
一种基于改进DBSCAN的雷达信号分选算法
2021-07-23 10:17周一鹏肖冰松王洪迅
空军工程大学学报 2021年3期
王 星, 陈 相, 周一鹏, 陈 游, 肖冰松, 王洪迅
(空军工程大学航空工程学院, 西安, 710038)
信息化条件下,电磁空间成为继海、陆、空、天之后的第五维战场空间,电子侦察系统通过截获电磁空间中密集的信息流,为战场态势感知和辅助干扰决策提供情报支撑[1]。雷达信号分选是电子侦察系统的初始环节,信号分选问题本质上是将侦察接收机侦收到的不同雷达辐射源信号进行分离的过程,是电子战得以成功实施的重要前提,对整个电子战系统具有重要的影响。
从机器学习的角度来看,聚类过程是无监督学习过程[2-3],聚类算法能够在无标记训练样本的条件下将原始数据进行分组,从而发现数据的内在结构。目前常用的无监督聚类算法主要包括:基于层次、基于密度、基于划分等几大类。DBSCAN算法是一种密度聚类算法,它不需要先验的聚类簇数量,并且能够分选出各种形状的聚类簇[4],算法复杂度低,适合于雷达信号的自分选。但该算法对聚类参数较敏感,且聚类参数是根据先验知识人为设定的,可靠性不高;同时DBSCAN算法适合于处理密度相对比较均匀的数据,当不同簇的密度变化较大时,DBSCAN分选效果不佳。为了克服传统DBSCAN算法的缺陷,李文杰等[5]提出的KANN-DBSCAN算法结合参数寻优策略,利用数据集自身的分布特性寻找最优分选参数,无需人为赋值,便能够实现全过程无监督聚类,但该算法复杂度较高,在处理数据量较大的数据集时效果不佳;OPTICS算法[6]是根据DBSCAN算法思想演化而来的一种基于层次密度的分选算法,最终得到带有可达距离和核心距离的输出数据,该算法对参数不敏感,但仍然需要聚类参数的人为输入,对于不同的输入,聚类结果有较大差异;胡健等提出IABC-DBSCAN算法[7],利用人工蜂群算法强大的全局和局部优化特征寻找DBSCAN算法中的最优聚类参数,可有效克服DBSCAN算法对聚类参数敏感问题,但并未完全解决DBSCAN算法全局参数设置问题。
随着新体制雷达信号处理能力的不断提高,波形参数捷变、数字波束合成等数字化技术普遍应用,使得新体制雷达信号的变化方式日益复杂,同时雷达与侦察接收机在空间上的距离位置、雷达的不同工作状态、以及雷达的不同工作体制等使得接收机侦收的雷达信号具有非均匀、多密度、脉冲数据量大、脉冲参数交叠严重等特点[8]。并且先进体制雷达如相控阵雷达的工作模式多样[9],往往集多种体制于一身,使得侦收到的信号具有很大的不确定性。在实际分选处理中,往往会将同一雷达的不同模式分选成多部雷达,造成分选“增批”问题,给雷达信号分选带来了巨大挑战。
针对上述问题,本文提出了一种CMDBSCAN算法,该算法首先结合距离曲线倾角突变的特点自适应获得邻域半径,并根据雷达信号在参数空间中的分布密度,相应地调整密度点数阈值,进而能够根据空间的密度分布特点自适应生成分选参数;之后结合多维云模型理论,利用逆向云发生器算法和三维正向高斯云算法[10],对DBSCAN分选结果进行有效性评估,利用反馈的判定结果,进一步优化DBSCAN算法邻域参数,提高DBSCAN算法的分选准确性和可靠性。
1 改进DBSCAN分选算法
1.1 DBSCAN算法聚类原理
DBSCAN算法以数据的稠密程度作为划分簇的依据,分类效果主要由一组“邻域”参数(Eps,MinPts)决定。给定数据集D={x1,x2,…,xm},给出几个重要概念的定义:
定义1Eps邻域。也称为ε邻域,对于数据点xj∈D,其Eps邻域定义为样本集D中与xj距离不大于Eps的样本对象xi的集合,即NEps(xj)={xi∈D|dist(xi,xj)≤Eps}。其中,dist(xi,xj)表示2个样本点之间的距离刻画。
定义2核心对象。给定整数MinPts,若样本xj的Eps邻域范围内包含的样本数量不小于MinPts,即满足|NEps(xj)|≥MinPts,则称xj为(Eps,MinPts)条件下的核心对象。
定义3密度直达。若样本xj在核心对象xi的Eps邻域范围内,即满足xj∈NEps(xi)且NEps(xi)≥MinPts,则称xj是从xi密度直达的。
定义4密度相连。对于对象xj和xi,若存在一个对象xk,使得xj和xi与xk均满足密度可达关系,则称xj和xi是密度相连的。
图1中直观地显示了以上定义,图中虚线圆是Eps邻域,设定MinPts=3。DBSCAN算法首先遍历出样本集D中所有核心对象,任意选择其中一个作为初始样本,然后找到这个核心对象最大密度相连样本集作为一个聚类类别,最后剔除已分类的样本,从剩余的核心对象中任选一个生成下一个聚类簇,重复以上步骤,直到核心对象集合为空。

图1 DBSCAN定义示意图
1.2 DBSCAN算法改进
DBSCAN算法聚类准确性与邻域参数(Eps,MinPts)密切相关,一般情况下邻域参数Eps和MinPts是根据人工经验设定的,具有不确定性。因此,研究如何自适应获取邻域参数对提高算法准确度和稳定性具有重要意义。
1.2.1 自适应获取邻域参数Eps
为解决参数设置问题,文献[11]采用K距离曲线法确定参数。根据文献[1],实现成功分选雷达信号所需的脉冲数通常取4~7,首先假定参数MinPts=4,遍历整个样本集D,计算样本xi与周围点的距离,找到最近第MinPts个样本点距离Dist(x),求出序列:{Dist(x1),Dist(x2),…,Dist(xm)};之后将序列按数值大小排序并绘成曲线,如图2所示。将图2中曲线开始快速上升处(即A点位置)的Dist值设置为Eps邻域。

图2 排序的Distmin曲线
上述方法寻找A点依然需要人为参与,本文对此方法进行改进,首先将序列{Dist(x1),Dist(x2),…,Dist(xm)}排序后记为{di|i=1,2,…,m},对序列{di}进行差分处理,得到差分序列{Δdi}:
Δdi=di+1-di
(1)
由于在A点距离曲线倾角变化最为显著,因此以倾角的变化作为依据寻找A点,进一步求{Δdi}的反三角函数,求得曲线在各点的倾角:
(2)
式中:α是缩放因子,避免由量级引起的Δdi的数值过大或过小。得到曲线各点的倾角后,再对角度进行差分处理,求出角度差分序列{Δθi}:
Δθi=θi+1-θi
(3)
最后寻找差分序列{Δθi}的最大值所在位置Pmax,Pmax所在的位置即对应到图2距离曲线倾角变化最为显著的A点,从而确定出Eps值。
1.2.2 设定变密度点数阈值
在战场环境中,侦察接收机侦收的雷达信号在参数空间中的分布具有非均匀、多密度的特点。这种非均匀、多密度分布的形成原因与雷达和侦察接收机的距离、雷达工作状态以及雷达工作体制密切相关。
若采用全局参数(Eps,MinPts),聚类过程中的判别标准相对单一,对于非均匀、多密度的雷达信号分选效果不佳。因此,在自适应求得邻域半径值之后,利用Eps值对雷达信号空间密度进行描述,增强算法对多密度雷达信号的适用性。
首先利用1.2.1中的方法自适应获得Eps值,之后计算数据集D中每一个样本点的Eps邻域范围包含的雷达样本点个数,将该数值记为样本点邻域密度特征值K,按照降序的方式将数据点邻域密度特征值K进行重新排序,数据排列的顺序表明了样本点所在簇密度大小。

1.3 改进DBSCAN算法实现步骤
信号参数由脉宽(PW)、载频(RF)和达到角(DOA)3种特征组成。已知样本空间中n个雷达信号组成的样本集D={x1,x2,…,xn},其中xi=(PWi,RFi,DOAi),基于改进DBSCAN聚类算法具体流程如图3所示。改进DBSCAN算法具体步骤:
输入:雷达信号数据集D
步骤1利用K距离曲线法计算MinPts=4时的距离序列{Dist(x1),Dist(x2),…,Dist(xm)};
步骤2引入差分的方法,利用反三角函数对距离序列预处理,自动获取邻域参数Eps值;
步骤3计算数据集D中每一个样本点的邻域密度特征值K,即在Eps邻域范围包含的样本点个数,并按照逆序排列;
输出:最终的簇划分C={C1,C2,…,Ck}
2 基于三维云模型的隶属度均值
2.1 云模型基本概念
云模型是一种可以实现在定性概念与定量数据之间不确定性转换的模型,反映了概念中随机性和模糊性[12]之间的关联。云的数字特征用3个数值进行表征:期望值Ex、熵En、超熵He,它们反映了定性概念C在总体上的定量特征[14]。其中,Ex表示云滴在论域空间U上分布的期望值,是最能反映该定性概念的点;熵En表示对定性概念C的不确定性度量,反映总体的离散程度[15];超熵He是对熵的不确定性度量,反映数据的凝聚程度。
设U代表用精确数值表示的论域,U可以是一维或高维的,C(Ex,En,He)表示U上的一个定性概念,若定量数据x(x∈U)是定性概念C(Ex,En,He)的一次随机实现,则x在论域U上的分布是一个隶属云,每个x是隶属云上的一个云滴[13]。
2.2 云模型隶属度均值计算
将基于改进DBSCAN聚类算法的每个分类簇看作一种定性概念,设第m个簇的信号样本n为xmnk,m=1,2,…,M,n=1,2,…,N,k=1,2,3,其中M代表分选簇的总数目,N代表每个簇中信号样本的总数,本文k=3,选取原始信号内的特征参数PW、RF、DOA作为分选向量,并且设xmn1为信号样本n的DOA参数,xmn2为RF参数,xmn3为PW参数。
改进DBSCAN算法聚类结果之间的相似度可以根据云模型隶属度进行判定,云模型隶属度均值计算原理如图4所示,主要包括逆向云模型发生器算法和三维正向高斯云算法两部分内容。

图4 云模型隶属度均值计算流程
2.2.1 逆向云发生器原理
由于输入样本点数据不带有确定度信息[16],无确定度逆向云发生器算法主要根据高斯云分布的数学性质求出Exk,Enk和Hek3种数字特征[17],逆向云发生器如图5所示。

图5 逆向云模型发生器
根据样本数据的一阶绝对中心矩和二阶中心矩逆向云发生器算法[18],求出样本一阶绝对中心矩和二阶绝对中心矩,如式(5)、(6)所示:
(4)
(5)
(6)
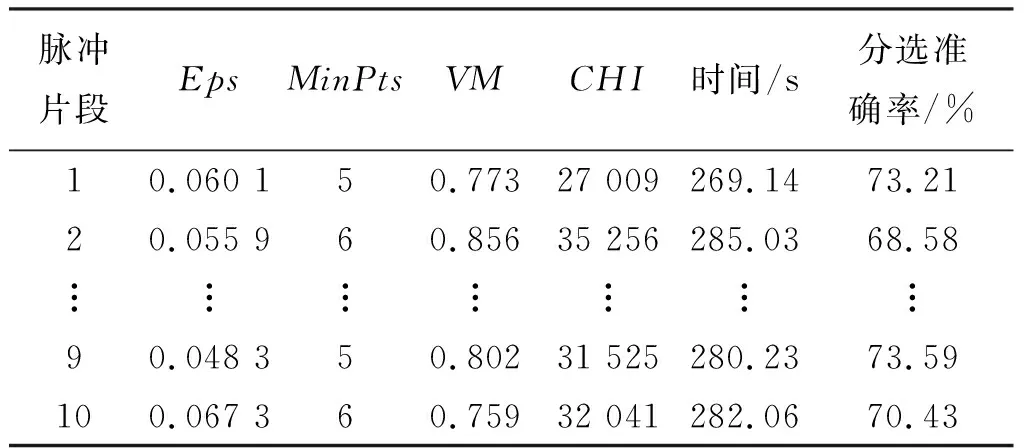
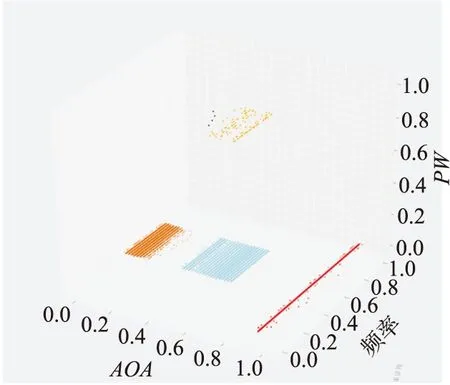
利用高斯云分布的性质[19]:在0 (7) (8) D(X)=Enk2+Hek2,k=1,2,3 (9) (10) 2.2.2 基于三维正向高斯云算法的隶属度计算 根据逆向云发生器得到的数字特征,将分选信号的PW、RF、DOA三维特征参数进行整合,每一分选类的总体数字特征可以表示为(Ex1,Ex2,Ex3,En1,En2,En3,He1,He2,He3),根据云模型理论,每一分选类可以抽象为一个定性概念,分选结果的总体数字特征是每一分选类的定性概念在总体上的定量描述。 根据多维正向云发生器原理[20],见图6,生成雷达辐射源信号的三维隶属云模型。首先产生一个以三维数据(En1,En2,En3)为期望,(He12,He22,He32)为方差的三维高斯随机数(En1′,En2′,En3′),其中每一维度的Enk′均是以Enk为期望,Hek2为方差生成的高斯随机数,其中k=1,2,3。 图6 三维正向云模型发生器 根据云模型理论,钟形隶属函数对模糊概念的分析具有普遍性,生成三维隶属云模型: μj(xil)= (11) 式中:μj(xil)代表分选簇i中的第l个信号对分选簇j构成的三维云模型的隶属度,其中i,j=1,2,…,M,l=1,2,…,N,xil代表第i个分选簇中第l个信号样本,Exjk,k=1,2,3表示第j个分选簇信号的第k维特征期望值。 2.2.3 聚类结果隶属度均值计算 式(11)表示其他分选簇中的三维信号样本对某一分选簇构成的云模型相似度。利用式(12)求出簇与簇间隶属度均值Eμji进行分选簇之间的相似度判定: (12) 从多维云模型理论分析,每一个分选簇都被抽象成了三维云模型所代表的定性概念,隶属度均值Eμji表示聚类结果i中所有三维信号样本隶属于某一定性概念程度的平均度量[21]。 利用基于三维云模型的隶属度均值和目标脉冲到达角参数实现改进DBSCAN分选结果有效性评估的CMDBSCAN分选模型如图7所示。 图7 CMDBSCAN分选模型 具体求解步骤如下: 步骤1首先结合距离曲线倾角突变的特点自适应获得邻域半径,并根据雷达信号在参数空间中的分布密度,相应地调整密度点数阈值,进而能够根据空间的密度分布特点自适应生成分选参数; 步骤2将基于改进DBSCAN算法分选簇抽象成定性概念,利用逆向云发生器算法和三维正向高斯云算法得到不同分选簇之间的隶属度均值Eμji。 步骤3选取每个聚类结果的脉冲到达角DOA均值ExDOA作为该目标辐射源的DOA参数。 步骤4利用如下规则进行评估判定: 1)若隶属度均值Eμji,Eμij均小于自适应阈值生成算法[22]求出的τμ,说明雷达辐射源信号间相似程度低,聚类分选结果正确度较高,符合分选结果有效性准则,直接输出分选结果,并将对应类的雷达脉冲数据从数据集中删除。 2)若聚类结果i与j相互之间的隶属度均值Eμji,Eμij均大于τμ时,计算聚类结果间脉冲到达角均值ExDOA的差值ΔDOA=|ExDOA(a)-ExDOA(b)|: a.若差值ΔDOA小于设定阈值τDOA,说明2个聚类结果之间有着较大的聚类相似度,认为第i、j个分选簇为一部雷达的多种工作模式,将2个分选簇合并为一类,输出分选结果,并将对应类的雷达脉冲数据从数据集中删除; b.若差值ΔDOA大于设定阈值τDOA,表示虽然2个聚类结果之间有着较大的聚类相似度,但并不属于同一辐射源,将分选结果保留在数据集中。 3)当隶属度均值Eμji,Eμij只有其中一个大于设定阈值τμ时,说明第i类与第j类之间信号交叠严重,将分选结果保留在数据集中。 步骤5将评估结果反馈到DBSCAN算法中,优化邻域参数(Eps,MinPts),对数据集中剩余脉冲重新进行计算,使最终聚类符合分选结果有效性准则。 步骤6输出最终分选结果。 为了模拟实际战场电磁环境,假设空域内共有20个平台参与作战想定,我方侦察接收机部署于某一飞机平台,通过仿真实验模拟平台间的复杂对抗过程,仿真结束后导出侦察接收机帧收的信号全脉冲参数。 在仿真作战过程中,不同作战平台的雷达装备服务于不同作战任务,并且不同作战平台在整个作战过程中的参与阶段和介入时间根据作战过程的演变而变化,其雷达的开关机时间也相应变化,因此帧收到的雷达信号具有非均匀、多密度、数据量大等特点。 首先通过基于载频和脉冲到达角分区方法[1]对海量脉冲数据进行稀释,选取脉冲数据较丰富的第2分钟内的X波段,方位在80°~160°内的941 312个脉冲作为实验数据,如图8~10所示: 图8 脉冲到达角-到达时间二维图 图9 载频-脉冲到达时间二维图 图10 脉宽-脉冲到达时间二维图 从稀释数据中抽取10个信号片段,每个信号片段的脉冲数量为30 000条,对比本文算法、原始DBSCAN算法、KANN-DBSCAN算法的分选性能。本文算法的邻域参数(Eps,MinPts)通过结合距离曲线倾角和邻域密度特征值自适应获得,KANN-DBSCAN算法的分选参数通过参数寻优策略确定[5],原始DBSCAN算法参数通过人工赋值。 聚类效果内部指标用Calinski-Harabasz分数(CHI)表示,计算方法如下: (13) 式中:CHI表示k个聚类结果簇内散度与簇间散度之比;其中Bk为分簇之间的协方差矩阵;Wk为分簇内部的协方差矩阵。CHI指标取值越高表示分簇之间距离越大,簇内越紧密,聚类效果越好。 聚类效果外部指标用V-测度衡量,V-测度(VM)由Andrew Rosenberg[23]等人提出,是基于条件熵衡量聚类结果与真实分簇的同质性和完整性的指标,其定义为: (14) 本文V-测度的取值范围为[0,1],取值越大说明分选效果越好。 表1~3为3种算法在各信号片段上的聚类分选结果,表4为3种算法聚类分选指标平均值的对比结果。 表1 DBSCAN算法实验结果 表2 KANN-DBSCAN算法实验结果 表3 本文算法实验结果 表4 3种算法实验指标平均值对比 从表1~4可以看出,CMDBSCAN算法的内部指标CHI远大于原始DBSCAN和KANN-DBSCAN算法,因为DBSCAN算法结合多维云模型,利用聚类结果间隶属度均值进行相似性判断,可有效提高DBSCAN算法对多模雷达信号的分选能力,避免分选结果中的“增批”问题。CMDBSCAN算法的聚类结果通过云模型进行有效性评估,使得聚类结果簇间分离程度更大,同时簇内数据聚合程度更好,内部指标CHI更高,分选效果有较大提高。 外部指标VM反映了聚类结果与真实数据之间的相关性,与分选准确率指标具有相似性。利用抽取的10个仿真数据片段,从表1~3中可以观察到本文算法在外部指标VM、分选准确率上都优于原始DBSCAN算法和KANN-DBSCAN算法,可有效提高分选准确率。 由于DBSCAN算法需要检索每个雷达脉冲点邻域内所有数据点,时间复杂度为O(n2),其中n为全脉冲雷达数据点数,由于KANN-DBSCAN算法结合参数寻优策略,迭代计算复杂度与参数K密切相关,时间复杂度为O(Knlbn),在文中雷达脉冲数据集条件下K=62。而本文采用K-d树结构,可有效遍历特定点给定距离内的雷达脉冲点,时间复杂度变为O(nlbn),同时本文引入云模型理论对分选结果进行有效性评估,三维云模型的时间复杂度为O(3n)。综上CMDBSCAN算法的时间复杂度为O(nlbn)+O(3n)。在大数据量条件下,原始DBSCAN算法对2个分选参数敏感,需要一定时间调试,并且时间复杂度呈指数式增长,CMDBSCAN算法可有效解决上述问题。 以片段10为例,图11~14分别展示了片段10中原始数据和3种算法的聚类结果分布,各参数取值范围为[0,1],且各参数的单位取值为1。从图中可以看出:原始的DBSCAN聚类算法结果存在明显的聚类误差,将4个辐射源的30 000条数据归为了6类,由于原始的DBSCAN算法采用全局固定的邻域参数(Eps,MinPts),对于密度分布不均匀的雷达信号,分选效果较差。KANN-DBSCAN算法结合参数寻优策略,无需人为赋值,能够实现全过程无监督聚类,如图13所示,分选效果有较大改进,能够实现雷达信号的基本分选,但是在处理非均匀、多密度的雷达信号时仍然存在一定误差,因为KANN-DBSCAN参数寻优方法求出的分选参数(Eps,MinPts)依然是全局参数,未能改变DBSCAN算法的固有缺陷。 图11 片段10原始数据分布 图12 原始DBSCAN聚类分选结果 图13 KANN-DBSCAN聚类分选结果 图14 CMDBSCAN聚类分选结果 从图11~14几种算法分选效果对比可以看出,CMDBSCAN算法的分选效果表现最好,除了部分离散点以外,其他数据均被正确聚类。由于CMDBSCAN算法能够自适应获得邻域半径,并且根据不同雷达信号在参数空间中的分布密度,相应地调整密度阈值,适用于非均匀雷达信号的分选,克服了传统DBSCAN算法的固有缺陷。并且结合云模型理论对分选结果进行有效性评估,可有效避免传统DBSCAN算法在多功能雷达信号分选中的“增批”问题,具有更强的信号分选能力。 电子对抗侦察中的雷达信号分选是将截获的雷达信号分离的过程,具有非合作性,属于无监督学习问题,DBSCAN算法是一种无监督的密度聚类算法,可自动分选任意形状的聚类簇,符合实际战场电子侦察需求。本文提出一种CMDBSCAN算法,首先从自适应获得Eps邻域半径和设置变密度点数阈值两个方向针对传统DBSCAN算法缺陷进行改进,仿真实验表明,该算法可实现对非均匀、多密度、大数据量的雷达信号进行有效性分选;最后结合多维云模型理论,将改进算法分选结果送入评估模型,结合逆向云发生器算法和三维正向高斯云算法,对分选结果进行有效性评估,利用判定结果进一步优化参数设置,仿真结果表明,DBSCAN算法结合云模型理论后可有效处理参数交叠严重、工作模式多样的雷达脉冲信号,提高了DBSCAN聚类算法的分选准确率。
3 CMDBSCAN算法分选模型

4 仿真实验分析









5 结语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
大数据(2022年4期)2022-07-25
农业工程学报(2022年7期)2022-07-09
逻辑学研究(2021年3期)2021-09-29
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
