
基于注意力机制的多尺度实时人脸检测方法
2021-07-20 00:05王皓洁孙家炜
现代计算机 2021年15期
王皓洁,孙家炜
(1.四川大学计算机学院,成都610065;2.四川川大智胜软件股份有限公司,成都610045)
0 引言
在传统方法中,人脸特征是基于手工特征选取的,2001年Viola和Jones提出V-J(Viola-Jones)[1]框架,利用Haar特征和AdaBoost进行特征选择,通过检测级联决策结构提高准确率,该方法在人脸检测领域取得了突破进展,在有限的计算资源下做到了实时检测,极大的推动了人脸检测应用商业化的进程。后来很多研究者在三个方面基于V-J框架进行改进,一方面设计新的特征,一方面使用其他类型的AdaBoost分类器,还有一方面是对分类器级联结构进行改进。例如ACF[2]是一种提供足够多的特征的方法。新的分类器级联结构如soft cascade[3]。2008年Felzenszwalb等人[4]提出可变形组件模型(Deformable Part Model,DPM),是一种基于人脸组件的检测的算法。DPM算法对目标的形变有很强的鲁棒性,对夸张表情、多姿态、多角度等的人脸都具有非常好的检测效果。但是其性能表现一般、稳定性较差。
传统方法基于手工选取的人脸特征,虽然计算高效,但是在多尺度、多姿态、多角度、遮挡、模糊等情况下的检测精度差强人意。
利用深度学习技术检测人脸的方法大致可以分为两类:两阶段检测器(two-stage)和单阶段检测器(onestage)。two-stage方法首先获得一定数量的预选区域(Region Proposal,可能存在目标的区域),然后再对每个预选区域进行分类和回归。one-stage方法可以经过一次网络就得到目标的位置和分类信息。Two stage从R-CNN[5]开始;之后出现的金字塔池化层[6]提供了网络输入图片多尺度的办法;Faster R-CNN[7]在Fast R-CNN[8]的基础上提出了预选区域提取网络(Region Proposal Network,RPN)候选框生成算法,使检测速度有了很大提升;Lin等人[9]基于Faster R-CNN提出了top-down结构和横向连接的金字塔特征网络(Feature Pyramid Networks,FPN)。one-stage方 法 以YOLO[10](You Only Look Once)为代表,对于检测效率有了极大提升。Single Shot MultiBox Detector(SSD)[11]引入不同尺度特征图做预测,大尺度特征图检测小目标,小尺度特征图检测大目标。
现实场景中环境复杂多样,多尺度、小人脸、姿态、遮挡、光照等因素会对人脸检测任务造成困扰,导致人脸检测的性能下降。然而高精度运算往往所需时间长,对算力的要求较高。因此,对于实际场景中的人脸检测而言,实现实时的检测速度并保持较高的精度是目前急需解决的问题。基于以上背景,本文提出一种轻量型、多尺度、基于注意力机制、实时的one stage人脸检测方法。使用多任务学习策略同时预测人脸框、人脸置信度和五个关键点来提高泛化能力,借鉴MTCNN[12]加入五个人脸特征点的检测有利于人脸框的回归精度。
1 设计方法
1.1 整体框架
本算法网络模型包括一个主干网络和三个检测模块,主干网络采用多个含有卷积层的块(Block)组成,同时利用批量归一化(Batch Normal)加快训练速度,提高模型精度,避免出现梯度消失和梯度爆炸的问题;首先从主干网络中提取三个不同尺度的特征层构建特征金字塔,进行特征融合,然后将三层分别送入3个检测模块(D1,D2,D3)中,分别检测小、中、大人脸。检测模块基于SSH[13]算法,采用多任务学习策略,包含目标分类、框体回归和人脸关键点回归操作;在检测模块中嵌入context module通过扩大感受野引入更多的上下文信息,对该模块使用了5×5和7×7的卷积分别进行操作;网络中不含全连接层,对输入分辨率没有限制,效率更高。总体来说,本文提出的检测算法在达到实时检测的情况下满足高精度要求,可应用于实际生产生活中。网络模型的整体结构如图1所示。

图1 模型总体结构图
1.2 主干网络设计
本文提出的主干网络构建了11个Block,每个Block中使用深度可分离卷积替代传统卷积层,将传统卷积层分为空间滤波和特征生成两部分,先使用单通道卷积融合空间信息,再使用逐点卷积融合特征的通道信息。该种方法有效分离了图像的区域和通道,计算量大幅减少,效率有很大提升,模型更轻量型。深度可分离卷积结构如图2所示。

图2 深度可分离卷积
图2中假设输入数据尺寸是W×W×C,W是特征图的尺寸,C表示特征图的通道数,首先使用C个3×3×1的卷积核进行单通道对应卷积;接着再通过N个1×1×C的点卷积操作融合各个通道的特征信息。使用该方式可大大缩减计算量,大约为传统卷积的1/9,效率大幅提升。
Block中引入了具有线性瓶颈的逆残差块结构,在逆残差结构中,首先使用膨胀系数提升通道数,然后再进行深度可分离卷积,最后压缩通道数,在算法中有两种瓶颈结构,一种是stride为1使用残差的瓶颈结构,另一种是stride为2,进行了下采样,未用残差的瓶颈结构。这两种结构如图3所示。

图3 逆残差结构
从高维度向低维度转换时,使用线性激活函数替代ReLU激活函数以避免数据坍塌造成的大量信息丢失。使用低维的网络优点是提升计算速度,缺点是提取不到足够多的特征信息,为了平衡模型的精度和效率,本文使用Expand系数扩展维度后再进行维度压缩。
Block中也引入了注意力机制,人类在观察一副图像时,会高效的分配有限的注意力,将注意力更多的投入到焦点区域,以获得重点关注的信息而摒弃无用的信息。在算法中,注意力机制依靠两个步骤,Squeeze操作和Excitation操作,首先对特征图进行Squeeze操作获得全局特征,然后对全局特征进行Excitation,获得各个channel的权重,最后将权重乘以原来的特征得到最后的特征。通过这种注意力模型,可以让模型学习到更重要的特征而抑制不重要的特征。Squeeze操作是通过全局平均池化层获得每个通道的一个全局特征。Excitation操作是将全局特征经过两个全连接层,第一个全连接层起降维的作用,第二个全连接层恢复原始的维度。通过这种方式,模型学习各个通道的权重系数,从而提升模型对特征的辨别能力。
注意力机制的结构如图4所示。
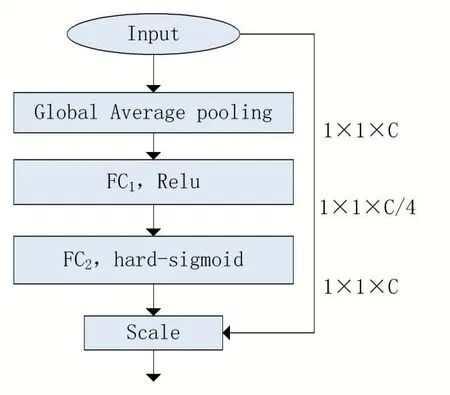
图4 注意力机制结构
图4中输入特征经过GAP(Global Average Pooling),输出大小为1×1×C,经过FC1层降维,输出尺寸为1×1×C/4,经过FC2层升维,输出尺寸为1×1×C,最后经过Scale操作,该操作是FC2层输出的权重系数与Input特征图对应通道相乘。
综上所述,主干网络中一个block组合了深度可分离卷积、逆残差结构和注意力机制,图5展示了主干网络中一个block的结构,在注意力机制中本文使用1×1的点卷积替换全连接层以适应不同尺度的输入图像。
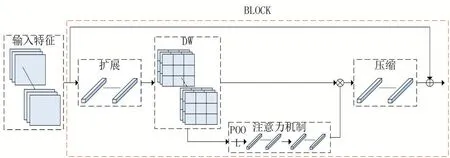
图5 主干网络block结构
1.3 特征金字塔设计
模型采用P3到P5的特征金字塔层,如表1所示,这三层分别下采样8、16、32倍,根据不同尺度的特征图采用不同尺度的anchor。

表1 特征金字塔anchor
如图1所示,具体过程为:提取主干网络中的Block3、Block8、Block11的三层,这三层的通道数分别为24、48、96,首先经过1×1的点卷积将通道数统一为64,输出表示为B3、B8、B11层,B11即为P3层,将B11层进行上采样,与B8层相加,再经过3×3卷积得到P4层,该操作是为了消除混叠效应。同样的,将P4层进行上采样与B3层相加,在经过3×3卷积得到P5层。
1.3 检测模块设计
检测模块基于SSH网络模型设计,主要是两个部分,一个是尺度不变性,通过不同尺度的特征层实现,D1、D2、D3结构相同,输入特征图的尺寸不同,分别为用来检测小目标人脸、中目标人脸和大目标人脸;另一个引入丰富的上下文信息,通过Context module实现。每个检测模块都包含了人脸分类、框体回归和特征点回归三条支路。如上表1所示,每条支路都设置了两个不同尺度的anchor,在本文中,anchor的长宽比为1。
如图6所示,输入的特征图尺寸为W×W×C,分别通过一个3×3的卷积和Context Module,将两个输出进行维度上的拼接,拼接后尺寸为W×W×C,最后使用三个1×1的卷积分别进行人脸分类、框体回归和关键点回归,获得W×W×(2×2)个人脸分类得分、W×W×(2×4)个框体回归坐标和W×W×(2×10)个关键点回归坐标。

图6 检测模块结构图
如图7所示,Context Module部分通过引入大尺度滤波器(5×5、7×7)的卷积来扩大感受野,获得更丰富的上下文信息,本文借鉴Inception[14]算法使用两个级联的3×3滤波器代替5×5滤波器,三个3×3滤波器级联代替7×7滤波器,节约了大概28%的计算量。

图7 Context Module结构图
2 训练
本文提出的算法是在PyTorch深度学习框架下设计训练的。算法使用公开数据集WIDER FACE的训练集进行训练,训练输入图片尺寸缩放为640×640,负例交并比阈值为0.35。采用动量梯度下降的方式训练网络。
2.1 正负样本均衡化处理
面对开集问题,我们需要检测器有较好的排除背景类别的能力,因此需要选取大量的背景作为负样本进行训练,本文中IOU低于0.35的anchor会被标注为负例,由于一张图上的人脸数有限而anchor数量庞大,所以会出现正负样本不均衡的问题,所以采用OHEM[15](Online Hard Example Mining,在线困难数据挖掘),将判定为负例的候选框损失值从高到低排序选择负样本,本文提出的算法训练时正负样本比例为1:7。
2.2 损失函数
对于训练的一个anchor,多任务损失函数定义如下:

3 结果分析
本文提出的算法使用公开数据集FDDB上进行评测,数据集包含2845张图片、5171个人脸,测试集在姿态、遮挡、旋转等方面有很大的多样性。评估指标使用真正率和假正数的关系绘制ROC曲线来客观评价本文算法对人脸检测的效果。图8为该算法与但近几年表现较好的RSA[16]、ICC-CNN[17]、Faster R-CNN[18]、Face-Boxes[19]、Scale-Face[20]、FD-CNN[21]、LDCF+[22]、BBFCN[23]、Fast R-CNN[24]算法进行对比,横纵坐标分别表示假正数和真正率。从图8中就可以直观的看出,本文提出的算法在人脸检测上的表现优于其他的算法,在假正数达到1000时,本文的真正率可以达到0.972。
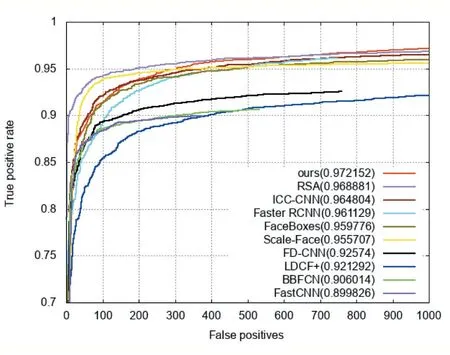
图8 FDDB数据集ROC曲线
本文使用FPS(每秒帧率)来评价算法的检测效率,在NVIDIA GeForce GTX 1080显卡上面的检测速度可达40FPS,可以达到视频级的检测。实验证明,该算法在普通的GPU上可以达到实时的人脸检测,并且检测精度很高,可用于实际的生产生活中。
4 结语
本文提出了一种轻量级、实时的人脸检测方法,该方法通过在逆残差结构中加入注意力机制,增强了模型对特征的辨别能力,抑制无用信息,提高了对目标的检测能力;构建特征金字塔结构,使得算法对多尺度目标同样具备非常好的检测效果;本文的算法可以实现one-stage检测,便于训练和测试;通过实验证明该算法在公开数据集的表现突出,并且能在GPU上达到实时的人脸检测。在未来的研究中,考虑到实际场景中检测设备配置有限,将会对网络进一步优化,提升在算法CPU上的检测效率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
奥秘(2021年5期)2021-06-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小雪花·初中高分作文(2017年9期)2018-05-21
米娜·女性大世界(2016年8期)2016-08-17
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
奇闻怪事(2014年5期)2014-05-13
