
基于多尺度特征融合的无人车目标检测算法
2021-07-19 06:39李伟文
北京信息科技大学学报(自然科学版) 2021年3期
李伟文,李 擎,高 超
(北京信息科技大学 高动态导航技术北京市重点实验室,北京 100192)
0 引言
目标检测已成为近年来计算机视觉领域最热门的研究任务之一,在无人驾驶车辆、人脸识别、智能交通、目标追踪等领域得到广泛应用。传统目标检测算法在特征提取阶段需要人工选取特征提取方式,例如方向梯度直方图HOG、局部二值模式算子LBP、尺度不变特征变换SIFT等。但该类方法受光照、目标颜色纹理及背景的影响较大,鲁棒性较差。
随着深度学习技术的不断发展,基于深度学习的目标检测算法成为主流。代表算法有基于候选区域的RCNN[1]、R-FCN[2]、Fast-RCNN[3],基于回归的YOLO[4]、SSD[5]、Efficient-net[6]等。但基于候选区域的算法运行速度慢,难以满足实时性要求;基于回归的目标检测算法速度快,精度却有所降低。文献[7]提出一种基于改进Faster R-CNN的复杂环境车辆检测算法,提高了运行速度,降低了漏检率。文献[9]设计了基于轻量级Mobile-Net的车辆目标检测网络,减少了算法的计算量。其将通道域注意力及目标中心区域预测模块引入深度网络中,提高了对目标的检测精度。文献[10]提出一种基于特征融合的感受野模型Receptive Field Block,以增强对小目标的检测效果。文献[11]通过修改YOLOv3的特征提取网络来提高对车辆目标的检测精度。
本文在SSD算法中增加自注意力机制ULSAM(ultra-lightweight subspace attention module)[12],并设计了特征融合模块来提高算法的精确度,对提高无人车的安全性、实用性有一定意义。
1 相关理论
1.1 网络结构
SSD目标检测算法的网络结构分为3个部分,分别是主干网络VGG16、附加网络层和预测层,如图1所示。在特征提取过程中会生成多个特征图,需要用到的有效特征图为Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2。

图1 SSD网络结构
1.2 先验框选择
在有效特征图上,以每个像素点为中心,生成数量不同、长宽比不同的先验框。不同尺寸、位置的先验框用于快速检测不同大小的目标。生成先验框的边长为
(1)
式中:m为先验框的个数,原SSD算法中为4或6;Smax是先验框边长的最大值,Smin是先验框边长的最小值。不同尺度特征图上先验框的个数分别为[4,6,6,6,4,4],长宽比为[1,2,3,1/2,1/3]。
2 改进SSD算法
2.1 注意力机制
在深度卷积网络中,注意力机制可看作是一种资源分配的机制,通过调整网络的权重来提高预测效果。因此本文在算法的有效特征层后增加自注意力机制ULSAM。


(2)
(3)
(4)
式中:maxpool3×3,1为核为3×3、填充为1的最大池化操作,DW1×1为Depth-wise卷积;PW1为Point-wise卷积;⊗表示同位置元素相乘;⊕表示同位置元素相加。
2.2 多尺度特征融合
本文通过将深层特征图进行反卷积操作后与浅层特征图进行像素级融合,得到同时包含丰富语义信息和细节特征信息的特征图,来提高算法对目标的识别精度。其中,反卷积也称为转置卷积,是一种上采样操作,可按照设置的参数来增大特征图的分辨率。
选择加权融合的方式,把处理后尺寸相同的特征图按照一定的权重相加。由于目的是提高检测对目标的识别精度,而低层特征图中包含更多的目标细节特征信息,因此在融合时将低层特征的权重适当增大,特征加权融合的计算公式为
f(x)=α1x1+α2x2+…+αnxn
(5)

本文中的特征融合方式是从最底层特征图开始,将其反卷积后与高层特征图融合,并将融合后的特征图作为新的底层特征图,然后多次重复上述操作。具体流程如下:
对特征图Conv11_2进行反卷积操作,与Conv10_2进行融合得到new_Conv10_2;对new_Conv10_2进行反卷积操作,与Conv9_2进行融合得到new_Conv9_2;对特征图Conv8_2进行反卷积操作,与Conv7融合得到new_Conv7。在融合Conv4_3和new_Conv7时,由于特征图尺寸相对较大,为防止过拟合及加快模型的收敛速度,采用了文献[13]中的融合方式,对new_Conv7进行一次反卷积操作、核为3的卷积操作以及BatchNorm操作;对Conv4_3进行一次核为3的卷积操作以及BatchNorm操作。最后融合两个BN层输出的结果并使用Relu激活函数得到new_Conv4_3。最后对特征图new_Conv4_3、new_Convq_2及经过注意力机制处理后的特征图Conv7、Conv_2、Conv10_2、Conv11_2进行回归和分类预测。本文的网络结构如图2所示,其中new_Conv_i是新的特征图,Conv_i是原特征图,BN_i是BatchNorm层,ULSAM_i是注意力模块,5个输入参数分别为输入特征图和输出特征的的通道数,输入特征图的高和宽、分组数。
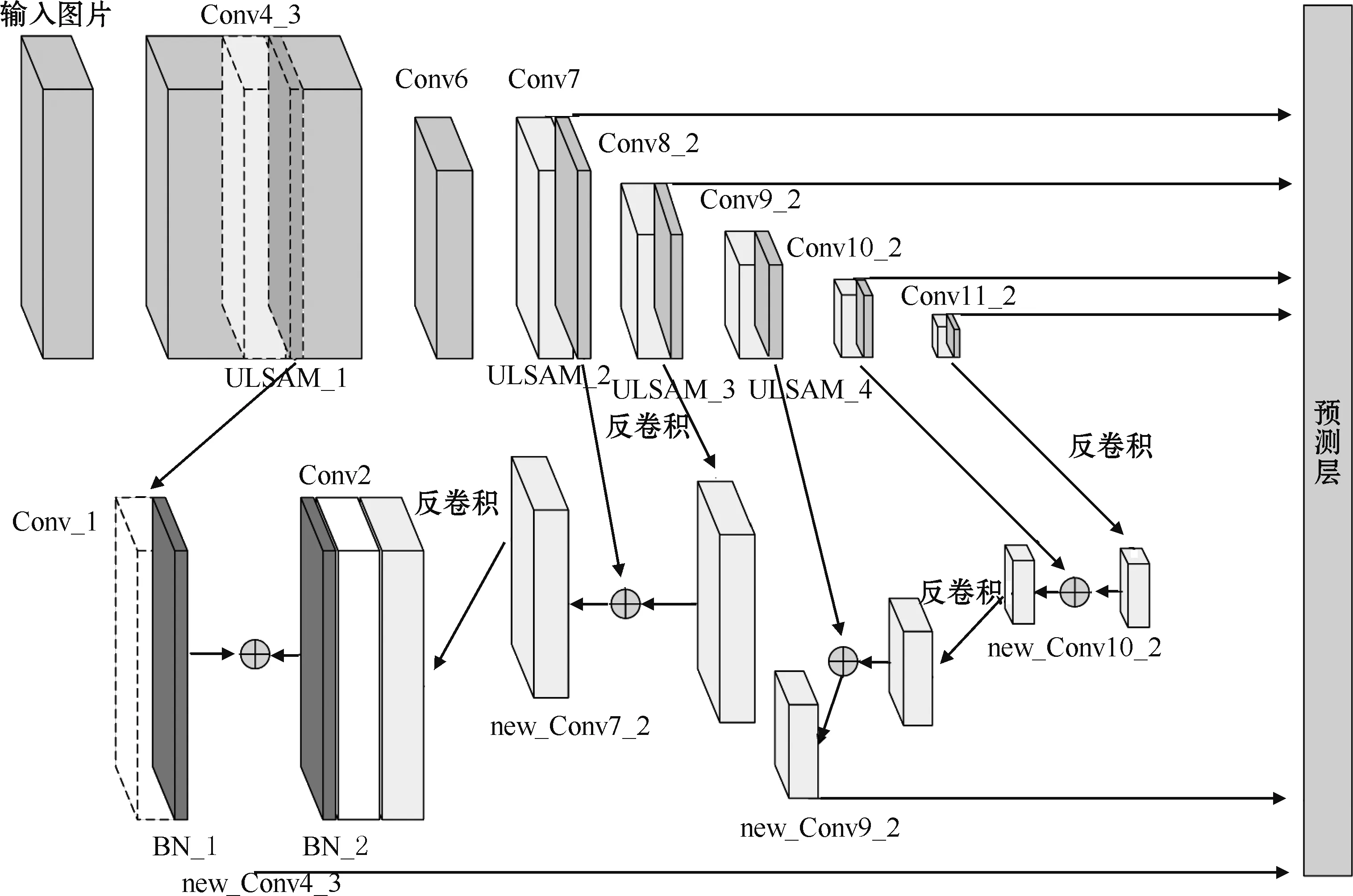
图2 本文网络结构
3 实验结果分析
3.1 实验平台
实验硬件配置:E5-2670、GeForce GTX1080ti显卡,32 GB内存的服务器。软件环境配置:Ubuntu16.04系统、CUDA、深度学习框架Pytorch,超参数设置如表1所示。

表1 超参数设置
3.2 实验数据集
本文中的实验主要分为两部分,第一部分选取KITTI为数据集,验证本文算法在无人车道路目标检测方面的能力。
第二部分选取PASCAL VOC数据集,验证本文算法的泛化能力。选择VOC2007和VOC2012的训练集部分作为训练数据集,将VOC2007的测试集部分作为测试数据集。
3.3 实验结果
在训练过程中分别记录本文算法和原SSD算法的Loss值,并绘制成曲线,如图3所示。

图3 模型训练Loss曲线
在图3中,位于下方的深色曲线是本文算法的Loss值,位于上方的浅色曲线为原算法的Loss值,可看出本文算法的Loss更小,且收敛速度更快。
计算本文算法和原SSD算法在KITTI数据集上的检测精度mAP,如表2所示,本文算法的mAP提升了3.8%,精度更高。
表2 KITTI数据集实验结果对比 %
采集实际道路行驶环境的图像,测试本文算法与原算法对车辆目标检测的能力,检测结果如图4所示。

图4 车辆目标检测结果
图4中第一列的3张图片为本文算法的检测结果,第二列为原算法的检测结果。对比检测结果可知,本文算法对车辆目标的识别效果更好,能有效检测出原算法忽略的目标。
将本文算法与Fast-RCNN等算法在PASCAL VOC数据集上的测试结果进行对比,如表3所示。
从表3可以看出,本文算法的mAP相较于Fast-RCNN、YOLO算法有明显提升,相对于原SSD算法提升了1.3%。由于PASCAL VOC中包括的目标类别较KITTI多,mAP的提升表明本文算法有一定泛化能力。

表3 PASCAL VOC数据集实验结果对比 %
为验证多尺度特征融合的效果,将融合前后的特征图Conv4_3可视化,如图5所示。

图5 Conv4_3特征图可视化结果示意
图5(b)左侧是特征融合前的Conv4_3可视化结果,右侧是特征融合后Conv4_3可视化结果,对比可看出,融合后的特征图中包含了更多的目标细节特征信息,验证了特征融合的作用。
4 结束语
为提高无人车目标检测精度,本文对原SSD目标检测算法进行改进,将高层特征图进行反卷积操作后与底层图融合,同时在有效特征图后引入自注意力机制,以增强对目标的识别能力。经实验验证,本文方法在一定程度上提高了SSD算法对目标的检测精度,能有效检测出原算法忽略的目标。在未来的研究工作中,将继续研究网络模型的优化问题,提高算法的检测精度。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
海外文摘·艺术(2020年22期)2020-11-18
岁月(2016年5期)2016-08-13
