
权利要求特征驱动的专利关键词抽取方法
2021-07-17 14:59俞琰尚明杰赵乃瑄
情报学报 2021年6期
俞琰,尚明杰,赵乃瑄
(1.南京工业大学信息管理与技术研究所,南京 210009;2.东南大学成贤学院电子与计算机学院,南京 211816)
1 引言
专利关键词是表明专利文献主题内容的一组词或者短语,被广泛应用于专利文献自动文摘、分类、检索、翻译、聚类等专利分析之中。而专利文献通常不包含关键词,需要人工标引。由于专利文献篇幅较长、内容专业,且近年来专利文献的数量急剧增长,使得人工标引专利关键词的方法已无法满足专利分析的需要。因此,如何利用计算机自动、高效、准确地抽取专利关键词成为一个重要的研究课题。
词频-逆文档频率(term frequency-inverse document frequency,TF-ⅠDF)[1]是目前使用较为广泛的关键词抽取方法之一。该方法首先通过词性规则匹配选取候选关键词,然后利用候选关键词在文档中的词频和数据集中的逆文档频率对候选关键词重要性进行评估,选择权重最大的若干候选关键词作为关键词。研究表明,该方法在专利关键词抽取方法中具有有效性[2]。
然而,目前的专利关键词抽取主要依据通用文本的关键词抽取方法,没有考虑专利文献自身的特征,关键词抽取结果仍有较大提升空间。具体来说,TF-ⅠDF方法在专利关键词抽取中主要存在两个问题。
问题1:基于人工制定的词性规则匹配方法费时、费力,且选取的候选关键词遗漏较多。例如,最常使用的词性匹配规则为依据形容词(a)和名词(n)的词性组合选取候选关键词[3],这可能漏选包含动词(v)的“前馈/v神经网络/n”“命名/n实体/n识别/v”“自由基/n引发/v剂/n”,包含语素(g)“最大/a熵/g”,包含数词(m)的“二/m羟基/n乙基/n二甲基/n乙烯/n”“喹赛/n多/m”等关键词。
问题2:候选关键词权重TF-ⅠDF不能很好地反映专利的创造性和新颖性。例如,在本文示例专利“基于最大熵和神经网络模型的韩语命名实体识别方法”(申请号:CN201710586675.2)中,非专利关键词“实体 标签”“模板 选择 规则”的TF-ⅠDF值高于专利关键词“前缀树字典”“神经网络模型”和“实体 字典”的TF-ⅠDF值。
实际上,专利文献包括标题、摘要、权利要求、说明书和附图等部分内容。其中,权利要求既是技术文献,也是法律文书,是专利文献的核心,在内容和格式上不同于普通文献,有其特定的要求。一方面,在内容上,权利要求需要包含体现专利新颖性、创造性与实用性的全部必要技术特征,以说明要保护的专利范围,而专利关键词正是体现专利新颖性、创造性与实用性的词语或短语;另一方面,在格式上,权利要求至少包含一项独立权利要求,还可以包含若干从属权利要求。从属权利要求通常会选出重要的、对申请专利新颖性、创造性和实用性起作用的必要技术特征加以限定,以增强专利的法律稳定性。因此,本文通过权力要求特征的分析,提出权力要求特征驱动的专利关键词抽取方法,以提高专利关键词抽取的准确性。
具体地,本文提出的权利要求特征驱动的专利关键词抽取方法具有如下主要创新点:①从专利关键词抽取任务出发,对权利要求特征进行分析;②基于权利要求特征,提出基于最长公共子串的候选关键词选取方法;③引入信息增益比概念,提出一种去除冗余候选关键词的方法;④基于权利要求特征,提出特指度指标,将其融入传统的TF-ⅠDF候选关键词权重之中;⑤通过实验数据比较分析,证明本文所提出的方法的可行性与有效性。
2 相关研究
目前,关键词抽取方法主要分为有监督方法和无监督方法两大类。
有监督方法通常将关键词抽取问题看作一个分类问题,使用机器学习方法,通过事先给定的包含样本的训练语料学习分类模型,然后使用学习得到的分类模型进行关键词抽取。典型的有监督方法包括朴素贝叶斯[4]、支持向量机[5-7]、条件随机场[8-9]等。近年来,随着深度学习方法的兴起,一些研究尝试使用深度学习方法自动学习文本特征,并结合条件随机抽取关键词[10-11]。总的来说,有监督方法抽取关键词优于无监督方法,但存在依赖训练语料的规模与质量、大规模人工标注的训练语料难以获取、抽取效果受到训练语料的领域性影响较大、模型较为复杂,可能存在过拟合等问题[12]。
无监督方法通常包括候选关键词选取和候选关键词权重两个主要步骤。其中,候选关键词选取通常采用词性规则匹配方法,其认为关键词的词性序列遵循特定排列规则,如“形容词+名词”[3]等规则;候选关键词权重则利用各种评分指标对候选关键词的重要性进行评估,以选取排名最前的若干候选关键词作为关键词。由于无监督方法不需要事先标注数据,模型直观明了,从而一直得到研究者的广泛关注,是近年来研究和应用的重点。其中,候选关键词权重主要包括基于统计的方法和基于图模型的方法等。
基于统计的方法根据文本中词语的词频、位置、词性和长度等统计特征权重候选关键词。其中,TF-ⅠDF方法[1]因其简单有效而被广泛使用。TF-ⅠDF方法认为词语的重要性与其在目标文本中出现的次数正相关,与其出现的总文本负相关。然而,TF-ⅠDF单纯以词频衡量一个词的重要性,不够全面。因此,有些研究者尝试利用词语的位置[13]、类内信息[14]、词跨度[15]、词性[16]、词聚类[17]和国际专利分类号等[18]特征对其进行改进。
基于图模型的方法将文本中的词构建为图模型,评估图中起重要作用和中心作用的词或者短语,将这些词或者短语作为关键词。其中,TextRank方法[19]因其简洁有效、适应性强、无需训练数据、扩展性强、速度快等特点而被广泛应用。TextRank方法以词作为图模型的顶点,词语间的关联作为边进行随机游走,根据得分高低选择关键词。一些研究者尝试利用词位置[20-23]、主题[24-26]、语义[27-29]等信息,以提高TextRank方法的关键词抽取准确率。
总之,目前的专利关键词抽取通常沿用传统通用文本的关键词抽取方法,没有充分考察和利用专利特征,抽取结果仍有较大提升空间。因此,利用专利特征以提高专利关键词抽取的结果仍有待进一步深入研究。
3 权利要求特征分析
专利权利要求是一种法律文件,说明要求专利保护范围,是专利申请文件的核心,在专利申请和专利诉讼中都起着至关重要的作用。
权利要求不同于一般文本,在内容和格式上都具有特定的要求。在内容上,权利要求需要包含体现专利新颖性、创造性与实用性的全部必不可少的技术手段或技术方案,即必要技术特征,以说明要保护的专利范围。在格式上,至少包含一项独立权利要求,还可以包含若干从属权利要求。独立权利要求从整体上说明专利权利范围,从属权利要求必须依从于一个独立权利要求或者在前的从属权利要求,用附加的技术特征对引用的权利要求作进一步限定。从属权利要求通常会选出重要的、对申请新颖性和创造性起作用的必要技术特征作限定,以增强专利的法律稳定性。为了避免这些反复出现技术特征的歧义性,常冠以“所述”“所述的”(英文“the”“said”)等特指词,确认所提技术特征。
图1为示例专利的权利要求。其中,权利要求1是独立权利要求,权利要求2~9为从属权利要求。从属权利要求2~4均引用独立权利要求1,对独立权利要求1中的技术特征进一步限定,从属权利5则引用从属权利要求4,对其中技术特征做进一步限定。图1虚线表明引用权利要求使用特指词“所述”对被引用权利要求做进一步限定,以避免歧义。
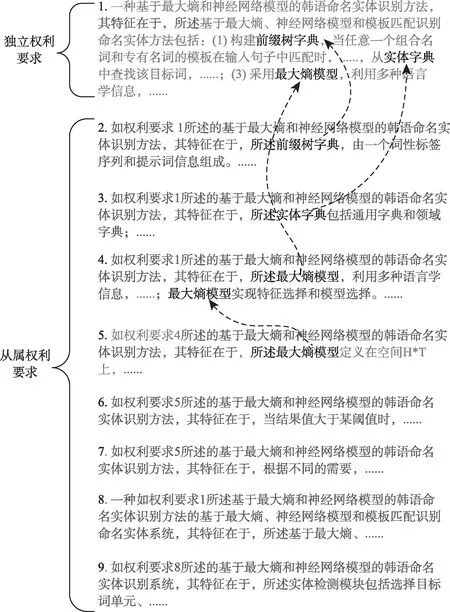
图1 示例专利权利要求
4 权利要求特征驱动的专利关键词抽取方法
根据权利要求特征,本文提出了权利要求特征驱动的专利关键词抽取方法。该方法主要包括预处理(第4.1节)、基于最长公共子串的候选关键词选取(第4.2节)、基于信息增益比的冗余候选关键词去除(第4.3节)和融入特指度的候选关键词权重(第4.4节)4个主要步骤。
4.1 预处理
预处理主要包括分词、去除停用词等工作。其中,由于中文文本词与词之间没有明显的切分标记,需要通过分词把一个句子按照其中词的含义进行切分。去除停用词则通过通用停用词表以及人工筛选去除频率高但是信息量少的词,如“发明”等词。此外,预处理工作还包括英文大小写格式转换、去除特殊符号等工作。
4.2 基于最长公共子串的候选关键词选取
根据第3节分析的权利要求特征,本文提出了基于最长公共子串的候选关键词选取方法。该方法首先构建专利树PatentTree,然后依据专利树的父节点与子节点的最长公共子串选取候选关键词。
具体地,PatentTree=(V,E,root),其中,V是PatentTree的节点集合;每个节点vi对应专利权利要求ci;E⊂(V×V)是PatentTree的边集合;E中元素<vi,vj>表示权利要求cj引用权利要求ci;root表示PatentTree根结点,对应专利标题和摘要,与独立权利要求相连。图2为示例专利的PatentTree。
根据PatentTree,选取PatentTree的父节点与子节点的最长公共子串(longest common string,LCS)作为候选关键词[30]。如示例专利父节点独立权利要求1中经过预处理的连续词串“构建前缀树字典”,与其子节点权利要求2中经过预处理的连续词串“所述前缀树字典”的最长公共子串为“前缀树字典”。表1为示例专利中父节点与子节点的最长公共子串。
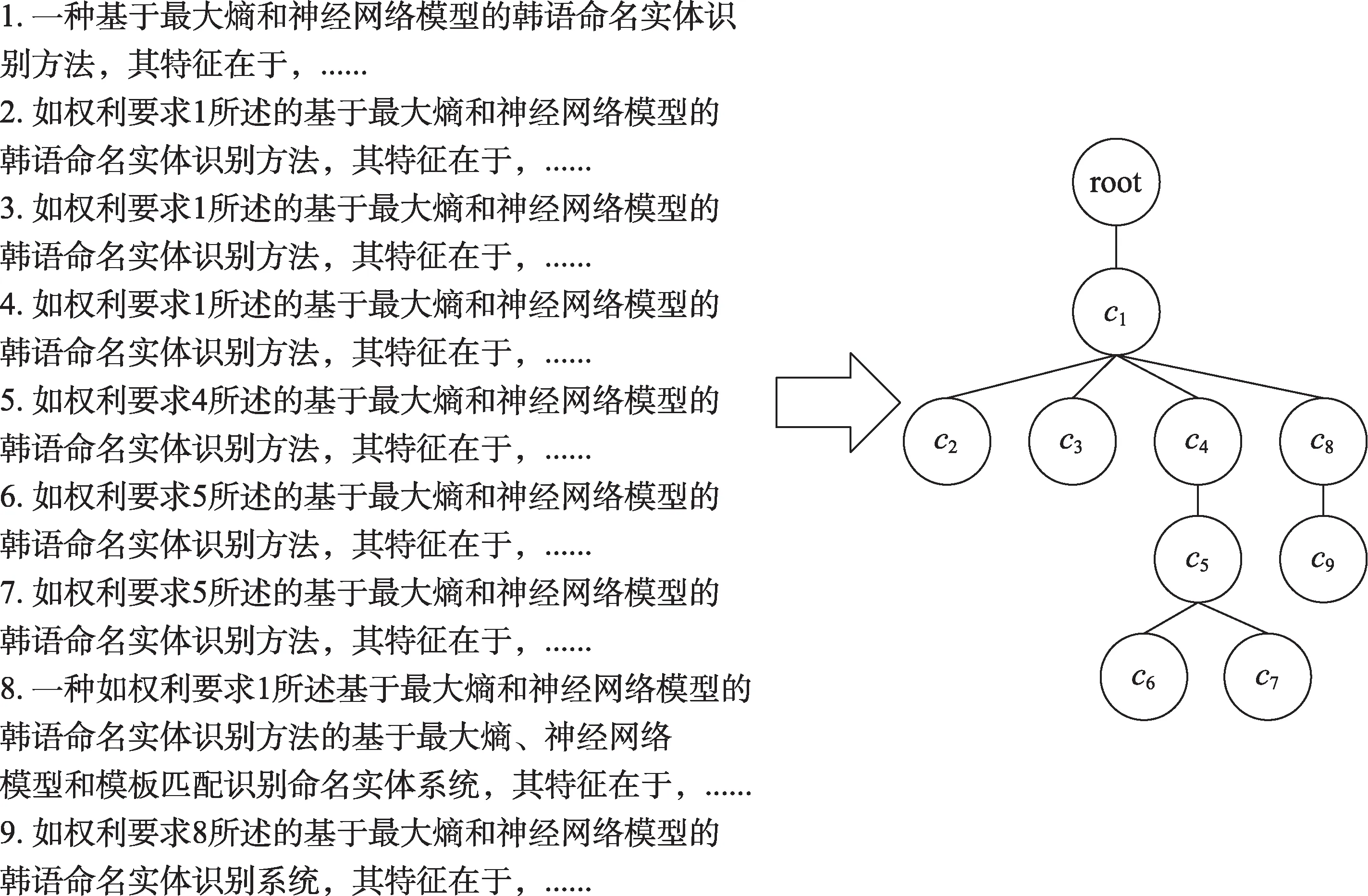
图2 示例专利PatentTree

表1 示例专利最长公共子串
所有的最长公共子串构成了候选关键词集合,表2为示例专利基于词性规则匹配方法[3]与基于最长公共子串方法选取的候选关键词比较,其中人工标注的关键词使用粗体表示。由表2可见,基于最长公共子串选取的候选关键词具有更高的关键词覆盖率、领域独立性和简单易行等优点。
4.3 基于信息增益比的冗余候选关键词去除
第4.2节选取的候选关键词中,存在较多嵌套候选关键词,所谓嵌套候选关键词,是指候选关键词y(称为父串)包含候选关键词x(称为子串),如“利用前缀树”和“前缀树”。表3第1列子串和第2列母串为示例专利中的部分嵌套候选关键词。嵌套候选关键词具有一定的普遍性,一些嵌套候选关键词均具有较高权重值,如在示例专利中,“最大熵”“基于 最大熵”“最大熵 模型”等嵌套候选关键词均具有较高权重,从而造成关键词抽取错误。
在这些嵌套候选关键词中,一方面,一些母串包含比子串更多信息,如母串“韩语命名实体识别”和子串“命名实体识别”,应予以保留;另一方面,一些母串并没有比子串包含更多信息,甚至是错误的候选关键词,为冗余候选关键词,如母串“基于最大熵”相较于子串“最大熵”,应予以去除。

表2 示例专利候选关键词选取比较
据此,本文提出指标I(Ⅰnformation),以衡量一个词w的信息量:

其中,|D|表示数据集文档数;|Dw|表示词w在数据集中出现的文档频率。一个词在数据集中出现的文档频率越低,其包含的信息量越大。
基于信息量Ⅰ的定义,给定母串y和子串x,使用信息增益比(information gain ratio,ⅠGR)衡量母串相较于子串增加的信息量的多寡,其定义为
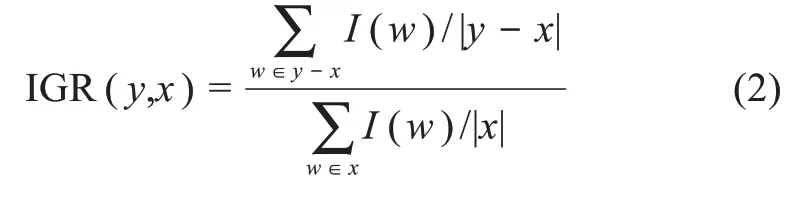
其中,|x|表示子串x中包含的词语个数;y-x表示包含在y中但不包含在x中的词语;|y-x|表示包含在y中但不包含在x中词语个数。公式(2)分母表示子串x的平均词语信息量;分子表示母串y相较于子串x新增加词语的平均信息量。由公式(2)可知,ⅠGR是一个正实数,当其值小于1时,表示母串中新增加的词语的平均信息量少于子串的平均信息量。ⅠGR的值越小,表明新增加词语的平均信息量越少;反之,表明新增词语的平均信息量越多。通过设定阈值(本文阈值设定为0.5),可以去除一些添加信息量少的冗余候选关键词。表3为示例专利信息增益比,其中,母串相对于子串中新增的词语使用粗体表示。由表3可知,通过信息增益比,可以保留“韩语命名实体识别”等嵌套候选关键词,同时去除“基于最大熵”等冗余候选关键词。

表3 示例专利信息增益比
4.4 融入特指度的候选关键词权重
TF-ⅠDF[1]是一种常用的度量候选关键词重要性的方法,该方法假设一个候选关键词在目标文本中出现频次越多,在文本集中出现越少,则越能够表示目标文本的主题思想,从而作为目标文本的关键词。其计算公式为
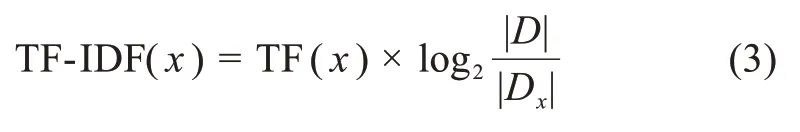
其中,TF(x)表示x在文本中的出现频次。
但TF-ⅠDF指标不能很好地反映专利中具有新颖性和创造性的候选关键词,如示例专利中反映创新性和新颖性的候选关键词“前缀树字典”的TF-ⅠDF值,低于候选关键词“模板选择 规则”。根据第3节权利要求特征的分析,本文提出特指度(specific degree,SD)度量候选关键词被特指词特指的次数,并将特质度信息融入候选关键词权重之中,形成TF-ⅠDF-SD候选关键词权重指标:
TF-ⅠDF-SD=TF-ⅠDF(x)×(SD(x)+1) (4)
在示例专利中,“前缀树字典”“神经网络模型”和“实体字典”等候选关键词具有较高的特指度,使得其TF-ⅠDF-SD权重值大于候选关键词“模板 选择 规则”“实体 标签”的TF-ⅠDF-SD值。
5 实验
5.1 数据
目前,由于没有正式公开的专利关键词标注数据集,本文的实验从国家知识产权局网站分别检索主题为“命名实体识别(named entity recognition,NER)”的计算机领域相关中文发明专利和主题为“纳米”的化学领域相关中文发明专利,分别随机下载1500篇作为目标专利。以“命名实体识别”和“纳米”为相关主题分别随机下载20000篇专利作为辅助数据集。每个数据集的目标专利分别由3位领域专家独立人工标注5~10个关键词,使用两两交集作为目标文本最终关键词标注结果[31-32],并对人工标注结果使用kappa值进行评测,两个数据集上的kappa得分均大于0.8,当kappa值超过0.8则被认为数据集标注是有效的[33]。数据集信息如表4所示。

表4 数据集信息
5.2 步骤与评估指标
本实验采用结巴分词工具[34]对实验数据进行分词与词性标注,使用哈尔滨工业大学停用词表[35]去除停用词等进行预处理工作,对目标专利进行候选关键词选取,再利用辅助数据集,计算信息增益比,去除冗余候选关键词,并计算候选关键词权重。对抽取的专利关键词使用准确率(precision,P)、召回率(recall,R)和F值(F1-score,F)进行评估,计算公式为


5.3 结果
5.3.1 基于最长公共子串的候选关键词选取评估
实验首先评估基于最长公共子串的候选关键词生成方法。为此,通过实验比较表5所示的两种关键词抽取方法。

表5 两种候选关键词选取方法的比较
实验结果如图3所示。从图3可知,在两个数据 集 中,LCS+TF-ⅠDF方 法 的P、R和F值 均 高 于Rule+TF-ⅠDF方法。在NER数据集中,LCS+TF-ⅠDF方法的P、R和F值比Rule+TF-ⅠDF方法分别高7%、8%和7.5%;在纳米数据集中,LCS+TF-ⅠDF方法的P、R和F值比Rule+TF-ⅠDF方法分别高6%、8%和7.2%。实验结果表明,使用最长公共子串方法比基于规则的方法生成的候选关键词具有更好的候选关键词生成结果。
5.3.2 基于信息增益比的冗余候选关键词去除评估
实验评估了基于信息增益比去除冗余候选关键词的有效性。为此,通过实验比较如表6所示的两种方法。
实验结果如图4所示。由图4可知,两个数据集结果类似。LCS+R+TF-ⅠDF的P、R和F值均高于LCS+TF-ⅠDF方 法。在 纳米数 据集,P、R和F分 别提高了7%、6%和6.5%;在NER数据集,P、R和F分别提高了8%、5%和6.3%。LCS+R+TF-ⅠDF比LCS+TF-ⅠDF增加了去除冗余候选关键词的步骤,表明通过去除冗余关键词可以提高关键词抽取的准确率、召回率和F值。
表7列出了示例专利中使用两种方法抽取的关键词,其中人工标注关键词使用粗体表示。由表7可知,如果不去除冗余候选关键词,一些冗余候选关键词会具有较高的TF-ⅠDF,如“基于 最大 熵”“最大熵模型”等,造成错误抽取。而通过去除冗余候选关键词,可以使得其他正确关键词有机会被正确抽取,从而提高关键词抽取的准确性。

图3 候选关键词选取方法比较结果

表6 两种去除冗余候选关键词方法的比较
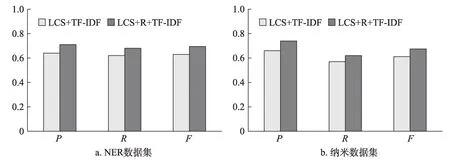
图4 基于信息增益比去除冗余候选关键词有效性评估结果
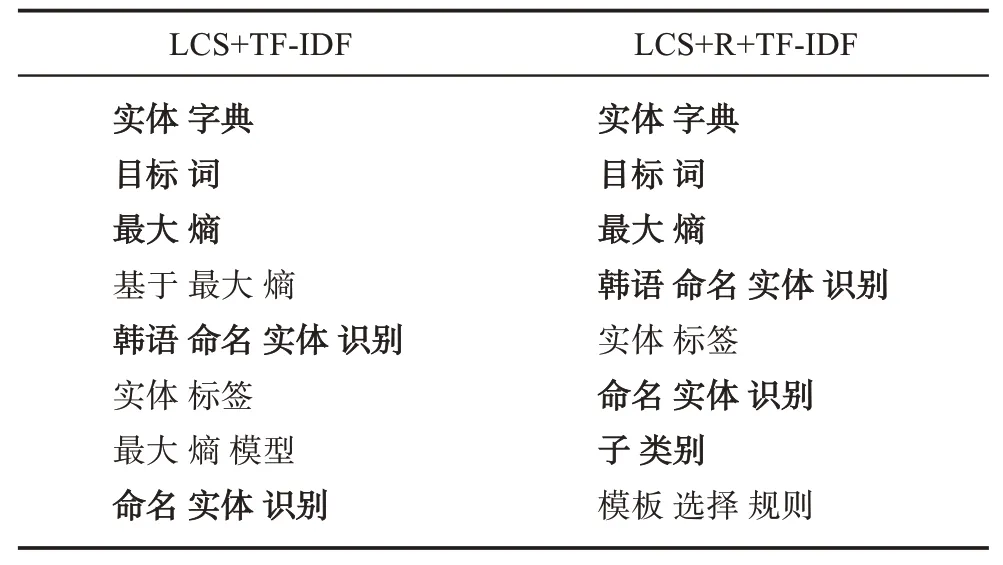
表7 示例专利基于信息增益比去除冗余候选关键词有效性评估
5.3.3 融入特指度的候选关键词权重评估
实验评估了融入特指度的候选关键词权重有效性。为此,通过实验比较如表8所示的两种方法。
图5为两种方法比较结果。由图5可知,在两个 数 据集 中,LCS+R+TF-ⅠDF-SD方 法 的P、R和F值均高于LCS+R+TF-ⅠDF的P、R和F值。其中,在NER数据集中,LCS+R+TF-ⅠDF-SD方法的P、R和F较LCS+R+TF-ⅠDF提高了6%、5%和5.5%;在纳米 数 据集 中,LCS+R+TF-ⅠDF-SD方 法 的P、R和F值较LCS+R+TF-ⅠDF提高了8%、5%和6.3%。LCS+R+TF-ⅠDF-SD方 法 相 较 于LCS+R+TF-ⅠDF方 法,在计算候选关键词时融入了特指度特征SD,用于提高专利中被反复特指的候选关键词的权重。实验结果表明,该特征能够有效地提高专利抽取的准确率、召回率和F值。
表9列出了示例专利使用两种方法抽取的关键词。由表9可知,通过在权重候选关键词计算时添加特指度信息,可以提高反映专利创新性和新颖性的必要技术特征的候选关键词权重,如“前缀树字典”“神经网络模型”和“实体字典”,从而提高专利抽取的准确性。

表8 两种候选关键词权重方法的比较
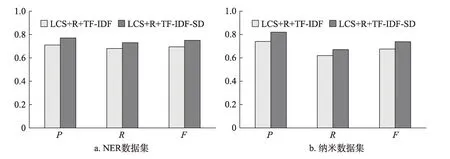
图5 候选关键词权重方法比较结果

表9 示例专利候选关键词权重方法比较
5.3.4 与其他无监督关键词抽取方法比较
实验将本文提出的方法与常见的无监督关键词抽取方法进行比较。欲比较的方法如表10所示。

表10 三种无监督关键词抽取方法的比较
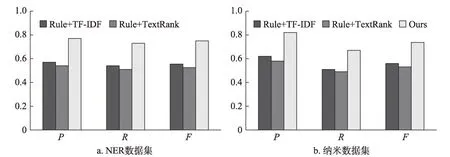
图6 与其他无监督关键词抽取方法比较结果
实验结果如图6所示。由图6可知,两个数据集中,Ours方法均获得了最高的P、R和F值。在NER数据集中,Ours方法的P、R和F值比Rule+TF-ⅠDF分别 提高 了20%、19%和19.5%;比Rule+TextRank方法分别提高了23%、22%和22.5%;在纳米数据中,Ours方法的P、R和F值比Rule+TF-ⅠDF方法分别提高了20%、16%和17.8%;比Rule+TextRank方法提高了24%、18%和20.6%。实验结果表明,本文提出的专利关键词抽取方法具有有效性。通过专利关键部分权利要求特征的分析,利用权利要求特征,采用最长公共子串选取候选关键词、基于信息增益比去除冗余候选关键词,以及在TF-ⅠDF方法中融入特指度信息,能够有效提高专利关键词抽取的准确率、召回率和F值。
表11为示例专利使用3种方法抽取的关键词,其中人工标注的关键词使用粗体表示。由表11可知,使用本文提出方法抽取的关键词的准确率明显高于传统的无监督关键词抽取方法,表明本文提出方法的有效性。
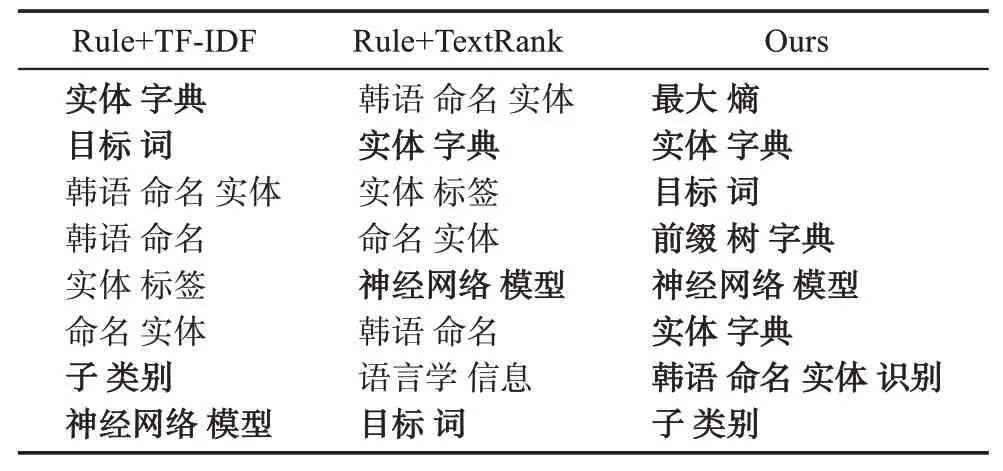
表11 示例专利与其他无监督关键词抽取比较
5.3.5 与有监督关键词抽取方法比较
实验将本文提出的关键词方法与一些有监督关键词抽取方法进行比较,数据集按照5∶1随机分为训练集与测试集,进行交叉验证。欲比较的方法为:
(1)NB[4]:使用词性规则匹配[3]选取候选关键词,使用朴素贝叶斯模型,选择TF-ⅠDF特征和候选关键词首词出现的位置特征。
(2)SVM[6]:使用词性规则匹配[3]选取候选关键词,使用支持向量机模型,选择与NB方法一样的特征,核函数参数为RBF。
(3)BiLSTM+CRF[11]:使用word2vec模型中的skip-gram模型训练词向量,使用BiLSTM网络,得到包含前后文本序列的双向表达,通过CRF预测最终的标签序列。定义B、M、E和O作为标签集合,其中B表示关键词的开头、M表示关键词的中间、E表示关键词的结尾、O表示其他。预训练的词向量大小为200维,学习速率为0.001,BiLSTM模型层数为2,隐藏层为128,激活函数为tanh。
(4)Ours:本文提出的无监督关键词抽取方法。
实验结果如图7所示。由图7可知,在两个数据集中,本文提出方法的P、R和F值均取得了最高值。在NER数据集中,Ours方法的P、R和F值比NB方法分别提高了15%、15%和15%;比SVM方法提高了13%、12%和12.5%;比BiLSTM+CRF-1方法分别提高9%、11%和10.1%。在纳米数据集中,本文提出的方法比NB方法分别提高14%、11%和12.3%;比SVM方 法 提 高15%、9%和11.6%;比BiLSTM+CRF方 法 提 高12%、6%和8.6%。实验结果表明,本文提出的方法通过利用专利权利要求的特征,可以获得比有监督方法更好的关键词抽取准确率、召回率和F值,且相比于有监督方法,本文提出的方法更加简单可行,具有更高的可行性和实用性。
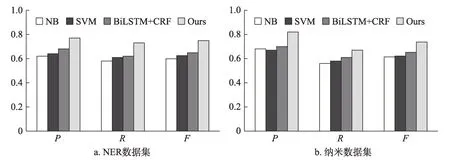
图7 与有监督关键词抽取方法比较结果
表12列出了示例专利与有监督关键词抽取方法的比较。由表12可知,在NB和SVM方法中,候选关键词首次出现的位置特征以及TF-ⅠDF特征对关键词抽取起到了重要作用。然而,在考虑这些特征属性时,很多错误缘于这些特征值较高,但本身并不是关键词的候选关键词,而BiLST+CRF则与训练集数据选取有较大关系。相比而言,利用权利要求特征的关键词抽取方法则更具有针对性,简单易行,具有更好的关键词抽取效果。
6 结论
专利关键词是表明专利文献主题内容的一组词或者短语,被广泛应用于专利分析之中。目前,专利关键词抽取主要依据通用文本关键词抽取方法,没有充分利用专利特征,专利关键词抽取的结果准确性仍有较大提升空间。专利文本既是一种技术文献,也是一种法律文书,具有严密独特的逻辑表述。因此,本文着眼于分析专利权利要求特征,并利用专利权利要求特征,提出一种权利要求特征驱动的专利关键词抽取方法,以提高专利关键词抽取的准确性。具体地,方法包括预处理、基于最长公共子串的候选关键词选取、基于信息增益比的冗余候选关键词去除和融入特指度的候选关键词权重4个主要步骤。实验结果表明,本文提出方法具有可行性与有效性。

表12 示例专利与有监督关键词抽取方法比较
在实验中,本文所提出的方法存在一定的局限,主要体现在无法正确选取一些包含特殊字符的候选关键词,如“2,2′-联吡啶”。此外,在计算特指度时,由于语言描述的灵活性,目前的特指度指标还不够精准,无法正确评估一些候选关键词的特指度,这将是本课题组后续研究的重点。
猜你喜欢
心理学报(2022年5期)2022-05-16
齐齐哈尔大学学报(哲学社会科学版)(2021年11期)2021-12-23
老年教育(2021年5期)2021-05-25
幽默大师(漫话国学)(2020年10期)2020-10-29
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
娃娃乐园·3-7岁综合智能(2016年6期)2016-09-19
中国经济周刊(2015年21期)2015-09-10
小学生时代·大嘴英语(2014年11期)2014-12-04
