺寸目标数量不足、分布不均衡的特点提出了针对小目标数据的过采样增强算法,根据尺度比例增加小目标的利用率。同时,针对地铁行人目标小的问题,提出了多尺度加权融合算法,并进行大量实验确定最优参数,提高对小目标的检测精度。结果显示,本文所提地铁行人多尺度加权特征融合算法在保证实时性检测的同时,检测精度mAP达到89.72%,相比原始SSD算法提升了5.82%,能够更准确地实时监测地铁中的客流量。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
扬子江(2019年1期)2019-03-08 02:52:34
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
河南科技(2014年23期)2014-02-27 14:19:15
