
配电云平台的决策级数据融合及其并行化
2021-07-28 10:38:50赵瑞锋李世明
电气技术 2021年7期
王 可 赵瑞锋 李 波 李世明
配电云平台的决策级数据融合及其并行化
王 可 赵瑞锋 李 波 李世明
(广东电网有限责任公司电力调度控制中心,广州 510600)
随着传感器技术的不断发展,配电主站中包含的传感器数量不断增加,配电云平台能够接收海量数据。为了提高数据的利用率,同时提高云平台对数据的处理效率,本文提出一种关于配电云平台的决策级数据融合方法及其并行化方案,通过计算传感器的重要程度判断传感器网络中各传感器反映某事项的程度,从而决定是否将数据实时传输到应用层,同时利用改进的基于权重的D-S理论在应用层实现进一步的数据融合,整个过程利用Spark进行并行化计算。本文提出的数据传输及融合方法能够在保证数据传输完整性的前提下大大提高应用层的决策效率,尤其对于需进行实时判断的事件,所提方法能够保证配电云平台实时高效地做出决策。
数据融合;权重;D-S理论;配电云平台;Spark并行
0 引言
近些年来,电力系统不断发展,电网规模不断扩大,传感器数量随之增加。传感器收集各类信息为配电云平台的数据分析及决策提供数据支持,数据集的规模和复杂性正在迅速增长。
随着配电物联网技术的不断发展,相关技术与应用不断更新,“云大物移智”逐渐应用于配电物联网。传统平台采用主备服务集中式处理模式,而如今配电网点多面广,除了传统配电网数据,低压数据、可再生能源数据、冷热能源数据、电动汽车充电数据、环境数据等不断接入,传统方法在海量终端接入、数据处理速度、存储能力及分析效率等方面存在着明显的瓶颈[1]。目前,配用电主站系统正转向边缘计算加云计算的技术架构,实现分布感知集中决策的配用电主站云边体系架构;除此之外,微服务技术也开始应用于云平台,它能够将应用分解为多个相互独立的、可以相互连接的微服务[2]。
基于配电云平台,诸多应用不断涌现。利用云平台能够实现数据实时监控,可以保存视频监控图像便于后期查看,还能够实现数据的可视化及智能处理。通过封装大数据分析、机器学习等算法,运维人员能够通过简单的拖拽操作实现相关的数据挖掘功能。广义的云平台涉及云、管、边的各个环节。目前为止,关于配电网的建设,仍存在以下问题:
在实时分析时,传统智能电网系统[3]通过分析终端向数据层发出请求,数据层根据请求,将全部相关数据通过规约层层传递到数据分析层,当数据规模较大时,传输速度较慢。实际上,现今配电物联网平台拥有相当数量的数据采集点,这些节点密集地分布在整个区域中,在某个小区域里,不止一个传感器采集的数据能够反映该区域的实时情况,若利用传统方法则会增加传输及计算成本,不能全面高效地对数据进行实时分析。
在应用层进行数据分析时,由于配电云平台获取的不再是单一的电力数据[4],温度、风力等多类环境数据也会传输到云平台进行保存,在进行数据分析时,与待分析问题相关的数据种类增加,若不对这些数据进行优化而直接进行数据分析,则计算量会呈指数级增长。
针对上述问题,本文提出一种基于配电云平台的决策级数据融合方法及其并行化方案,以减少下沉式计算模型中需实时处理的数据及各类数据分析任务的数据规模,提高云平台的决策效率。
1 总体架构
配电系统中的多类传感器组成一个无线传感器网络[5],这些传感器节点密集部署在整个区域中,通过无线通信来感知、监视和测量特定事件[6]。传感器节点可以通过单跳或多跳方法交换其数据,以将其传递到网关或基站进一步处理。配电系统中形成的无线传感器网络通常由单个或者多个协议控 制[7],以适应网络的功能和规格,包括其节点的部署、网络环境、自我配置、能耗和容错能力[8]。针对无线传感器网络的特点,考虑到相距较近的节点采集的数据较相似,为了实现实时数据分析,并减少数据损失,通过判断传感器节点在传感器网络中的重要程度,优先传输重要数据,对实时性要求不高的数据则在之后传输。Kshell[9]、度中心性[10]、接近中心性[11]常被用于寻找复杂网络中的重要节点,采用Kshell及接近中心性等方法能够衡量一个传感器节点对于整个拓扑网络的重要性,而希望得到的是传感器节点在其所处的小区域中的重要性,因此,本文所提方法基于度中心性寻找重要节点。首先将有代表性的传感器采集到的数据传输到应用层,采用所提策略可以精简数据,提高传输效率,尽可能地减少不必要的开销及冗余计算,提高系统运行效率。
除此之外,可进一步地在应用层对相关数据进行决策级的数据融合。决策融合是一种决策工具[12],决策融合方法能够合并来自多个传感器的结果以提高决策系统的性能。贝叶斯推理[13]、模糊逻辑[14]及D-S证据理论[15]是许多研究领域中常用的决策融合方法。贝叶斯推理会因规则的增加或删除而重新计算所有概率,运算量过大;模糊逻辑虽然运算量适中,但是其通用性较差;D-S证据理论将每个传感器输出视为证据程度或基本概率分配,然后将多个基本概率分配进行组合,具有更强的通用性。针对不同的问题,不同类型的传感器提供的数据对该类决策的贡献程度不同,例如定位开关故障时,电流、电压及温度传感器提供的数据更有参考价值。考虑到配电云平台针对不同问题进行分析的特点,设计一种确定不同类型数据权重的方法,利用基于权重的D-S证据理论,实现在配电云平台的并行决策级数据融合,与传统方法相比,可以充分利用各个数据源之间包含的冗余和互补信息,提高系统决策的准确性。
为了进一步提高配电云平台的数据分析效率,本文提出的方法利用Apache Spark进行并行化处理。Spark是一个容错通用集群计算系统。Spark模型的主要概念是弹性分布式数据集(resilient distributed dataset, RDD),R. Kozik等将RDD定义为对象的只读集合,该对象在集群的各个节点之间进行分区和分布[16]。Spark引擎自动并行化进行RDD的相关操作,这种抽象使程序员不必处理线程、锁及传统并行编程中涉及的所有复杂性问题。与Hadoop的MapReduce模型相比,Spark的处理时间更快[17]。本文提出的配电云平台数据分析框架如图1所示。
2 方法
2.1 确定传感器的重要程度
在电力系统中,大多数区域会设置多个传感器,地理位置相近的同种类型传感器传递的数据具有很大的相似度,如果都进行实时传输会造成数据冗余,也会增加无线传感器网络的数据传输压力。考虑到在无线传感器网络中,每个传感器都是网络中的一个节点,与其周围节点联系更加紧密的节点所采集的数据能够大致反映该区域的实时情况,因此,通过计算节点的重要程度来选择需实时传递的传感器数据。节点选择及数据传输规则如下。

图1 配电云平台数据分析框架
1)在无线传感器网络中,每个传感器可视为一个节点,根据路由策略,能够形成传感器网络G,根据传感器类型对网络G中的每个节点进行编号,如低压配电区数据的标签设为1,环境数据(如温度、风力大小等)的标签为2,以此类推,形成传感器网络G的节点标签集合。
2)对于每个传感器节点,标签和它相同的相邻节点对它贡献度的权重为1,标签和它不同的相邻节点对它贡献度的权重为0.5。
3)由于考虑的不是节点的全局重要性,而是它在所处区域内的重要程度,因此,利用节点的度中心性来衡量,即

式中:I、I分别为节点、的度中心性,即重要程度;l、l分别为节点、的标签;d为节点与之间的物理距离。
4)计算出节点的重要程度后,选择需要优先传输数据的节点。对于每个标签l所包含的节点按照重要程度进行排序,首先选择第一个节点即重要程度最高的节点,然后删除它的一跳相邻节点中所有的标签为l且距离小于阈值的相邻节点,以此类推,直到所有节点都被遍历一遍。
5)删除的节点减缓向簇首传输数据的速度,即不立即向簇中心传递数据,实现方法是设置不同节点传输数据到簇首的时间,由簇首控制。
2.2 改进的基于权重的D-S证据理论
1)基本原理
本文改进的基于权重的D-S证据理论[18]步骤如下:
(2)根据需要处理的事项获取信度函数(F),(F)为属于F的信度函数。由于处理不同事项形成的识别框架和信度函数不同,这里讨论的是数据融合的通用性框架,信度函数公式需根据处理事项具体判断,此处不讨论。
(3)合成规则加权为

其中有
式中:F、F、F分别表示事项、、;m(F)表示第类传感器数据关于F的信度函数值;的计算在下文中讨论。
2)加权(即确定k的值)
结合上一步获得的节点重要程度,针对每个传感器所传输数据的重要程度,为每个传感器数据赋予权重。配电云平台中保存了多种数据,除了电压、电流等电力系统相关数据,还有温度、风力等多类环境数据。在解决不同问题时,不同数据的重要程度不同。例如,分析馈线故障原因时,环境情况(如风力)、电力系统中馈线相关的数据(如电压数据)在此数据分析任务中起较重要的作用,此时应给予这些数据更高的权重。因此,通过考虑传感器的重要程度和先验相关系数来求该权重。重要程度的计算如前文所述,本文利用层次分析法计算先验相关系数,即引入经验值。
(1)首先需要确定决定不同传感器与待分析问题相关程度的判断准则,此处选择距离、参数相关性作为判断准则,根据要分析的问题,该因素可由决策者(专家)根据经验进行判断。然后构造判断矩阵,其元素a的确定采用Santy的1-9标度法[19],见表1,专家根据经验确定a的值。

表1 aij的确定
求出判断矩阵的最大特征值对应的特征向量,该特征向量就是该类数据通过迭代最终得到每类数据的权重。
(2)由传感器重要程度及通过层次分析法获得的传感器先验相关系数,可以获得用于规则合成的最终权重值,即
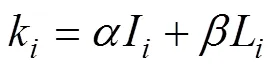
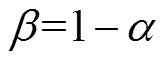
3 Spark并行化
Spark遵循主从模型,通过集群管理器(主机master)驱动程序能够访问集群。驱动程序通过将任务分配给执行程序来协调用户应用程序的执行,执行程序是在工作节点(从站slaves)中运行的。默认情况下,每个工作节点仅运行一个执行程序。关于数据,RDD分区分布在工作节点上,驱动程序为每个执行程序启动的任务数取决于驻留在工作程序中的RDD的分区数。本文中把无线传感器网络看成一个拓扑,利用Spark的GraphX计算引擎进行一系列的并行计算[20]。并行化总体框架如图2所示。
3.1 确定重要传感器并行化
首先是衡量每个传感器的重要程度,同时得到传感器的合成规则加权值,为后续决策级数据融合提供数据支持,流程如图3所示。
GraphX提供的degree算子能够获取相邻节点的信息,利用式(1)计算传感器的重要程度获得ImpRDD。同时,结合Santy标度法,能够得到合成规则权重KRDD。

图2 并行化总体框架

图3 衡量传感器重要程度的流程
具体来说,在每个工作节点上,通过degree算子可以得到传感器在该节点的相邻节点的信息,然后通过工作节点间的通信,reduceByKey算子能够根据传感器ID获得该传感器所有的相邻节点信息,即整合多个传感器相邻节点信息CRDD并结合式(1)得到每个传感器的重要程度ImpRDD。根据第2节中提出的重要传感器选择策略,每次选择一个需要进行实时数据传输的传感器节点后,利用subgraph算子去掉标签相同的相邻节点,得到一个子图,然后重复上述操作,直到每个传感器的优先性SRDD都获得value值,value为1表示该传感器的数据优先传输,value为0则表示该传感器数据在进行实时数据分析时不立即传输到应用层,传感器重要性判断流程如图4所示。
3.2 决策级数据融合并行化
当数据传输到应用层时,利用改进的基于权重的D-S证据理论可以进行决策级的数据融合,在每个集群(工作节点)上,通过式(2)计算中间信度函数FRDD,通过节点间的通信及reduceByKey算子,最终可以得到每个故障对应的信度函数KMRDD,决策级数据融合并行化流程如图5所示。

图4 传感器重要性判断流程

图5 决策级数据融合并行化流程
4 结论
本文介绍了一种基于配电云平台的数据融合方法及其并行化框架,提出了一种计算节点重要程度的方法,首先将传感器网络中有代表性的数据传输到应用层,然后利用改进的D-S证据理论进一步对数据进行决策融合。考虑到配电云平台针对不同问题分析的特点,设计了一种不同类型数据权重的确定方法,并利用Spark进行并行计算,在配电云平台实现了并行决策级数据融合。
与传统方法相比,所提方法可以充分利用各个数据源之间的冗余和互补信息的优点,提高系统决策的准确性,能够识别近60%的冗余数据,分析速度提高了将近40%,大大提高了数据分析的效率。
[1] 李勋, 周伟. 依托关联规则挖掘的电力生产安全事故致因攫取[J]. 电气技术, 2020, 21(2): 86-90, 118.
[2] 耿贞伟, 苏文伟. 对微服务架构的电力云服务平台研究[J]. 微型电脑应用, 2019, 35(2): 80-82.
[3] 汪东平. 基于无线传感网的智能电网故障监控系统设计与实现[J]. 自动化与仪器仪表, 2019(5): 63-67.
[4] 陈汝斯, 林涛, 毕如玉, 等. 基于有限量测数据的主动配电网电压暂降源精确定位策略[J]. 电工技术学报, 2019, 34(增刊1): 312-320.
[5] 叶永市, 林瑞全, 龚林发. 基于多传感器的电缆绝缘监测[J]. 电气技术, 2020, 21(3): 91-96.
[6] 王晨宇, 汪定, 王菲菲, 等. 面向多网关的无线传感器网络多因素认证协议[J]. 计算机学报, 2020, 43(4): 683-700.
[7] 吴戈, 纪鹏菲, 张铮, 等. 基于异步调度的低延时无线传感器网络MAC协议[J]. 传感器与微系统, 2019, 38(6): 19-22.
[8] ZHAO Mingbo, TIAN Zhaoyang, CHOW T W S. Fault diagnosis on wireless sensor network using the neighborhood kernel density estimation[J]. Neural Computing and Applications, 2019, 31(8): 4019-4030.
[9] 李昌超, 康忠健, 于洪国, 等. 考虑电力业务重要性的电力通信网关键节点识别[J]. 电工技术学报, 2019, 34(11): 2384-2394.
[10] WANG Yu, GUO Jinli, LIU Han, et al. A new evaluation method of node importance in directed weighted complex networks[J]. Journal of Systems Science and Information, 2017, 5(4): 367-375.
[11] ZHANG Yao, PRAKASH B A. Data-aware vaccine allocation over large networks[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2015, 10(2): 1-32.
[12] 袁晓光, 杨万海, 史林. 动态大规模无线传感器网络决策融合[J]. 电子与信息学报, 2010, 32(12): 2976-2980.
[13] 翟社平, 郭琳, 高山, 等. 一种采用贝叶斯推理的知识图谱补全方法[J]. 小型微型计算机系统, 2018, 39(5): 995-999.
[14] 章思青, 陶洋, 代建建, 等. 基于模糊逻辑的多跳WSNs分簇算法[J]. 传感技术学报, 2018, 31(7): 1085-1090.
[15] 李捷, 杨雪洲, 周亮. 基于改进DS理论多周期数据融合的目标识别方法[J]. 火力与指挥控制, 2019, 44(7): 43-48.
[16] KOZIK R. Distributing extreme learning machines with apache spark for net flow-based malware activity detection[J]. Pattern Recognition Letters, 2018, 101: 14-20.
[17] 肖文, 胡娟, 周晓峰. 基于MapReduce计算模型的并行关联规则挖掘算法研究综述[J]. 计算机应用研究, 2018, 35(1): 13-23.
[18] 陈杰. 基于DS证据理论的决策融合算法研究[D]. 哈尔滨: 哈尔滨工程大学, 2016.
[19] 张鼎衢, 林国营, 宋强, 等. 基于灰色理论及模糊层次分析法的电能计量装置状态评估[J]. 电测与仪表, 2019, 56(11): 134-139, 152.
[20] 时生乐, 赵宇海, 李源, 等. 一种有效的基于GraphX的分布式结构化图聚类算法[J]. 计算机科学与探索, 2017, 12(10): 1571-1582.
Decision level data fusion and parallelization of power distribution cloud platform
WANG Ke ZHAO Ruifeng LI Bo LI Shiming
(Electric Power Dispatching and Control Center of Guangdong Power Grid Co., Ltd, Guangzhou 510600)
With the continuous development of sensor technology, the number of sensors included in the power distribution master station is increasing. The power distribution cloud platform can receive massive amounts of data. In order to improve the utilization rate of data and speed up data processing in the cloud platform, this paper proposes a decision-level data fusion method on the distribution cloud platform and its parallelization scheme. By calculating the influence of the sensors, it is possible to determine the degree that each sensor in the sensor network reflects a certain item, thereby deciding whether to transmit the data to the application layer in real time. At the same time, the improved weight-based D-S theory is used for further data fusion at the application layer, and the entire process uses Spark for parallel computing. On the premise of ensuring the integrity of data transmission, the data transmission and fusion method proposed in this paper can greatly improve the decision-making efficiency of the application layer. Especially for events that require real-time judgment, this method can enable the distribution cloud platform to make decisions in real time and efficiently.
data fusion; weight; D-S theory; power distribution cloud platform; parallel (Spark)
广东电网有限责任公司科技项目(036000KK52180021)
2020-10-09
2020-11-18
王 可(1989—),男,硕士,工程师,主要研究方向为电力系统自动化、电力系统大数据。
猜你喜欢
意林(2021年2期)2021-02-08 08:32:47
当代陕西(2020年17期)2020-10-28 08:18:18
经济技术协作信息(2018年7期)2019-01-14 03:05:40
电子制作(2018年18期)2018-11-14 01:48:20
通信电源技术(2018年5期)2018-08-23 01:16:20
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
断块油气田(2014年6期)2014-03-11 15:33:53
河南科技(2014年16期)2014-02-27 14:13:18
河南科技(2014年15期)2014-02-27 14:12:51
