
一种社交网络中朋友推荐算法的研究
2021-07-28 08:31陈暄
现代信息科技 2021年2期

摘 要:针对云计算环境下的社交网络中朋友推荐中可能存在大量冗余,无效信息等缺点,提出了基于猴群算法的朋友社区推荐方案,该方案利用爬虫程序获得的新浪微博好友数据集,对用户所在的社区进行划分,并进一步使用猴群算法对社区中的朋友链接关系进行了划分。仿真实验中将该算法与基于用户综合相似度的推荐算法在查准率,查全率和F1指标方面进行对比,结果显示,文章提出的算法都展现出了较好的效果。
关键词:云计算;社交网络;朋友推荐
中图分类号:TP393.09;TP391.3 文献标识码:A 文章编号:2096-4706(2021)02-0093-03
Abstract:In view of the shortcomings of redundancy and invalid information in the recommendation of friends in social networks in cloud computing environment,a friend community recommendation scheme based on monkey algorithm is proposed. In this scheme,the users community is divided by using the data set of Sina Weibo friends obtained by crawler program,and the link relationship of friends in the community is further divided by using monkey algorithm. In the simulation experiment,the algorithm is compared with the recommendation algorithm based on user comprehensive similarity in terms of precision,recall and F1 index. The results show that the algorithm proposed in this paper shows good results.
Keywords:cloud computing;social network;friend recommendation
0 引 言
伴随着云计算、移动互联技术的不断发展,社交网络已经成了工作、生活中重要的组成部分。越来越多的人利用不同的社交软件建立属于自己的社交网络,而在社交網络中朋友是必不可少的重要组成部分,因此如何得到可靠的朋友成了社交网络研究中的一个重要的方向。其中,朋友推荐方案的设计,不同的学者从不同的方向进行了研究。文献[1]在朋友推荐方面提出了一种用户兴趣标签匹配的方案,其中心思想是通过Word2Vec对训练库中的关键词进行训练,通过获得的关键词的向量,获得一个词向量的空间,最后通过余弦相似度的算法得到关键词之间的相似度并进行验证,结果说明该方案具有非常好的可靠性;文献[2]提出了社交圈检测算法,进而定义用户间的社交圈相似性,并使用YouTube数据验证了该文假设,使用Facebook自我网络数据验证了社交圈检测方法的有效性;文献[3]提出了一个新的在线社交网络朋友推荐方法,为用户提供了既快速又准确的朋友推荐,结果显示能够显著增加在线社交网络朋友推荐的准确性;文献[4]则从图论的角度出发,使用基于混合图模型的随机游走算法,为用户提供个性化的朋友推荐,并通过参数的调节获得图中的网络权重,实验表明该算法能够提高在线社交网络朋友推荐的准确性;文献[5]在社交网络中提出了基于协同过滤的推荐方法,仿真结果表明该方法能够有效推断用户行为。
以上学者从不同的方向进行了研究,取得了一定的研究成果。本文提出了一种基于猴群算法的朋友社区推荐方案,该方案从朋友社区的角度出发,提高了朋友推荐的效率。仿真实验中,将本文算法具有较好的推荐效果。
1 社交网络概念
社交网络是一种新的基于互联网的网络结构,它通常是由结点和若干条边组成。这种网络结构表达了社交网络中的很多关联关系。通常使用结点表示一个用户或者一个团队,而关联关系代表了两个用户或者团体之间存在的某种关系。而社交网络中的结点会随着新结点的加入或者新的关联关系而发生变化。而通常所说的社交网络分析主要是使用一定的技术手段对网络进行分析,它能够根据用户的兴趣爱好不断形成新的关系,从而使得社交网络的规模逐渐变大。
2 猴群算法
猴群算法[6]是Zhao和Tang在2018年提出的一种仿生类智能优化算法,该算法主要模拟大自然中的猴群爬山的过程。该算法是一种简单而有效的随机性全局优化算法,具有参数少、寻优能力强、能有效解决复杂问题等优点,逐渐成为进化计算研究领域中的常用算法。
该算法通常分为3个部分:
(1)爬过程。所谓爬过程是指每只猴子个体在当前的可行解范围内通过逐步爬行进行迭代,从而不断寻找优化问题的目标函数值的过程,具体的过程为:
步骤1:随机生成向量ΔXi=(Δxi1,Δxi2,…,Δxin),i=1,2,…,M,分量Δxij以均等的概率取a,其中,j=1,2,…,n,a(a>0)为猴群每次爬的步长。
步骤2:计算,其中,j=1,2,…,n,a(a>0),向量fi′(Xi)=(fi1′(Xi),fi2′(Xi),…,fin′(Xi))为目标函数的所在位置的伪梯度。
步骤3:设Yi=Xi+a·sign(fin′(Xi)),其中,j=1,2,…,n,sign为符号函数
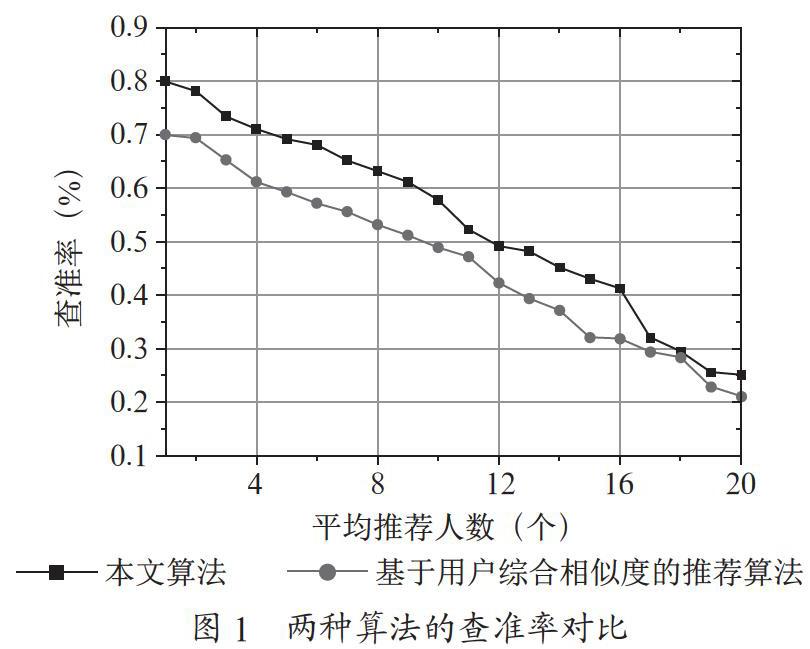
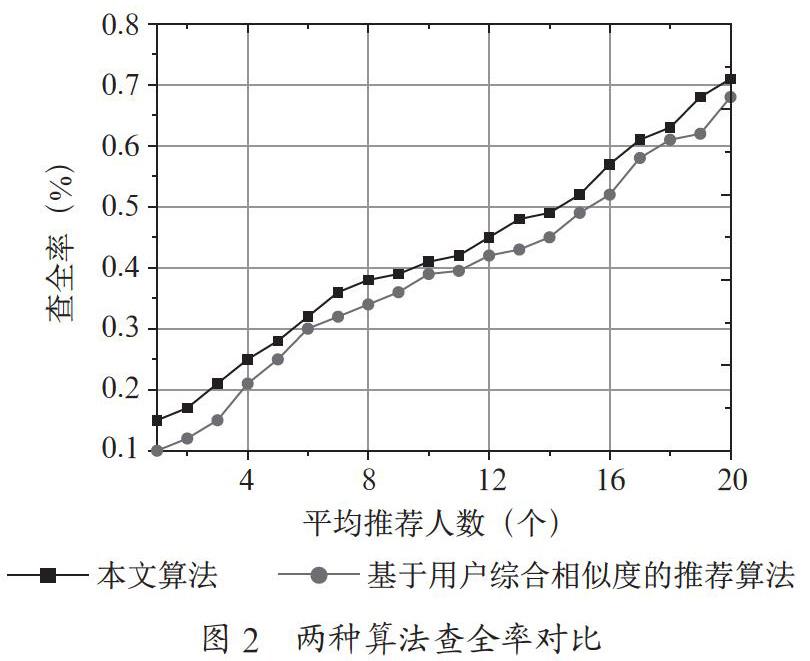
步骤4:当向量Yi=(yi1,yi2,…,yin)在[xmin,xmax]范围内,并且f(Yi) (2)望过程。望过程主要是指猴子个体在经历了爬的过程之后达到了在各自范围内的最高峰。通过望动作向各个方向进行观望,在各自的视野范围查看是否存在比当前位置所在山峰的更高的山峰。如果存在就转到更高的位置,否则就继续进行爬行,具体过程为: 步骤1:在猴子可以观察的范围内,随机产生实数范围为(xij-b,xij+b),随机产生实数yij,设定Yi=(yi1,yi2,…,yin),那么Y=(Y1,Y2,…,YM),其中,b为观察范围内的长度。 步骤2:当向量Yi=(yi1,yi2,…,yin)在变量范围内,并且f(Yi) (3)跳过程。跳过程是为了能够进入一个新的领域而进行的一个动作,即在当前的局部解内无法获得最优解,然后重新进行搜索,将当前所有猴子的各自位置向着每只猴子朝向重心位置的方向进入到新的领域进行搜索,具体的操作为: 步骤1:在猴子跳的限定区间[c,d]中生成一个实数θ。 3 基于改进的猴群算法的社区朋友推荐 随着社交网络范围的不断增大,有些无法在社交网络进行注册认识的好朋友,通过相同的兴趣,共同的爱好会构成潜在的关系,因此文章提出了一种改进的社区朋友推荐算法。首先,选用利用爬虫程序获得的新浪微博好友数据集,根据选定种子节点的好友列表中逐渐获得新用户的信息,但是对于活跃度低的用户进行剔除,有助于算法整体性能提高,保证了参与算法的有效性,其次对用户所在的社区进行划分,主要过程是能够根据不同用户之间存在的链接关系进行划分,在划分过程中引入仿生学的猴群算法,利用猴群具有的良好的算法性能,并在此基础上进行改进,将改进后的猴群算法与社区划分进行结合,同时将社区网络中的评价函数值与猴群算法的适应度进行一一对应。即每一个猴群算法中的个体都会对应社区网络中的一种划分的方法,这样最后获得猴群算法的最优解的个体就是最优社交的划分方案。将猴群算法中的每一个个体的适应度值与不同社区中的多用户进行所对应的,多用户分布在不同的社区中,然后得到目标用户所在的社区的用户相似度,而在社区网络中用户之间的不同的相似度代表了网络中的权重,因此用户之间的相似度则采用综合相似度进行计算。根据社交网络中生成的对应矩阵,用户的特征向量表明了用户与用户之间的链接关系,使用特征向量中的余弦相似度获得用户之间的链接信息关系的相似度,继而计算出每一个用户的属性向量,根据这种属性的余弦相似度得到不同用户的个人信息相似度数值,最后通过对于用户信息相似度进行综合排序,将相似度最高的用户推荐给好友。 4 仿真实验 为了进一步说明本文算法的效果,本文选择了硬件环境是CPU为i5,内存为4 GB DDR3,硬盘为1 TB,软件环境为Matlab,操作系统为Windows 10,用户数据库来自微博的数据用户作为研究对象。将本文算法与基于用户综合相似度的推荐算法在查准率,查全率和F1指标中三个指标作为参考进行对比。 4.1 查准率 查准率是指查看结果的准确程度。其值等于目标用户推荐出的正确好友数量与目标用户推荐出的所有好友数量的比值。图1显示了两种算法下的查准率结果。 图1中显示了基于用户综合相似度的推荐算法和本文算法的对比效果,从图中发现随着推荐人数的增加,两种算法对应的曲线都呈现下降趋势。这主要是因为伴随着推荐人数逐渐增多,在原有的基础上引入了不同的用户,导致了用户之间的相似度呈现出下降趋势,不确定因素的用户数量上升,因此导致查准率有所降低。考虑到实际情况中的推荐用户存在的多个潜在好友的情况,为了研究成果具有针对性,避免造成不必要的負面推荐影响,本文设定平均推荐为20人,当推荐人数为1的时候,本文算法的查准率明显优于基于用户综合相似度推荐算法,虽然随着推荐人数的逐渐增多,查准率都有所下降,但本文算法依然具有优势,这说明了本文算法的效果。 4.2 查全率 查全率是指查看结果是否全面的程度。其值等于目标用户推荐出的正确好友数量与目标用户好友数量的比值。图2显示了两种算法下的查全率的结果。 图2中显示了基于用户综合相似度的推荐算法与本文算法的对比结果,从图中得到随着推荐人数不断增加,两种算法对应的曲线都呈现上升的趋势,这是因为随着推荐人数的不断增加,搜索到的用户信息更加的全面,随着推荐人数不断的上升,本文算法在整个曲线的总体上的查全率值始终优于基于用户综合相似度的推荐算法,当人数在达到16人后,两种算法的差距正在逐渐减少,但是相比之下,本文算法依然具有一定的优势,这也说明了本文算法在社交网络的朋友推荐方面确实具有良好的效果,由于采用了猴群算法,使得在社区朋友推荐方面具有明显的提升,提高了查询广度,扩大了交友的范围,提升了寻找的效率。进一步说明了本文算法的效果。 4.3 F1指标 F1指标主要用来权衡查准率和查全率之间的权重关系,这是因为衡量一个良好的朋友推荐系统要兼顾准确率和查全率,其值等于查准率和查全率的积与两者和的比值。图3显示了两种算法下F1指标结果。 图3中显示了基于用户综合相似度的推荐算法与本文算法的对比效果,从整体上看,随着平均推荐人数的增长,本文算法、基于用户综合相似度的推荐算法在F1方面都呈现先上升后下降的平稳趋势。当推荐的人数数量较少的时候,本文提出算法的Fl平均为0.251,而基于用户综合相似度推荐的F1为0.212。当推荐人数为12的时候,两种算法都达到了最大值,本文提出算法的Fl为0.453,而基于用户综合相似度推荐的F1为0.421,当推荐人数大于12的时候,由本文算法和基于用户综合相似度推荐算法可知,本文算法得到的F1值为0.262,基于用户相似度的推荐算法的F1值为0.247。由此可见,本文算法取得了更好的推荐效果。这主要是因为F1指标需要考虑查准率和查全率两个指标,由于这两个指标评价本身存在一定的同斥性,因此会导致出现先升后降的趋势,但从整体上看,本文算法在综合指标上还是优于基于用户综合相似度的推荐算法,这说明了算法具有较好的稳定性,说明了采用猴群算法的社交网络推荐确实能够提高效率,对用户综合信息形似度的排序,选择相似度最高的用户当作猴群个体进行求解得到推荐的好友,提高了算法推荐效率。 5 结 论 针对社交网络中可能存在用户信息推荐不准确的问题,提出了一种基于云计算下的社交网络朋友推荐算法,在该算法中主要阐述了基于猴群算法的朋友社区推荐方案,仿真实验数据说明该算法在社交网络中具有较好的效果,下一步研究方向朝着用户隐私安全进行考虑。 参考文献: [1] 程宏兵,王珂,李兵,等.一种高效的社交网络朋友推荐方案 [J].计算机科学,2018,45(S1):433-436+452. [2] 马秀麟,衷克定,刘立超.从大数据挖掘的视角分析学生评教的有效性 [J].中国电化教育,2014(10):78-84. [3] 王玙,高琳.基于社交圈的在线社交网络朋友推荐算法 [J].计算机学报,2014,37(4):801-808. [4] 俞琰,邱广华,陈爱萍.基于混合图的在线社交网络朋友推荐算法 [J].现代图书情报技术,2011(11):54-59. [5] 刘航.关于用户踪迹融合协同过滤推荐的仿真研究 [J].计算机仿真,2020,37(7):422-425+454. [6] ZHAO R, TANG W. Monkey Algorithm for Global Numerical Optimization [J]. Journal of Uncertain Systems,2008,2(3):164-175. 作者简介:陈暄(1979.03—),男,汉族,安徽祁门人,教师,副教授,硕士,研究方向:云计算、社交网络。
猜你喜欢
电脑知识与技术(2016年24期)2016-11-14
企业导报(2016年20期)2016-11-05
新闻前哨(2016年10期)2016-10-31
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
