
基于智能相机的行人检测技术研究
2021-07-19 21:11方杰
电脑知识与技术 2021年15期
方杰


摘要:该文通过智能相机采集的图片,形成训练数据,并基于现有的行人检测算法,整理了行人检测的流程,提出并通过实验研究了训练模型以及更新策略,同时探讨了生成检测结果后的处理策略以及行人检测模型验证结果。
关键词:行人检测;模型训练;更新策略;YOLOv4-Tiny
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)15-0184-03
随着智慧城市及智能化产业的不断发展,视频监控以其直观、准确、及时和信息内容丰富而广泛应用于许多场合,尤其在安防领域中的重要性日益突出,成为技术安全防范最有力的手段。如今安防监控对高清化、智能化、网络化、数字化的要求也越来越高,数据呈现出爆发性的增长,同时,这些海量的视频数据为相关执法部门提供了足够的调查取证依据。文献[1]提出了不同视角下的行人重识别解决方法;文献[2]提出了光线照明环境下的行人重识别解决方法;文献[3]提出了基于度量学习的行人检测方法;文献[4]讨论人体结构特征的构建在行人检测上的研究;文献[5]把行人重识别问题看作分类问题或者验证问题。
本文基于目前国内外行人重识别的进展情况,使用通过智能相机采集的训练数据,在现有的训练模型基础上,调整算法和参数,构建更好的神经网络结构,以达到更快速更准确的效果。本文主要包含以下四部分内容: 行人检测的整体流程,行人检测算法解析,行人检测模型验证结果详解以及总结和挑战。
1 行人检测的整体流程
行人检测的流程大致过程如下:首先,对原始图片进行分辨率调整,使其调整为网络输入大小;其次,将图片输入网络模型,通过训练好的卷积神经网络进行预测;再次,根据预测结果计算出行人坐标,使用NMS算法去掉重叠框;最后,返回检测结果。
1.1 原始图片获取
原始图片直接通过智能相机采集获得,具体而言,可以通过两种方式获取。一种方式是智能相机的视频流,在视频流中截取出图片;另一种方式是智能相机直接采集图片。以上两种方式都能够获取训练样本和测试样本。
1.2 网络预测
通过上述方式得到图片数据后,然后进行图像预处理操作,包括以下几个步骤:
步骤1:在训练或者检测中,将所有原始图片调整至固定尺寸,实验中所使用的尺寸宽度为448px,高度为256px ,该尺寸是网络结构预设的输入Feature Map尺寸;
步骤2:去均值,归一化: 将图像三通道的值减去均值0,0,0;然后做标准归一化操作,将图像值除以255;
步骤3:再将预处理图片导入网络中, 进行前向传播, 对网络结果的输出进行信息处理, 最后通过输出层返回该图像中一系列框的坐标和置信度,目标类别。同时,每个坐标包括预测框的中心点坐标和预测框的宽和高。根据设定的框置信度过滤一系列的框,过滤后剩余的预测框作为输出。由于只有一个类别,检测类别为行人即可。
1.3 NMS算法去掉重叠框
由于上述方式得到的剩余框中有比较多的重叠, 需要在这个阶段处理掉这些重叠框。这些框有较高的置信度,我们最终只需要一个框作为检测框即可,所以需要使用NMS算法过滤掉多余的框。
1.4 检测结果转存
将网络输出结果进行乘以输入图片的宽度和高度,并进行转存,返回这张图片中行人对应的坐标,框置信度和类别概率。
2 行人检测算法解析
行人检测算法主要包括以下几个方面:网络结构解析、模型训练以及更新策略和阈值设置以及检测结果后处理。
2.1网络结构解析
实验所使用的模型采用YOLOv4-Tiny算法改造,使用了3个Resnet Block, 每个Resnet Block包含多层Convolution Layer,并进行组合, 每个Resnet block的基础通道数随着尺寸变小而增大。同时, 网络输入的Feature Map大小为448px*256px。
网络结构整体架构图如表1所示:
2.1.1 先验框部分Anchor
原始Yolov3算法使用了9个Anchor,输出层为三个。随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。Yolov3采用了Yolov2的k-means聚类算法得到先验框的尺寸,为每种采样尺寸设定了先验框,在微软发布的COCO数据集上9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。分配環节上,在最小的13*13特征图上使用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象,因为该特征图上每个像素点对应原图感受也最大。中等的26*26特征图上应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。而较大的52*52特征图上应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
2.1.2 输入到输出结构
输入到输出的总体结构如图1所示:
对于一个输入图像,Yolov3算法将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率和相应指标。上图中,如果使用416*416的输入图像,在每个尺度的特征图每个网格设置3个先验框,则计算后总共有10647个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,共有80种类别)。
2.2 模型训练以及更新策略
模型训练以及更新策略主要是进行模型训练的损失函数和相关的优化策略.首先分析预测边界框和检测框Anchor Boxes,及网络预测值tx,ty,tw,th之间的关系。Yolov3借鉴RPN网络使用Anchor Boxes来预测边界框的offsets。边界框的实际中心位置(x,y)需要利用预测的坐标偏移值,先验框的尺度(wa,ha)以及中心坐标(xa,ya)来计算,这里的xa和ya也即是特征图每个位置的中心点。上述公式为Faster-RCNN算法中预测边界框的方式。这个方式是没有约束的,也就是tx和ty的大小可以为任意值,导致预测的边界框容易向任何方向偏移。当tx >1时边界框向右偏移超过一个宽度大小,导致每个位置预测的边界框可以落在图片的任意位置,这就导致了模型训练的不稳定,在训练的时候要花很长时间才可以得到正确的offsets,但是有一个优点就是当这个像素附近出现密集目标时,本位置的Anchor被匹配完以后,其他位置的Anchor可以来匹配,可能一定程度上增加了目标框的召回率,充分利用了周边位置的Anchor,也是这个特性导致了训练的不稳定。在Yolov3中放弃了这种预测方式,二是沿用Yolov2的方法,就是预测边界框中心点相对于对应cell左上角的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmod函数处理偏移值,这样预测的偏移值在(0,1)范围内(这里每个cell的尺度看作为一,cell对应的就是输出Feature Map上的一个像素点)。后来Yolov4中发现,如果目标框刚好落在cell边缘上,就会出现预测的偏移值向0或者1偏移,导致sigmod输入值x无穷小或者无穷大,导致网络训练不稳定,所以在yolov4中采用了预处理预测值,也就是让预测值在(0.05,0.95)范围内。
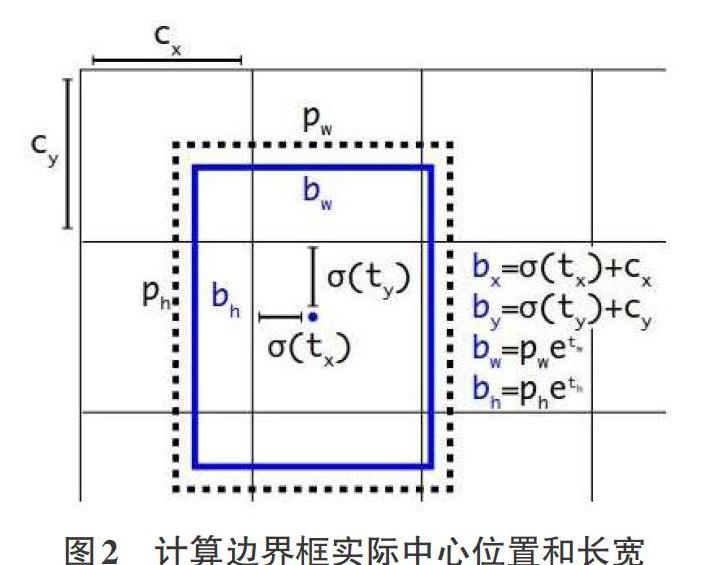
综上,根据边界框预测的4个偏移量tx,ty,tw,th,可以使用如下图中公式来计算边界框实际中心位置和长宽,如图2所示。
其中,(cx,cy)为cell的左上角坐标。如上图所示,当前的cell坐标为(1,1)。由于逻辑回归函数的处理,边界框的中心会被约束在当前cell的内部,防止偏移出cell,pw和ph表示先验框的宽度和高度,它们的值也是相对于特征图的大小。由以上值就可以计算出边界框相对于整个特征图的位置和大小,公式如图中所示。我们如果将上面边界框的4个值乘以输入图像长宽,就可以得到边界框在原图中的位置和大小,从而获得的目标检测框。
通过设定iou阈值将检测结果进行NMS(非极大值抑制处理),我们的目的是要去除冗余的检测框,保留最好的一个。其详细原理如下:对于bounding box 的列表B及其对应的置信度S,选择具有最大置信度的检测框M,将其从B集合中移除并加入最终的检测结果D中。通常将B中剩余检测框中与M的iou大于阈值Nt的框从B中移除,重复这个过程,直到B为空。其中常用的阈值为0.3-0.5.最后得到最好的一个框坐标。将坐标进行处理,分别乘以输入图片的宽和高,获得相对于输入图像的坐标。
2.3 检测结果后处理策略
检测结果后处理是对网络检测好的结果进行处理,处理的目的是尽可能地减少误检或者漏检目标。常常采用以下几种方式进行处理:
1)增大预测框过滤的阈值,常常采用0.5的阈值过滤前景和背景框,为了减少误检目标的情况,可以采用增大这个阈值的方式。
2)感兴趣区域绘制,测试图片中发现,误检或者漏检情况的出现,常常是图片中边缘的目标,我们绘制感兴趣区域一定程度上避免这种情况的出现。感兴趣区域的绘制如下图所示,图中蓝色框为感兴趣区域,红色框表示检测目标框。
3 行人检测模型验证结果详解
3.1不同训练次数测试指标变化曲线
测试不同迭代次数生成的训练模型的不同指标,从而获得各个模型对应的测量值。其中测量值有precision,recall,ap和平均iou值四个值。迭代次数10w次为一个单位。以下图片是在训练集上各个模型的各个指标变换曲线图。图3为精度,召回率和ap值在各个迭代次数下生成模型测试值。由于训练集有15.5w张,测试数据过大导致测试时间比较长,所以选择了杭州和东莞二个场景下的图片作为训练集来测试,这些图片也在训练集中。从下图可以看出,模型训练次数在30w次以前在震荡,40w次处生成的模型精度有提升,后续进入震荡变化。图4表示测试框平均iou值变换情况,结合图一可以看出,在40w—80w次迭代过程中,训练的模型主要的在调整框的坐标和尺寸大小。
接下来是在验证集上进行测试,测试方式和在训练集上测试相同,测试集中圖片数量为1500张,测试效果如图5和图6所示。从图5和图6中可以看出,模型在60w次出达到最优,不管是测试指标值,还是测试框的平均IOU值。
从上述在训练集和测试集中测试的曲线可以看到,训练过程完全存在过拟合的迹象,具体有以下几点: 1.结合图4到图7来看,模型的参数量级是能够拟合训练集,而且造成了过拟合,因为图6中指标出现了下降趋势;从图4训练集测试情况来看,batch size可以设置大一些, 大的batch size可以在训练过程中减少波动, 同时很多论文验证了适当调大batch不仅可以加速收敛, 还可以在一定程度上提升收敛程度;迭代次数过多,从第一点来看出现了过拟合情况,模型迭代到60w次就可以停止训练。训练初期模型主要是在提升指标值,在40w次就提升到最优,后续在60w前再调整框的尺寸和坐标。60w次以后出现过拟合情况,应该停止训练。在30w次到40w次迭代过程中有指标提升原因是学习率下降了,这里是否可以提早减小学习率以降低学习过程震荡过程,后续可以通过实验来验证。
4 总结和挑战
本文提出了一种基本能实现多种场景下行人检测算法,经过一系列的优化,效果上有提升,在保持效果的前提下,速度也得到了提升。但是行人检测也面临诸多挑战,比如对于行人这种形体多变的检测任务,需要更多适合不同行人形状的锚框,如果锚框增多就需要使用更多的训练数据集来训练模型。二是尽管本文的方法已经取得了一个不错的召回率,但是训练图片中行人比较少,在行人比较密集的情况,算法可能效果不佳。那么未来,可以搜集不同场景下的图片用来增加训练集更新模型,增加Anchor数量以更好减少检测框坐标回归的难度,提升检测框坐标回归的准确性和密集目标的召回率。
参考文献:
[1] 周刊,胡士强,吴桐.基于深度度量学习的行人重识别方法[J].传感器与微系统,2020,39(5):61-64.
[2] 梁晓琴.基于深度学习的行人重识别探究[J].中国科技信息,2020(18):70-71.
[3] 邓轩,廖开阳,郑元林,等.基于深度多视图特征距离学习的行人重识别[J].计算机应用,2019,39(8):2223-2229.
[4] 朱婷婷.基于度量学习和深度学习的行人重识别研究[J].信息与电脑,2019,(15):131-132.
[5] 王蕴绮,闫思伊,尹唯佳.基于深度学习的行人重识别经典算法研究[J].河南农业,2018(3):49-51,64.
【通联编辑:朱宝贵】
