
合规视角下的数据安全技术前沿与应用
2021-07-23 07:53:12陈磊刘文懋
数据与计算发展前沿 2021年3期
陈磊,刘文懋
1.绿盟科技集团股份有限公司,北京 100089
2.清华大学,自动化系,北京 100084
引 言
在当今大数据时代,数据得到人们越来越多的重视。大数据和人工智能的深度融合深刻而广泛地影响了包括政府、金融、运营商、电力和互联网的各行各业,数据价值的流通与释放进一步促进了经济和生产力的发展。然而,数据带来的发展机遇也伴随着安全挑战:近年来,大规模数据泄露事件频频发生、“大数据杀熟”、数据歧视、个人信息非法采集和隐私窃取等安全问题愈发严峻,且这些问题对公民以及社会造成了不可忽视的负面影响与危害。
为了应对挑战,全球掀起数据安全与隐私的立法热潮,法规监管力度不断强化。欧盟于 2018 年实施《通用数据保护条例》(General Data Protection Regulation, GDPR)[1],美国于 2020 年实施《加州消费者隐私法案》(California Consumer Privacy Act,CCPA),日本于2020年6月通过修订版《个人信息保护法》。中国在 2020 年7月和10月陆续公开发布两部重量级的法规草案:《数据安全法(草案)》和《个人信息保护法(草案)》。随着全球数据安全法规监管的不断强化,合规性问题成为企业数据安全建设迫切需要考虑的安全任务。换句话说,合规性成为了企业数据安全建设与治理的重要驱动力。然而,法规向企业提出范围更广和约束更严的数据安全的相关要求,给传统的网络与数据安全技术和产品带来了前所未有的巨大挑战。
在这样的背景下,本文通过对实际应用中的三类重点数据安全场景——用户隐私数据安全合规、企业内部数据安全治理和企业间数据安全共享与计算的合规性与安全需求进行梳理与分析,并分别选取当前业界可以应对的十种前沿数据安全技术进行研究和分析,包括:处于学术前沿的差分隐私、数据匿名和同态加密,工业界内炙手可热的安全多方计算、联邦学习,以及从其他领域引入的新技术知识图谱、流程自动化、用户实体行为分析等。通过对这十种前沿技术展开原理与应用研究,旨在为国内数据安全合规、隐私保护等场景提供技术指导。
1 国内外数据安全法规现状
1.1 国外
2018年5月25日,欧盟正式实施《通用数据保护条例》(GDPR)用以保护欧盟成员国境内企业的个人数据,也包括欧盟境外企业处理欧盟公民的个人数据以及公民享有的各项数据权利。
受GDPR的影响,全球其他国家也陆续推出了各自相关的法规:巴西于2019年7月通过《通用数据保护法》(葡萄牙语简称LGPD);印度公布修改后的《2019年个人数据保护法(草案)》(Personal Data Protection Bill, 2019);泰国于2020年5月正式实施了《个人数据保护法》(Personal Data Protection Act,PDPA)等。此外,美国各个州在数据隐私领域上纷纷重新立法,包括加利福尼亚州 (加州)、蒙佛特州、夏威夷、马里兰、马萨诸塞、密西西比和华盛顿等。其中,最具代表的是加州于2018年6月通过的《加州消费者隐私保护法案》(CCPA)。由于CCPA的影响涉及大部分知名IT科技公司,如惠普、Oracle、Apple、Google和Facebook等,该法案从立法到颁布备受各界人士的关注。2019年10月,美国加州州长正式签署CCPA的最终法案,已于2020年1月1日正式生效。CCPA与GDPR类似,同样对企业提出更高的数据合规性要求,据IAPP和OneTrust调查结果显示,大约仅有2%的受访者认为他们的企业已经完全做好了应对CCPA合规 的准备[2]。
在执法方面,欧盟GDPR相较其他国家的法规,已经进入全面执法阶段,多个欧盟成员国已经陆续开出多张违反GDPR的罚单。其中,英国执法力度最大,英国ICO (Information Commissioner’s Office)2019年于7月对英国航空公司和万豪国际集团由于数据泄露事件分别开出1.83亿英镑和9900万英镑的巨额罚单。另外,Google罚款事件非常具代表性,备受关注——作为一家大型国际互联网公司,Google却已被欧盟的两个国家罚款:2019年1月被法国处罚5000万欧元,原因是执法方认为Google的隐私条款未充分体现GDPR公开透明和清晰原则;2020年3月被瑞典处罚700万欧元,原因是Google未充分履行GDPR赋予用户的数据“遗忘权”。GDPR立法与执法的严苛程度,从以上的事件可见一斑。
1.2 国内
我国于2017年6月1日正式实施《中华人民共和国网络安全法》(以下简称《网络安全法》)[3]。它是我国首部较为全面规范网络空间安全管理方面问题的基础性法律,不仅包括网络运行安全、关键信息基础设施的运行安全,同时给出数据安全与个人信息保护的一般规定。
自2019以来,我国数据安全相关立法进程明显加快:根据《网络安全法》,国家互联网信息办公室分别于2019年5月和6月发布了《数据安全管理办法 (征求意见稿)》和《个人信息出境安全评估办法(征求意见稿)》等法规;同年10月1号正式实施《儿童个人信息网络保护规定》,对儿童个人信息安全进行特殊和更加严格的保护。2020年5月我国发布《中华人民共和国民法典》,其首次在我国法律中明确且具体提出“隐私权”的概念,并确立隐私权范围和个人信息保护的一些基本规范。2020年7月,我国对外发布《中华人民共和国数据安全法(草案)》(以下简称《数据安全法(草案)》),确立了数据分级分类保护、数据安全风险评估、应急处置机制和安全审查的重要制度,明确了开展数据活动必须履行数据安全保护义务等内容。2020年10月,《中华人民共和国个人信息保护法(草案)》(以下简称《个人信息保护法(草案)》)在人大网公开,该法律完善和丰富了个人各项数据权利,赋予个人包括知情权、决定权、查询权、更正权、删除权等;同时相比《网络安全法》,其对违法的行为加大了惩处力度,最高可处罚5000万人民币或企业上一年度营业总额的5%。《数据安全法》和《个人信息保护法》作为两部较为综合性的法律,前者更加强调在总体国家安全观的指导下,对国家利益、公共利益和个人、组织合法权益方面给予全面保护,后者则更加侧重于对个人信息、隐私等涉及公民自身安全的个人信息与权益进行保护。
在标准层面上,我国数据安全多部标准已经发布或者正在制定中,相关的标准体系正逐步趋向完善,包括《数据安全能力成熟度模型》 (GB/T 37988-2019)、《个人信息安全规范》(GB/T 35273-2020)、《个人信息去标识化指南》(GB/T 37964-2019)、《大数据安全管理指南》(GB/T 37973-2019)等。
在数据安全相关执法上,我国监管部门主要聚焦在两个方面:一是针对APP个人信息侵权专项治理,近年来网信办、工业和信息化部、公安部、市场监管总局四部门成立专项治理工作组,对三十余万款APP开展个人信息合规性评估与整治,包括未公开收集使用规则、未经用户同意收集使用个人信息和私自共享给第三方用户信息等,对涉及违规APP进行通报、约谈、整改、下架等处罚形式,通报对象不乏有大型企业的APP[4]。二是针对个人信息非法交易与数据黑灰产的整治,公安部在多个城市连续开展“净网2019”、“净网 2020”专项行动[5],对此类案件重拳出击,从源头上进行杜绝,降低由于个人信息非法交易与泄露导致的定向电信诈骗、短信骚扰等给用户带来的精神困扰与财产损失。
2 合规驱动下的数据安全
2.1 概述
根据数据业务的应用场景以及数据域分布的不同,企业数据安全建设可分为三类场景:
(1)用户隐私数据安全合规:企业与用户交互的场景,它们需满足数据安全与隐私合规性。具体包括数据采集的隐私保护、个人信息治理与可视化、用户数据权利请求响应(访问权、删除权和限制处理权等)等子场景。
(2)企业内部数据安全治理:企业内部网络环境中,需对其敏感数据和重要数据在存储、使用等环节进行安全防护和监控。具体包括敏感数据的识别与分类、脱敏数据的残余风险评估、数据操作行为的异常检测等子场景。
(3)企业间数据共享与计算:两个或两个以上企业组织之间,实现数据的共享与计算任务,在满足正常业务同时确保数据与隐私安全。具体包括涉及个人数据的发布与共享、云上数据安全存储与计算、多方数据安全共享与计算、多方数据安全的联合AI建模等子场景。
上述三大类场景的各个子场景不仅有自身的安全与隐私需求,也有合规性要求,具体可以对应到GDPR和《网络安全法》的合规性条款。为了应对这些场景的安全与合规挑战,可选取差分隐私、同态加密、安全多方计算和联邦学习等十种前沿技术,具体如图1所示。下文2.2-2.4小节将分别从三类场景出发,具体阐述如何通过前沿技术超越合规,解决隐私与安全问题。
2.2 新技术及在用户隐私合规的应用
2.2.1 差分隐私
在法规中,为了应对隐私问题带来的风险挑战,欧盟GDPR指出数据控制者与处理者处理个人数据时“应当执行合适的技术措施和有组织性的措施来保证合理应对风险的安全水平”(第32条);而我国《网络安全法》规定:“网络运营者应当采取技术措施和其他必要措施,确保其收集的个人信息安全,防止信息泄露、毁损、丢失”(第42条)。这些法规均要求企业采取一定的技术与管理措施,确保采集的用户个人信息与隐私安全。在数据采集中,如何平衡数据可用性与隐私保护的矛盾,下面介绍的是当前应用的一种关键技术。
差分隐私(Differential Privacy, DP)技术由于无需假设攻击者掌握的背景知识,其安全性可通过数学证明等优势,近年来受到了学术界和工业界的广泛关注。
它最早由微软研究者Dwork 在2007年提出[6],它可以确保数据库插入或删除一条记录不会对查询或统计的结果造成显著性影响,数学化描述如下:

其中,D和D′分别指相邻的数据集(差别只有一条记录),f(g)是某种操作或算法(比如查询、求平均、总和等)。对于它的任意输出C,两个数据集输出这样结果的概率几乎是接近的,即两者概率比值小于eε,那么称为满足−ε隐私。主要实现思路通过在查询结果中加入噪声,比如Laplace类型的噪声,使得查询结果在一定范围内失真,并且保持两个相邻数据库概率分布几乎相同。ε参数通常被称为隐私预算(Privacy budget),ε越小,两次查询相邻数据集D和D′分的结果越接近,即隐私保护程度越高。一般将ε设置为一个较小的数,比如0.01,0.1。实际应用中需通过调节ε参数,以平衡隐私性与数据可用性。
在早期差分隐私应用场景中,数据存储在数据库中,通过提供具有差分隐私功能的查询接口给查询者使用,通常称该方案为中心化的差分隐私模型(Centralized Differential Privacy,CDP),代表性应用是微软开发了PINQ(Privacy Integrated Queries)系统。随着研究与发展,出现了另一种模式——本地差分隐私(Local Differential Privacy, LDP),代表性应用是谷歌公司的Chrome浏览器的Rappor应用,以及苹果公司的iphone的隐私数据采集。以苹果公司为例,它通过差分隐私技术可挖掘到iPhone用户使用表情的频率分布,但无法获得具体某一个用户的确切隐私,如图2所示。其原理是在LDP模式下,每一个用户终端都会运行一个DP算法,每一个终端采集的数据都会加入噪声,然后将其上传给服务器;服务器虽然无法获得某一个用户的确切隐私,但通过聚合与转换可以挖掘出用户群体的行为趋势。虽然差分隐私技术已经在工业界有一部分的成功应用,尤其是LDP,然而仍然面临实现算法复杂度高,特色数据分布数据集的差分隐私结果噪声过大,隐私预算难以控制等的实用化瓶颈。
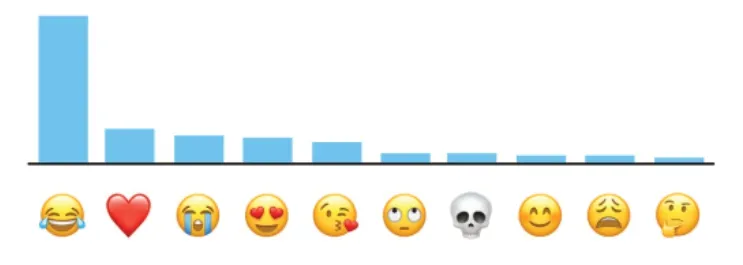
图2 差分隐私在iPhone的应用(图引自[7])Fig.2 Application of differential privacy in iPhone
2.2.2 知识图谱
欧盟GDPR赋予给用户关于个人数据的访问权、修改权和被遗忘权等多项权利。相应地,企业必须履行和响应用户提出的请求。比如用户发起数据查看请求,那么企业必须完整呈现数据主体的个人数据报告,包括收集了哪些用户数据、共享给了哪些企业(第 12至22 条)。我国《网络安全法》赋予了用户一定程度的“删除权”和“修改权”,同样地企业须履行和配合用户完成数据权利请求的流程。企业如何更好地完成该项法律规定的义务,即如何对同一个个人信息主体进行实体识别与数据关联是一个技术挑战。
知识图谱(Knowledge Graph)技术可以很好应对以上合规性带来的挑战。它最早由Google在2012年提出[8],应用于优化搜索引擎,通过信息的提取与关联以实现更好地查询复杂的信息。随着理论与技术的发展与完善,目前知识图谱已广泛应用于社交网络、金融、电商等领域的数据挖掘。
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。
同样,知识图谱应用于个人数据保护领域,它可以帮助企业快速识别个人与敏感数据的存储位置,这些数据是如何被使用的,以及它的合同、法律和监管义务,同时可以将个人数据主体所有的属性维度信息,比如姓名、出生年月、手机号和地区等信息进行关联。RSAC 2020创新沙盒比赛的冠军公司——Securit.ai,它将知识图谱技术引入到隐私合规领域,称为个人数据图谱(People data graph),它可以将个人数据主体所有的属性维度信息,比如姓名、出生年月、手机号和地区等信息进行关联,如图3所示;同时在此基础上能给出敏感数据存储的分布地图,以及传输的数据映射图。这样,当用户提出个人数据请求时,比如删除数据,企业可快速获取用户实体所有的数据维度、存储位置以及共享的第三方信息,进而短时间内响应与处理用户请求,满足GDPR和CCPA的合规要求。

图3 个人数据图谱(图引自[9])Fig.3 Personal data graph(cited from Ref.[9])
2.2.3 流程自动化
欧盟GDPR一方面赋予了用户各种数据权利,另一方面也规定了企业在收到用户数据权利请求后的响应时间,即“必须在一个月内对所有的请求进行响应和处理,若请求过于复杂,可延长至两个月”(第 12至22 条)。我国《网络安全法》虽未明确规定具体的响应时间,但在国家标准《个人信息安全规范》(GB/T 35273-2020)中,规定从请求到响应的时间是30天内(第 43 条)。对于该合规性要求,据Gartner调查,约有三分之二企业对单个数据主体权利请求(Subject Rights Request, SRR)的回复需要超过两周以上的时间,且这些流程通常是人工完成,平均成本约高达1400美元。如何提升运营效率,降低响应超时的违规风险是一个极具挑战性的问题。
流程自动化技术可帮助企业的数据安全运营团队从繁琐重复的手工处理“请求-响应”转为自动化处理,一方面可降低人工的运营成本,另一方面可减少由于响应时间延误带来的违规风险。它可以赋能两类隐私合规产品中:主体权利请求 (Subject Rights Request, SRR)和统一许可偏好性设置管理(Universal Consent and Preference Management, UCPM)。SRR可处理与响应用户提出的个人数据访问、修改和删除等权利请求;UCPM可处理与响应用户对被收集的个人数据提出限制处理和拒绝的权利请求。SRR和UCPM产品,可划分为两个功能层:
(1)用户侧功能:在移动App、应用程序或网站网页的产品界面中,为用户增加清晰透明的请求窗户与按钮,包括提供个人数据查看、修改、删除按钮,或者限制处理的目的和拒绝与第三方公司共享等偏好性设置面板,类似于图4所示;

图4 SRR/UCPM产品为用户提供面板(图引自[9])Fig.4 Panel for SRR/UCPM products(cited from Ref.[9])
(2)企业侧功能:企业后端系统收到请求,进行身份识别与确认后,对请求的内容进行解析,并对映射关联实体数据,在规定时间内对请求进行响应,将结果通过邮件或网页形式反馈给发出请求的用户。
欧美安全初创公司Securiti.ai、BigID和One Trust等多家均推出SRR和UCPM相关产品。但作为近年来的新兴隐私合规技术,未来仍然可进一步发展:(1)提升流程效率,优化响应单个SRR/UCPM请求流程;(2)降低运营成本,包括考虑运营团队处理请求时所涉及的计算资源;(3)引入人工智能技术,提升自动化处理的效率与精度。
2.3 新技术及在数据安全治理的应用
2.3.1 敏感数据智能识别
欧盟GDPR的核心是保护个人数据,但对个人数据的定义十分宽泛,不仅包括姓名、年龄、性别等基本个人信息,还包括个人照片、IP、Mac、网络Cookie等一系列信息(第4条);我国《网络安全法》的“个人信息”同样蕴含丰富的个人基本信息以及特殊数据,比如包括个人照片、身份证照片和指纹等(第76条)。如何识别这些特殊的“个人信息”,传统的敏感数据识别方法,需要人工设计规则与字典,难以覆盖全面,易出现漏检现象。
智能敏感数据识别技术主要应用在文本、图像等非结构化数据类型中。它包括以下三类智能算法:(1)基于相似度算法:可准确检测以文档形式存储的非结构化数据,例如 Word 与 PowerPoint 文件、PDF 文档、财务文档。主要思路是分别提取敏感信息文档和待检测文档的指纹特征,然后通过相似度算法比较,根据预设的相似度阈值去确认被检测文档是否为敏感信息文档。(2)基于非监督学习算法:它无需人工打标签。待检测敏感数据提取特征后,使用K-means、DBSCAN等聚类算法,将输入的样本向量进行聚类,聚类完成形成不同“簇”的数据集合,人工对这些“簇”的部分样本进行分析确定相应“簇”的类别,比如敏感型、非敏感型。(3)基于监督学习算法:它需收集一定数量的训练数据(比如文档、图片),同时对数据进行人工打标签,比如敏感与非敏感标签。然后选择相应的监督学习算法,比如支持向量机(SVM)、决策树、随机森林、神经网络等,再对训练数据进行模型训练与调参。训练完成,将输出的模型应用在新的数据进行智能识别与预测,自动化输出数据类型——敏感或非敏感数据。
在实际应用中,创新公司Securiti.ai和 BigID均宣称利用机器学习和聚类算法在大规模数据实现分类,以自动化发现个人数据以及其他敏感数据。但算法的效率、识别精度以及可扩展性仍然是一系列富有挑战性的关键问题。
2.3.2 数据脱敏风险评估
欧盟GDPR规定,在数据处理过程中,应当选择合适的技术措施合理地应对安全风险(第32条)。我国《网络安全法》要求企业采取一定的技术与管理措施,确保用户个人信息与隐私安全(第42条)。数据脱敏是企业广泛采用的一种安全技术措施,然而发现脱敏方法选择不对,脱敏强度不够,仍然存在隐私泄露风险。在风险管理的视角下,如何刻画和评估风险尤为关键。
数据脱敏风险评估,是对脱敏后的数据的隐私泄露风险进行分析和刻画。其技术主要可分为两类:基于人工抽查的定性判定方法和通用的评估技术。其中,基于人工抽查的定性判定方法,指的是按照标准流程和表格进行专家检查和判定,然而,这种方法成本十分昂贵。
通用的风险评估技术与数据脱敏方法与模型无关,在学术上通常称为重标识风险(Re-identification risk)的度量。加拿大学者El Emam等人建立了较为通用的重标识风险评估理论与方法[10],并根据攻击者能力与攻击意图,将攻击分为三类场景并将其形象化命名为:检察官攻击 (Prosecutor attack)、记者攻击 (Journalist attack)和营销者攻击 (Marketer attack)。在三种攻击场景下,El Emam等人基于概率和分布设计了一套评价指标体系,它包括8种指标,分别可以刻画平均重标识概率、最大重标识概率、高重标识记录占比等风险信息。它们的数值范围均为[0,1],1表示最高重标识风险,0表示几乎最低重标识风险。在具体应用中,需根据实际情况,选择合适的指标进行重标识风险评估。
在工业应用中,数据安全公司Privacy Analytics提供数据脱敏以及风险评估与检测,帮助数据处理企业实现HIPAA合规,同时将数据共享或出售给保险、药企和科研结构等第三方。目前该技术被我国一些专家学者重视,制定了一些相关标准,并开发一些相关的评估工具。比较有代表性的是绿盟科技提出的数据脱敏风险评估方案,当敏感数据经过数据脱敏后,对脱敏数据集结果进行风险评估,最终得到风险值,根据预置场景(内部使用、与第三方共享、对外交易的、对外公开发布的)阈值进行比较,若不满足分析原因,实施二次脱敏,直到脱敏的残余风险在可控范围。如图5所示,对身份证号和手机号的数据集进行三次“脱敏-评估”循环,直至风险的可能性和危害性落入可接收范围内。

图5 绿盟科技的数据脱敏风险评估应用Fig.5 Application of risk assessment for data masking
2.3.3 用户实体行为分析
同上一节的欧盟GDPR规定(第32条)和我国《网络安全法》规定(第42条)的相关要求。在数据库、大数据平台的安全防护中,需记录和分析用户实体的正常和异常行为模式,比如防止数据由于外部攻击或内部原因导致的泄漏行为。传统基于规则的异常检测方法无法应对复杂业务带来的挑战。
用户实体行为分析(User and Entity Behavior Analytics, UEBA)技术通过对用户实体持续的画像与建模,可从海量收集的安全数据中及时发现和识别出攻击以及异常的行为[11]。UEBA包括一些基本的分析方法(阈值分析),同时也包括一些高级分析方法(关联分析,机器学习):
(1)阈值分析:主要是基于统计方法做异常检测。对一段时间内的数据进行统计,然后和阈值比较,如果超出阈值范围,则判定为异常。比如统计正常的历史流入流出流量的统计值作为阈值,进行异常行为判定。
(2)关联分析:用于发现隐藏在大型数据集中的有意义的联系。可以基于算法做关联分析,挖出数据之间的关联规则,另外,还可以借助图数据库等工具,挖掘数据之间的关联。
(3)机器学习:通过对大量历史数据持续进化不断学习,能够检测和识别异常或恶意行为,特别是对数据安全未知威胁的检测具有优势。UEBA通常应用逻辑回归、SVM、K-Means聚类、DBSCAN密度聚类、随机森林等算法。
根据 Gartner 报告,UEBA 在中大型企业(比如IBM,Google)已在一些安全场景实现落地与应用,该技术已逐步趋向成熟。而在数据安全领域的应用,典型应用场景是数据库泄露的异常检测。以敏感数据为中心,通过采集用户实体对数据操作相关维度信息,通过数据分析与学习过程,建立多维度实体的行为基线,利用机器学习算法和预定义规则找出严重偏离基线的异常行为,及时发现内部用户、合作伙伴窃取数据等违规行为。在该场景中,通常采用5W1H模型进行UEBA分析与建模:Who(何人),When(何时),Where(何地),What(何事),Why(原因),How(行为方式)。通过6个维度实体行为的分析,可及时发现数据泄露与异常操作行为。
2.4 新技术及在数据共享计算的应用
2.4.1 数据匿名
GDPR规定,企业不能直接共享原始的个人数据,但对个人数据进行匿名化处理得到的匿名数据,可用于统计和研究目的,其不受该法规约束与限制(前言的第26段);我国《网络安全法》也有类似的规定,“经过处理无法识别特定个人且不能复原”的数据可与第三方进行共享(第42条)。如何实现低成本的、安全合规的个人数据共享与发布,这对于企业来说是挑战性问题。
数据匿名 (Data Anonymization),是对个人信息进行泛化和屏蔽等处理,使得对应的个人信息主体无法被识别,达到“身份匿名或隐藏”的效果。
在匿名化技术中,K-匿名是最早研究的技术[12]。它可以保证数据表中至少有K条记录泛化为相同的取值。这样处理保证了一定的数据可用性,同时也保护了患者的隐私——即使攻击者有背景知识,也无法唯一地确定到底哪一条记录属于朋友的诊断记录。
由于K-匿名不对敏感属性进行约束,当等价组的敏感属性取值相同时,仍然存在隐私泄露风险。后续学者提出了L-多样性(L-diversity)[13]和T-近似性(T-closeness)[14]模型。
(1)L-多样性模型:它不仅可以保证形成的等价组至少包含K个记录,同时通过修改敏感属性或者添加伪造记录,使得任意等价组的敏感属性至少包含L个不同的值。
(2)T-近似性模型:它不仅可以保证形成的等价组至少包含K个记录,同样通过修改敏感属性或者添加伪造记录,使得任意的等价组的敏感属性的分布与全局的敏感属性分布之间的距离度量值小于参数T。
总的来说,各个模型的隐私保护程度效果,T-近似性优于L-多样性,L-多样性优于K-匿名;然而对于数据可用性,却正好相反。在实际应用场景中,需根据两者的具体需求进行技术选型。
在工业界应用中,数据匿名技术有丰富开源项目,其中ARX较为成熟,支持K-匿名、L-多样和T-近似模型,且提供丰富的界面和API接口。同时数据匿名技术在Google、Privitar和Anonos等公司均有一定的应用。然而,该技术仍然存在挑战性问题有待进一步解决,比如在高维数据集上表现的数据可用性急剧下降问题,多个敏感属性的匿名化处理,匿名算法优化以及在大数据平台的应用等问题。
2.4.2 同态加密
欧盟GDPR对于个人数据保护的安全措施,推荐使用加密等手段,以应对数据存储与处理环节的安全风险(32条);我国《网络安全法》同样推荐应用加密等技术措施,以防止数据与个人信息的泄露以及毁损等安全问题(21条)。传统的数据加密方法,如AES、3DES和SM4,加密得到的密文数据无法进一步分析。在兼顾数据安全与数据利用的应用场景中,如云上的敏感数据计算,需要使用一种新型的加密技术,不仅能保障数据的安全,同时加密后仍然可以执行数据处理操作。
同态加密(Homomorphic Encryption,HE)是应对以上需求的一类关键技术。它的概念最早由Rivest等人在1978年提出[15],它是一种特殊加密算法,其形式化可表述为:假设A和B是两个待加密的明文,Enc(g)是其加密函数,那么它存在以下关系(被称为数学同态):
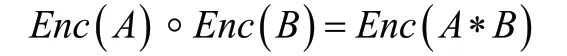
通俗地讲,密文域进行◦操作相当于在明文域进行∗操作(◦和∗是两种特定的数学运算)。这种性质使得加密数据的处理、分析与检索等操作成为可能,同时在云计算趋势下该技术具有极其重要的应用价值。下面以简单例子进行阐述:如图6表示,假设在不可信的云环境中,员工C1上传两个密文数Enc(A)和Enc(B),到不可信的云平台中,员工C2提交两个明文数据进行∗的任务,那么公有云平台翻译过来的数据执行动作为:密文操作Enc(A))◦Enc(B)。由于数据从始至终一直处于加密状态,那么无论是云服务厂商,还是攻击者他们都将无法访问或窃取明文数据,从而保障了云平台的数据安全。

图6 同态加密在云平台应用Fig.6 Homomorphic encryption in the cloud
根据同态加密能力,将同态加密分为加法同态、乘法同态和全同态加密(Full Homomorphic Encryption,FHE)。其中,全同态加密可同时满足加法同态和乘法同态,同时可执行任何次数的加和乘运算后仍具有同态性。全同态加密方案具有重要的理论与应用价值。2009年IBM的研究人员Gentry首次提出了一个完整的FHE方案[16]。但研究发现,Gentry方案计算开销较高,且密钥规模、密文尺寸较大。随后,一些改进方案被提出,例如BGV方案、基于误差学习(Learning with Errors, LWE)、理想陪集问题(Ideal Coset Problem,ICP)、整数上的近似最大公因子问题(Approximate Greatest Common Devisior,AGCD)等方案。
在工业界应用上,微软有在Github开源的同态加密库SEAL;IBM公司将同态加密(FHE)在Linux系统的应用工具进行开源——FHE Toolkit Linux,以及IBM同态加密库HElib;Duality公司推出同态加密SecurePlus平台[17],图7是该平台在金融领域应用,通过应用同态加密技术可使得敏感数据在整个处理生命周期中,始终保持加密状态,用户无需解密即可计算和分析数据。也就是说,平台用户可在遵守隐私和金融法规下,即不暴露敏感的个人或商业信息前提下,实现交易查询、实体和账户及金融犯罪信息的调查。然而,现有的同态加密技术与方案需要消耗大量的计算资源、存储资源(体现在高额的实现成本)是目前实用化的主要挑战,目前只能应用和部署在安全要求较高的特定场景中,离广泛的商业应用仍然有一段较长的距离。

图7 Duality SecurePlus平台在金融数据查询的应用(图引自[17])Fig.7 Application of Duality SecurePlus platform in financial data query(cited from Ref.[17])
2.4.3 安全多方计算
同上一节的欧盟GDPR规定(第32条)和我国《网络安全法》规定(第21条)的相关合规性要求。在传统的多方数据共享与计算场景,各方需将各自的敏感数据分别上传至服务器后,再进行计算。然而该方案仍然存在第三方隐私窃取问题。因此需提出“去中心化”的隐私保护方案。
安全多方计算(Secure Multi-party Computation,MPC)正是实现以上安全与合规目标的一类重要技术方案。它可以看作是多个节点参与的特殊计算协议,即在一个分布式的环境中,各参与方在互不信任的情况下进行协同计算,输出计算结果,并保证任何一方均无法得到除应得的计算结果之外的其他任何信息,包括输入和计算过程的状态等信息。它解决了在不信任环境下多个参与方联合计算一个函数的问题[18]。为了阐述原理,图8给出了安全多方计算与传统分布式计算两种模式的区别。

图8 安全多方计算与传统分布式计算的比较:(a)传统分布式计算;(b)安全多方计算Fig.8 Comparison between secure multi-party computing and traditional distributed computing: (a)Traditional distributed computing; (b)Secure multi-party computing
MPC具有以下的特点:(1)隐私性:参与方仅限于获得自己一方的输入和输出数据,除此之外,其他方的数据无法获得。(2)正确性:可确保联合计算之后所有参与方都能获得正确的计算结果。(3)去中心化:不同于传统的分布式计算,在安全多方计算中提供了一种去中心化的计算模式,各参与方的地位平等,不存在拥有特权的第三方。
实现多方安全计算协议主要有基于混淆电路(Garbled Circuit,GC)、秘密分享(Secret Sharing,SS)和同态加密三种方式。根据支持的计算任务场景可分为专用MPC和通用MPC两类。其中,专用MPC支持特定计算任务的MPC,比如比较数值大小、隐私求交集(Private Set Intersection,PSI)计算协议等;而通用场景MPC理论上可支持任何计算任务,它具有完备性。
在工业应用中,两方计算技术发展较为成熟,目前有多种实现方案,比如2004年发布的Fairplay系统是第一个实现的系统;Google使用PSI技术对Chrome用户的其他网络账户密码进行泄露密码库的检测,同时保证无法获取原始密码信息。对于多方计算,在某些特定场景下也具有较好性能,然而通用的场景具有诸多挑战,例如扩展性问题、效率问题以及诚实性问题(输入方可能输入虚假数据或篡改状态数据),这些问题亟需未来进一步研究与解决。
2.4.4 联邦学习
同2.4.2节的欧盟GDPR规定(第32条)和我国《网络安全法》规定(第21条)的相关要求。传统的分布式机器学习主要用于解决计算瓶颈,但无法保障输入数据与隐私的安全。具备隐私保护的机器学习成为新一代机器学习发展的关键需求。
联邦学习(Federated Learning, FL)正是满足以上隐私与安全需求的一类机器学习方法。它的概念最早由Google在2016年提出[19],原本用于解决大规模Android终端协同分布式机器学习的隐私问题。作为一种新兴的技术,联邦学习有机融合了机器学习、分布式通信,以及隐私保护技术与理论。
随着全球隐私法规的强化,以及数据挖掘需求的旺盛,自从联邦学习概念提出以来,在学术界和工业界受到广泛的关注与研究,发展十分迅速,不仅可应用于2C场景——如用户移动设备,还推广到了面向企业场景——企业组织间的敏感数据共享与机器学习。联邦学习可以使得多个参与方(如企业、用户移动设备)在不交换原始数据情况下,实现联合机器学习建模、训练和模型部署。简单来看,联邦学习它是一个可隐私保护的分布式机器学习框架与算法。
按照参与方使用数据集的场景不同,联邦学习分为三种类别:横向联邦学习、纵向联邦学习和迁移联邦学习。横向联邦学习各方使用的不同数据集,其样本的维度大部分是相同的,但各方的样本ID是不同的;纵向联邦学习各方使用的数据集样本ID大部分是相同的,但各方的样本维度是不同的;迁移联邦学习各方使用的数据集样本具有高度的差异,即样本ID和样本维度仅有少部分的重叠。
联邦学习的核心思想是在保证原始数据不出本地域情况下,实现多方的数据共享与联合建模。那么,多方建模过程涉及的原始数据需进行转换,联邦学习首先将原始数据进行特征化、参数化过程保证了原始数据的“不可见”;同时通过对提取的特征向量、参数用差分隐私、同态加密或安全多方计算技术避免数据重构攻击、模型反演攻击导致的隐私泄露。
联邦学习近年来在工业界得到了广泛关注,国内外多家企业开展了探索,并且开展了一些商业化落地案例。例如谷歌将联邦学习应用在Android手机的新闻推荐、输入法Gboard,并推出 TensorFlow Federated联邦学习开源框架;Intel 将TEE(可信任执行环境)技术与联邦学习进行结合;国内的以微众银行为代表的企业将联邦学习应用在保险定价、图像检测等领域,并开源了FATE联邦学习框架。然而,总的来说,联邦学习的发展仍处于初步发展阶段,当前仍面临诸多挑战,例如:如何解决参与方诚信问题,如何设计联邦学习框架有效的激励机制,高效通信机制研究,以及探索更多联邦学习的应用场景。
3 总结与展望
在全球数据安全法规监管的不断强化趋势背景下,合规性成为了企业数据安全建设与治理的重要驱动力。在合规视角下,数据安全的内涵在合规与业务安全双重需求驱动下不断外延和扩展,安全问题的日益凸显及数据安全覆盖的应用场景将变得更加多样化,这给传统的数据安全技术与解决方案带来了巨大的挑战。为此,本文引入十种前沿的数据安全技术,包括知识图谱、用户实体行为分析、同态加密、安全多方计算、联邦学习和差分隐私等;根据这十种技术的发展起源与功能特点,将其映射到三大类企业数据安全场景——用户隐私合规、数据安全治理、数据共享计算,本文详细剖析了这三类场景的合规要求与安全挑战,同时分别阐述和探讨这些技术的原理、应用以及当前面临的挑战。
从宏观视角看,数据安全领域当前面临诸多关键性挑战,亟需未来进一步解决。首先,数据安全建设是一个系统性工程,不仅要靠技术也需靠管理,如何建立完善的数据安全管理体系和技术体系,充分利用和发挥好技术与管理的关系,如何将新型技术与成熟技术(如加密、去标识化等)进行有效结合等是重要的关注点;其次,数据安全建设是一个长期持续改进的过程,需研究与建立一套基于数据安全风险管理的评估模型,通过“风险识别-风险控制-风险评估”的闭环迭代,持续进行改进与优化;最后,需强调的是数据安全与数据应用不应是矛盾与对立的关系,如何平衡两者的关系,在保障数据安全的同时让数据价值最大化,未来需从技术的理论和应用两个角度开展深入研究。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
工会博览(2022年16期)2022-07-16 05:53:54
今日农业(2022年1期)2022-06-01 06:17:42
吉首大学学报(自然科学版)(2020年2期)2020-09-14 08:15:02
五邑大学学报(自然科学版)(2020年1期)2020-06-17 04:13:04
绿色中国(2019年14期)2019-11-26 07:11:44
电子制作(2019年14期)2019-08-20 05:43:42
当代贵州(2018年21期)2018-08-29 00:47:20
电子制作(2017年20期)2017-04-26 06:57:48
信息安全研究(2016年3期)2016-12-01 06:06:28
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
