
大伙房水利水电工程汛期分期评价
2021-07-29 10:27:40张文菲
水电站机电技术 2021年7期
张文菲
(辽宁省抚顺市新宾满族自治县水务局,辽宁 抚顺 113200)
1 研究区概况
大伙房水库地处辽河流域东辽河水系浑河干流上。工程于1954年动工,1958年竣工并投入使用,总库容22.68亿m3,水库坝址以上控制流域面积5 437 km2,河道长度169 km,是一座防洪、供水、灌溉、发电、养鱼等综合利用、多年调节的大型水利枢纽工程。
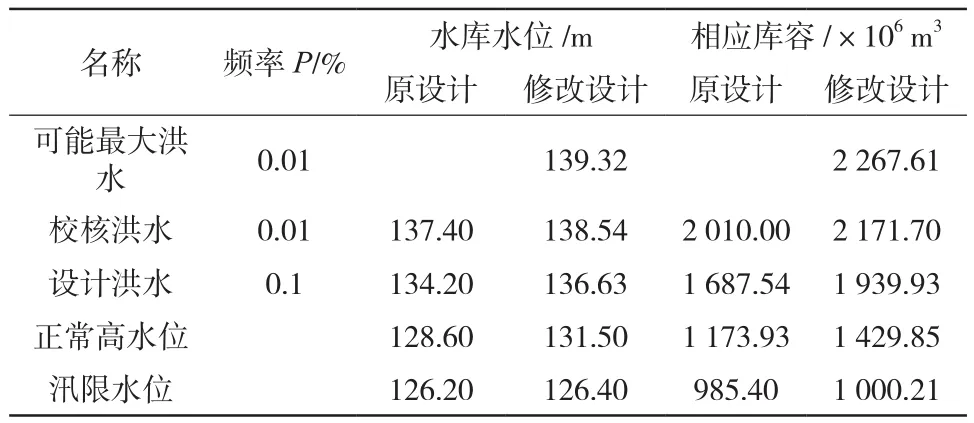
表1 大伙房水库控制运用有关特征值
2 研究方法
2.1 水库汛期分期的定量分析方法
Fisher最优分割法是对有序样本进行分类的一种统计方法,该方法用来分类的依据是样本的离差平方和,分割的原则是:使得各段(类)内部样本之间差异最小,而各段(类)之间的差异最大。对于有序样本序列,首先定义类的直径,一般以类内样本的离差平方和表示。若将n个样本分成 k 类,则以所有类的直径之和定义极小化函数P(n,k)。当分类数k固定时,P(n, k)越小,分类就越合理,其最小值表示为e[P(n, k)],对应的分类方式为最优类分割。建立e[P(n, k)]—k相关曲线,取曲线开始趋向平缓处的k值为最优分类数[1]。
2.2 基于 BP 神经网络模型的汛期分期合理性评价
单指标分期法在汛期分期中仅考虑单个影响因子,从而使其在实用性上存在一定的局限性;多指标分期法虽然考虑了多个影响因子,但在进行分期结果的判断时往往依据经验,从而使其结果的合理性存在一定的主观性。
步骤1:为消除不同量纲影响,便于训练样本,对样本数据的输入值和输出值用式子表示[2].

步骤2:置 k=1,把样本数据对(xk,h,dk,j)提供给网络,(h=1,2,…,n;j=1,2,…,n)。
步骤3:计算隐层各节点的输入xi、输出yi(i=1,2,…,n)。

步骤4:计算输出层各节点的输入xj、输出yj(j=1,2,…,n)
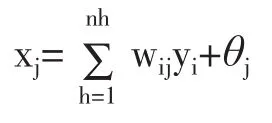

步骤5:计算输出层各节点所收到的总输入变化时单样本点误差Ek的变化率。
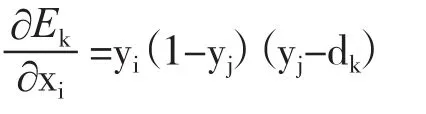
步骤6:计算隐层各节点所收到的总输入变化时单样本点误差的变化率。

步骤 7:置 k=k+1,取学习模式对 (xk,h,dk,j)提供给网络,转步骤3,直至全部nk个模式对训练完毕。
步骤8:重复步骤2至步骤8,直至网络全局误差函数。
2.3 汛期隶属度常用计算模型
(1)台阶型
该方法承认在汛期的不同阶段暴雨洪水的季节性差异,将各期的汛期隶属度按照台阶式来计算[3]。从图1可以看出各个汛期之间缺乏必要的过渡,在实际中难以操作。在许多水库中,前后汛期汛限水位并不是通过分期设计洪水计算得到,只是一个经验值。
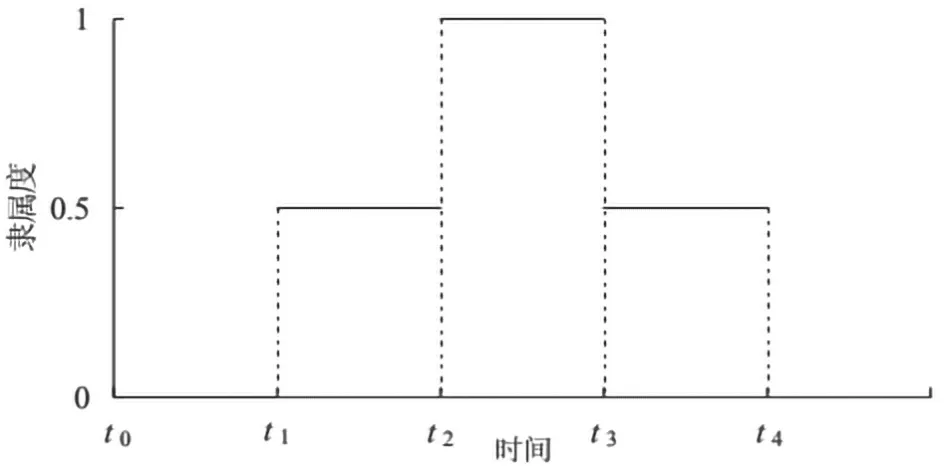
图1 台阶型隶属度示意图
(2)斜线型
该方法考虑到季节转换的渐进性,因此在前汛期到主汛期、主汛期到后汛期的隶属度上采用斜线过渡,从应用效果上优于台阶型方法[4-6]。其汛期隶属度如图2所示。

图2 斜线型隶属度示意图
3 研究结果
3.1 水库最大洪峰流量
大伙房水库在1951年至2006年期间,最大洪水发生在1995 年7月30日,洪峰流量为10 700 m3/s,年最大洪峰流量多年平均值约为1 786 m3/s。点绘出大伙房水库年最大洪峰流量出现时间分布图,见图3。结果显示6~10月中最大洪峰呈明显的单峰形状。

图3 大伙房水库年最大洪峰流量散布图
可知,旬平均降水量和3种典型历时最大降水量也主要集中在7月下旬至8月上旬,8月中旬以后,旬平均降水量和典型历时最大降水量开始逐渐减小;从年最大洪峰流量的时程分布可以看出,洪峰流量在7月下旬至8月中旬出现的次数占整个洪峰系列的70%,7月中旬前和8月中旬后,洪峰流量的外包线开始明显下降,表明8月中旬后再出现较大洪水过程的几率较小。大伙房水库主汛期开始于7月中旬,结束于8月中旬。

图4 大伙房水库流域汛期各旬暴雨日数分布图

图5 大伙房水库流域汛期各旬平均降水量分布图
3.2 基于 Fisher 最优分割法的大伙房汛期分期
根据Fisher最优分割法的计算步骤,计算出误差函数e[P(n,k)],其结果见表2。
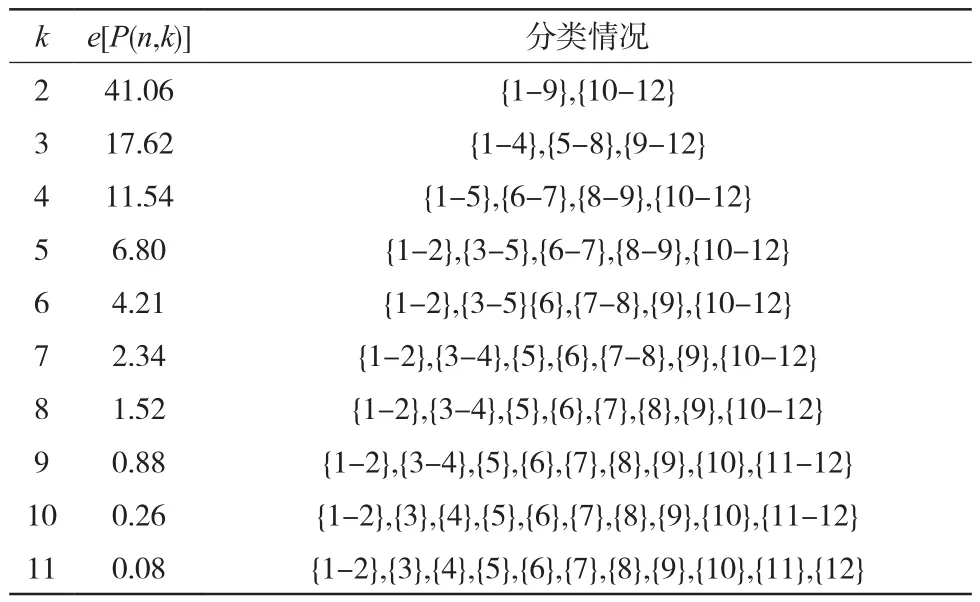
表2 分类情况表
绘制误差函数e[P(n,k)]随分类数k的变化曲线,如图6所示。从图中可以看出,最小误差函数e[P(n,k)]值单调递减,曲线在k值为3时出现拐点,k值在超过3之后,再增大时误差函数值减小缓慢,所以分为3类较好。对分类结果进行检验,根据自由度f1=k-1=2,f2=n-k=9和给定的显著水平α=0.05, 查表求得Fα=4.256,计算F=12.356>Fα,通过F检验。大伙房水库汛期分为3期,前汛期、主汛期、后汛期。
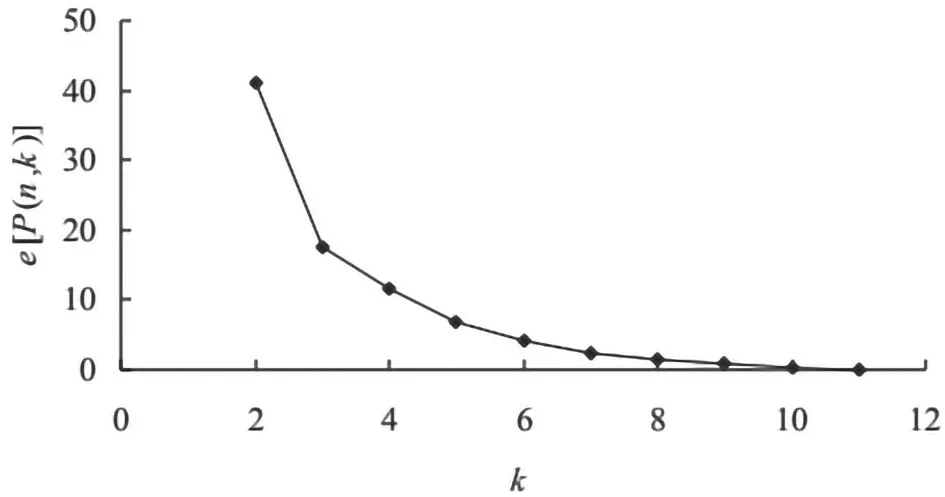
图6 e[P(n,k)]—k关系曲线图
3.3 大伙房水库汛期分期的合理性评价
通过3.2小节对大伙房水库流域暴雨洪水时程规律的分析,总结得出大伙房水库控制流域汛期分期的6个特征性指标:暴雨日数、旬降水量、旬最大1 d降水量、旬最大3 d降水量、旬最大7 d降水量、年最大洪峰出现次数,具体数值见表3。
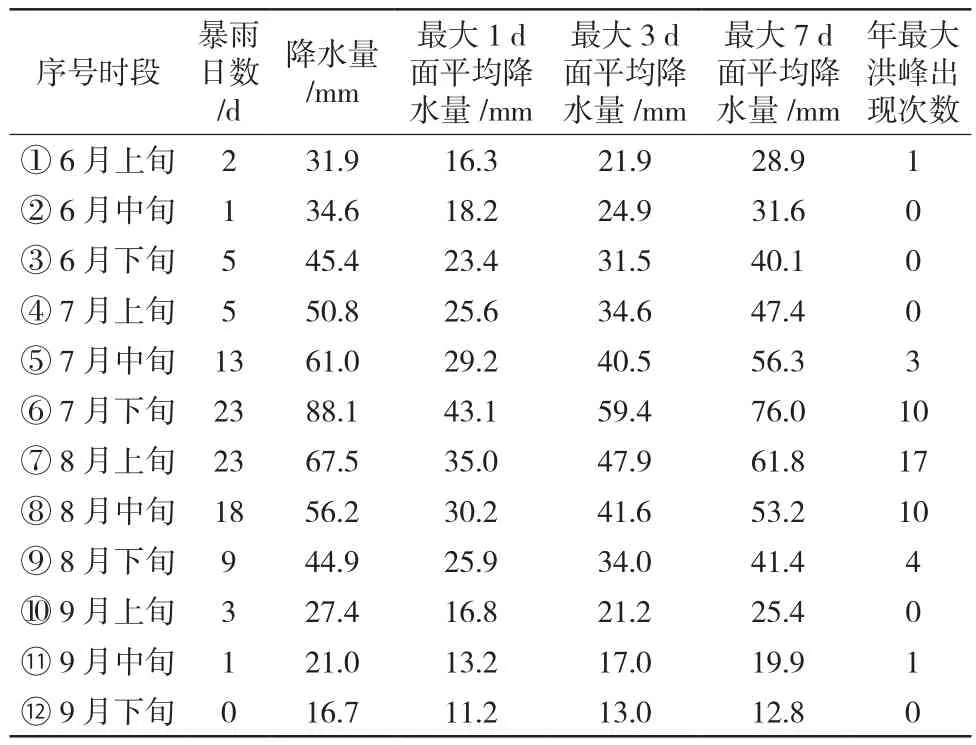
表3 大伙房水库汛期分期指标特征值
4 结论
通过综合分析大伙房水库控制流域暴雨洪水在时程分布上的变化规律,采用Fisher最优分割法对大伙房水库控制流域汛期进行了划分,并提出采用BP神经网络对汛期分期结果进行评价,为水库兴利与实现洪水资源化提供了技术支持。
猜你喜欢
《学习方法报》地理商务星球七年级(2023年13期)2023-10-11 02:44:46
启蒙(3-7岁)(2019年8期)2019-09-10 03:09:08
中华诗词(2018年12期)2018-03-25 13:46:36
江西农业(2018年23期)2018-02-11 07:26:59
水利规划与设计(2017年9期)2017-12-20 08:24:46
水利技术监督(2017年3期)2017-06-09 06:55:34
水利技术监督(2016年6期)2017-01-15 14:01:42
水科学与工程技术(2016年1期)2016-07-12 14:25:59
水利科技与经济(2016年10期)2016-04-26 08:40:26
水利科技与经济(2016年6期)2016-04-22 05:08:06
