
FISS GAN: A Generative Adversarial Network for Foggy Image Semantic Segmentation
2021-07-26 07:24KunhuaLiuZihaoYeHongyanGuoDongpuCaoLongChenSeniorandFeiYueWang
Kunhua Liu, Zihao Ye, Hongyan Guo,, Dongpu Cao,,Long Chen, Senior, and Fei-Yue Wang,
Abstract—Because pixel values of foggy images are irregularly higher than those of images captured in normal weather (clear images), it is difficult to extract and express their texture. No method has previously been developed to directly explore the relationship between foggy images and semantic segmentation images. We investigated this relationship and propose a generative adversarial network (GAN) for foggy image semantic segmentation (FISS GAN), which contains two parts: an edge GAN and a semantic segmentation GAN. The edge GAN is designed to generate edge information from foggy images to provide auxiliary information to the semantic segmentation GAN.The semantic segmentation GAN is designed to extract and express the texture of foggy images and generate semantic segmentation images. Experiments on foggy cityscapes datasets and foggy driving datasets indicated that FISS GAN achieved state-of-the-art performance.
I. INTRODUCTION
ENVIRONMENTAL perception plays a vital role in the fields of autonomous driving [1], robotics [2], etc., and this perception influences the subsequent decisions and control of such devices [3]–[5]. Fog is a common form of weather, and when fog exists, the pixel values of foggy images are irregularly higher than those of clear images. As a result, the texture of foggy images is less than that of clear images. There are already many methods for semantic segmentation of clear images, which can extract and express the features of clear images and achieve good semantic segmentation results. However, the performance of these methods on foggy images is poor. This poor performance occurs because current methods cannot efficiently extract and express the features of foggy images. Moreover, foggy image data are not sparse, and the current excellent work [6], [7] on sparse data cannot be used. Therefore, to date, researchers have developed two ways to address this problem:
A. Defogging-Segmentation Methods
In this method, first, a foggy image is converted to a fogfree image by defogging algorithms, and then the restored image is segmented by a semantic segmentation algorithm.Therefore, the defogging-segmentation method can be separated into two steps.
Step 1:Fog removal. According to the classic atmosphere scattering model [8], [9], a fog-free image can be represented by a foggy image
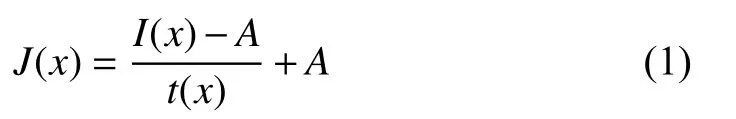
whereJ(x) is the fog-free image;I(x) is the foggy image;t(x)is the transmission map; andAis the global atmospheric light.
Step 2:Semantic segmentation of fog-free images. When semantic segmentation is performed, the algorithms’ inputs may be the fog-free image and its auxiliary information or only the fog-free image. Therefore, the problem of semantic image segmentation after defogging can be expressed as

whereg(x) is auxiliary information; if there is no auxiliary information,g(x) is self-mapping;f(·) is the relation betweenJ(x) andg(x);F(·) is flection fromf(J(x),g(x)) toS(x); andS(x)is the semantic segmentation image.
B. Semantic Segmentation Method Based on Transfer Learning
In this method, first, a semantic segmentation model is trained based on clear images. Then, based on the trained semantic segmentation model and transfer learning, the semantic segmentation model is trained on foggy images. The semantic segmentation method based on transfer learning can also be separated into two steps.
Step 1:Training the semantic segmentation model with clear images. The method used to obtain the semantic segmentation model is the same as that shown in (2).However, the inputs for this method are clear images and their auxiliary information or only clear images. The training model can be expressed as

whereC(x) are the clear images,Mis the semantic segmentation model of clear images, andg(x) is the auxiliary information mentioned above.
Step 2:Training the transfer learning model with foggy images. Using the clear images as the source domain and foggy images as the target domain, the semantic segmentation model can be trained with foggy images based on the model above
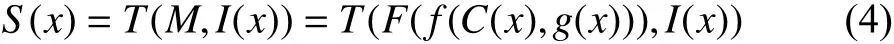
whereT(·) is a transfer learning method, and the other terms are the same as defined above.
These two methods can achieve semantic segmentation results for foggy images; however, they are based on defogged images or semantic segmentation models trained with clear images. Without this information, these two methods are useless. This study focuses on a new semantic segmentation method that directly explores the mapping relationship between foggy images and the resulting semantic segmentation images. The mathematical model can be expressed as follows:

It is challenging to solve (5). The motivation of this paper is to explore a semantic segmentation method that can efficiently solve (5), which is an efficient method to express the mapping relationship between foggy images and the resulting semantic segmentation images.
A generative adversarial network (GAN) is an efficient semantic segmentation method. Lucet al. [10] first explored the use of a GAN for clear image semantic segmentation because a GAN could enforce forms of higher-order consistency [11]. Subsequently, [12] and [13] also provided GANs for the semantic segmentation of clear images and achieved state-of-the-art performance. In this paper, we also explore the semantic segmentation method for foggy images based on a GAN. Additionally, based on the “lines first, color next” approach, edge images are used to provide auxiliary information for clear image inpainting [14]. This method has been shown to greatly improve the quality of clear image inpainting. In this paper, we also analyze the foggy image semantic segmentation (FISS) problem using the “lines first,color next” approach and use edge images as auxiliary information. Specifically, we first obtain the edge information of foggy images and then obtain the semantic segmentation results for foggy images under the guidance of this edge information. Based on the above ideas, a two-stage FISS GAN is provided in this paper. The main contributions of this paper are as follows:
1) We propose a novel efficient network architecture based on a combination of concepts from U_Net [15], called a dilated convolution U_Net. By incorporating dilated convolution layers and adjusting the feature size in the convolutional layer, dilated convolution U_Net has shown improved feature extraction and expression ability.
2) A direct FISS method (FISS GAN) that generates semantic segmentation images under edge information guidance is proposed. We show our method’s effectiveness through extensive experiments on foggy cityscapes datasets and foggy driving datasets and achieve state-of-the-art performance. To the best of our knowledge, this is the first paper to explore a direct FISS method.
The structure of this paper is as follows: Section I is the introduction; Section II introduces the work related to foggy images and semantic segmentation methods; Section III describes FISS GAN in detail; Section IV describes the experiments designed to verify the performance of FISS GAN; and Section V summarizes the full paper.
II. RELATED WORk
A. Foggy Images
Most studies on foggy images are based on defogging methods. Image defogging methods can be divided into traditional defogging methods and deep learning-based defogging methods. Meanwhile, according to the different processing methods, traditional defogging methods can be divided into image enhancement defogging methods and physical model-based defogging methods. The methods based on image enhancement [16]–[18] do not consider the fog in the image and directly improve contrast or highlight image features to make the image clearer and achieve purpose of image defogging. However, when contrast is improved or image features are highlighted, some image information will be lost, and images defogged by this method will be obviously distorted.
The methods based on atmospheric scattering models[19]–[25] consider the fog in the image and study the image defogging mechanism or add other prior knowledge (scene depth information [26], [27]) to produce a clear image.Among these methods, the classic algorithms are the dark channel defogging method proposed by Heet al. [23], an approach based on Markov random fields presented by TAN[21], and a visibility restoration algorithm proposed by Taralet al. [28]. The image defogging methods based on atmospheric scattering models provide better defogging results than those obtained by image enhancement. However,the parameters used in the methods that utilize atmospheric scattering models to defog an image, such as the defogging coefficient and transmittance, are selected according to experience, so the resulting image exhibits some distortion.
With the development of deep learning (DL), recent research has increasingly explored defogging methods based on DL. Some researchers obtained the transmission map of a fog image through a DL network and then defogged the image based on an atmospheric scattering model [29]–[32]. This kind of method does not need prior knowledge, but its dependence on parameters and models will also cause slight image distortion. Other researchers designed neural networks to study end-to-end defogging methods [33]–[38]. Moreover,with the development of GANs in image inpainting and image enhancement, researchers have also proposed image defogging methods based on GANs [39]–[44], which greatly improve the quality of image defogging. In addition to studies on defogging, researchers have studied methods for obtaining optical flow data from foggy images [45].
B. Semantic Segmentation
Semantic segmentation is a high-level perception task for robotic and autonomous driving. Prior semantic segmentation methods include color slices and conditional random fields(CRFs). With the development of DL, traditional DL-based semantic segmentation methods have greatly improved the accuracy of semantic segmentation. The fully convolutional network (FCN) [1] is the first semantic segmentation method based on traditional DL. However, due to its pooling operation, some information may be lost. Therefore, the accuracy of semantic segmentation with this method is low.To increase the accuracy of semantic segmentation, many improved semantic segmentation frameworks [15], [47]–[56]and improved loss functions [51] were subsequently proposed.Most traditional DL-based semantic segmentation methods are supervised. Supervised semantic segmentation methods can achieve good segmentation results, but they require a large amount of segmentation data. To solve this problem, Hoffmanet al. [57] and Zhanget al. [58] proposed training semantic segmentation models through a synthetic dataset where the new model is trained to predict real data by transfer learning.
Lucet al. [10] introduced GAN into the field of semantic segmentation. The generator’s input is the image that needs to be segmented, and the output is the semantic segmentation classification of the image. The discriminator’s input is the ground truth of the semantic segmentation classification or the generated semantic segmentation classification, and the output is the judgment result of whether the input is a true value. In addition, considering GAN’s outstanding performance in transfer learning, researchers proposed a series of semantic segmentation GANs based on transfer learning. Pix2Pix [12]is a typical GAN model for semantic segmentation that considers semantic segmentation as one image-to-image translation problem and builds a general conditional GAN to solve it. Because domain adaptation cannot capture pixel-level and low-level domain shifts, Hoffmanet al. [13] proposed cycle-consistent adversarial domain adaptation (CYCADA),which can adapt representations at both the pixel level and feature level and improve the precision of semantic segmentation.
An unsupervised general framework that extracts the same features of the source domain and target domain was proposed by Murezet al. [59]. To address the domain mismatch problem between real images and synthetic images, Honget al. [60] proposed a network that integrates GAN into the FCN framework to reduce the gap between the source and target domains; Luoet al. [61] proposed a category-level adversarial network that enforces local semantic consistency during the trend of global alignment. To improve performance and solve the limited dataset problem of domain adaptation, Liet al. [62] presented a bidirectional learning framework of semantic segmentation in which the image translation model and the segmentation adaptation model were trained alternately and while promoting each other.
The approaches above can directly address clear images and achieve state-of-the-art performance. However, these methods cannot handle foggy images very well because of their weak texture characteristics. To the best of our knowledge, there has been no research on a direct semantic segmentation method for foggy images.
III. FOGGY IMAGE SEMANTIC SEGMENTATION GAN
Unlike current semantic segmentation GANs [10], [12],which handle clear images and contain one part, FISS GAN(Fig. 1) handles foggy images and contains two parts: the edge GAN and the semantic segmentation GAN. The purpose of the edge GAN is to obtain the edge information of foggy images to assist with the semantic segmentation tasks. The edge directly achieved from foggy images contains all detailed edge information, while the edge information used for semantic segmentation is only its boundary information.Therefore, we use the edge information achieved from the ground truth of the semantic segmentation image as the ground truth in our edge GAN instead of the edge information from the clear image.
To clarify, we tested these two kinds of edges by the Canny algorithm [63]. The visual differences between the two edges are shown in Fig. 2. As seen in Fig. 2, the edge achieved directly from the foggy image contains too much useless information for semantic segmentation. In contrast, another edge is just the boundary of its semantic segmentation, which is appropriate for semantic segmentation.
The purpose of the semantic segmentation GAN is to accomplish the semantic segmentation of foggy images. The inputs of the semantic segmentation GAN are foggy images and edge images achieved from the edge GAN, and its outputs are the semantic segmentation results of foggy images.Therefore, based on the mathematical model for the semantic segmentation of foggy images (formula (5)), the mathematical model of FISS GAN can be expressed as follows:

whereF(·) is the semantic segmentation GAN;f(·) is the concatenate function;I(x) is the foggy image; andEgan(x) is the edge information achieved from the edge GAN.
A. Dilated Convolution U_Net
To further improve feature extraction and expression abilities, we learn convolution and deconvolution features by combining thoughts from U_Net [15] and propose a new network architecture, namely, dilated convolution U_Net(Fig. 3). Dilated convolution U_Net consists of three convolution layers (C1,C2, andC3), four dilated convolution layers (DC), and three fusion layers (f(C3,DC),f(C2,CT1),andf(C1,CT2)). The dilated convolution U_Net contains 4 dilated convolution layers and can result in a receptive field of the dilation factor of 19. Fusion layers are the layers that concatenate features from the dilated convolution results or transposed convolution results with the corresponding convolution layer. Similar to the fusion approach of U_Net[15], we divided the fusion operation into three steps:

Fig. 1. The pipeline of FISS GAN.

Fig. 2. The visual differences.
Step 1:FuseC3 andDCto obtainf(C3,DC) and deconvolutef(C3,DC) to obtainCT1;
Step 2:FuseC2 andCT1 to obtainf(C2,CT1) and deconvolutef(C2,CT1) to obtainCT2;
Step 3:FuseC1 andCT2 to obtainf(C1,CT2).
The fusion approach of this paper is a concatenation operation. Three convolution layers and four dilated convolution layers are used to extract input features, and two deconvolution layers are used to express the extracted features. The size of each layer feature is shown in Fig. 3.

Fig. 3. Structure of dilated convolution U_Net.
The differences between dilated convolution U_Net and U_Net [15] are as follows: 1) Dilated convolution U_Net incorporates dilated convolution layers to improve feature extraction ability. 2) In feature fusion, because the feature sizes of the convolution layers and deconvolution layers in U_Net [15] are different, the features of the convolution layers are randomly cropped, and this operation leads to features that do not correspond. Thus, some information from the fusion image might be lost in the fusion step. In the dilated convolution U_Net [15] proposed in this study, the feature sizes of the convolution layers and their corresponding deconvolution layers are the same, which means that the features of the convolution layers can be directly fused with the features of the deconvolution layers. Thus, no information will be lost in the fusion step. 3) U_Net achieves image feature extraction and expression from the convolution layers,maximum pooling layers, upsampling layers (first the bilinear layer, then the convolution layer or transformed convolution layers) and convolution layers. U_Net consists of 23 convolution layers, 4 maximum pooling layers and 4 upsampling layers. According to the convolution kernel and step size of U_Net, the number of parameters that need to be trained is 17 268 563. The dilated convolution U_Net proposed in this paper achieves image feature extraction and expression by convolution layers, dilated convolution layers,transformed convolution layers and convolution layers. This method consists of 3 convolution layers, 4 dilated convolution layers and 2 transformed convolution layers. With the convolution kernel and step size of dilated convolution U_Net(Table I), the number of parameters that need to be trained is 4 335 424. The more parameters that need to be trained, the more computations that are required. Therefore, dilated convolution U_Net has fewer network layers, fewer parameters, and less computation than U_Net.

TABLE I PARAMETERS OF G1 AND G2
B. Edge GAN
The architecture of the edge GAN, as shown in Fig. 1,includes the edge generatorG1 and edge discriminatorD1.The purpose ofG1 is to generate an edge image similar to the ground truth edge image.G1 is composed of the dilated convolution U_Net and one convolution layer (G1_C3).Because the edge image is a set of 0 or 255 pixel values, it can be expressed by single-channel image data. Therefore, the size ofG1_C3 is 1×H×W. The purpose ofD1 is to determine whether the generated edge image is the ground truth image and provides feedback (please refer to “the false binary cross entropy (BCE) loss fromD1Loss” below) to the edge generatorG1 to improve the accuracy of the generated image.The design ofD1 is similar to that of PatchGAN [64], which contains five standard convolution layers.
The loss function plays an important role in the neural network model. This function determines whether the neural network model converges or achieves good accuracy. The edge GAN includesG1 andD1. The loss function includes the loss function ofG1 and that ofD1. The inputs ofD1 are the ground truth of the edge images and the edge images generated fromG1, where the ground truth of the edge image is achieved by the Canny algorithm [63] from the semantic segmentation image. In addition, the output ofD1 is whether its input is true. Specifically, the output is the probability matrix (0 ~ 1).
The value of the probability matrix is expected to be close to 1 after the ground truth passes throughD1, which means that this edge image is the ground truth (the size of the matrix is the same as the size of the output matrix, and the label value is 1). In contrast, the value of the probability matrix of the generated edge image after passing throughD1 is close to 0,which means that this edge image is a generated edge image(the size of the matrix is the same as the size of the output matrix, and the label value is 0). Therefore, the discriminator loss function of the edge GAN (D1 loss) is designed as the BCE loss of the discriminator output and its corresponding label.
Since the output ofD1 includes the true value probability obtained by taking the ground truth of the edge image as the input and the false value probability obtained by taking the generated edge image as the input, theD1 loss has two parts:the BCE loss between the true value probability and 1,namely, true BCE loss, and the BCE loss between the false value probability and 0, namely, false BCE loss. Specifically,D1 loss is the average of true BCE loss and false BCE loss.

The features of theD1 convolution layer can adequately express the ground truth of the edge image or the generated edge image. Therefore, we achieveG1’s ability to generate images by narrowing the gap between the feature of the ground truth edge image and the feature of the generated edge image. The gap between the feature of the ground truth edge image and the feature of the generated edge image is calculated byL1 losses. Meanwhile, the false BCE loss fromD1Lossindicates the quality of the image generated byG1. A large false BCE loss indicates that the generated edge image is different with the ground truth image. A small false BCE loss indicates that the generated edge image is close to the ground truth image. A false BCE loss partly reflects the quality of the generator, and its optimization goal is consistent with that of the generator, which is to reduce its value. Therefore, it is considered part of the generator loss function.

C. Semantic Segmentation GAN
Similar to the edge GAN, the semantic segmentation GAN includes the semantic segmentation generatorG2 and semantic segmentation discriminatorD2. The goal ofG2 is to generate semantic segmentation classifications with the same ground truth as the semantic segmentation classifications.G2is composed of the dilated convolution U_Net and one convolution layer (G2_C3). The goal of the semantic segmentation GAN is to divide the foggy images intonclasses. Therefore, the size ofG2_C3 isn×H×W. The purpose ofD2 is to judge whether the generated semantic segmentation image is the ground truth image and provide feedback (please refer to “the false BCE loss fromD2Loss”below) to the semantic segmentation generatorG2 so that it can improve the accuracy of the generated image. The structure ofD2 is the same as that ofD1, which contains 5 standard convolution layers.
The input ofD2 is the ground truth of the semantic segmentation image of the foggy image and the semantic segmentation image generated byG2, and its output is the probability matrix (0 ~ 1), which indicates whether the input is ground truth. Therefore, similar to theD1 loss of the edge GAN, the discriminator loss function of the semantic segmentation GAN (D2 loss) includes two parts: the BCE loss between true value probability and 1, namely, true BCE loss,and the BCE loss between false value probability and 0,namely, false BCE loss. Specifically,D2 loss is the average of true BCE loss and false BCE loss.


The loss functions of edge GANs are mathematical operations (linear operations) of several existing loss functions, which have all been proven to be convergent when proposed and are commonly used in GANs. Therefore,mathematical operations (linear operations) of several existing loss functions are also convergent, as are the loss functions of the semantic segmentation GAN.
IV. EXPERIMENTS
A. Experimental Setting
The foggy cityscapes dataset [65] is a synthetic foggy dataset with 19 classifications (road, sidewalk, building, wall,etc.) for semantic foggy scene understanding (SFSU). It contains 2975 training images and 500 valuation images withβ= 0.005 (βis the attenuation coefficient; the higher the attenuation coefficient is, the more fog there is in the image),2975 training images and 500 valuation images withβ= 0.01,and 2975 training images and 500 valuation images withβ=0.02. Due to the differences in the attenuation coefficients, we separate the foggy cityscapes dataset into three datasets.Dataset 1 is composed of 2975 training images and 500 valuation images withβ= 0.005. Dataset 2 is composed of 2975 training images and 500 valuation images withβ= 0.01,and Dataset 3 is composed of 2975 training images and 500 valuation images withβ= 0.02. The corresponding semantic segmentation ground truth contains semantic segmentation images with color, semantic segmentation images with labels,images with instance labels and label files with polygon data.The ground truth of edge images is obtained from semantic segmentation images with color and by the Canny algorithm[63].
The foggy driving dataset [65] is a dataset with 101 realworld images that can be used to evaluate the trained models.We separately use Dataset 1, Dataset 2, and Dataset 3 to train the models and use the foggy driving dataset [65] as the test set to test the trained models. Due to the lack of training data and validation data, we carry out random flip, random crop,rotation, and translation operations on the data during training and verification to avoid the overfitting phenomena.
The activation function of the dilated convolution U_Net is ReLU [66], while that ofG1_CT3 andG2_CT3 is sigmoid.The activation function of the first four layers inD1 andD2 is LeReLU [67], and the parameter value is 0.25, while that of the last layer is sigmoid. The optimization algorithm of the edge GAN and semantic segmentation GAN is Adam [68].The experiment’s input size is 256 × 256, and the number of training epochs is 100. The edge GAN and semantic segmentation GAN architecture parameters are shown in Tables I and II.

TABLE II PARAMETERS OF D1 AND D2
B. Qualitative and Qualitative Experimental Results
To the best of our knowledge, there is no direct semantic segmentation method for foggy images for comparison;however, OCR [48] and HANet [49] have achieved remarkable results on cityscapes datasets in public without additional training data. Among them, HANet [49] achieved the best performance. To verify the performance of FISS GAN, we compare it with OCR [48] and HANet [49]. Our training and validation data come from the foggy cityscapes dataset mentioned above, and we separately train OCR [48],HANet [49] and FISS GAN on Dataset 1, Dataset 2, and Dataset 3. Meanwhile, we use the foggy driving dataset as the test data.
The qualitative experimental results on Dataset 1, Dataset 2,and Dataset 3 are separately shown in Figs. 4–6. The semantic segmentation effect of FISS GAN is better than that of OCR[48] and HANet [49] on each dataset. To further determine the performance of each model, the mean intersection over union(IoU) score of each model is calculated in this paper (Table III).As shown in Table III, the mean IoU scores of FISS GAN on Dataset 1, Dataset 2, and Dataset 3 are 69.37%, 65.94%, and 64.01%, respectively, which are all higher than the corresponding scores of OCR [48] and HANet [49], and FISS GAN achieved state-of-the-art performance. These results indicate that FISS GAN can extract more features from a foggy image than OCR [48] and HANet [49]. Meanwhile,regardless of the method, the mean IoU score on Dataset 1 was higher than that on Dataset 2 and Dataset 3. According to our analysis, the ultimate reason for this difference is that images in Dataset 1 have small attenuation coefficients, which means the image pixels from Dataset 1 are smaller than those from Dataset 2 and Dataset 3, and the images in Dataset 1 have more texture than those in Dataset 2 and Dataset 3.Therefore, it is easier to extract and express the features of images in Dataset 1 than those of Dataset 2 and Dataset 3.
Additionally, we test the pixel accuracy of the edge GAN on each dataset. The qualitative experimental results of each dataset are shown in Fig. 7, and the quantitative experimental results of each dataset are shown in Table IV. The pixel accuracy of Dataset 1 is 87.79%, which is slightly larger than that of Dataset 2 and Dataset 3, which indicates that the edge GAN can efficiently generate edge images, and more edge features can be extracted from the dataset with less fog.
C. Convergence Process
We count the validation data of OCR [48], HANet [49] and FISS GAN to create a mean IoU diagram (Fig. 8) and loss diagram (Fig. 9) for each model. TheX-axis of both Fig. 8 and Fig. 9 is the epoch. TheY-axis of Fig. 8 is the mean IoU value,while theY-axis of Fig. 9 is the loss value. To be more specific, the loss value of OCR [48], HANet [49] were obtained from their open-source code, while the loss value of FISS GAN isG2Loss. As seen in Fig. 8, the mean IoU value of the verification data is not significantly different from that of the test data. Meanwhile, Fig. 9 shows that the loss of OCR[48], HANet [49] and FISS GAN tends to decrease or stabilize. Therefore, the OCR model [48], HANet model [49]and FISS GAN model are all convergent models.
D. Ablation Study
To verify that the dilated convolution in the dilated convolution U_Net can extract more features than the standard convolution, we separately use the dilated convolution and standard convolution (standard convolution U_Net) to train and test the FISS GAN (edge GAN and semantic segmentation GAN). The datasets (training and test datasets),FISS GAN parameters, and epoch numbers are the same as in the above experiments. The pixel accuracy and mean IoU are shown in Table V. As seen in Table V, regardless of the dataset, the pixel accuracy and the mean IoU achieved through dilated convolution U_Net are higher than those of standard convolution U_Net.
Additionally, to verify the edge effect on FISS GAN, we replace the edge achieved from the semantic segmentation images with edges achieved from foggy images and trained FISS GAN (edge GAN and semantic segmentation GAN)with the same experimental settings above. The pixel accuracy and mean IoU are shown in Table VI. As seen in Table VI,with the same dataset, the pixel accuracy and mean IoU achieved from the edges of semantic segmentation images are slightly higher than those obtained from the other methods.This experiment indicates that the edge achieved from the semantic segmentation images could provide more guided information than the edges achieved from foggy images.
V. CONCLUSIONS AND FUTURE WORk
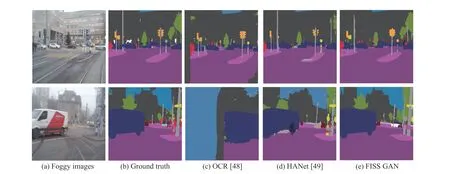
Fig. 4. The qualitative experimental results of each model on Dataset 1.

Fig. 5. The qualitative experimental results of each model on Dataset 2.

Fig. 6. The qualitative experimental results of each model on Dataset 3.
Currently, semantic segmentation methods for foggy images are based on fog-free images or clear images, which do not explore the relation between foggy images and their semantic segmentation images. A semantic segmentation method (FISS GAN) has been proposed in this paper that can directly process foggy images. FISS GAN was composed of edge GAN and semantic segmentation GAN. Specifically, FISS GAN first obtained edge information from foggy images with edge GAN and then achieved semantic segmentation results with semantic segmentation GAN using foggy images and their edge information as inputs. Experiments based on foggy cityscapes and foggy driving datasets have shown that FISS GAN can directly extract the features from foggy images and achieve state-of-the-art results for semantic segmentation.Although FISS GAN can directly extract the features from a foggy image and realize its semantic segmentation, it cannot accurately segment a foggy image with a limited texture. In the future, we will focus on designing a more efficient feature extraction network to improve the accuracy of the semantic segmentation of foggy images.
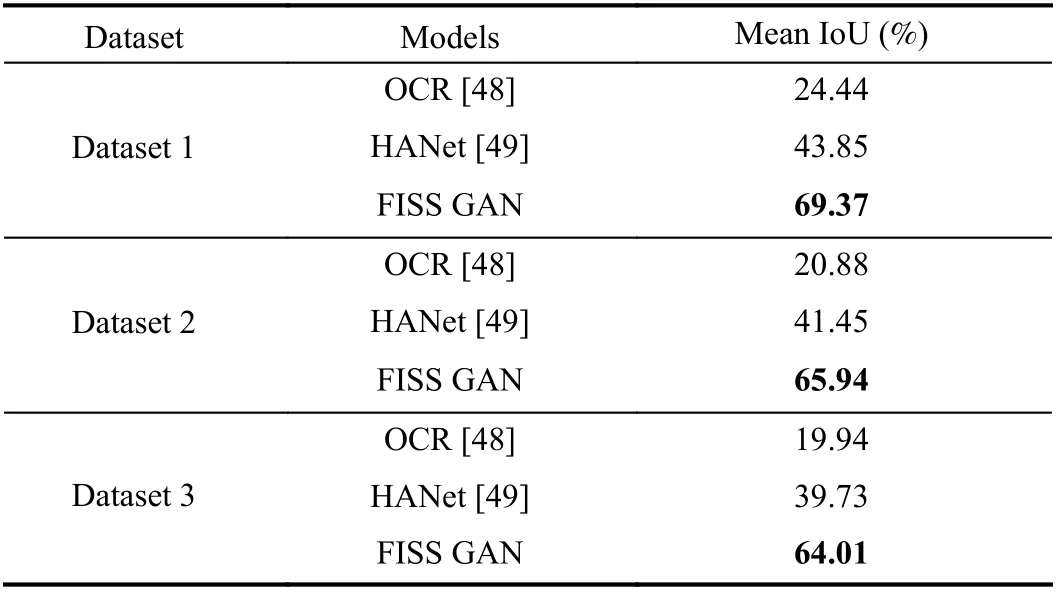
TABLE III THE MEAN IOU SCORE OF EACH MODEL

Fig. 7. The qualitative experimental results of each dataset.

TABLE IV THE QUANTITATIVE EXPERIMENTAL RESULTS OF EACH DATASET
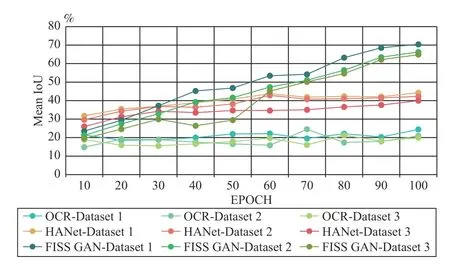
Fig. 8. Validation mean IoU for OCR [48], HANet [49] and FISS GAN.
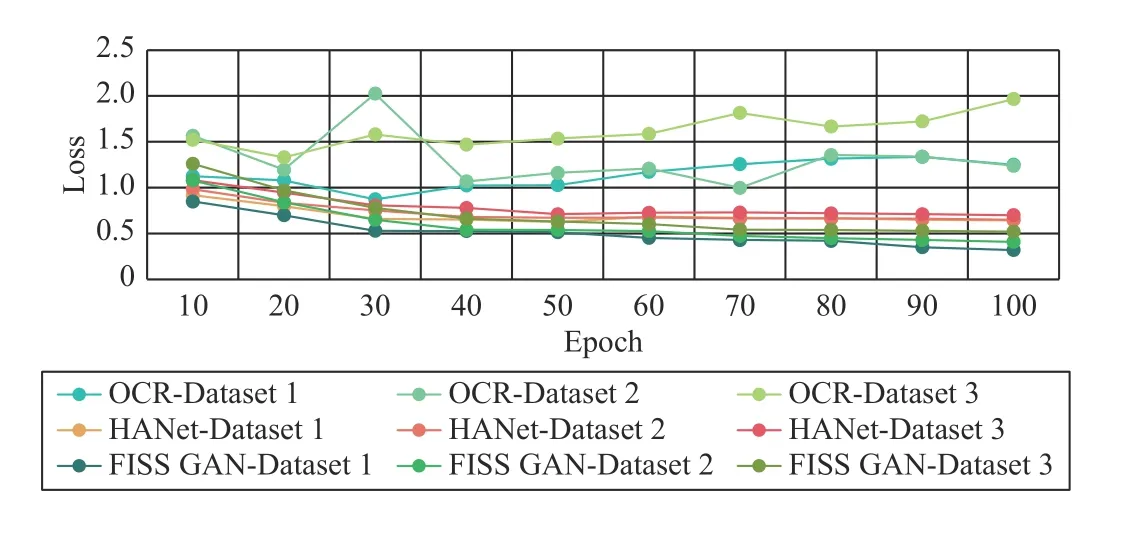
Fig. 9. Validation loss for OCR [48], HANet [49], and FISS GAN.

TABLE V COMPARISON RESULTS OF STANDARD CONVOLUTION U_NET AND DILATED CONVOLUTION U_NET (%)
 IEEE/CAA Journal of Automatica Sinica2021年8期
IEEE/CAA Journal of Automatica Sinica2021年8期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Subgradient Algorithm for Multi-Agent Optimization With Dynamic Stepsize
- Kernel Generalization of Multi-Rate Probabilistic Principal Component Analysis for Fault Detection in Nonlinear Process
- Learning Convex Optimization Models
- An RGB-D Camera Based Visual Positioning System for Assistive Navigation by a Robotic Navigation Aid
- Robust Controller Synthesis and Analysis in Inverter-Dominant Droop-Controlled Islanded Microgrids
- Cooperative Multi-Agent Control for Autonomous Ship Towing Under Environmental Disturbances