
基于SSD的小目标检测改进算法
2021-07-27 02:59程凯强寇旭鹏
计算机与现代化 2021年7期
程凯强,张 旭,寇旭鹏
(1.上海工程技术大学机械与汽车工程学院,上海 201620; 2.云南农业大学大数据学院,云南 昆明 650201)
0 引 言
随着深度卷积神经网络[1]和图像计算硬件的发展,计算机视觉在智能交通、智能安防系统中得到了广泛应用。计算机视觉任务中主要包括图像分类[2]、目标检测[3]、语义分割[4]、实例分割[5]等任务。目前单一类别的目标检测如人脸[6]、行人检测[7]技术在日常生活中得到了一定范围的应用,但多类别目标检测依然存在目标漏检、误检的问题,尤其是数据中的小目标,仍具有较大的提升空间。
检测任务和分类任务一样都依赖图像的特征信息的提取,传统的特征提取方法主要有HOG[8]、Haar[9]、LBP[10]等算法,这些传统算法需要人为设定阈值。由于目标的形态多样、光照变化强度不一、背景复杂等因素,重新设计一个鲁棒性较强的传统模型并不容易,并且其提取的图像特征影响后续分类的速度和准确率。随着卷积神经网络的不断发展,通过卷积核学习相关参数来获取图像的抽象特征的优势逐渐凸显出来,出现了很多经典网络模型:AlexNet[11]、VGG[12]、GoogleNet[13]、ResNet[14]、DenseNet[15]等提取图像信息,并应用到相应的工作任务中。
基于深度学习的目标检测任务中主要包含目标分类和位置回归2大任务,研究人员将其分为2大类:双阶段目标检测算法和单阶段目标检测算法,双阶段目标检测算法先使用算法产生目标获选区域,然后对获选区域进行再分类,而单阶段目标检测算法是直接对输出图像应用算法同时得到目标类别和相应的位置信息。RCNN[16]是目标检测领域CNN的开山之作,首次将神经网络引入目标检测任务中。何凯明等人提出的Faster RCNN[17]中采用RPN网络来替代Selective Search[18]提取候选框的方法,实现了端到端训练,并且提出anchor机制提高多类别目标的检测精度,但是其将目标检测分为2个阶段来完成,受到锚框生成机制的影响,模型在检测速率方面较弱。牛津大学为了检测任务能够达到实时效果,提出了YOLO[19]系列算法,利用回归的思想,大大提高了检测速度,但是其识别的目标位置精准性差,召回率低。Liu等人在2016年提出SSD[20]算法,结合YOLO算法中的回归方法,沿用Faster RCNN中的anchor机制,并且提取多尺度特征图进行分类和检测,大大提高了目标检测的精度,且检测能达到实时效果,但是其中用来检测小目标的浅层特征图中缺乏高层的语义信息,导致小目标检测的精度较低;并且在固有的多尺度特征图中通道和空间信息同等关注,影响整体的信息利用率,不利于获取不同目标的典型特征。
针对这些问题,本文选取SSD作为基础模型,并提出以下的改进方法:
1)在浅层特征层前采用深度可分离卷积和普通卷积进行同步特征学习,并进行特征融合,使得浅层卷积获得不同感受野的特征图和丰富的语义信息,提高小目标的检测精度。
2)在所有有效特征图后添加空间和通道权重分配网络,保证网络关注空间和通道间信息差异性和重要度,更关注有用信息的利用分析,提高检测精度。
1 SSD模型原理
SSD是一种常用的单阶段检测算法,分类和定位都被拟合为回归问题,其沿用了Faster RCNN中的anchor机制,在有效特征图中设置尺度和长宽比不同的先验框,获得一定比例数量的预选框,其主要优势在于采用多尺度的特征图进行目标检测,减少了不同大小和形状的目标的漏检和误检,其网络结构如图1所示。
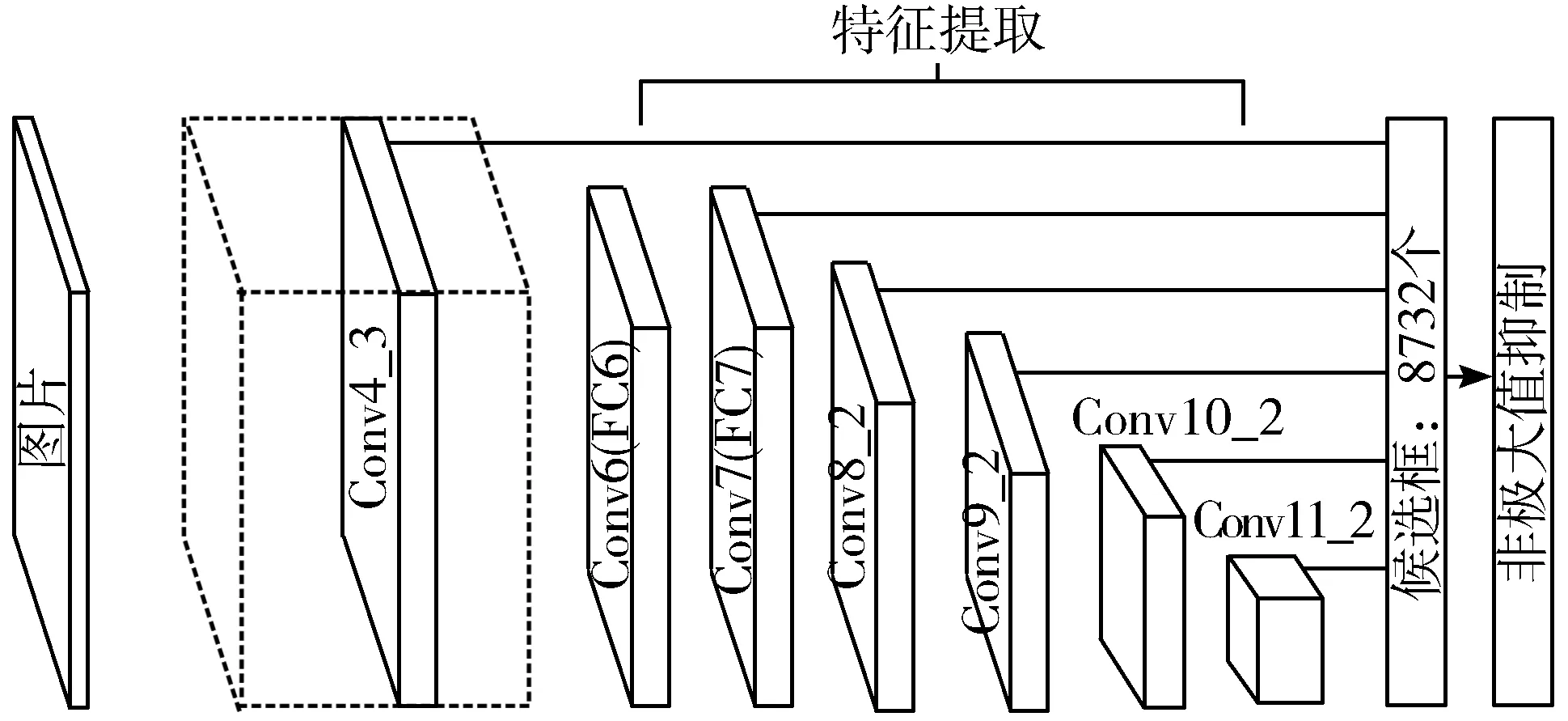
图1 SSD模型
SSD中将VGG16最后的全连接层替换为卷积层,其后加入5层卷积,并且去除Dropout层。将改进后的VGG16网络作为特征图提取的主干网络,其主要流程为:使用改进后的VGG16对输入的RGB三通道彩色图像进行特征提取,得到一系列的特征图,并且选取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2这些特征图作为有效特征图,在有效特征图中每个像素点上设置不同比例的锚框,Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2中分别设定5776、2166、600、150、54、4个锚框,并进行锚框的分类和定位回归,最后将得到的候选框输入非极大抑制(NMS)网络[21]中进行置信度排序和位置优化,得出最终的目标检测类别和位置信息。
Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2这些有效特征图对应的像素值分别为38×38、19×19、10×10、5×5、3×3、1×1,并且对应的网络通道数为256、1024、512、256、256、256,每个特征图对应的感受野大小不同,越深层特征图对应越大的感受野,更适合用来检测较大物体。由图2(排列后面代表深层特征图)的特征图可视化结果可以知道,浅层特征图中包含丰富的纹理和细节特征,深层特征图中包含丰富的抽象语义信息如轮廓形状和最强的特征(如人的眼睛区域),所以在SSD模型中的低层有效特征图的Conv4_3层中包含少量的抽象信息,适当增加其抽象信息丰富度,可以提高检测的精度。同时抽象信息中包含丰富的强信息特征,并且强信息特征可以作为类别的主要判断,所以在有效特征图后加入权重分配网络,关注特定类别的强特征信息,利于提高小目标的检测精度。

(a) 原图 (b) 特征图1 (c) 特征图2 (d) 特征图3 (e) 特征图4图2 特征图可视化
2 特征融合和权重分配的检测模型
针对SSD模型对目标检测能力不足的问题,本文首先提出基于双网络的特征提取,增强负责检测小目标的浅层特征图Conv4_3的抽象信息,然后在Conv4_3中每个像素中设置6个比例的候选框的大小,增多目标候选框,最后在SSD模型固有的多尺度特征层后面添加空间-通道联合权重分配网络,使得网络有效关注重要信息,提高目标检测精度。本文提出的基于特征融合和权重分配小目标检测模型如图3所示。
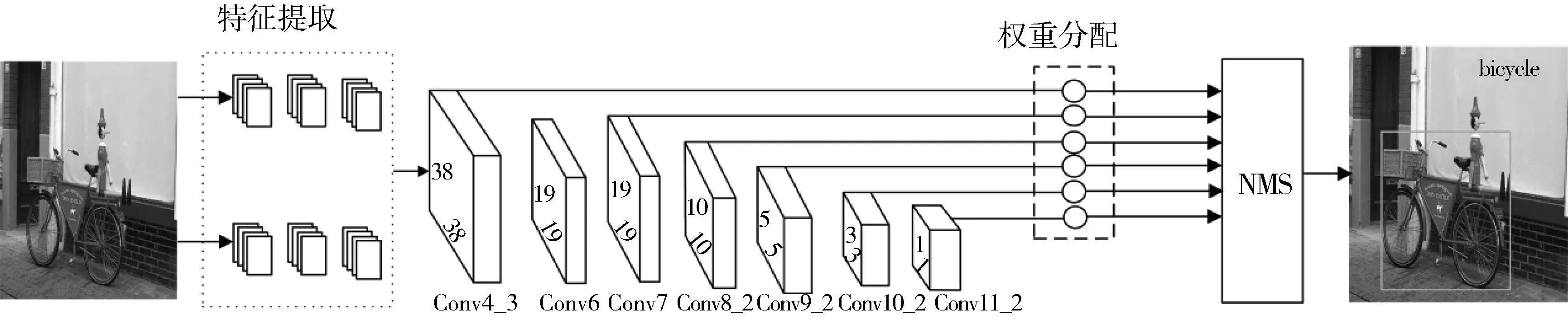
图3 改进模型结构图
2.1 特征融合
特征提取过程中,每一层提取得到的特征图所包含的信息都不相同,网络越深所得到的特征图语义信息越抽象;而SSD模型采用多层卷积特征图进行预测,其浅层特征分辨率高,拥有更详细的边缘信息,但是缺乏高层特征图包含的语义信息,影响小目标检测精度。所以本文在浅层特征层前设计双网络训练和融合来增强浅层特征的高级语义信息。其具体实现如下:
1)将训练图片输入深度可分离卷积[21],将输入层的信息进行每个通道独立卷积,然后对不同通道在相同位置进行加权特征融合,得到38×38×256的特征图N-Conv4_3。
2)使用普通3×3的卷积进行特征提取,得到38×38×256的特征图S-Conv4_3。
3)将2部分得到的特征N-Conv4_3、S-Conv4_3进行特征融合,得到38×38×512的特征图R-Conv4_3,替代原模型中的浅层特征图Conv4_3,特征融合模型具体实现如图4所示。
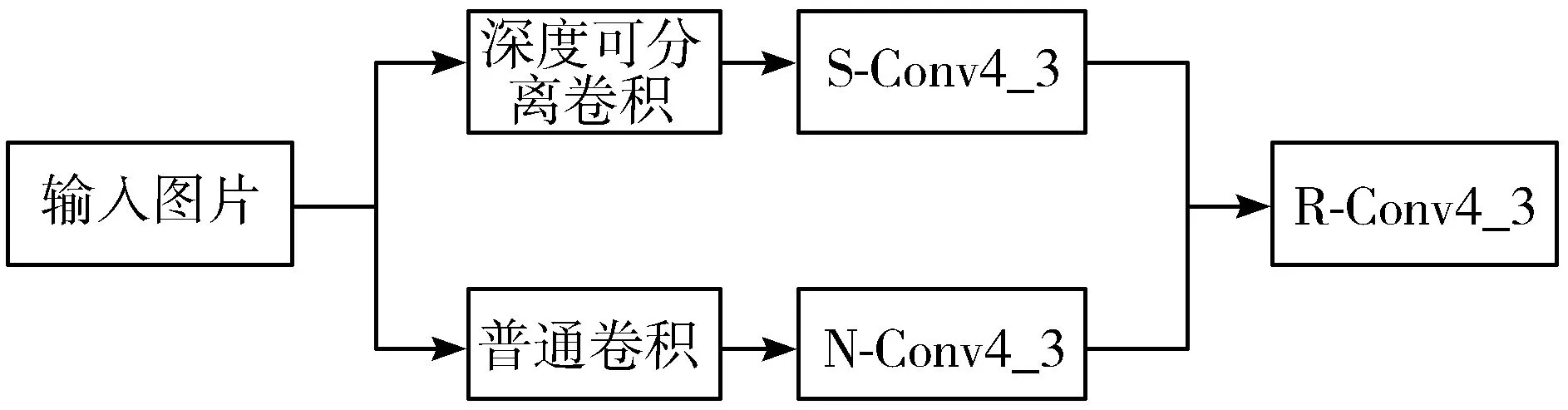
图4 特征融合
经过深度可分离卷积和普通卷积同步训练并融合以后得到的R-Conv4_3特征图比原模型中的浅层Conv4_3包含更多的语义信息,有利于检测小目标。
2.2 权重分配网络的实现
人在处理视觉图像信息的时候并不总是关注全局信息,而是根据不同任务重点来关注不同具体区域的信息来获取对任务处理有用的信息,然后根据不同区域的信息来建立内部的联系,指导有用信息的利用,减少无用信息的关注度。根据人类处理图像信息的特点,提出权重分配网络,以在图像信息提取过程中保证能够提取更多有用信息,保证定位和分类的准确性。
由图3可知,卷积得到的特征图每个通道包含不同强度信息,对后续图像分类和定位的贡献不同;本文中添加通道权重分配,在不同通道进行全局平均池化,得到每个通道的自适应权重参数,其计算公式如式(1):
Mc=Multi(σ(AvgPool(F),F))
(1)
其中,σ表示激活函数,进行非线性变换,F表示输入的特征,AvgPool(F)表示全局平均池化输出的特征。输入的特征图F通过基于宽和高的全局平均池化,将输出的特征与特征图进行基于逐元素的相乘操作,最终生成通道权重网络Mc,其结构如图5所示。
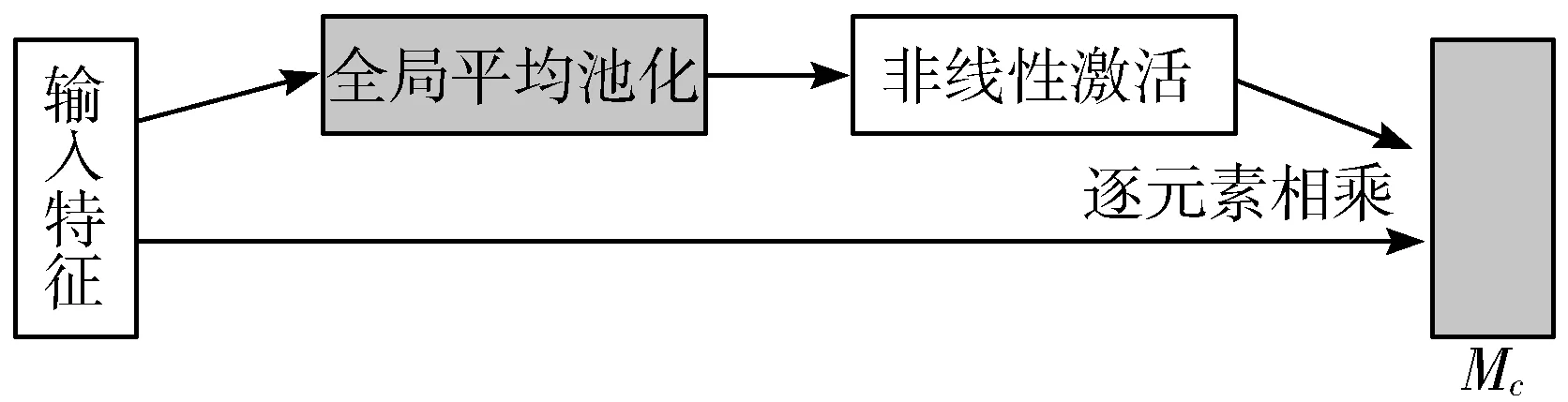
图5 通道权重分配
图像中不同邻域的像素之间包含着差异信息,特征图相邻的像素之间依然含有大量的差异信息,有效地利用相邻信息关联性和差异性,能够获取更多的特征图空间抽象信息,所以本模型中添加空间权重分配网络,在空间上得到自适应的权重参数,有利于准确定位目标尤其小占比目标,其具体实现如图6所示。
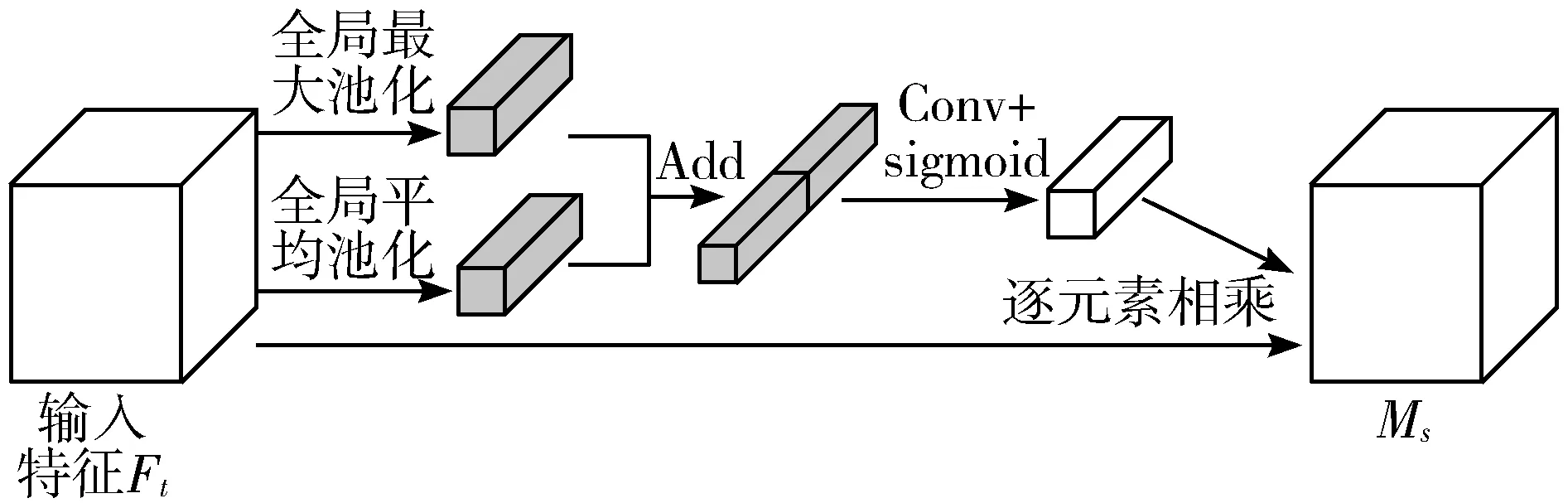
图6 空间权重分配
首先将输入的特征Ft分别进行全局最大池化、全局平均池化[22],得到每个像素的全局信息,并进行特征融合,获取空间维度信息的差异特征并表现在不同的权重中,将融合后的实数数列进行卷积得到和原输入相同维度的数列,最后将得到的数列和原输入特征图相乘,得到空间权重分配输出Ms。
针对图像中不同区域显示不均匀以及边缘不清晰导致检测精度差的问题,提出通道-空间联合的分配网络的检测模型,分别在特征输入空间和通道分配网络中,将不同分配网络得到的特征图进行融合,保留通道和空间权重信息,其具体的结果如图7所示。
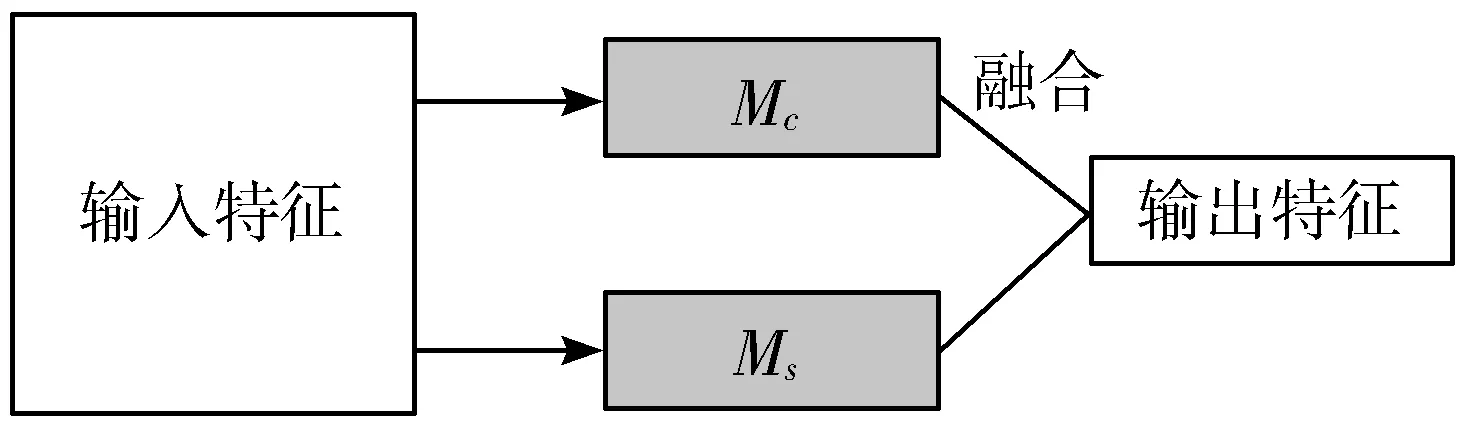
图7 联合权重分配
权重分配网络根据信息的重要程度,适当分配权重,保证有效信息权重大,无效信息权重小,使得网络能够有效地获取有用信息,减少无用信息的冗余。
2.3 模型中的损失函数
损失函数在模型训练过程中至关重要,训练过程中loss目标需逐渐减低最后趋于收敛和稳定。改进模型继续采用原模型的损失函数,其由位置损失(Lloc)和置信损失(Lconf)加权和组成,其公式如式(2)所示:
(2)
式中,Lconf(x,c)表示置信损失,Lloc(x,l,g)表示位置损失,N表示真实框和预测框的匹配数量,通过交叉实验验证得到α一般取值为1;当真实框和预选框的IOU大于设定的阈值,则取值为1,当真实框和预选框的IOU小于设定的阈值,则取值为0;式中位置损失Lloc(x,l,g)采用Smooth L1 loss函数来表示目标真实框与预测框之间的误差,置信损失Lconf(x,c)采用Softmax loss来计算每个类别概率。置信损失Lconf(x,c)和位置损失Lloc(x,l,g)的具体表达式分别如式(3)和式(4)所示:
(3)
(4)
3 模型的训练及评估
3.1 数据集
本文采用公开数据集PASCAL VOC 2007、PASCAL VOC 2007+2012进行模型训练,其中PASCAL VOC 2007、PASCAL VOC 2007+2012所包含的不同类别的数量如表1所示。
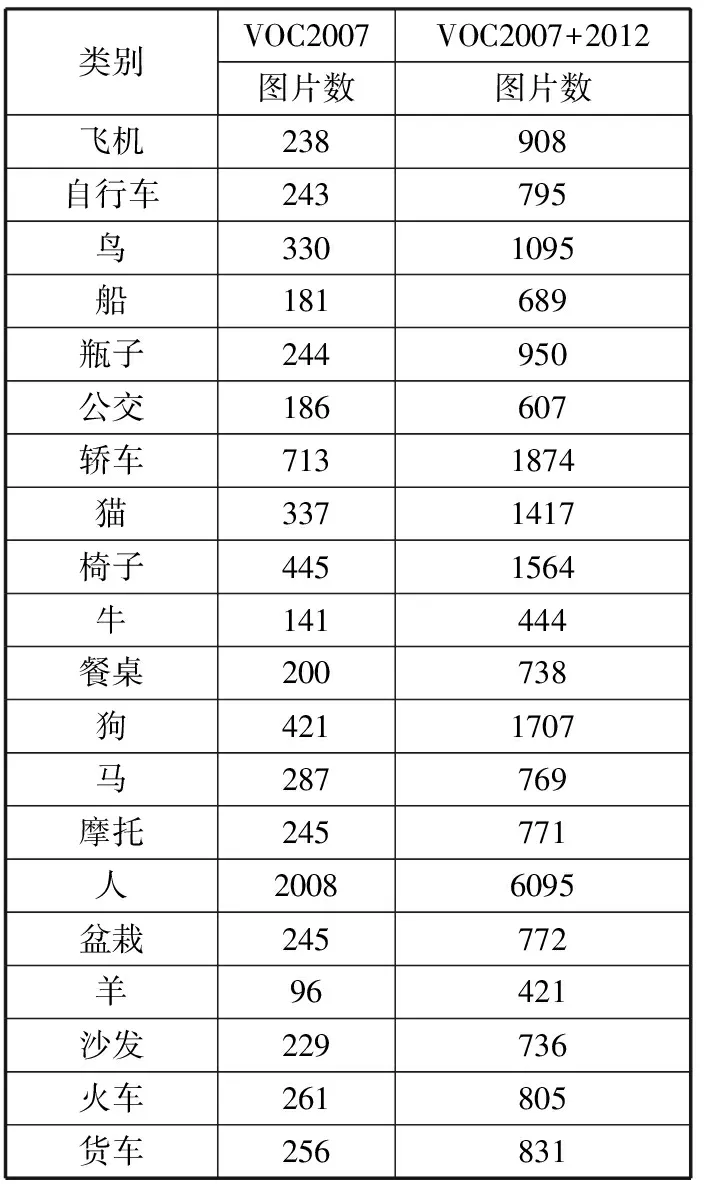
表1 数据集图片数量统计
3.2 环境配置及训练参数设置
本研究所有实验均在以下硬件环境中完成:Intel E5 2678 V3 CPU,32 GB内存,单个RTX 2080Ti GPU,系统版本为Ubuntu 18.04.5 LTS。使用Tensorflow1.14.0深度学习开源框架,10.1版本的CUDA并行计算架构。训练过程中参数设置如表2所示。
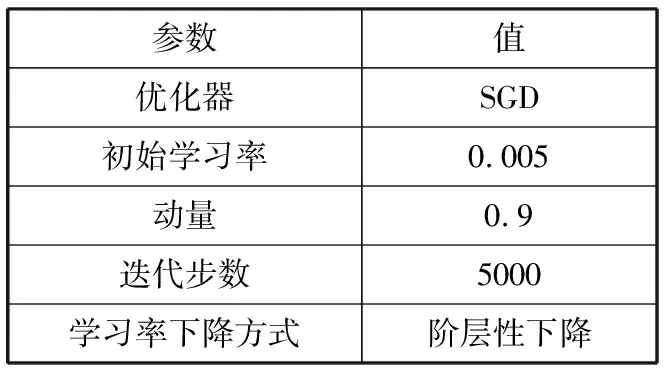
表2 参数设置
模型训练过程中训练损失和验证损失变化曲线如图8所示。
图8中横轴表示模型训练的epoch,纵轴表示损失值的大小,图8(a)代表训练集为VOC2007时,训练和验证的损失随着epoch的增加,逐渐降低,并且在epoch为60后趋于收敛。图8(b)代表训练集为VOC2007时,训练和验证的损失随着epoch的增加,逐渐降低,并且在epoch为40后趋于收敛。
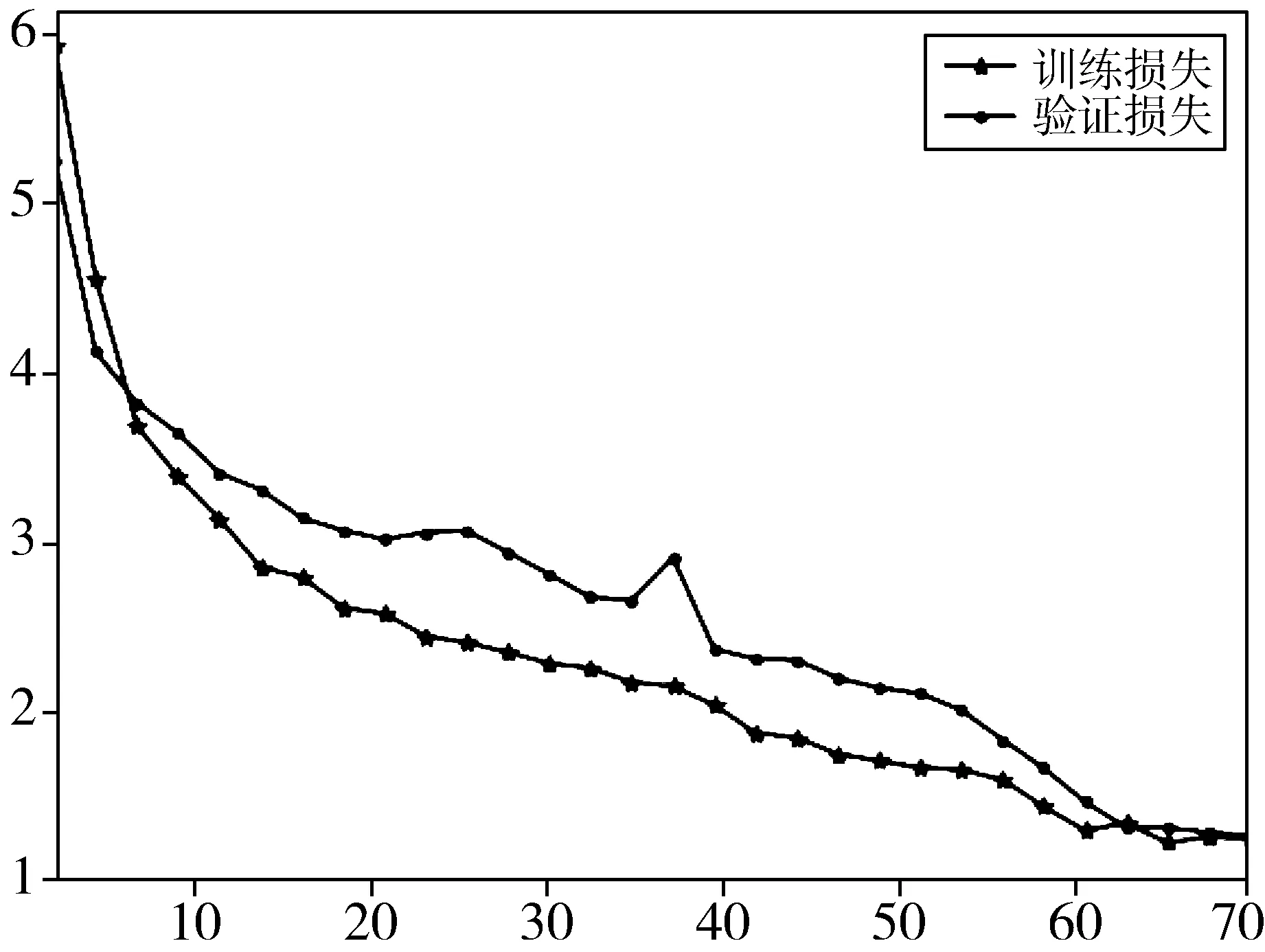
(a) 训练集为VOC2007+2012
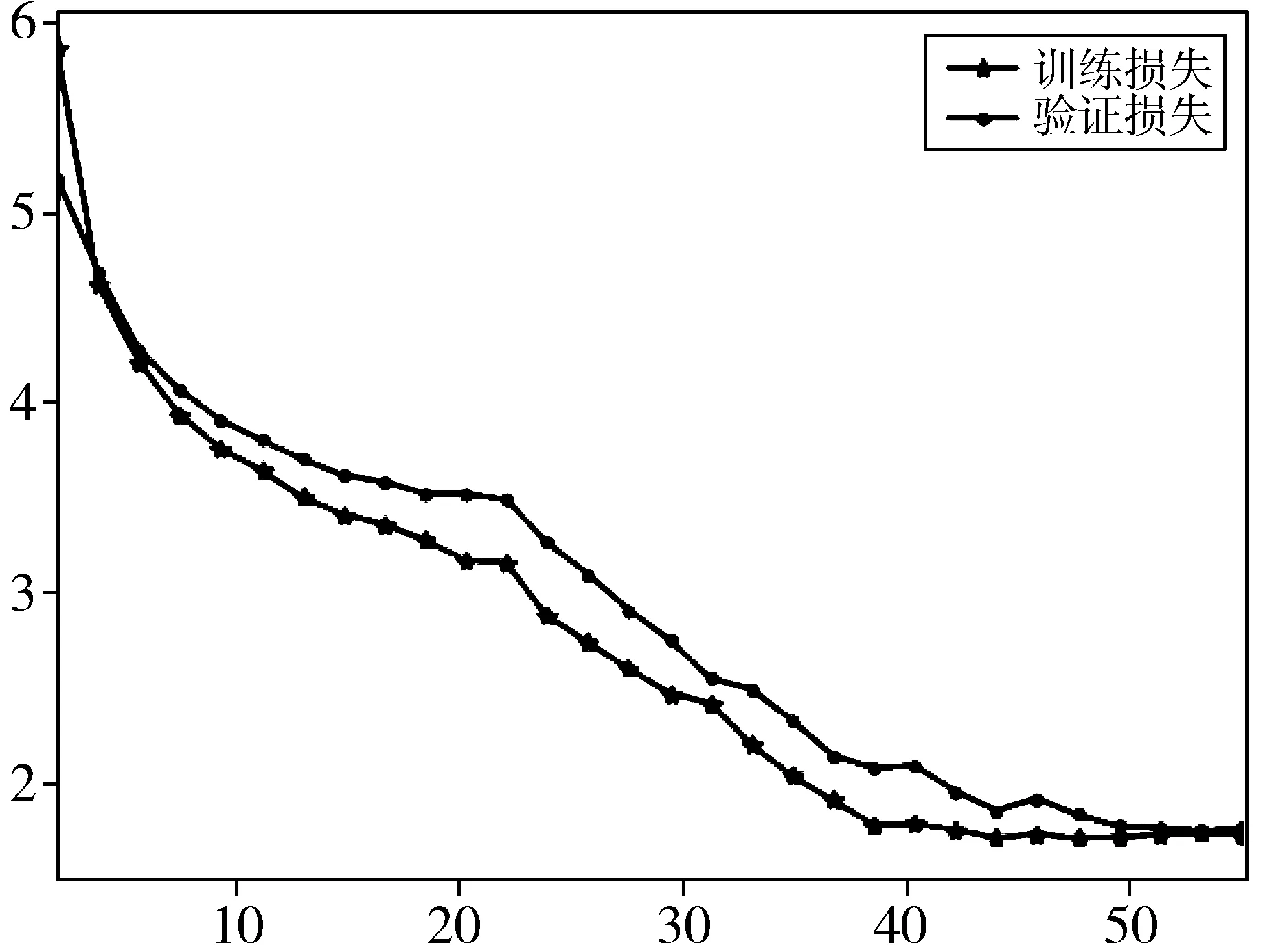
(b) 训练集为VOC2007
3.3 评价标准
mAP[23]是目标检测领域非常重要的性能评价指标,综合考虑了类别的平衡性、定位精度等问题。
本文以mAP作为模型的评价指标,其大小表示为以Recall召回率作为横坐标、以Precision准确率作为纵坐标所得到的图像面积大小,其中召回率表示实际是正类且被预测为正类的样本占所有实际为正类样本的比例;准确率表示为实际是正类且被预测为正类的样本占所有预测为正类样本的比例;在相同的置信度下,模型的mAP越大表示模型检测性能越好。
3.4 实验结果
采用改进的SSD模型,通过调优超参数提高模型的拟合程度,本文模型在VOC2007和VOC2007+2012训练集中分别进行模型训练,得到的平均mAP分别为74.98%、77.43%,与Faster RCNN、SSD分别对比,实验结果如表3所示。
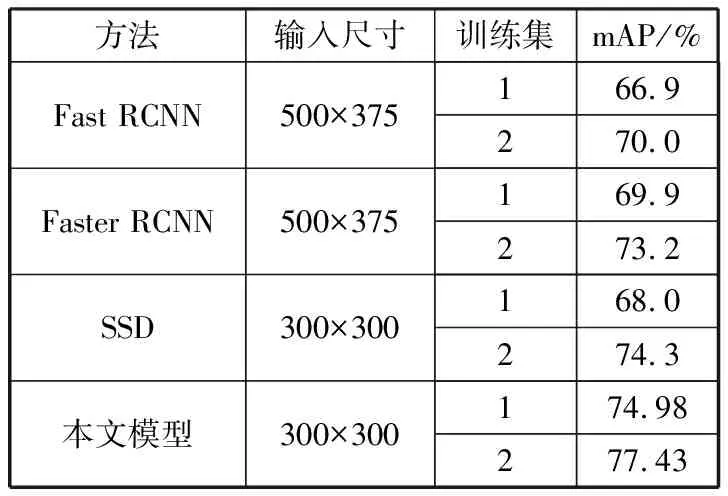
表3 目标检测结果对比
表3中训练集1表示VOC2007,2表示VOC2007+2012,由表3数据可知,VOC2007训练集训练时,本文提出模型的mAP为74.98%,较Fast RCNN、Faster RCNN、SSD分别提高8.08个百分点、5.08个百分点、6.98个百分点。VOC2007+2012训练集训练时,本文提出模型的mAP为77.43%,较Fast RCNN、Faster RCNN、SSD分别提高7.43个百分点、4.23个百分点、3.13个百分点。
本文提出的模型中使用深度可分离卷积和普通卷积进行同步特征提取,旨在提高浅层特征图的抽象信息,提高小目标的检测精度,VOC数据集中有20类不同大小的目标,本文选取6类具有代表性的较小目标进行小目标的精度对比,其结果如表4所示。
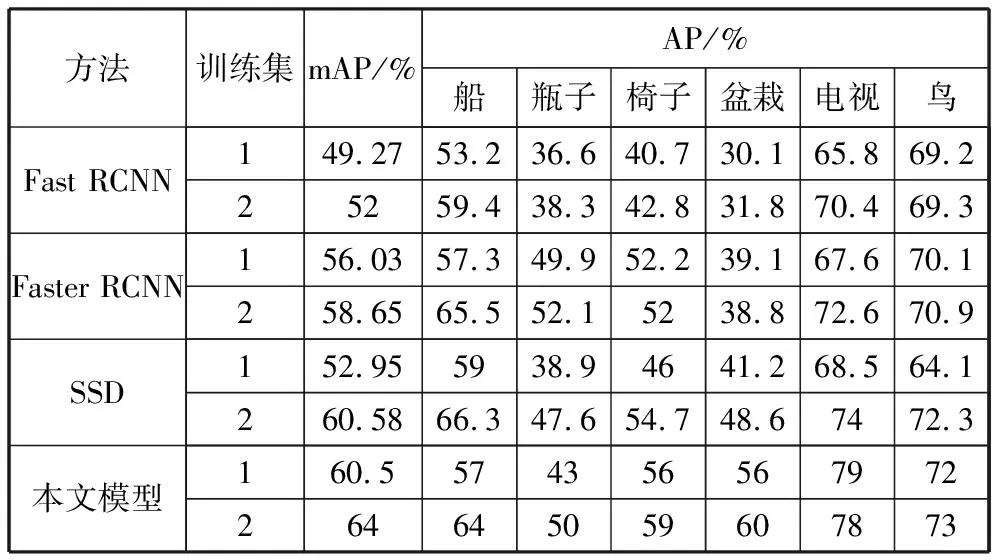
表4 小目标检测结果对比
表4中训练集1表示VOC2007数据集,2表示VOC2007+2012数据集,由表4数据可知,VOC2007训练集训练时,本文提出模型在6类小目标的平均准确率为60.5%,较Fast RCNN、Faster RCNN、SSD分别提高11.23个百分点、4.47个百分点、7.55个百分点;VOC2007+2012训练集训练时,本文提出模型的mAP为64%,较Faster RCNN、SSD分别提高12个百分点、5.35个百分点、3.42个百分点,盆栽和电视的检测精度提升尤为显著,所以本文提出的方法有效提高了目标的平均检测精度,对小目标的检测精度也明显提升。
不同模型可视化效果如图9所示,其中第一行表示本文提出的模型使用VOC2007训练情况下的检测效果,第二行表示本文提出的模型使用VOC2007+2012训练情况下的检测效果,第三行表示SSD模型的检测效果。在第一列有很多船只的检测图中,本文模型在VOC2007+2012训练下准确检测出的船只数量最多;并且此模型也准确检测出第二列较小的船只;在第三列中,VOC2007+2012数据集训练的模型对鸟的漏检达到最小,并且没有误检。由可视化效果可以知道,本文提出的模型在检测性能上有所提升。

图9 不同模型的可视化
4 结束语
本文改进的模型在主干网络部分采用深度可分离卷积和普通卷积构成双网络同步提取浅层特征图信息后进行特征图融合,获取对应不同感受野的特征信息,增强浅层特征图信息量;针对有效信息的模型表征能力问题,本文在有效特征图后加入权重分配网络,使得特征图中重要信息更易受到关注,降低了小目标的漏检率,提高了整体目标检测精度。
但是本文的算法在测试过程中依然存在目标重复检测的问题,后期将从非极大抑制NMS算法中进行分析,适当解决相关问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年17期)2020-10-28
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
人大建设(2018年5期)2018-08-16
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
应用科技(2015年5期)2015-12-09
电视技术(2014年19期)2014-03-11
