
基于BERT的金矿地质实体关系抽取模型研究
2021-07-15 07:22黄徐胜朱月琴付立军刘雨江唐珂珂李
地质力学学报 2021年3期
黄徐胜朱月琴付立军刘雨江唐珂珂李 金
1.中国科学院大学,北京 100049;2.中国科学院沈阳计算技术研究所,辽宁 沈阳 110168;3.自然资源部地质信息工程技术创新中心,北京 100037;4.中国地质调查局发展研究中心,北京 100037;5.山东大学大数据技术与认知智能实验室,山东 济南 250100
0 引言
地质文献是地质科研成果的规范化记录和表现形式,是探索研究地球科学的成果结晶和研究基础。随着新一代信息技术的研发及应用,各个部门积累了大量的地质文献数据。据统计,目前中国地质文献中心积累的地质文献数据约为9041万条,总量达102 T,属于典型的地质大数据(谭永杰等,2017;陈建平等,2017)。因此如何快速、有效地分析、挖掘这些海量的文献数据,发现潜在的地质知识价值,实现地质数据的“增值”,是地质信息化工作所面临的一项重要挑战。而基于地质文献的实体关系抽取研究的目的就是准确、高效识别并抽取出地质文献中的实体以及之间的关系,建立起实体间的知识体系结构,以便于人们快速发现和理解知识点之间的关联脉络,目前这已经成为地质大数据的一项研究热点。
金矿地质文献中蕴含了大量的金矿相关实体以及金矿地质实体之间的关联关系(薛玉山等,2020;张兵强等,2020;张康等,2020;汪青松等,2021),识别金矿实体及实体间的关系对于进一步挖掘金矿地质文献知识、提升金矿地质文献数据的分析挖掘以及促进金矿的进一步开采利用等方面有着积极而深远的意义。文中论述了一套基于远程监督关系的金矿地质实体关系抽取模型构建方法,尝试通过少量标注样本建立地质实体的关联关系的智能抽取方法,从而达到对金矿文献的快速分析挖掘及潜在知识发现的目的。
1 金矿地质实体关系抽取研究现状
关系抽取是信息抽取的核心内容,旨在提取文本中实体对的关系。在有监督关系抽取中,通常把关系抽取当作关系分类的问题来处理,但是模型经常面临缺乏训练标注数据的情况。为解决这个问题,Mintz et al.(2009)首次提出远程监督思想,使用知识库对齐目标文本的方法,构造远程监督数据集。Riedel et al.(2010)在此基础上提出 “至少一次 (at-least-once assumption)” 假设,把远程监督关系抽取看作多实例学习(MIL)问题,把所有包含该实体对的句子整合成句袋,基于句袋进行分类。Hoffmann et al.(2010)提出多实例结合多标签的方法缓解错误标注问题。Zeng et al.(2015)在远程监督方法中使用CNN(convolutional neural networks)模型,提出了Piecewise CNN(PCNN)模型,采用max pooling的方法,保留细粒度的信息。在PCNN的基础上, Lin et al.(2016)融合注意力机制,对句袋中的每一个句子分配权重,权重的大小决定了该句在句袋中的比重,有效地缓解了数据集中的噪声问题。Feng et al.(2018)提出了强化学习的方式,该模型的实例选择器用于减轻噪声,使得模型更有效地训练数据,然后进行关系分类训练。蔡强等(2018)融合句子层次的注意力机制和词语层次的注意力机制提出多尺度注意力机制的方法,准确率在NYT-Freebase(NYT)数据集上达到了78%。
除了浅层模型之外,Huang and Wang(2017)、蔡强等(2019)提出一种基于深度残差神经网络的抽取方法,该方法利用残差神经网络获取特征。唐朝等 (2020)在残差网络的基础上,融合BiGRU模型,在公开的数据集NYT上进行关系抽取,准确率比残差网络提升了2.9%。Bing et al.(2019)、钱小梅等(2020)采用DenseNet神经网络的抽取方法加深网络,解决神经网络中梯度消失的情况。
近年来,预训练模型成为关注的焦点。BERT(Jacob et al.,2019)是google提出的基于双向Transformer(Vaswani et al.,2017)的网络模型,该模型被证明能够有效地应用在大部分的自然语言处理任务中。Soares et al.(2019)提出了一个利用预先训练的BERT语言模型结合目标实体的信息来处理关系分类任务的模型。Alt et al.(2019)提出将Generative Pre-trained Transformer(GPT)模型应用在远程监督关系抽取中,该模型被证明可以有效地捕获文本的语义和语法特征。上述模型做出了很大的贡献,但是存在以下问题:①没有解决关系方向问题;②没有学习复杂的数据特征。
由于地质实体间关系复杂、类型多,采用智能建模方法实现地质实体的关系自动识别难度大。因此目前基于地质文本信息的抽取研究主要集中在地质实体的抽取及可视化表达等方面,如:Zhu et al.(2017)提出的地质知识图谱构建框架及探索;张雪英等(2018)采用DBN模型实现了对地质实体信息的初步识别;而地质实体间关系抽取还停留在初步探索阶段,如:朱月琴等(2017)在地质数据语义模型中提出地质文本表达中的6种地质语义关系;吕鹏飞等(2017)采用统计语言模型和基于规则的方式提取三元组集合等。因此文章在前期研究的基础上,构建了基于远程监督的金矿地质实体关系抽取模型,并通过金矿地质文献的少量人工标注,探索并实现了金矿地质实体关系的智能化抽取。
2 远程监督关系抽取
关系抽取是知识图谱补全的重要环节,在自然语言处理领域具有重要的地位,如智能问答(Yih et al.,2015)、语义搜索(朱月琴等,2017)等。使用有监督的方法进行关系抽取需要大量的语料,这些语料完全依赖于人工的标注。然而,人工标注的方法只能构建少量的数据集。同时针对特殊领域的关系抽取,由于对标注人员的专业知识有一定要求,因此标注进展非常缓慢。远程监督的关系抽取方法(Mintz et al.,2009)可以使用金矿知识库与金矿地质文献对齐的方法自动标注数据集。该方法做出如下假设:“如果金矿地质文献中的两个实体在对应的金矿知识库中存在着某种关系,则认为两个金矿实体在所有含有这两个实体的句子中都有这样的关系”。
如图1前两个句子所示:如果知识库中存在实体关系三元组(焦家式金矿、类型、破碎带蚀变岩型金矿),那么包含“焦家式金矿”和“破碎带蚀变岩型金矿”这个实体对的所有句子都会存在“类型”关系。该方法解决了缺乏地质领域数据集的问题。然而,使用远程监督关系抽取模型时,存在以下缺点。
(1)远程监督的假设过强,会存在标注错误的问题。如图1第三句所示:句子中存在“焦家式金矿”和“破碎带蚀变岩型金矿”实体对,“破碎带蚀变岩型金矿”并不是“焦家式金矿”的“类型”,但是仍然会以“类型”的关系存在于数据库中。这种启发式对齐知识库的方法,使得数据集存在错误标签问题。

图1 远程监督框架结构Fig.1 Framework of the remote supervision
(2)没有解决实体关系的方向问题。现有的关系抽取方法把关系抽取问题按照关系分类的方式处理,并不能很好地识别实体关系方向问题。除此之外,知识库和文本中的实体关系顺序存在不一致的可能。
(3)识别关系类别的难易程度不同。现有模型在训练过程中无法区分关系类别的易训练程度,导致模型不能有效地训练复杂的实体关系。
3 基于远程监督的金矿地质实体关系抽取模型构建
根据金矿地质数据量大以及文献标注较少等特征,文中引入了远程监督的思想。针对金矿地质文献分析角度单一性和复杂性的数据特征,文中定义了金矿地质文献的实体和关系的类型,提出了结合地质领域特征的关系抽取模型。如图2所示,模型一共包括四个模块:①金矿地质数据编码模块;②基于BERT的金矿地质特征提取模块;③金矿地质分类模块;④金矿地质实体的过滤模块。
3.1 金矿地质数据编码模块
对于远程监督关系抽取,Zeng et al.(2015)曾通过分片卷积神经网络的方法,获取句子的结构信息,提高特征提取能力。文中结合金矿地质数据集中的知识,采用知识库顺序的实体编码方法。通过将一个无向关系分为两个有向关系的方式确定金矿地质文献中的关系方向。将每个关系r∈R(R为关系集合)分为两个关系类,即:r(e1,e2)和r(e2,e1),其中e1和e2表示两个实体。在实体前后加入特殊的标签 “#”和 “$”,“#”表示头节点的边界, “$”表示尾实体边界,实体根据知识库中的顺序进行标记,如图2所示。
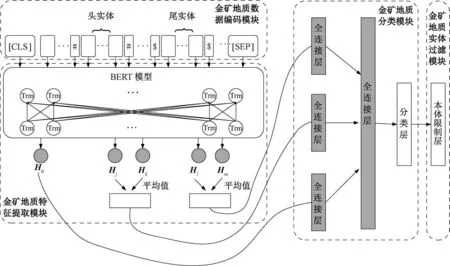
图2 远程监督关系抽取模型Fig.2 Remotely supervised relation extraction model
3.2 基于BERT的金矿地质特征提取模块
BERT(Devlin et al.,2019) 是google提出的基于双向Transformer(Vaswani et al.,2017)的网络模型,在句子之间用[SEP]作为分隔符号,在每个序列的开始,添加一个特殊的字符[CLS],用于存储该序列的语义信息。金矿的实体关系分类就可以利用[CLS]的输出进行预测。
模型的输入表示由词嵌入、句子嵌入和位置嵌入构成。给定一个包含头实体和尾实体的句子s,Hj和Hk向量是头实体经过BERT模型的状态向量,Hl和Hm向量是尾实体经过BERT模型的状态向量。H0向量是[CLS]经过BERT的状态向量。经过平均操作、激活函数以及全连接层,得到最终的头实体和尾实体输出,如公式1所示:
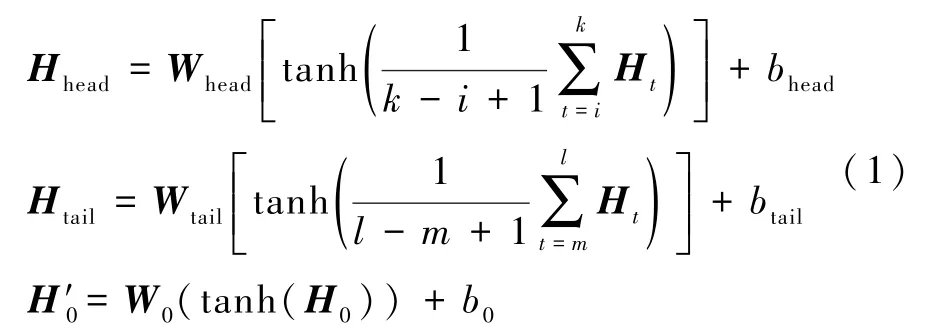
其中tanh在神经网络中是激活函数,用于增加神经网络的非线性程度;Whead表示头实体的权重向量;Wtail表示尾实体的权重向量;W0表示[CLS] 的权重向量;bhead、btail、b0表示头实体、尾实体和[CLS]的偏置参数;i、k表示头实体的开始位置与结束位置;m、l表示尾实体的开始位置和结束位置;Ht表示Hj、Hk这样的状态向量;H′0、Hhead和Htail表示[CLS]、头实体、尾实体经过第一层全连接层得到的向量。
连接H′0、Hhead和Htail经过第二层全连接层得到向量Hfinal,如公式2所示:
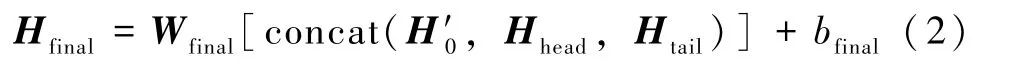
其中Wfinal为连接H′0、Hhead和Htail后计算的权重;bfinal为连接H′0、Hhead和Htail后计算的偏置参数;concat是连接H′0、Hhead和Htail的函数。
3.3 金矿地质分类模块
训练神经网络的目标是使正确类的概率最大化,一般是通过最小化交叉熵损失 (cross-entropy loss)来实现的,如公式(3)所示:
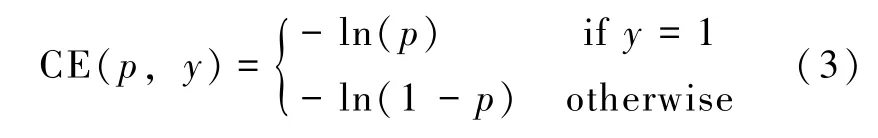
其中CE表示交叉损失函数;p表示准确率;y表示是否为真实的标签。当y为真实的标签的时候,则进行-ln(p)运算,否则进行-ln(1-p)运算。
由于最小化交叉熵损失函数不能区分关系训练的难易程度,因此通过引入γ超参数识别样本难易程度(Lin et al.,2017),如公式(4)所示:
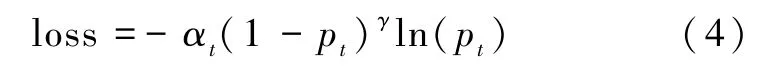
其中loss为神经网络中的损失函数,用于判断预测值与真实值的差距;α和γ是可以调整的超参数,α为权重,介于[0, 1]之间,用于减轻样本太多对训练的影响;t为样本的编号,γ用于对损失函数的调节。当y=1时,pt趋向1,表示容易训练的正样本,损失函数的权重趋向0;当y=0时,pt趋向0,表示极难训练的正样本,对损失函数的权重趋向0。因此通过该损失函数可以提取复杂地质实体之间的特性,从而大大提高了该模型的准确率。
3.4 金矿地质实体类别过滤
金矿地质领域存在丰富的实体关系信息。实体类别与实体类别之间存在着某种特有的关系,现有的模型并没有融合这些特征,造成抽取的实体关系存在常识错误等问题,准确率大大降低。结合金矿地质文献的特征,构建关系的实体类别过滤层。假设T=(E1,E2,…,En),其中T是本体的集合。
如图3,e1,e2∈E1;e3,e4∈E2;e5,e6∈E3; 其中en代表金矿地质实体,如:黄铁矿、方铅矿、石英等。En是实体所属的本体,如:化合物、金矿、种类等,r表示的是实体间的关系,E1与E2之间的关系是r1(E1,E2),E2和E3之间不存在关系,E1与E3之间的关系是r2(E1,E3)。当抽取的结果是r1(e1,e3),满足E1与E2之间的关系,设为可信。如果抽取结果为r2(e3,e5)时,其本体E2与E3没有关系,则将关系可信度设为0。当抽取的结果是r2(e1,e3),而E1与E2之间并没有这种关系,则将r2(e1,e3)可信度设为0,并在候选关系中,选择合适的关系。
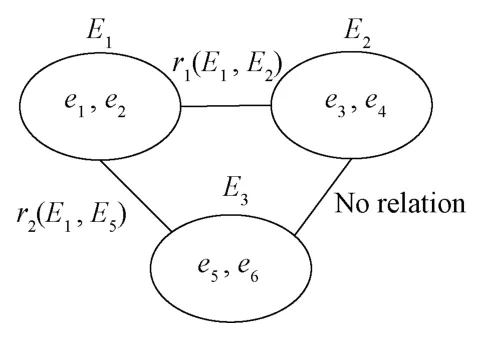
图3 本体关系图Fig.3 Ontology diagram
4 模型的验证与分析
4.1 实验数据准备
首先,在Riedel et al.(2010)数据集上评价文中建立的关系抽取模型。该NYT数据集由知识库Freebase和纽约时报语料库启发式对齐的方法构成,是远程监督领域标杆型的数据集。
同时,在地质领域数据集上进行模型检验。该数据来源于中国知网,选用2000至2015年28740篇与金矿相关的学术论文。经过数据预处理后,将人工标注的4021个金矿地质三元组与文献对齐,形成290489条数据集。从中挑选50970条有效数据,33761条用于模型的训练,17209条用于模型测试。文中概括归纳以金矿矿区、矿床、矿段和矿体为例的金矿地质实体一级关系为控矿因素、找矿标志以及属性特征等。其具体实体及关系见图4所示。
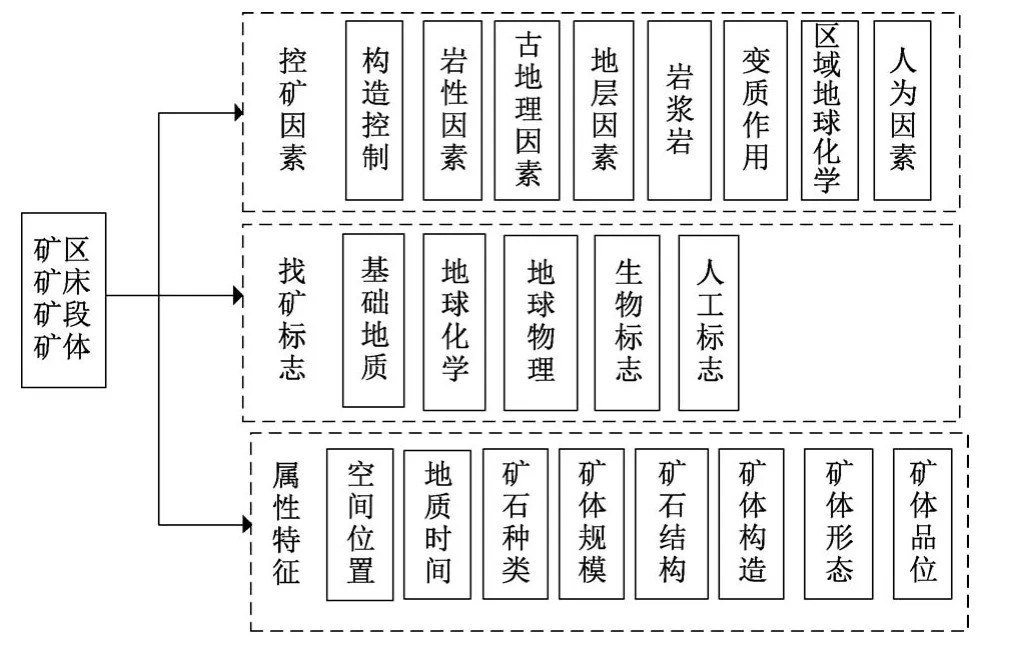
图4 实体关系类别Fig.4 Categories of entity relation
4.2 实验过程与结果分析
文中将Lin et al.(2016)提出的PCNN+ATT(Piecewise CNN+attention)模型、Huang and Wang(2017)提出的残差神经网络(ResNet)模型和Gao et al.(2017)提出的全连接神经网络(DenseNet)等模型作为基线模型,并对文章模型与基线模型的抽取效果展开了详细的解析。
(1)模型的实验参数设置
在这个实验中,文章模型实验的参数如表1所示。

表1 实验参数Table 1 Experiment parameters
(2)模型的评价指标
模型的评价指标与其他远程监督关系抽取论文 (Zeng et al.,2015;Lin et al.,2016;蔡强等,2018)指标类似,文中采用P@N表示概率最大的前N个金矿地质实体关系预测正确的概率,分子表示预测成功的实体对的个数,N需要手动设置,如:N=100,则表示前100个金矿地质实体对,如公式(5)所示。PR(准确率-召回率)曲线图形成的面积可以用来评价模型的整体性能。
(3)金矿地质实体关系抽取效果
为验证文中模型的关系抽取效果,分别在地质领域数据集和NYT通用数据集上进行对比实验,实验结果见表2和表3。

表2 各种模型在NYT数据集上的抽取效果Table 2 Extraction effect of the models in NYT dataset
由表2可知,文中的方法在Top 5000时平均准确率达88.6%,超过PCNN+ATT模型35.2%。证明该模型能够一定程度降低数据集噪声,提高关系抽取的精准度。其次,文中的模型在Top 300、Top 1000和Top 5000上平均准确率分别为96.1%、94.4%、88.6%,证明该模型有着更稳定的整体表现。综上所述,该方法在远程监督的任务上是可行的,可以用在地质领域的关系抽取中。
由表3可知,金矿地质实体关系抽取效果的整体趋势和NYT数据集一致。文中构建的模型在该领域数据集的关系抽取效果比NYT数据集好。原因是地质数据标签为12个,相比NYT数据集的53个标签,金矿地质实体关系分类相对容易。其次,地质数据的特征更加明显,特征提取更加方便。PCNN+ATT模型虽然在P@100时,平均准确率达到99.0%,但是到了P@300的时候,平均准确率急剧下降。相比之下,文章模型表现更加平稳,在Top 300、Top 1000和Top 5000时平均准确率分别为100.0%、98.6%、93.1%。综上所述,文章模型在有向实体关系识别方面表现稳定。

表3 各个方法在地质领域数据集上的抽取效果Table 3 Extraction effect of the methods in geological dataset
由图5和图6可知,文中模型曲线为在NYT数据集和地质领域数据集上的面积分别为0.65和0.75,在保证了准确率的同时,提升了召回率,因此该模型能够解决实体关系识别的长尾问题。
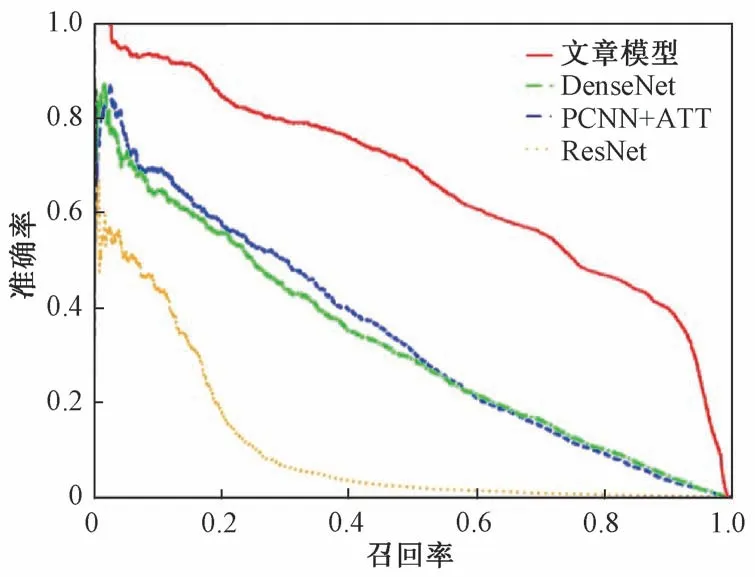
图5 模型在NYT数据集上的PR图Fig.5 PR graph of each model in NYT dataset
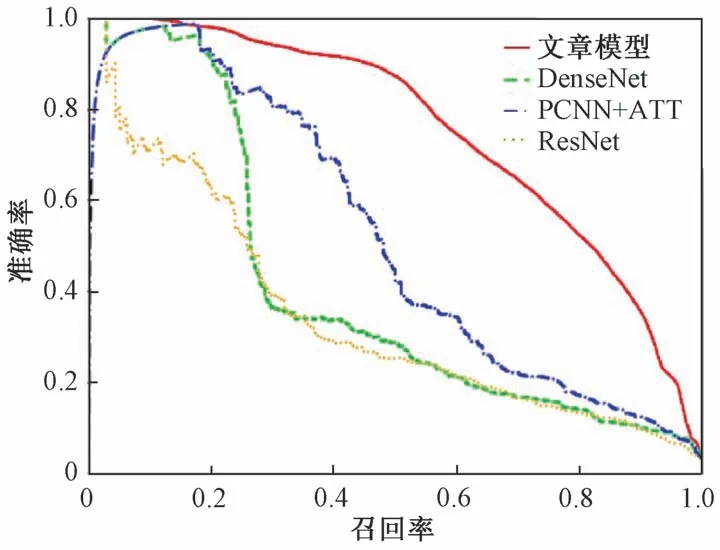
图6 模型在地质数据集上的PR图Fig.6 PR graph of each model in geological dataset
使用文中模型对单篇文献数据(宋春明等,2014)进行关系抽取效果验证,部分抽取结果如图7。由图7可知,模型对金矿地质实体和关系进行了准确的判断。

图7 文章模型的抽取效果Fig.7 Extraction effect of BERT model
综上所述,文章的模型能够解决金矿地质实体关系抽取问题,在地质领域的数据集上有较高的准确率,长尾问题得到了解决。因此,该模型适用于金矿地质实体关系抽取。
5 结论
文章探讨了基于金矿文献的地质实体关系抽取方法。首次将远程监督关系抽取的思想引入金矿地质文献中,初步解决了目前由于金矿实体关系复杂、人工标注少而造成的金矿实体关系智能化抽取程度不高等问题;并利用远程监督的思想,构建了批量的金矿地质关系抽取实验数据集;同时在模型的构建及训练过程中,通过数据编码、分类模块、实体过滤以及限制输出等方法的改进,大大提升了金矿相关实体关系的抽取效果,实现了对金矿文献数据的实体关系抽取实验。实验结果验证了该方法的有效性。
将来可在进一步总结提炼金矿实体关系基础上,结合地质实体的背景信息,达到关系抽取效果的提升,从而为地质实体的智能识别、关系的抽取以及智能找矿等应用方面提供理论技术方法支撑。
猜你喜欢
军事文摘(2022年20期)2023-01-10
英语文摘(2021年11期)2021-12-31
矿产勘查(2020年2期)2020-12-28
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年3期)2020-12-19
中国外汇(2019年18期)2019-11-25
学生天地(2018年19期)2018-09-07
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
