
基于双向编码表示预训练模型的舆情文本解析分类*
2021-07-26 15:42:24王亚珅李阳阳
科技与创新 2021年13期
金 昊,王亚珅,李阳阳
(中国电子科技集团公司电子科学研究院,北京 100041)
1 引言
随着人工智能、大数据及互联网技术的不断发展,舆情监测分析系统也从人工阶段逐渐趋于智能化和自动化。然而,随着网民数量的增加以及网络空间的扩大,所产生的数据也呈爆炸式的增长,Facebook每天处理的数据超过500 TB,阿里巴巴拥有的数据量超过100 PB(1 PB=1 024 TB),新浪微博用户数超过5亿,每天产生的微博数超过1亿条[1]。面对海量舆情数据,急需一种有效的文本分类算法来自动识别和分类舆情信息。
文本解析分类作为自然语言处理(NLP)的基本任务之一,目标是将文本分配到对应的类别中,通常基于已有数据集(文本以及文本对应的类别标签)训练出一个模型,并使其有一定的泛化能力,从而能够对新文本的类别进行预测。文本解析分类可被用于语义分析、问题分类以及话题分类等。最早期的文本分类方法通过设定专家规则、构建专家系统进行分类,但费时费力、覆盖范围和准确率十分有限。后来随着统计学的发展,文本分类问题重视人工特征的提取与浅层分类模型。近期,随着深度学习在图像领域突飞猛进的发展,一些技术,如卷积神经网络(CNN)[2]、递归神经网络(RNN)[3],也逐渐被应用在文本解析分类领域。
基于深度学习进行文本解析分类的方法将文本输入到一个深度网络,首先得到文本特征,然后将文本表示输入到分类器,最后通过softmax得到每个类别的概率。基于卷积神经网络(CNN)的模型可获得具有局部信息的文本特征;基于递归神经网络(RNN)的模型可得到具有长阶段信息的文本特征。在循环神经网络RNN中,LSTM和GRU常用于处理单词序列,同时一些变体也相继被提出,比如Tree-LSTM[4]和TG-LSTM[5]。基于卷积神经网络(CNN),VDCNN尝试构建一个更深的CNN网络用于文本分类[6];DCNN使用了一个动态的k最大池化机制[7];DPCNN旨在不增加很多计算损失的情况下加深网络[8]。此外,利用大量未标注数据的语言模型预训练方法可以有效学习通用语言特征。一些代表性模型有ELMo[9]、GPT[10]、BERT[11],均采用无监督方法在文本数据上训练神经网络语言模型。
总结来说,笔者们提出一种基于BERT预训练模型的舆情文本解析分类方法,将卷积神经网络运用到BERT的任务特定层中,弥补BERT模型忽略局部信息的缺点,使用自注意力机制来让最终的文本表示关注在文本的重要短语上,从而更有效地获取文本的局部信息,提升分类性能。在数据集上的实验结果也证明了此方法可以获得较好的舆情文本解析分类性能。
2 方法
2.1 方法框架
方法框架如图1所示。首先,进行词编码得到词向量;随后,对应词向量通过多层转换器编码,将输入特征映射成为一个上下文关联的特征向量;最后,为了捕获局部信息,使用卷积神经网络进一步编码并将编码后的信息输入到分类器预测舆情文本属性。
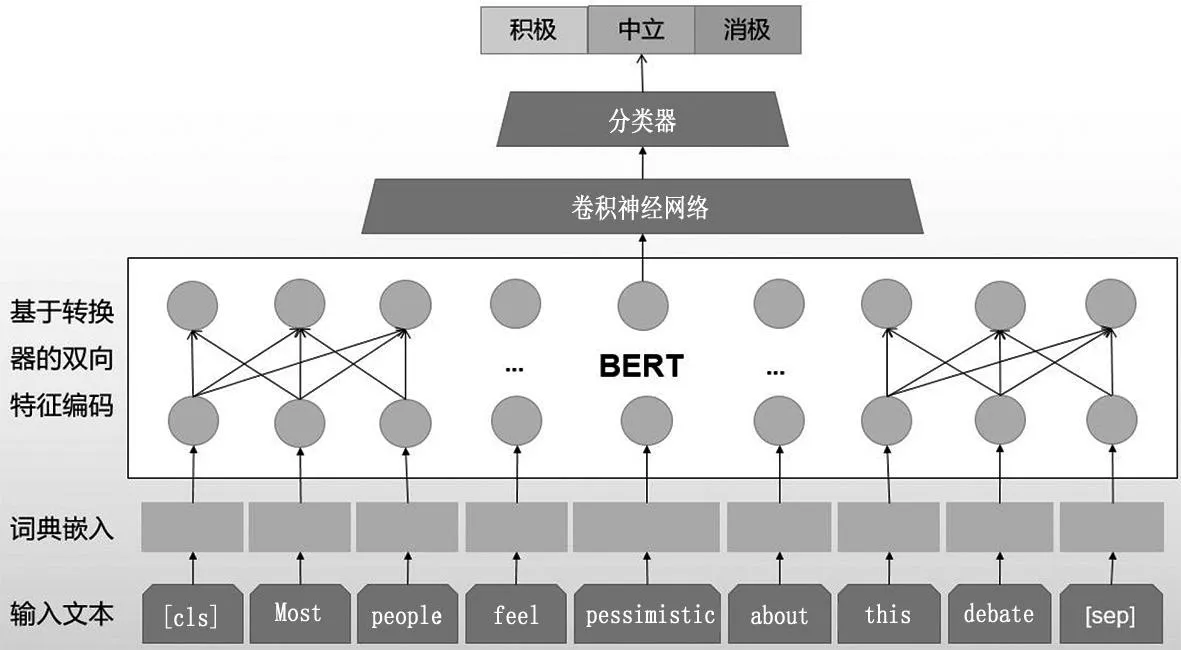
图1 方法框架
2.2 输入文本与词典嵌入
BERT模型的语言综合能力在文本分类上表现优异,但忽略了文本中某些片段或短语的信息。为了解决这一问题,通过联合调节所有层中的双向转换器(Transformer)来训练预训练深度双向特征表示。模型的输入是一个支持单句文本和句对文本的线性序列,其中句首用符号[CLS]来表示,句尾用符号[SEP]来表示。如果是句对,句子之间要添加符号[SEP]。输入特征由标志向量(Token)、分割向量(Token)和位置向量(Position)共同组成,分别代表了单词信息、句子信息和位置信息。对于给定的词,其输入表示是可以通过三部分特征嵌入求和组成。假设模型输入是一个有着个标志的序列,记为X={x1,x2,x3,…,xl}。
2.3 双向编码表示(BERT)
使用一个多层的双向转换器编码机将输入表示(即特征)映射到一个上下文嵌入向量的序列C={c,T,s},C∈Rd×1。c和s是分别对应于[CLS]和[SEP]的上下文表示。T={T1,T2,T3,…,Tm}对应于具有实际意义的单词标志的上下文表示,并且有M=l﹣2m。
输入符号序列(x1,…,xn)经过输入嵌入,得到映射后的序列Z=(Z1,…,Zn),然后经过编码器编码后输入解码器,一次一个元素地生成输出符号序列(y1,…,ym)。转换器架构如图2所示,转换器模型由编码器和解码器组成,使用堆叠式自注意力与全连接层[12],在产生下一个符号输出时,会将之前的输出用作附加输入,形成自回归的整体结构。

图2 转换器架构(图片来源于文献[12])
编码器:编码器由N=6个相同的层组成,每个层又由2个子层组成,分别是多头注意力机制和全连接的前馈网络层,并在2个子层中使用残余连接,然后进行层标准化。因此,每个子层的输出可以表示为LayerNorm{x+Sublayer(x)},其中Sublayer(x)是由子层实现的函数。模型中的所有子层与嵌入层输出的维度均为dmodel=512,用以促进这些残余连接。
解码器:解码器同样是由N=6个相同的层组成。与编码器中的2个子层不同,解码器还插入了对编码器的输出执行多头注意力的第三子层,其余与编码器类似,在每个子层中使用残余连接,然后进行层标准化。特别地,笔者们修改了解码器中的自注意力子层,即添加了掩码,以确保位置i的输出信息只依赖于位置i之前的输出,防止与后面的输出相关联。
注意力机制:一个注意力函数是一个查询和一组键值对输出的映射,其中查询、键、值和输出都是向量,通过查询与对应键的兼容性函数,可以获得每个值的权重,进而加权求和得到输出。
缩放点积注意力机制:“缩放点积注意力”的输入为三个不同的向量,查询、键以及值,其维度分别为dk、dk与dv,为每个向量计算查询与键的点积,再除以进行归一化,然后使用softmax函数,将函数输出点乘值,得到加权后的结果。同时计算一组查询的注意力函数,将它们打包成矩阵Q,键和值打包成矩阵K和V,则输出矩阵计算为:

加和点积(乘)注意力机制作为两种最常用的注意力函数,在dk很小的时候它们的执行效果相似,当dk较大的时候,如果不进行缩放则加性注意力表现更好,但点积注意力的计算速度更快。对于较大的dk值,点积会增大幅度,由于softmax函数使梯度过小,因此,将点积缩放,可抵消这种影响。加性注意力机制使用具有单个隐藏层的前馈网络来计算兼容性函数。虽然与点积注意力机制在理论上的复杂度相似,但点积注意力机制可以使用高度优化的矩阵乘法来实现,因此,在实践中点积注意要快得多,并且空间效率更高。
多头注意力机制:多头注意力机制是对查询、键和值做好h次不同的投影,映射的维度分别为dk、dk和dv,然后并行执行注意力函数,将不同的结果拼接在一起,最后通过线性映射输出,得到最终值。通过多头注意力,模型可以在不同的表示子空间里学习到相关的信息。对于单头注意力,平均值抑制了这一点。

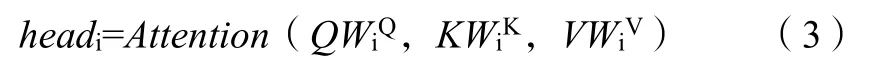
2.4 卷积神经网络
为了捕获文本的局部信息,比如短句和短语,采用卷积神经网络从T中提取特征。假设卷积窗口尺寸为k×1,那么卷积神经网络的输出为:

式(4)中:O={O1,O2,O3,…,On},n=m-k+1。
2.5 分类器
为了整合局部卷积神经网络的输出,在分类器中先采用全连接层将局部特征映射到整个文本的特征表达中。最后一层网络的输出经过softmax函数,得到:

使用交叉熵作为损失函数来优化模型:

式(6)中:iy和分别为训练样本中第i个文本的真实标签和预测值。
3 实验
本文采用公开数据集SST-1和SST-2(Stanford sentiment treebank[14])来验证方法的可行性。SST-1共有11 855条样本,5个标签,分别为非常积极(very positive)、积极(positive)、中立(neutral)、消极(negative)和非常消极(very negative)。其中,8 544条样本用来训练,1 101条样本用来验证,2 210条样本用来测试。SST-2含9 613条样本,2个标签,分别为积极(positive)和消极(negative)。其中,6 920条样本用来训练,872条样本用来验证,1 821条样本用来测试。本文方法与已有方法在数据集上的分类准确率如表1所示,可见取得了较好的结果。
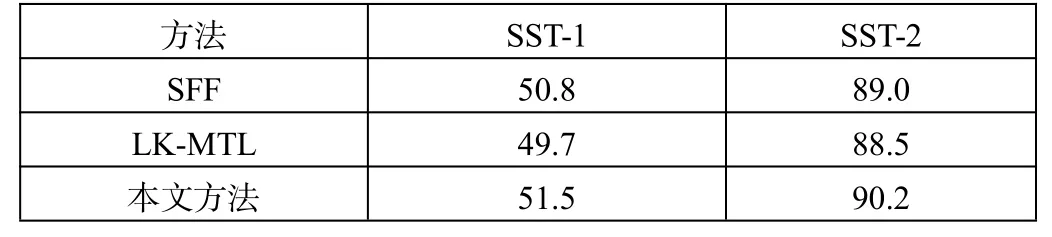
表1 文本分类准确率
本文的对比方法为SFF[15]和LK-MTL[16]。随着卷积神经网络在NLP任务中的应用,SFF方法通过一种新颖的权重初始化方法来提升性能。与随机初始化卷积神经网络不同,SFF通过编码语义特征到卷积过滤器,使其在训练的初始阶段便促使模型专注学习有用特征。LK-MTL方法为基于卷积神经网路的多任务学习方法。为了解决不同任务间互相干扰的问题,该方法设计了一种带有泄露单元的多任务卷积神经网络,该单元具有记忆和遗忘机制以在任务之间过滤特征。与这两种方法相比,本文结合BERT模型与卷积神经网络,使得在特征提取阶段既关注上下文信息,又捕获文本局部信息,获得了较高的文本分类准确率。
4 结论
为了对海量舆情文本数据进行智能解析,本文提出了一种基于BERT预训练模型的舆情文本解析分类方法。为了捕获文本局部信息,将卷积神经网络用在BERT的特定任务层中,并使用自注意力机制来让最终的文本表示关注在文本的重要短语上,从而更有效地获取文本的局部信息,提升分类性能。因此,将基于BERT预训练模型运用到舆情文本分类方法中是有效且可行的。由于模型具有一定的泛化能力,将其应用于新的文本分类任务也具有一定的可行性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
电视技术(2014年19期)2014-03-11 15:38:20
