
多目标情感分类中文数据集构建及分析研究
2021-07-23 06:39:00刘鹏远田永胜杜成玉邱立坤
中文信息学报 2021年6期
刘鹏远,田永胜,杜成玉,邱立坤
(1. 北京语言大学 信息科学学院,北京 100083;2. 北京语言大学 国家语言资源监测与研究平面媒体中心,北京 100083;3. 闽江学院 计算机与控制工程学院,福建 福州 350108)
0 引言
情感分析是自然语言处理领域中最活跃的研究方向之一。方面级别情感分析(aspect-level sentiment analysis)是一种细粒度的情感分析任务,其关注文本针对某一实体、实体的某个部分或属性的情感倾向。目标情感分类(aspect term polarity)是目标级别情感分析的核心子任务之一,目的是分析评论中目标(aspect term)的情感倾向,这个目标是实体的一部分或者是实体的属性,且必须明确出现在句子内。比如(见图1): “大堂小了点儿,房间挺干净,价钱不错。”这句话中的目标词有“大堂”“房间”和“价钱”,根据上下文“小了点”“挺干净”及“不错”可以确定他们的情感倾向分别为负向、正向和正向。当前目标级别情感分类的研究主要基于深度神经网络,采用端到端的方式进行情感倾向的预测或分类[1-2],而循环神经网络因其在处理序列方面的优势得到了研究者更多的青睐,如Tang等人[3]、Ruder等人[4]的研究。除此之外,注意力机制[5]也常常被用来融合目标词与上下文的信息,如Wang[6]、Ma[7]、Peng[8]、曾锋[9]等人利用目标词与句子进行交互以得到更好的表示。近年来,也出现了基于预训练语言模型BERT[10]的目标级情感分类研究[11-12]。

图1 XML格式目标情感分类示例
以上各类模型与方法通常会在某一个目标情感数据集上进行试验及横向比较。目前使用最广泛的目标情感分类数据集是SemEval-2014 task 4[13]和Twitter[14],均为英文数据集。我们对这两个数据集中的评价目标和对应的情感倾向进行统计发现:
(1) Twitter数据集及SemEval-2014 task 4数据集中含有一个以内评价目标的句子所占比例很高(分别为100%及73.6%);
(2) SemEval-2014 task 4数据集中,评价目标情感倾向不一致的句子占比仅有8.6%。
在实际应用中,一个句子包含一个以上目标词且评价倾向性不同的情况比较常见。但是,由于评测数据集中的多目标实例较少,情感不一致的实例更少,这种分布对现有模型在多目标句子上的目标情感分类评价造成一定困难,也限制了模型针对多目标句子进行目标情感分类的提升空间。
为解决以上问题,本文构建了一个针对多目标情感分类的中文数据集(1)https://github.com/NLPBLCU/Chinese-Multi-Target-Sentiment-Classification-Dataset,人工标注了6 339个评价目标,共2 071条数据。该数据集:
(1) 评价目标个数分布相对平衡;
(2) 情感正负极分布相对平衡;
(3) 多目标情感倾向分布相对平衡。
随后,本文利用多个目标情感分类的主流模型在该数据集上进行了实验,比较了各个模型针对多目标情感分类的表现,并进行了详细分析与讨论。
1 数据集构建
1.1 数据准备
本文选取了谭松波收集整理的酒店评论语料作为原始语料(2)https://languageresources.github.io/。该语料规模为10 000篇,内容为携程网的评论。我们将原始语料进行去重并以此为待标注对象,共得到7 767篇评论,其中5 323篇是正向评论,2 444篇是负向评论。
1.2 标注对象
依照目标情感分类任务研究的惯例,我们舍弃目标评价倾向为冲突的句子,仅标注为正向、负向与中性的评价句。
在语料选择方面,选取含有2个及2个以上目标的句子为标注对象,并且尽量控制标注数据在3种情况下的分布基本同时平衡:
(1) 句中目标数量;
(2) 目标情感正负倾向极性;
(3) 句中目标情感相同或不同。
具体标注时,将每个评论中的目标词抽离出来,分别标注每一个目标词在其中的情感倾向,然后得到该句子的标注结果,如: {“大堂”: 负向;“房间”: 正向;“价钱”: 正向}。
1.3 标注流程、数据格式与标注规范
由三名语言学及应用语言学专业的硕士生担任标注员,先进行一轮试标注与讨论,在此基础上总结出标注规范。然后依据标注规范由两名标注员独立地进行标注,对于标注不一致的情况,由第三位标注员进行仲裁。
(1) 试标注。从待标注对象中随机抽取100条,按照标注程序进行试标注。三名标注员在标注了所有100条语料后,就标注不一致的数据进行讨论,总结并形成最终的标注规范。
(2) 数据格式。数据为XML格式,如图1所示。其中:
标注规范(3)详细规范与示例将随数据集及代码一并发布。:
(1) 目标词。目标词是明确出现在句子中的被评价对象的具体属性,本文构建的是酒店领域的数据集,因此被评价对象是“酒店”,目标词可能是“装修风格”“服务态度”等。只标注具有多个目标词的句子。
(2) 情感倾向。包含正向、负向、中性三种情况。正向评价是评价者对某个目标词持积极的、满意的态度。负向评价是评价者对某个目标词持消极的、不满的态度。中性评价是评价者对某个目标词持中立的、客观的态度。
(3) 标注单位。参照现有的英文目标情感分类数据集,本节以单个句子为单位进行标注。
(4) 标注边界。只标注目标词,目标词前的形容词性修饰成分及数量短语等不在标注范围内。
(5) 目标词包含名词型和动词型两种。
(6) 目标词若出现多次,只标注离评价词最近的目标词。
1.4 标注结果
本文仅标注目标词为2的实例与目标词大于等于3的实例,最终标注了2 071条数据,共6 339个目标,平均每个句子3.06个目标。标注好的数据集基本情况如表1、表2所示。句中目标词情感极性一致与不一致句子,目标同数量,目标词为正向情感与负向情感三者比例分别平衡。数据集整体标注一致率为78.1%。

表1 目标词数量或情感倾向分布

续表

表2 所有目标词的情感倾向分布
2 模型与实验
2.1 模型
为探索和分析目标情感分类的主流方法在本文构建数据集上的表现,我们选择了5个具有代表性且已开源的主流神经网络模型,其中包括2个基于BERT的目标情感分类模型。我们还实现了1个基于BERT的基线模型BERT-SPC。
(1) IAN[7]: 将上下文词与目标词通过LSTM层得到隐藏层状态序列,接着利用池化函数得到目标词的初始向量表示,该向量与上下文隐藏层状态通过注意力层得到上下文词注意力权重分布,接着计算加权后的上下文表示,作为它最终的上下文向量。然后用类似的方法得到目标词表示,再与上下文表示拼接。
(2) RAM[8]: 首先通过双向LSTM层得到句子的隐藏层状态序列,接着利用位置信息构建位置加权记忆矩阵,然后构建多个注意力层,每一层的结果都是基于上一层的结果重新进行计算,以此来捕捉记忆矩阵中有用的信息。
(3) ATAE-LSTM[6]: 对句子和给定的方面词用LSTM进行编码后,采用注意力机制对隐藏层输出进行处理,将得到的注意力向量与方面词向量拼接得到关于方面词的情感极性表达。
(4) AEN-BERT[11]: 运用标签平滑化的方法来解决中性类别方面词情感模糊的问题,并运用了多个不同注意力机制对上下文和方面词进行建模。
(5) BERT-HAN[12]: 建立于BERT上的基于螺旋注意力机制的神经网络模型。首先利用目标词构建句子,接着采用句子对的输入方式利用BERT预训练词向量,然后利用螺旋上下文注意力层和螺旋目标词注意力层通过多次叠加注意力层来更好地表示上下文和目标词。
(6) BERT-SPC: 使用预先训练好的BERT来生成序列的词向量,BERT有单个句子和句子对两种输入方式。本文采用句子对的输入方式,将目标词与上下文组成句子对进行输入,输入方式为“[CLS]+target+[SEP]+context+[SEP]”,然后将得到的向量送入softmax分类器。
2.2 实验
2.2.1 数据集与评价指标
实验采用本文建立的多目标情感分类中文数据集,其中含有多个评价目标的句子共6 339条。按照3∶1的比例分别将两个数据集划分成训练集和测试集,具体划分见表3。评价指标采用分类准确率,即模型正确分类的样本数与模型总样本数之比。

表3 多目标情感分类中文数据集详细信息
2.2.2 参数设置
表4是各模型实验时的参数设置。其中,IAN、RAM采用斯坦福大学发布的GloVe词向量(4)https://nlp.stanford.edu/projects/glove/来作为预训练词向量;BERT-SPC、AEN-BERT、BERT-HAN采用BERT BASE(5)https://github.com/google-research/bert进行预训练。

表4 模型参数设置
2.2.3 实验结果
实验结果如表5所示。在6个模型中,基线模型BERT-SPC表现最好,IAN表现最差。仅将目标词与实例一起输入并进行训练的BERT-SPC模型,就已经能够学到很好的目标词情感倾向信息。而其他两种对目标词与句子进行不同注意力权重计算的模型: AEN-BERT与BERT-HAN的表现反而不如BERT-SPC。值得注意的是,两个非BERT模型RAM与ATAE-LSTM的表现,分别比两个基于BERT的模型BERT-HAN与AEN-BERT要好,其可能的原因将在后续分析中进一步尝试探究。
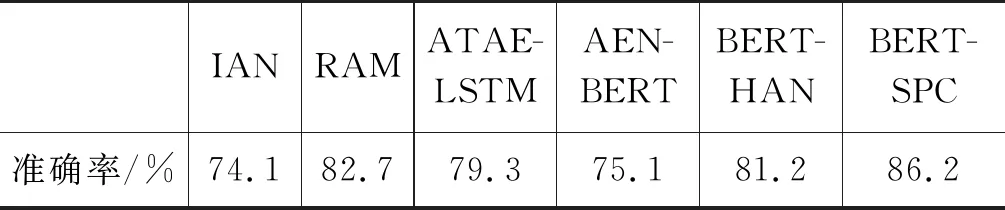
表5 模型的准确率
3 讨论
3.1 目标不同情感倾向对模型分类性能的影响
本文将所有模型对目标分别为正向、负向及中性三种情感倾向分类时的性能进行对比,结果如表6所示。其中正向及中性情感倾向最优模型为BERT-SPC,负向为BERT-HAN。所有基本模型在目标情感倾向不同时性能从好到坏的排序均为: 目标为正向情感倾向>目标为负向情感倾向>目标为中性情感倾向。当目标情感倾向为中性时,各个模型的表现均不尽人意。这个结果在很大程度上与数据集中目标情感倾向的分布有关(见表2)。

表6 模型在不同情感倾向上的分类性能(%)
图2是将数据集中三种情感倾向目标的分布作为待比较的分布基准,考察所有模型性能提升绝对值的柱状图。所有模型在目标为正/负向情感倾向时,性能较分布基准均有所提升,且提升幅度较大。目标为中性情感时,三种基于BERT的模型,不但性能较分布基准均有所提升且幅度较大(BERT-SPC提升幅度最大),这说明基于BERT的模型能在数据分布不均衡的条件下,学到一定的中性倾向的目标信息;而对其他三种非BERT模型,性能均低于分布基准,说明这几个模型所学到的目标中性情感倾向信息较少,甚至基本学不到(IAN模型)。

图2 各模型分别在目标为三种情感倾向时性能较分布基准提升绝对值的柱状图(准确率/%)
基于BERT的模型能够比非BERT模型更好地融合中性情感目标数据的信息,但因此会在一定程度上影响其在目标为正/负向情感时的性能,这可能是造成AEN-BERT与BERT-HAN在总体性能上没有RAM模型好的原因之一。
3.2 目标数对模型分类性能的影响
为考察各模型在不同目标数情况下的性能,根据数据集中每句含有的目标数,分两类对各模型性能进行统计: ①含2个目标; ②含3个目标及以上。
此外,我们还在第1节介绍的待标注对象语料中,按照本文建设多目标情感分类数据集基本类似的过程,额外标注了仅含有单个评价目标的例句共1 046条,其情感倾向性分布与本文建立的多目标情感分类数据集基本一致。类似地,按照3∶1的比例划分成训练集和测试集,句子分别为784条和262条。在这个单目标数据集上,所有模型重新进行了实验,参数设置与之前多目标实验相同(见表4)。
将各模型在单目标数据集及多目标数据集上的实验结果合并列于表7。其中,目标词数量为1,代表单目标数据集,其余两行代表在多目标数据集上的结果。

表7 不同目标数时模型的分类性能(准确率/%)
本文发现,虽然直觉上多目标数据相对于单目标数据更加难以分类,但在单目标数据集上的模型性能并非均比在多目标数据集上的性能更高。同时,目标词数量分别在1、2及大于等于3时,模型的分类性能并没有较大的差距。这主要由于多目标情感不一致时,模型的分类精度会更低。于是,我们统计了在多目标数据集中,同一条目多个目标情感一致与不一致时各个模型分类性能的表现,如表8所示。在多个目标情感一致时,各个模型的性能均非常优异(大于90%),AEN-BERT的表现最好,其次是BERT-SPC。各个模型在多目标情感倾向不一致时,BERT-SPC的表现最好,能够达到80.0%,AEN-BERT表现最差,还不到60%。所有模型的性能比情感倾向一致时的性能均有大幅度的下降,降幅最大的模型是AEN-BERT,接近40%,降幅最小的模型是BERT-SPC,也达到了14.4%。

表8 模型在多目标情感倾向一致和不一致
3.3 模型分类结果的相关性
图3是6个模型在本数据集上的分类结果相关性热力图,它反映的是各个模型在数据集上的预测结果的相关性。如果两个模型预测结果的相关性比较高,则一个模型预测正确时,另一个模型预测正确的可能性也较高;当一个模型预测错误时,另一个模型预测错误的可能性也较高。
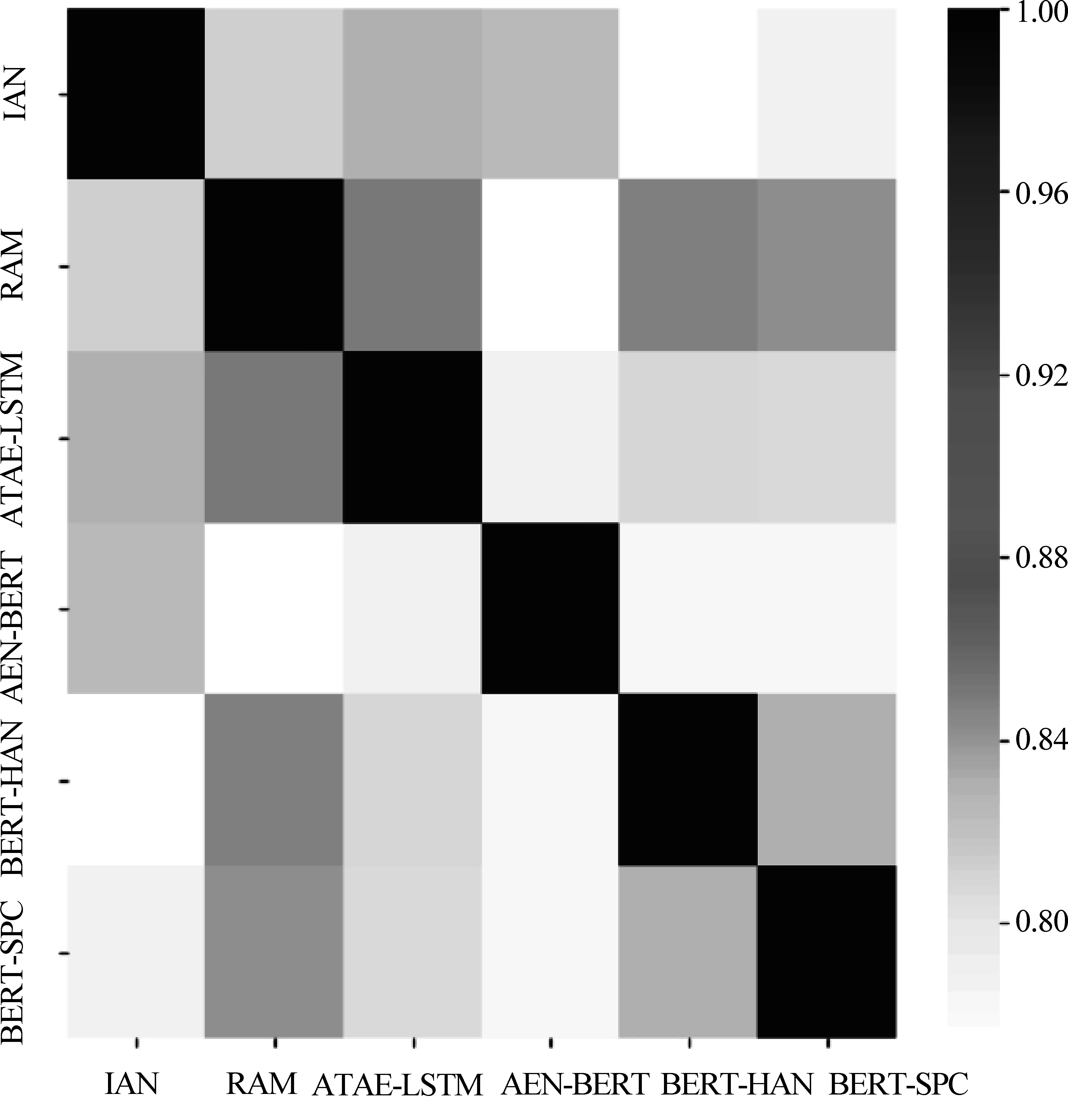
图3 模型分类结果的相关性
从图3可知,6个模型分类结果的相关性都比较高,基本在80%以上,其中ATAE-LSTM与RAM的相关性及BERT-HAN与RAM的相关性相对较高,超过了85%。
本文还统计了BERT-SPC模型预测错误(共219个)但其他模型能够预测正确的目标数及比例(即与BERT-SPC模型预测错误目标数之比),列在表9中。可见,虽然模型分类结果相关性比较高,但对任务上最佳的BERT-SPC模型错误预测的目标,其他模型也有一定正确预测的可能,但是有部分目标(219-133=86个)所有模型均无法正确预测。
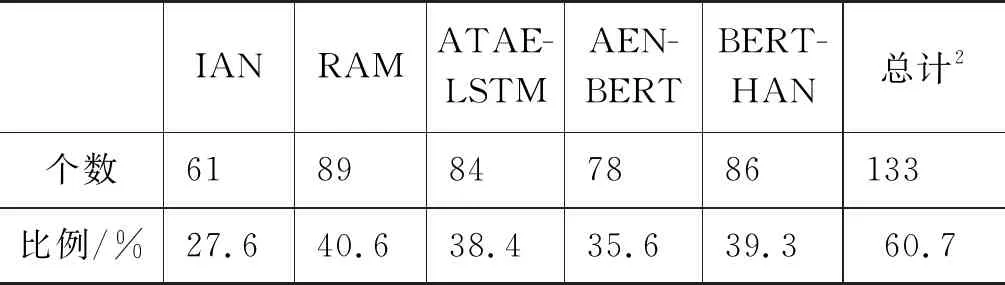
表9 BERT-SPC模型预测错误但其他模型能够预测正确的目标数及比例1
3.4 目标分类难度
数据集中目标的情感倾向可能被1个或多个模型正确预测,也可能无法被任何模型正确预测。可从正确预测目标情感倾向模型个数的角度来考察目标情感倾向的预测难度。我们将各个模型对测试集中所有1 586个目标实例的预测结果进行了逐个统计,对每一个目标进行模型预测正确计数,即每有一个模型对其预测正确,则该目标模型预测正确的个数加一。所有目标分成从0到6共七类。在此基础上,我们进一步将所有目标分为易、中、难三个等级,结果列于表10。
易: 模型预测正确数为5、6的目标;
中: 模型预测正确数为2、3、4的目标;
难: 模型预测正确数为0、1的目标。
由表10可知,有86个目标,所有模型均没有预测正确,有883个目标所有模型均预测正确。难度等级为“难”“中”及“易”的目标,分别占所有目标的8.6%,20.9%及70.5%。

表10 目标情感倾向预测难度等级分布
在目标难度等级的基础上,我们考虑了以下四种典型情况:
(1) 一致: 处在有情感倾向一致目标的句中的目标;
(2) 不一致: 处在有情感倾向不一致目标的句中的目标;
(3) 中性: 中性情感目标;
(4) 中性不一致: 中性情感目标,且处在有情感倾向不一致目标的句中。

图4 目标“一致”“不一致”“中性”“中性不一致”时的难度分布
本文绘制了这四种典型情况下难度分布柱状图,见图4。当目标在“一致”时,90%的目标在等级“易”中,即容易分类;;“不一致”时,仅有50%左右的目标容易分类。当目标为“中性”时,超过70%的目标在等级“难”中,即难以分类,而当目标为“中性不一致”时,有约85%的目标难以分类。这四种典型情况下,目标分类难度从难到易依次为: “中性不一致”→“中性”→“不一致”→“一致”。
3.5 实例分析
为对模型难以分类的实例有一定感性认识,我们对全部模型均预测错误的目标例句进行了仔细观察,并列举了部分在表11中。第一列为样例,加粗字体为目标,加粗字体后括号内的数字为该目标的情感倾向,1/-1/0分别表示正向/负向/中性。第二列为要预测情感倾向的目标,第三列为该目标类型,“一致”/“不一致”与3.4节中考虑的前两种典型情况相同。第四列为要判断的目标词的真实情感倾向。最后一列是6个模型分别对目标词情感倾向的预测结果。

表11 全部模型预测洁度的样例分析
我们发现目标词以外的情感倾向会对目标词的情感倾向抽取造成干扰。如在句子“其实格林豪泰……还挺好,接着就是前台了,那叫什么服务态度啊?”中,目标词为“前台”,其情感极性很明显为负向。但是所有的模型都把它分到了正向,这可能是因为,在这个句子中短语“还挺好”离目标词更近,且情感倾向为正向,但这是对目标词“大门”的描述,因此对模型的分类造成了干扰。在中性目标词的情感倾向分类上,由于目标词没有明显情感倾向,则其余目标词的情感倾向造成的干扰将会更加明显。此外,中性目标词的情感倾向含糊不清,程度较弱,不太容易判断他的情感倾向是否是中性。例如在句子“第二次入住了……冰镇饮料喝。”中,尽管目标词“冰镇饮料”的情感倾向为中性,但是句子中修饰目标词的“免费”很多情境下是表达正向情感的。在数据规模上,由于中性目标数量远远低于正向与负向目标数,故也使得模型对于中性目标的情感分类泛化能力较弱。
4 相关工作
传统的基于目标词的情感分析方法包括基于规则的方法[15]和基于统计的方法[14,16]。这些方法侧重于将一组分类线索转化为特征向量,但这既需要费力的特征工程工作,也需要大量的额外语言资源。循环神经网络较早应用到目标级别情感分类领域[3-4]。单纯基于RNN的模型无法很好地捕捉到句子中目标词与情感极性词或短语之间的关联,研究人员引入注意力机制来解决这个问题。Wang等人[6]对句子和给定的方面词用LSTM进行编码后,采用注意力机制对隐藏层输出进行处理,得到关于目标词的情感极性表达。Tang等人[17]基于输入句子的词向量构成的外部记忆进行注意力学习,模型的每一层基于上一层输出的结果重新计算注意力分布,最终得到关于给定方面词的情感极性表达。Ma等人[7]不仅计算句子隐藏层输出的注意力分布,还计算方面词的注意力分布。Li等人[18]将位置嵌入作为输入的一部分,并用层次注意力机制来融合目标和上下文词的信息。卷积神经网络能够并行计算,在运算速度上有一定优势,于是也有学者基于参数化卷积神经网络[19]和基于门控卷积神经网络[20]的相关研究。BERT模型提出后,一些研究在它的基础上对上下文进行编码,并结合注意力机制,来更好地解决方面级别情感分类任务。Song等人[11]在BERT表示的基础上,采用多个不同注意力机制对上下文和方面词进行建模。杜成玉和刘鹏远[12]利用螺旋注意力机制,反复增强BERT编码后的方面词与句子的表示。其他工作还有Zhao等人[21]利用图卷积网络进行目标级情感建模与分类。
现有的方面级别情感分类任务的数据集主要有: SemEval-2014 task 4: Aspect Based Sentiment Analysis[13]、SemEval-2015 task 12: Aspect Based Sentiment Analysis[22]、SemEval-2016 task 5: Aspect Based Sentiment Analysis[23]和Twitter[14]。
SemEval-2014 task 4数据集包含两个领域,分别为Laptop和Restaurant。Laptop数据集摘自笔记本电脑的用户评论,包含3 048个英语句子;Restaurant数据集来自于Ganu等人[24]标注的餐厅评论,由3 044个英语句子组成。两个领域的数据集都以句子为单位人工标注了句子中的目标词及其情感倾向和位置,其中情感倾向包含正向、负向、中性,除此之外,Restaurant数据集还标注了目标词的类别的情感倾向。
SemEval-2015 task 12数据集采用的原始语料与SemEval-2014 task 4数据集相同,但它是以一条评论为单位进行标注的,两个领域的数据集都标注了目标词的类别及其情感倾向,不同的是,后者标注了实体和属性对,其中实体和属性属于提前规定好的实体和属性集合;Restaurant数据集还标注了观点目标词及其情感倾向和位置,它与SemEval-2014 task 4数据集中的方面词的概念相同。
SemEval-2016 task 5数据集的标注内容与SemEval-2015 task 12数据集相同,增加了其他语种,比如中文、法语、阿拉伯语等。
Twitter数据集是使用关键字通过Twitter API收集的开放域数据集,关键字包含人名、公司和产品的名称等,然后以tweet为标注单位,人工标注了tweet中出现的关键字及其情感倾向,这是到目前为止人工标注的最大的针对方面情感分类任务的Twitter数据集。
5 结论
本文针对现有数据集的问题构建了一个面向多目标情感分类的中文数据集,该数据集中评价目标个数、情感正负极性及多目标情感倾向均分布平衡。本文还实现了多个目标情感分类的主流模型并在该数据集上进行了实验与比较分析。结果表明: ①目标个数对各模型在数据集上的分类结果影响不大; ②在同一句中多个目标情感倾向是否一致对模型的影响较大; ③情感倾向为中性的实例较难进行预测,一方面是由于中性目标实例较少,另一方面是因为中性情感倾向的强度一般较低。
多目标情感分类的模型应考虑如何对目标情感倾向性不一致,尤其是在同时目标的情感倾向中有中性情感的情况下,进行有针对性的改进。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
英语学习(上半月)(2019年9期)2019-10-10 02:17:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
米娜·女性大世界(2016年8期)2016-08-17 17:01:00
工业设计(2016年11期)2016-04-16 02:44:40
