
基于写页面热度的混合内存页面管理策略
2021-07-17 01:37钱育蓉赵京霞张文冲
东北师大学报(自然科学版) 2021年2期
杜 娇,钱育蓉,张 猛,赵京霞,张文冲
(新疆大学软件学院,新疆 乌鲁木齐 830008)
0 引言
大数据时代,数据密集型应用的比例逐渐超过计算密集型应用,成为计算机系统中的主流应用[1],内存计算也随之迅速发展,对存储系统的容量、性能、功耗以及可拓展性不断提出了更高的要求.目前的存储系统中,应用最广泛的存储器件是传统的动态随机存取存储器(Dynamic Random Access Memory,DRAM),然而DRAM存储技术受其本身工艺尺寸、存储密度、掉电数据丢失等特性的限制[2],难以满足大数据时代对海量信息存储的需求[3],计算瓶颈问题逐渐转化为I/O瓶颈问题,为能提供与计算能力相匹配的I/O能力,需对现有的存储系统进行优化甚至变革.
近年来,新型非易失性存储器(Non-Volatile Memory,NVM)凭借其非易失性、漏电功耗低、存储密度高和扩展性强等特性,为计算机存储系统的发展带来了新方向[4],但NVM各存储单元存在寿命限制以及读写性能不对称等问题,因此要真正发挥非易失存储器的优势,解决上述两个问题是前提.
改进目前主流内存设备(DRAM)的能力,在很长一段时间内,科研工作者将压缩DRAM工艺尺寸和成本,提高容量,降低其能耗作为研究目标,但DRAM面临的一些问题依然没有得到较好的解决.除此之外,目前应用广泛的还有闪存,闪存与磁盘相比无机械延迟,速度也相对较快,但远远不及阻变存储器(Resistive Random Access Memory,RRAM)、相变存储器(Phase Change Memory,PCM)等新型非易失存储器.杨濮源等[5]基于磁盘和固态硬盘构建混合存储系统,对数据页进行精准分类,虽然提升性能,但固态硬盘与NVM相比较,在存储性能方面仍然存在一定差距.
在非易失性存储器领域方面国内外学者也展开了许多研究.一部分研究者从材料及工艺出发,致力于研制更高性价比的存储介质.另一部分学者从软件层面出发,寻求提高存储系统能力的方法.W.Wei等[6]为了能够更准确地反映NVM混合主存系统中最后一级高速缓存的性能,设计了TMPKI(Transformed Misses Per-Kilo Instructions)性能度量制式;沈凡凡等[7]为降低缓存单元的写压力,提出了一种SRAM辅助新型非易失性缓存的磨损均衡方法;D.Liu等[8]将NVM上的写操作在整个NVM芯片空间内平均分布,通过磨损均衡的方法提高NVM的寿命.
通过对新型非易失性存储器及混合存储的研究现状及背景进行分析,发现目前引入NVM构建混合内存系统主要有3种结构:第1种是NVM完全取代DRAM作为内存;第2种是NVM与DRAM构成混合内存,但两者处于同一层次;第3种是DRAM与NVM采用层次结构构成混合内存结构[9],这种情况下,DRAM充当缓存的角色.针对第1种结构,NVM目前存在写操作延迟大、寿命有限的缺点,因此单独使用NVM作为内存是不可行的.若采用第2种层次结构,则内存的大小为NVM的大小,处理器对DRAM是未知的,同时DRAM与NVM之间需要频繁交换数据,会影响系统的性能.因此本文基于第3种的混合内存结构进行了研究.
本文基于DRAM和RRAM构建一种DRAM-RRAM混合存储模型,针对混合内存结构中RRAM写延迟大以及写耐性有限的缺陷,从减少RRAM上写操作数量的角度出发,提出一种混合内存管理策略,主要思想是通过将请求页面按照写访问热度进行划分,将最近多次被写的页面设置为热写页面,与之相对应的,将最近很少发生写操作的页面定义为冷写页面,把热写页面尽可能放置到DRAM上,冷写页面存到RRAM上,减少RRAM上的写次数,达到提高系统性能、延长RRAM寿命的目的.
1 混合内存模型
1.1 阻变存储器
RRAM存储数据信息的方式是基于阻值变化的,它利用薄膜材料在不同电流激励的作用下出现高低阻态之间的可逆转变现象来进行数据存储[10],高阻值时写“1”,低阻值时写“0”,与DRAM相比不需要充电操作,空闲时不耗能.其结构简单,由金属-介质-金属构成,有利于实现三维的高密度集成.国际半导体技术路线图组织在其2013年度报告中指出,RRAM将成为下一代存储器中最有力的候选者[11].
从单元存储密度、容量、读写延迟、耐久性、写能耗和易失性等方面出发,将RRAM与常用存储器件DRAM、NAND Flash进行了对比,见表1.发现DRAM的读写延迟小,耐久性好,但其功耗高,存储密度相对较低.RRAM在功耗、读写性能、耐性等方面都优于目前流行的闪存.
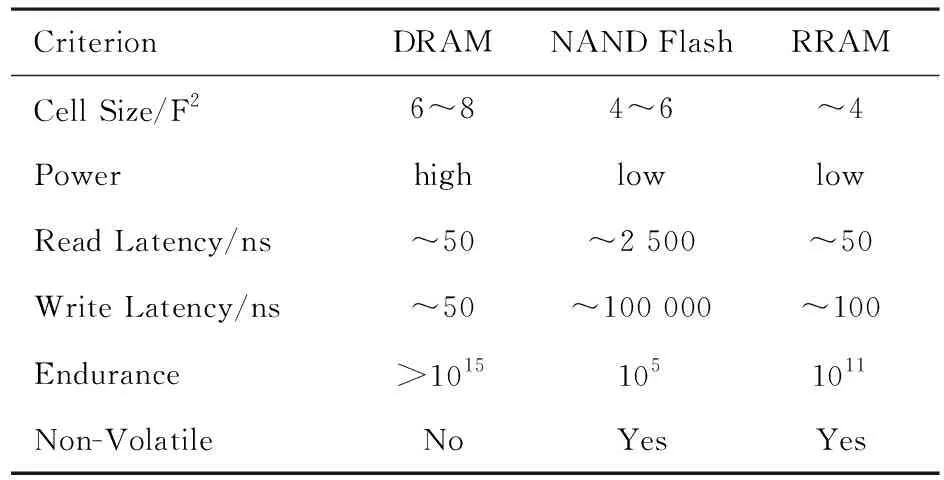
表1 常用存储技术比较
1.2 混合内存结构
在DRAM-RRAM混合内存系统中,不仅要对DRAM的特性进行模拟重现,还需模拟RRAM特性,因此需要设计一个混合内存控制器来进行管理和控制,充当桥梁的角色,分别为上层和下层提供一个接口,响应上层下发的请求,并通过接口从下层存储介质中查询,并将执行完的数据返回给CPU.图1展示了引入RRAM后的混合内存体系结构.传统的内存是直接与内存总线相连接的,而本文则将DRAM和RRAM连接到内存控制器上,内存控制器再与内存总线连接.
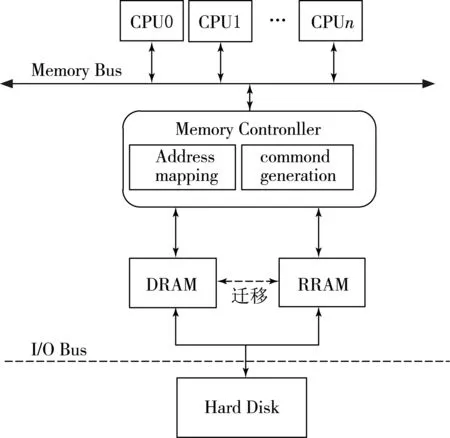
图1 混合内存体系结构
内存控制器负责管理DRAM和RRAM内存,主要工作包含管理数据的访存,实现地址映射、维护分区列表、命令产生、读写调度控制等,同时管理每一个对内存发起访问的请求.其中DRAM和RRAM分别设计存储管理模块,二者的地址空间是分别独立的,任何时候一个数据页只存在于一个设备上.内存控制器维护DRAM和RRAM的分区列表,根据请求地址将请求发送到相应的内存,DRAM与RRAM之间进行数据迁移.
混合内存控制器中请求下发执行过程如图2所示,具体如下:
(1) 当内存访问请求到达时,内存控制器对访问请求进行解析,获得请求类型、地址、大小等信息,请求信息进行保存.
(2) 判断该请求操作的页面是否在内存中.若请求命中执行步骤3,未命中执行步骤5.
(3) 对请求类型进行判断,若为读请求,根据地址映射关系表中的信息,到DRAM或者RRAM中进行查找,找成功,则返回结果,本次请求处理结束.
(4) 若为写请求,首先判断DRAM上是否有存储空间,若有则写入DRAM中,若没有则存入RRAM中.最后将结果返回内存控制器,进一步返回给CPU.
(5) 若请求未命中,产生一个缺页中断.在外存中查找,当读操作发生缺页中断程序从外存读取请求页时,优先考虑将请求页写入DRAM中,若DRAM中没有空间时则写入RRAM中.目的是减少RRAM的写次数,因为RRAM具有较高的写延迟(相对于DRAM).

图2 请求下发流程
2 基于写热度的混合内存页面迁移策略
2.1 写页面热度定义
对写页面的热度进行定义是为了体现页面最近被写访问的情况,若一个页面最近一段时间被经常执行写操作,则该页面可能为热写页面;若一个页面最近一段时间内没有被写过,则预测该页面在以后的一段时间内也可能不会被写访问,则把该页面的状态设置为冷写页面.
LIRS(Low Inter-reference Recency Set,LIRS)替换算法是针对最近未使用算法(Least recently used,LRU)的优化,受LIRS算法中IRR(Inter-Reference Recency)参数(记录一个页面最近2次的访问间隔)思想启发[12].本文将页面最近写访问发生的那个时刻定义为current,将current之后的时间定义为future,将current的上一个写访问发生的时刻定义history,通过添加以下2个计数器共同判定写页面的冷热状态,这样的好处是既考虑了该页面的历史访问情况,又兼顾了该页面将来的访问情况,如图3所示.
定义1 历史写距离count(history).记录页面在最后一次和倒数第二次发生写操作期间,其他被写过的页面的数目,该数值可以反映页面曾经被写的冷热程度.如果某个页面只发生过一次或没有发生过写访问,则count(history)值无穷大.
定义2 将来写距离count(future):表示一个页面在最后一次被写访问后,即该页面的current时刻之后,其他被写过的页面的数目.
count(history),count(future)不统计在同一页面上发生重复写访问的情况,认为对其他页面中的同一页面发送重复写访问不会影响当前页面的写热度.如图3中,页面1上2次写操作期间,其他页面共发生了3次写操作,其中页面2上发生了2次,但我们只记录1次,不重复记录,因此页面1的count(history)=2,count(future)=2.

图3 页面访问的3个时刻
用count(history)和count(future)两个值来评估一个页面的热写度,可以防止一个页面count(history)很小,但很久没有被写过的页面判断为热写页的情况发生.目的是尽量将热写页存到DRAM上,所以在该混合内存结构下,DRAM中允许存储的热写页面数为DRAM能存储的最大页面数.
2.2 写页面热度状态转换过程
表2描述了一个写页面从冷写页状态转变到热写页状态的过程.

表2 写页面热度变化过程
假设内存系统允许的最大的热页面数目为5.在对页面F的写请求到达前,页面A,B,C,D,E均为热写页,其中页面E的count(future)值和count(history)值均为最大,说明页面E是所有热写页中最近最久没有被写过的页面,页面转变过程可以描述为:
(1) 页面F最初的count(future)值为1,count(history)值为8.对页面F的写请求到达后,将其count(future)值与count(history)值进行更新,根据定义,其count(history)值被更新为其前一刻的count(future)的值,更新后的count(future)值为1,故更新后的页面F的count(future)值为0,count(history)值为1.相应的将其他页面的count(future)也进行更新.
(2) 将页面F更新后的count(future)值与页面E的count(future)值比较,页面F的count(future)值小,因此页面F的热写度比页面E更高.
(3) 将页面E的状态更改为冷写页状态,页面F的状态更改为热写页,页面E迁移到RRAM上或者被换出.
2.3 页面迁移
在混合内存DRAM-RRAM结构下,DRAM与RRAM之间需要进行页面迁移操作.当从RRAM向DRAM中迁移时,说明该页面为热写页,采用立即迁移的方式;当DRAM向RRAM中迁移时,说明该页面状态为冷写页,若DRAM中仍有剩余空间,先不执行迁移操作,当不得不迁移时再执行,目的是为了减少RRAM上的写操作次数,因此,此时采用延迟迁移的方式.为保证访问命中率,页面替换采用的是传统的clock算法规则.通过两个链表管理页面,全局clock、写clock.
全局链表(clock):管理所有的内存页面,即DRAM页面与RRAM页面.当请求未命中时,从此链表中选择需要换出的页面.
写clock:记录最近发生写操作的页面信息,同时包含部分被换出内存的页面信息,count(future)max为热写页面中热度最低的页面,因此只追踪比count(future)max小的页面信息,就可以检测到热写页,该链表主要用于判断页面的热写度状态.
当写请求命中,但页面位于RRAM上时,若该页面状态正好从冷写页转换为热写页,先将其迁移到DRAM上,然后再执行写操作.
当写请求未命中时,从外存调入所需页面,同时将其存储到DRAM上,因为写请求未命中时,会对内存产生两次写操作:一次是从外存写入时;另一次是写请求的执行.因此,为了减少在RRAM上的写操作,将其存储到DRAM上.若DRAM上没有存储空间,执行页面迁移操作,将DRAM上的冷写页迁移到RRAM上,为新读入的页面让出空间.
当一个页面被选中,需换出内存时,将其历史写信息保存一段时间.因为该页面可能在不久将来会再次被请求,这时候,若该页面曾是热写页,则将其存于DRAM上,否则分配任意空间.
2.4 算法描述
从请求命中和未命中两种情况展开描述.为每一个页面设置写冷热标志位、访问位、读访问位、写访问位等状态信息,将其初始值均设置为“0”.
算法1:请求命中处理
Input:the requested page isp,operation typeop
Output:the address of thep
p.reference _bit=1;
/将访问页状态置1,页面替换时需要使用此状态位.
if (opis read ) then
p.read_reference=1;∥读访问位置1
else if (opis write ) then
if (opin write_clock) then
p.write_reference=1;∥写访问位置1
if (pin RRAM) then
if( DRAM have free pages) then
migratepto DRAM;
else∥DRAM上没有空闲
use the migration strategy,then write the pagep;
∥在DRAM上选择一个冷写页q迁移到RRAM,将页面P迁移到q的位置
else
setpin DRAM;
else∥页面P不在write_clock中
addpto the write_clock;
setpis write-cold;p.write_reference_bit=0;
算法2:请求未命中处理过程
讨论DRAM、RRAM上的空间已满的情况,请求未命中处理过程.因为若DRAM或RRAM上尚有空间,则请求页可直接调入内存.
Input:the requested page isp,operation typeop
Output:the address of thep
use clock policy to replace a pageqfrom global_clock;
if (opis read ) then∥请求为读操作
if (pin write_clock andpis a write-hot page) then
if (qin RRAM ) then
use the migration strategy to find a DRAM write-cold pagef;
if (havef) then
migrateffrom DRAM toq;
loadptof;
else∥q在DRAM上
loadptoq;
else∥请求为写操作
if (pin write_clock ) then
p.write_reference_bit=1;
else
addpto the write_clock;
setpto write-cold;p.write_reference_bit=0;
if (write_clock is full) then move out a write_clod page;
if (qis in RRAM) then
use the migration strategy to find a write-cold pagef;
migrateffrom DRAM toq;
loadpto DRAM;
addpto global_clock;
setp.reference_bit=1.
3 实验部分
3.1 实验环境
为了同时仿真DRAM和RRAM的特性,本文在GEM5和 NVMain的基础上,构建DRAM-RRAM混合内存模拟器,通过混合内存控制器来负责调度上层下发的请求,并将执行完的数据返回给CPU,环境配置信息如表3所示.

表3 实验环境配置信息
本文采用的基准测试程序集是PARSEC[13],该测试集由多线程应用程序组成,是普林斯顿共享内存计算机应用库,是一种并发程序测试集,它包含的不同领域的应用程序可以代表未来的发展方向.从中选取6个不同基准程序,包括blackscholes、bodytrack、canneal、facesim、streamcluster、x264),输入集选取simMidum规格进行实验.
3.2 实验与结果分析
实验中设计了3种内存结构,分别为4 GB容量的DRAM、4 GB容量的RRAM和2 GB DRAM+2 GB RRAM,首先通过模拟器单独在DRAM设备和RRAM设备上运行上述测试程序集,获得单个设备的性能,然后在混合内存结构上运行同一测试集.
图4展示了3种内存结构下不同基准的平均读延迟,内存总容量均为4 GB.在DRAM内存结构下,所有应用的平均读延迟最小,与RRAM内存结构相比,混合内存结构下部分应用的读延迟低,这是因为DRAM具有较快读速度的物理性质.
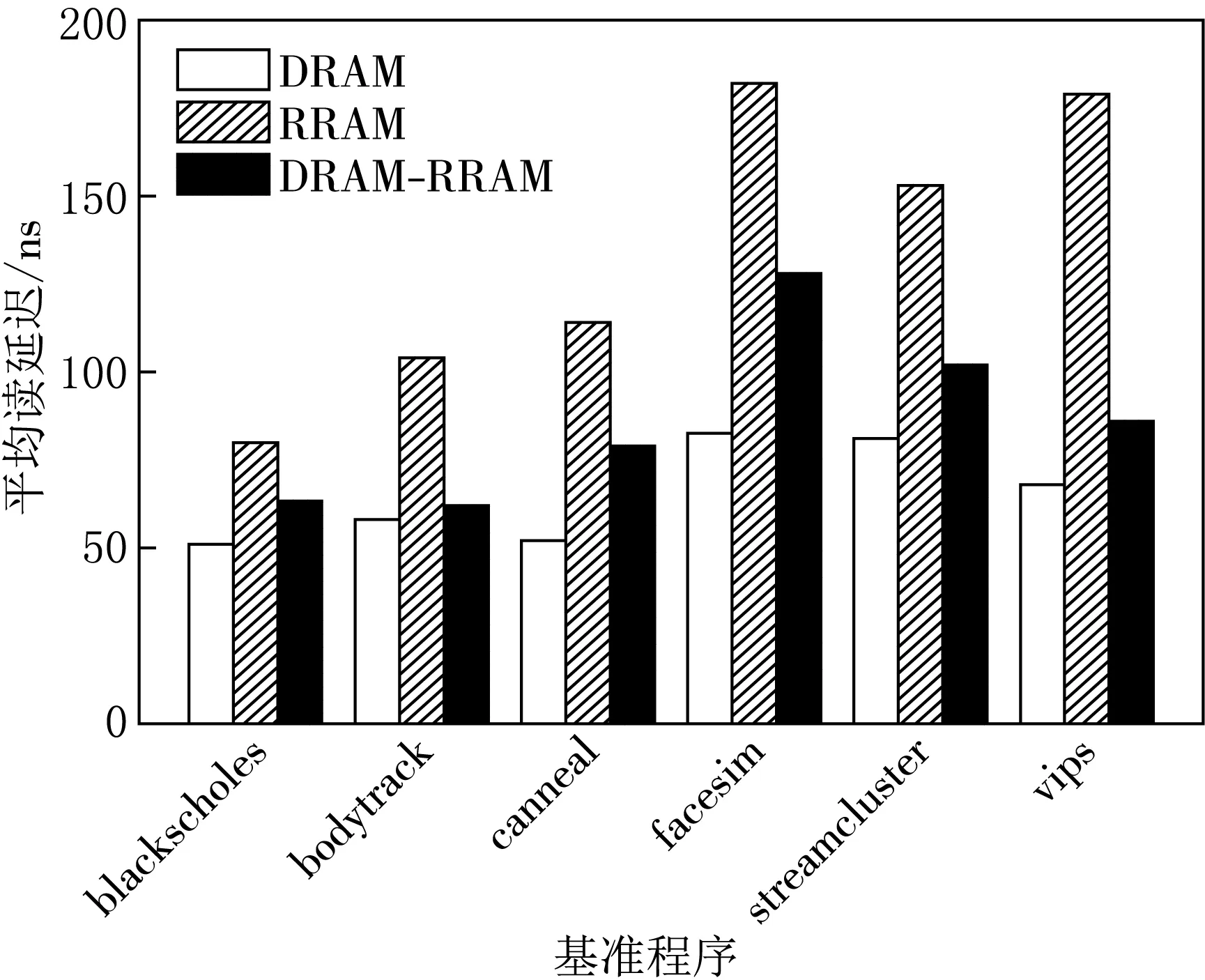
图4 不同内存结构下平均读延迟比较
图5展示了不同内存结构下,基准程序的平均写延迟情况.整体来看,DRAM内存结构下的平均写延迟最小,DRAM-RRAM混合内存结构的写延迟大于DRAM内存结构,但比RRAM单独作为内存时写延迟低.其中streamcluster基准程序在DRAM和DRAM-RRAM内存结构下的平均写延迟接近,而facesim基准程序在DRAM-RRAM内存结构下的平均写延迟较大,并未显示出DRAM快速写的特性.这主要是因为streamcluster属于读密集应用,而facesim属于写密集应用.也就是说,混合内存结构,对读密集应用具有更好的支持,对于写密集型应用可能会反映出RRAM写延迟大的缺点,因为对于写密集性应用,当大量写请求发送到RRAM上时,会带来大量延迟.
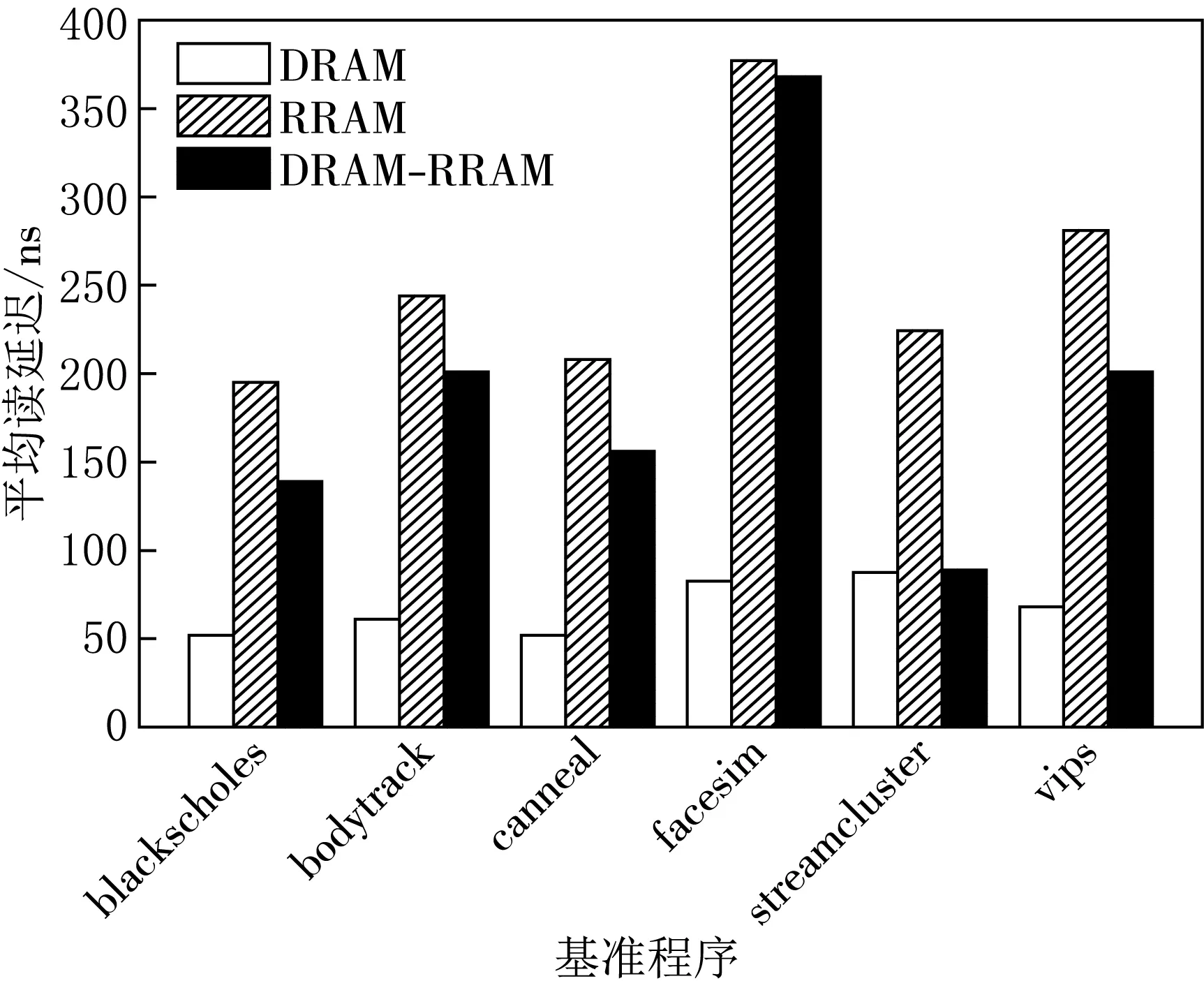
图5 不同内存结构下平均写延迟比较
以上实验中使用页面管理算法是LRU算法,以下实验将基于所提的写热度页面迁移策略开展.从平均运行时间的角度,对其有效性进行验证.
不用页面管理策略下的平均运行时间见图6,可以看到在混合内存结构DRAM-RRAM下,本文所提页面管理策略与传统的LRU算法相比,平均运行时间明显降低,在写密集应用facesim上最为明显,运行时间缩短了约31.2%.这是因为本文通过对写页面的热度状态进行定义,尽可能减少RRAM上的写操作,降低由于RRAM写操作带来的延迟,同时使用clock页面替换算法,保证了命中率,降低了整体运行时间,提高了系统性能.
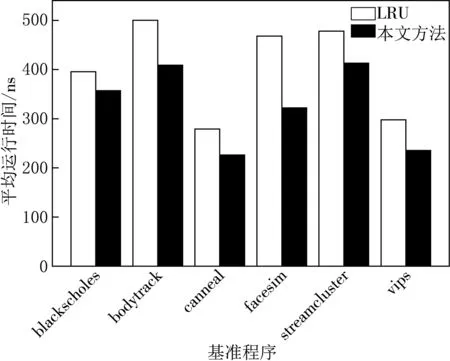
图6 不用页面管理策略下的平均运行时间
4 结论
本文基于Gem5和NVMain构建了DRAM-RRAM混合内存模拟器,考虑混合内存结构下RRAM寿命及写延迟较大的问题,提出一种基于写热度的混合内存页面迁移策略,根据页面最近写访问情况,引入count(history)和count(future)计数器,对页面的写热度状态进行判定.实验结果表明,本文构建的混合内存结构,能在保证系统性能的情况下,增大内存系统容量,所提页面迁移策略能有效缩短系统运行时间,对于写操作密集型应用,降低效果更加明显.本文考虑的是减少RRAM上写操作数量,如何在此基础上将RRAM上的写操作平均分配到个各储单元,还需进一步研究.
猜你喜欢
保健医苑(2022年1期)2022-08-30
北京航空航天大学学报(2021年6期)2021-07-20
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
电脑爱好者(2015年21期)2015-09-10
环球时报(2014-06-18)2014-06-18
计算机世界(2009年27期)2009-07-30
电脑爱好者(2009年13期)2009-07-07
