
基于线程队列动态规划法的GPU性能优化
2021-07-26 04:34魏雄胡倩王秋娴闫坤许萍萍
计算机与网络 2021年10期
关键词:并行计算
魏雄 胡倩 王秋娴 闫坤 许萍萍

关键词:线程队列;线程动态规划;加速比;线程调度;并行计算
0 引言
GPU 在大数据和人工智能领域表现出惊人的计算能力,随着GPU 的普及,在生命科学、航空航天和国防中提供了较强的计算能力,特别是在2020 年新冠肺炎基因序列测序和疫情传播预测等方面表现突出。
大数据和AI时代的到来使计算任务加重,面对应用的不同资源需求,GPU的资源单核未充分利用[1]。为了解决GPU资源利用率不足的问题,国内外学者提出一些方法,例如JustinLuitjens[1]提出了并发内核执行(CKE)来支持在GPU 上并发运行多个内核,并且GPU 自身架构也支持线程级并行性(Thread-level Parallelism,TLP)[2],但大量并发线程会导致严重的带宽问题,内存延迟而无法及时处理的内存请求有可能会导致流水线暂停,降低整体性能。
为了更好地提升性能,利用GPU 的资源,本文提出了线程队列动态规划法TQDP,从线程角度出发,通过提高线程的执行次数和提升系统吞吐量,从而提高系统性能。
1 GPU
新一代GPU 体系架构集成的计算资源越来越多,同时由于GPU 缺乏适当的体系架构来支持共享,需要软件、硬件或者软硬件协同的方法来使用计算资源,因其复杂性导致GPU资源利用不足,影响整体性能。
1.1 GPU体系架构
NVIDIA 第8 代GPUTuring 第一次使用GDDR6 DRAM内存,并引入了新的SM 体系架构,采用了可加速光线追踪的RT Core,以及可用于AI推理的全新Tensor Core[3]。虽然GPU架构经过一代代的变化,但是大致架构改动不大。
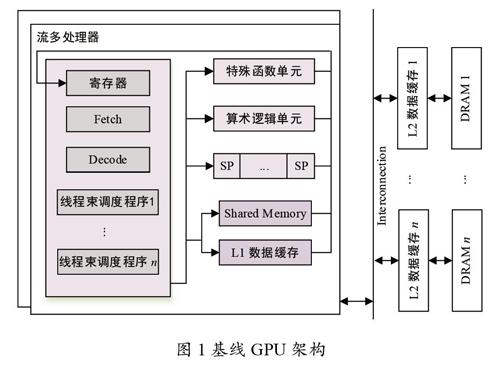
图1 是一个基线GPU 架构图,GPU 有多个流多处理器(Streaming Multiprocessor,SM),在每个SM 中,计算资源包括算术逻辑单元(ALU)、特殊函数单元(SFU)以及寄存器,片上内存资源包括只读纹理缓存和常量缓存、L1 数据缓存(D-cache)和共享内存。在多个SMs之间共享统一的一个L2缓存[1]。GPU 中有多个处理器核SP,在一个时刻可以并行处理多个数据。寄存器(Reg File)是GPU 內部的存储单元,是有限存储容量的高速存储部件,用来暂存指令、数据和位址。线程束调度程序(Warp Scheduler)负责调度一个SM 中的Warp。Warp 是GPU 执行程序时的调度单位,Warp 大小为32,32 个thread组织成一个Warp。
1.2 线程调度算法
GPU具有高效并行性和灵活的可编程性等特点,在处理数据方面有极大的优势。面对不同的应用和资源需求,为了更好地管理计算资源,为线程分配资源,目前主要有先到先服务(FCFS)[4]、轮询(RR)[5]、优先级调度(PSA)[6]和最短线程优先(SJF)[7]调度算法。
在出现长线程时,从另一方面说,尽可能地提高线程的执行数,也可提高系统的吞吐量。因此,对线程进行预处理,预估线程的执行时间变得极为重要。另一方面,由于SJF算法本身的缺陷,导致执行时间较长的线程长时间得不到响应,降低了系统吞吐量和整体性能。
因此,从线程调度的角度,提出了TQDP,难点在于线程的预处理上,根据线程的执行时间进行排序,以及需要考虑执行时间较长线程的调度。
2 TQDP
队列线程是按照一定的管理策略分配计算资源,通过科学合理的方法提高线程的响应率和系统的性能。
2.1 TDQP
按照线程预处理获得的执行时间从短到长加入到等待队列,按照队列中优化后的顺序执行线程能更好地提升系统的吞吐量和性能。在对线程进行预处理时,其中队列中线程的执行顺序需要比较线程的执行时间和到达时间。如果某一两个线程执行时间均是0.01 ms,那么就比较线程的到达时间。
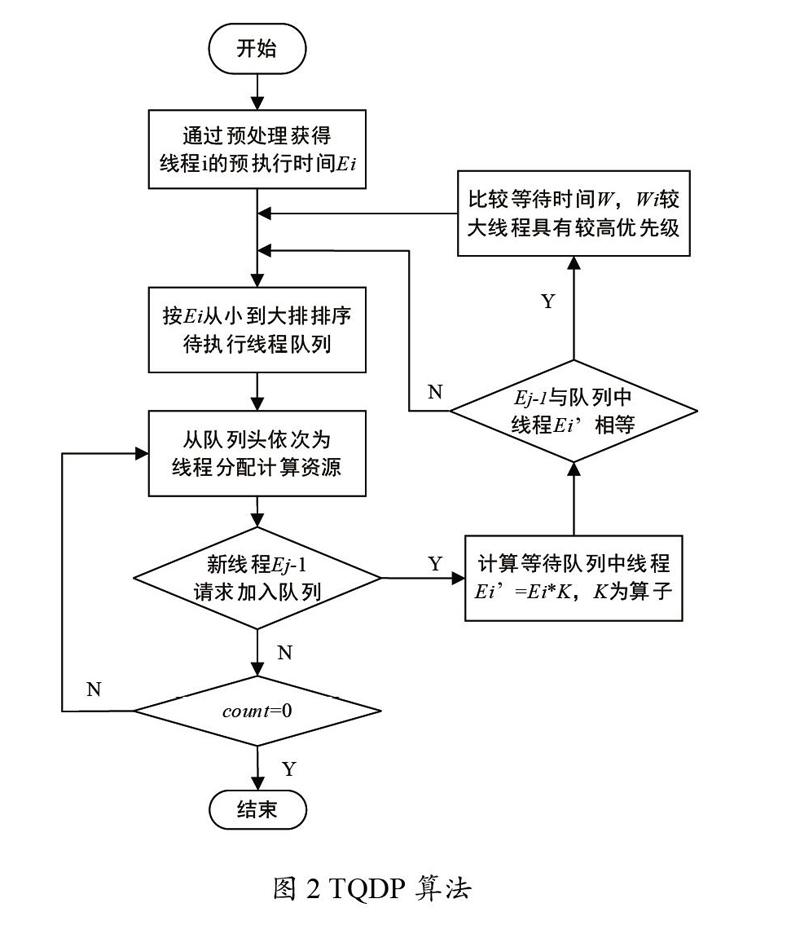
TQDP 算法流程如图2所示,通过获取待执行线程的相关信息,线程执行时间和等待时间,在队列中按从小到大排序。在执行过程中有新的线程请求加入队列,队列中线程执行时间乘以算子( <1, 的取值会在实验部分说明), '= * 计算,再根据新线程-1的大小插入等待队列中,队列中出现相同,则比较不同线程的等待时间的大小,较大线程的顺序有较大的优先级。
2.2 TQDP算法模型
TQDP 方法中, 为所有线程执行时间之和, 为线程的到达时间(提交时间), 为线程的服务时间(执行时间), 为线程的周转时间, 为线程的等待时间。线程个数为, 为当前系统时间。用三参数法,表示为,在一个GPU 中多个SM 上,到达时间各不相同的线程,获取总的最小执行时间,即:
2.3 TQDP的实现
TQDP的具体方案为:
①对于待执行的kernel进行预处理,获取线程执行时间、到达时间、等待时间等相关参数信息,存储在不同的数组中,将获取的执行时间在待执行队列中进行排序,更新线程的执行队列。
②新加入的线程,在插入到执行队列中之前,执行时间数组中对执行时间设置算子,然后将新线程插入到队列中,并更新执行队列。
③如果执行时间数组中对应线程出现相同数值,则在等待时间数组中寻找对应线程的等待时间,比较2 个线程的等待时间,并将等待时间较长的线程优先级提高。
④按照更新的执行队列中的线程顺序,系统执行kernel。
3 实验
本文的实验环境为GPGPU-Sim3.2.2 [8],算法的框架为OpenCL,配置的参数如表1 所示。实验中的取值对执行队列中线程执行顺序优化的影响以及对于系统执行算法的影响,根据执行队列中线程执行时间大小、线程等待时间长短以及提高线程优先级等因素考虑后将取值设定为0.75。实验比较的性能相关参数有加权加速比(Weighted Speedup)、系统吞吐量(System Throughput,STP)、平均标准化周转时间(Average Normalized Turnaround Time,ANTT)等,主要使用Weighted Speedup 和ANTT 评估,Weighted Speedup 是运行kernel的加速比之和,将其定义为并行执行中的规范化IPC,而非独立执行中的IPC,并纳入了公平性(Fairness)。测试的基准程序集为Parboil及Rodinia等。
图3 显示了不同方法对10 个不同基准测试的WeightedSpeedup 的影响。整体而言,与参考文献[9] 中的方法++DynCTAT,Mod+Bypass,PBS,BF,opt相比,本文所提出的方法TQDP 明显优于其他方法。就平均结果,++DynCTAT,Mod+Bypass,PBS,BF,opt 与TQDP 分别为1.087,1.095,1.098,1.204,1.235,1.245,TQDP比其他方法分别提高了14%,13.7%,13.3% ,3.4% ,8.8% 。TQDP 在BLK_ BFS2、FWT_TRD、JPEG_CFD、SCP_TRD 等基准测试中表现的Weighted Speedup较于其他方法有明显提升。TQDP 一开始对于线程进行了预处理,获取了很多需要的参数信息,在之后的执行过程中,大大减少了系统对于线程的处理过程。
与++DynCTAT、Mod+Bypass,PBS,BF,opt 相比,本文所提出的方法TQDP 在BFS2_FFT,FFT_TRD,FWT_TRD,JPEG_CFD,JPEG_LIB等基准测试表现出的Fairness 明显优于其他方法,如图4 所示。正如之前介绍的,TQDP 对于长短线程都有考虑到,特别是对于长线程在执行过程中长时间得不到响应的情况,通过TQDP 算法,可以大大降低发生的概率,正是由于考虑到了长线程的调度情况,因此TQDP 的Fairness 参数表现结果好。
由于基準测试程序集数量过多,本文将所用的基准测试分为了2 类:计算密集型和内存密集型,分别表示为C 和M,然后排列了3 种组合:C+M,C+C,M+M。如图5 所示,对于STP,TQDP、SMK、SMK-(P+W)分别为1.28,1.38,1.40,与文献[11]中的方法SMK、SMK-(P+W)相比,TQDP 分别提高了8.5%和1.4%。对于C+C、M+M,TQDP都有明显的改进,目的就是通过提升系统吞吐量来提高系统性能,从实验结果来说,这一目的是达到了。TQDP 算法本身是从提高线程执行数、提升系统吞吐量的角度对队列中线程执行顺序进行优化。
ANTT平均标准化周转时间越低越好,意味着响应时间更接近于独立执行。吞吐量STP很好,那么ANTT 也应该很好。正如之前所说,对于STP,与SMK 和SMK-(P+W)相比,TQDP分别提高了8.5%和1.4%,而且对于ANTT,如图6 所示,分别为1.85,1.60,1.50,与SMK和SMK-(P+W)相比,TQDP 分别提高了18.9%和6.3%。因为,TQDP 对于吞吐量和公平性都是好的,所以它的ANTT 值是最低的。另一方面,SMK在STP 方面很弱,因此在ANTT方面也很弱。结合之前的实验结果,图5中TQDP表现的结果优于其他2种方法,因此在图6中,TQDP 的实验结果也优于其他方法,符合预期。
总之,实验结果表明本文提出的方法TQDP优化了系统性能。实验结果证明,TQDP 与++DynCTAT,Mod+Bypass,PBS,BF,opt 相比,Weighted Speedup 比其他方法分别提高了14%,13.7%,13.3%,3.4%,8.8%,TQDP 在预处理时减少了后面系统对线程的处理过程。与SMK 和SMK-(P+W)相比,STP 分别提高了8.5%和1.4%,TQDP 主要的目标是对线程队列中线程执行顺序的优化,提高线程执行数,提升系统吞吐量,优化系统性能。
4结束语
本文证明了提出的方法TQDP 确实可以优化系统性能。在测试的大部分基准测试中,TQDP 表现优秀,实验结果表现基本与预期一致,实验目的基本实现,从线程角度出发,通过优化线程执行队列的执行顺序,提高线程的执行次数,缩减程序执行时间,提升系统性能。就测试的相关参数平均而言,TQDP 相比其他方法都得到了很大的提升,但仍有不足之处,比如算法中对于算子数值的设置,简单考虑了算子的取值范围,粗略设定了数值,并没有深入研究设置不同数值对于算法的影响,以及不同程度大小算子对于线程执行队列的优化效果如何。在之后的工作中,将会从这一方面进行考虑,对算子的数值进行优化,探究算子的不同取值对于本算法优化效果影响。
猜你喜欢
软件导刊(2017年1期)2017-03-06
计算机应用(2016年12期)2017-01-13
科学与财富(2016年15期)2016-11-24
大经贸(2016年9期)2016-11-16
中国新通信(2016年16期)2016-10-18
计算机辅助工程(2016年3期)2016-08-01
电脑知识与技术(2016年14期)2016-06-30
科技视界(2016年11期)2016-05-23
电脑知识与技术(2015年12期)2015-07-18
湖南大学学报·自然科学版(2015年2期)2015-04-20
