
基于整群抽样和支持向量回归模型的高功率半导体激光器剩余使用寿命预测
2021-07-15 02:55:04严建文钟小虎郭三敏1
中国机械工程 2021年13期
严建文 钟小虎 范 煜 郭三敏1,
1.合肥工业大学管理学院,合肥,2300092.合肥工业大学航空结构件成形制造与装备安徽省重点实验室,合肥,2300093.浙江大学机械工程学院,杭州,3100584.安徽皖维集团有限责任公司,合肥,238002
0 引言
高功率半导体激光器及其阵列具有体积小、质量小、能耗低、光斑易调节、光电转换效率较高的优点,已广泛应用于金属材料加工,该种激光器可用于连续性焊接不同型号的合金钢,获得大面积深度均匀的相变硬化层,也能够精确地控制熔覆层结构及其几何形状[1]。为保证材料加工过程的安全性和可靠性,需利用预测与健康管理(prognostics and health management, PHM)技术对高功率半导体激光器的状态进行监测和分析[2]。PHM技术的主要目的在于预测故障发生的时间和地点,估计剩余使用寿命(remaining useful life, RUL)的分布或期望[3],提高激光器的可靠性。准确的RUL预测可为决策者提前制定维修计划和优化供应链管理,减少不必要的维修或更换成本,提供有效的信息。
相比于传统的基于可靠性的方法[4-5],现有的数据驱动方法主要通过对状态监测或检测数据进行分析,捕捉数据中潜在的退化规律和故障失效信息,通常可以分为两类。①基于退化模型的方法[6](如维纳过程模型[7]、伽马过程模型[8]、逆高斯过程模型[9]、隐(半)马尔可夫模型[10-11]等),旨在对设备的退化演化过程进行建模,如采用逆高斯过程模型对退化过程进行分析,以预估GaAs激光器的RUL分布[12-14]。这类方法均假定退化模型是事先知道的,模型参数利用状态监测数据进行估计,然而实际工程中很难事先确定一个适当的退化模型,且退化模型选择不当将会严重影响RUL的预测精度[15]。②基于机器学习的方法[16](如人工神经网络(artificial neutral network, ANN)[17]、基于相似性的学习算法(SbRP)[18]、支持向量回归(support vector regression, SVR)方法[19-20]等),试图将退化数据与RUL之间的关系进行直接映射。如文献[21]利用SbRP方法对GaAs激光器的RUL进行了预测;文献[22]基于自回归模型和SbRP方法,提出了一种基于相似性的差值分析(SbDA)方法用于GaAs激光器的RUL预测。
基于机器学习的方法能够有效克服退化模型未知的问题,近年来已得到了广泛的研究和应用。然而,如何可靠地在失效历史数据有限的情况下实现对目标设备的实时预测仍然具有极大的挑战。SVR方法是支持向量机(support vector machine,SVM)算法在RUL预测领域最常见的应用方式,可有效地解决小样本情况下的预测问题。BENKEDJOUH等[19-20]利用SVR方法将退化时间序列映射成非线性回归,然后将得到的回归拟合到功率模型中,并用于机械设备的RUL预测。LIU等[23]建立了一种改进的概率SVR模型用于预测核电站装备部件的RUL。FUMEO等[24]通过优化精度与计算效率之间的权衡,开发了一种在线SVR模型用于轴承的RUL预测。上述研究虽然拓展了SVR模型在RUL预测问题中的应用,但均未考虑关键预警阶段特别是临近故障失效前的预测可靠性问题,即使SVR方法所训练模型的回归曲线的整体误差最小,也有可能因为关键预警阶段数据拟合得不好而导致实时预测的结果未必能可靠地支持维护决策。关键预警阶段RUL预测的准确性是决策者在运行可靠性和成本之间权衡的决策基础,特别是临近故障失效前。HUYNH等[25]提出了一种考虑RUL预测精度的预测维护决策框架,其决策框架的性能优劣取决于临近失效阶段的RUL预测精度。ZHAO等[26]根据不同的可靠性水平将产品退化过程简化为5种状态,其中,状态0为正常运行状态,状态1为退化加速状态,状态2和状态3为关键预警状态,状态4为失效状态。相对于整个退化过程,状态2和状态3阶段的RUL预测结果对维护决策更具有实际意义。
基于上述情况,本文提出了一种基于整群抽样和SVR模型的方法用于高功率半导体激光器的RUL预测。对测试样本状态2和状态3阶段的数据进行多次整群抽样后用于SVR模型测试,SVR模型中的参数使得SVR模型对训练样本的后期数据拟合得更好,更能满足维护决策需要。最后,所提方法的有效性、准确性和稳健性通过GaAs激光器数据集得到了验证。
1 基于整群抽样和SVR模型的剩余寿命预测框架
SVR方法基于结构风险最小化原则,保证了模型最大的泛化能力,特别适合处理小样本、非线性和高维数据,它在RUL预测领域最常见的应用方式为最小二乘支持向量回归(least square support vector regression, LS-SVR)方法。给定一组训练集{(xp,yp)|p=1,2,…,n},其中xp∈RN为N维输入向量(N≥1),yp∈R为输出值,n为训练样本总数,则LS-SVR模型可用一个非线性映射函数φ(·)来表示,即
y=wTφ(x)+b
(1)
式中,w为权向量;b为偏差项。
通过将原始输入数据映射到高维空间,非线性可分问题在该空间上变为线性可分问题,则LS-SVR问题可变为求解为如下优化问题:
(2)
式中,ep为随机误差;γ为调节参数;m为支持向量的个数,且m≤n。
此外,根据拉格朗日函数和KKT定理,采用非线性核函数时的LS-SVR可表示为
(3)
式中,ap为拉格朗日乘子;K(x,xp)表示非线性核函数。
图1给出了某个测试样本采用现有SVR方法的测试结果,可以看出,即使训练得到了相对于整个数据集最优的模型参数,但状态2和状态3这两个阶段的拟合曲线与实际曲线相差甚远,远远达不到制定最佳维护策略的要求,甚至会造成提前停机或失效风险。如何提高算法预测结果的可靠性是当前工业应用的实际需求,然而直接对式(2)进行改良是个极大的挑战,可能会使算法失去其一般性。鉴于此,本文提出了基于整群抽样的方法,通过对状态2和状态3两个阶段的测试数据进行多次整群抽样来间接增大上述两个阶段数据在算法实现过程中的误差权重,使得算法更侧重于这两个阶段的预测准确度。假设Z={z1,z2,…,zp,…,zq,…,zn}为数据集,其中z1,z2,…,zn为数据向量,则整群抽样方法在本文方法中的应用形式如图2所示,k(k=1,2,…,K)为整个退化过程中的某一阶段,其中K为整个退化过程划分的阶段数。使用整群抽样的本文方法与传统SVR方法主要区别在于:本文方法将测试样本k阶段的数据Zk={zp,…,zq}进行整体抽样h次并重新放回,从而得到新的测试样本,对应的测试数据较原始测试数据多出了h组k阶段的数据,
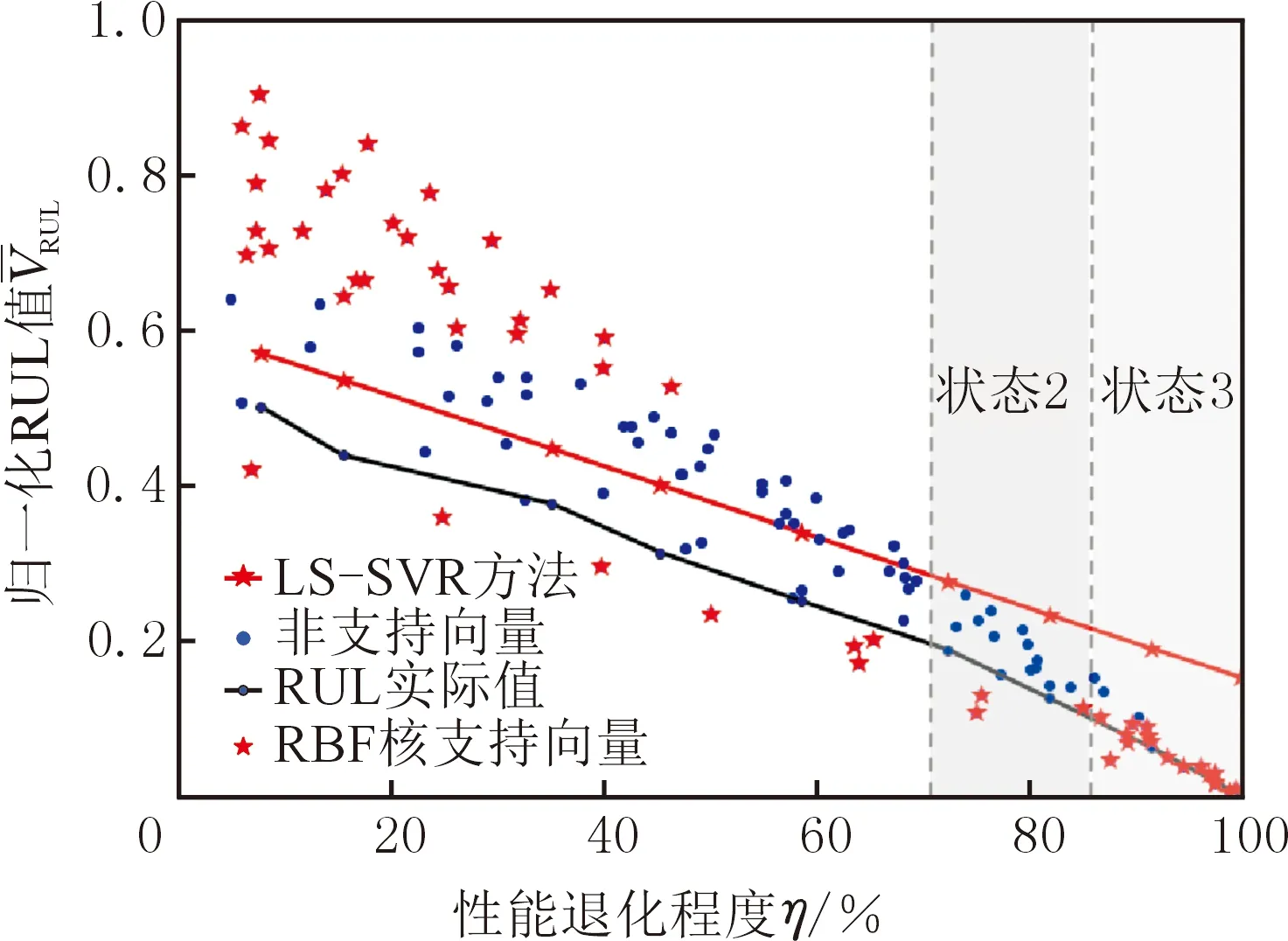
图1 传统SVR模型某样本测试结果Fig.1 Testing result of a sample by traditional SVR model

图2 整群抽样在本文方法中的应用形式Fig.2 Usage mode of cluster sampling in the proposed method
用该测试数据进行测试得到的最优模型参数即为k阶段的模型参数,对应模型对整个退化过程中的k阶段也是拟合最优的。整群抽样后,Zk中每个数据点的权重从1/n增大到wZk,其中,wZk可由下式计算:
(4)

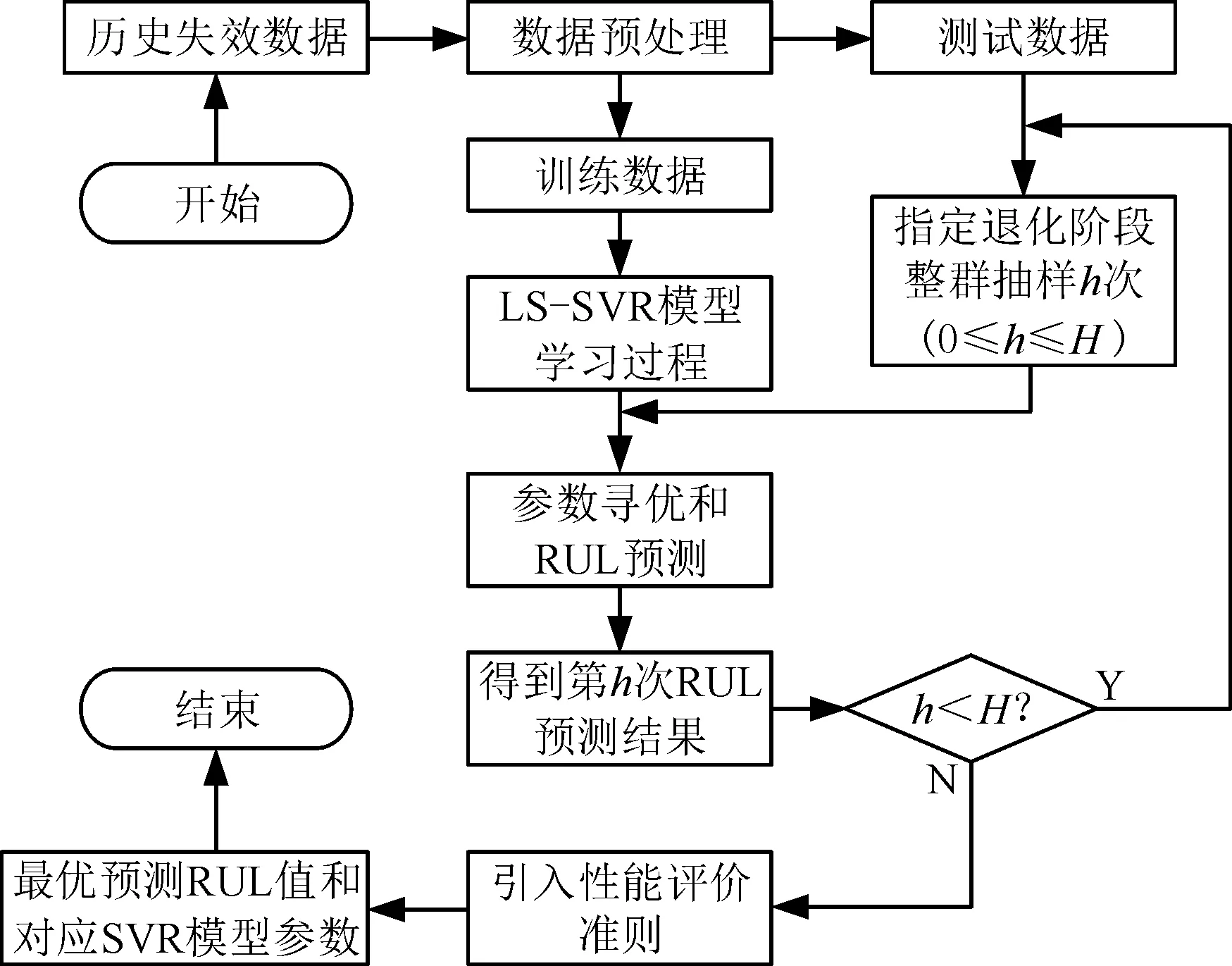
图3 基于整群抽样和SVR模型的剩余使用寿命预测流程Fig.3 RUL prediction flow chart based on cluster sampling and SVR model
2 实例分析
2.1 数据来源
本文采用的GaAs激光器是一种广泛应用的高功率半导体激光器,其相关数据参见文献[22]。本研究的所有记录数据如表1所示,均为GaAs激光器在80 ℃恒定热应力下工作电流随时间变化而增加的百分比,已被广泛用作性能退化指标进行RUL估计[12-14,21-22]。表1中共有15个实验样本,每250 h测试一次数据,至4000 h为止。假设产品的失效阈值为6(即工作电流增加6%,GaAs激光器功能失效),状态2和状态3下对应的性能退化数据分别为[4,5)和[5,6),则本实验注重性能退化数据在[4,6)之间的RUL预测准确性,实验数据退化曲线见图4。由于GaAs激光器的退化曲线均近似于线性回归模型,因此其各自的失效时间可通过非参数局部线性估计方法来确定[27]。选取样本1~5为测试样本,样本6~15为训练样本,采用本文方法对测试样本在状态2和状态3下的RUL进行估计,并与传统SVR方法、SbRP方法和SbDA方法这三种小样本方法进行比较分析。性能评价准则依据平均绝对误差(mean absolute error,MAE),MAE值越小,表明性能越佳。
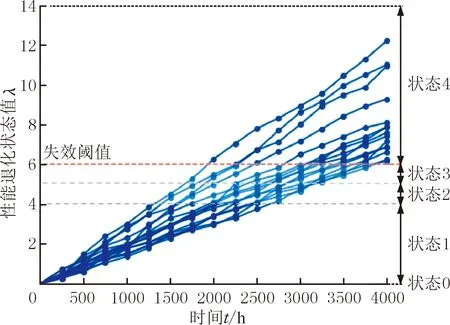
图4 GaAs激光器实验数据退化曲线Fig.4 Degradation curves of GaAs laser experimental data
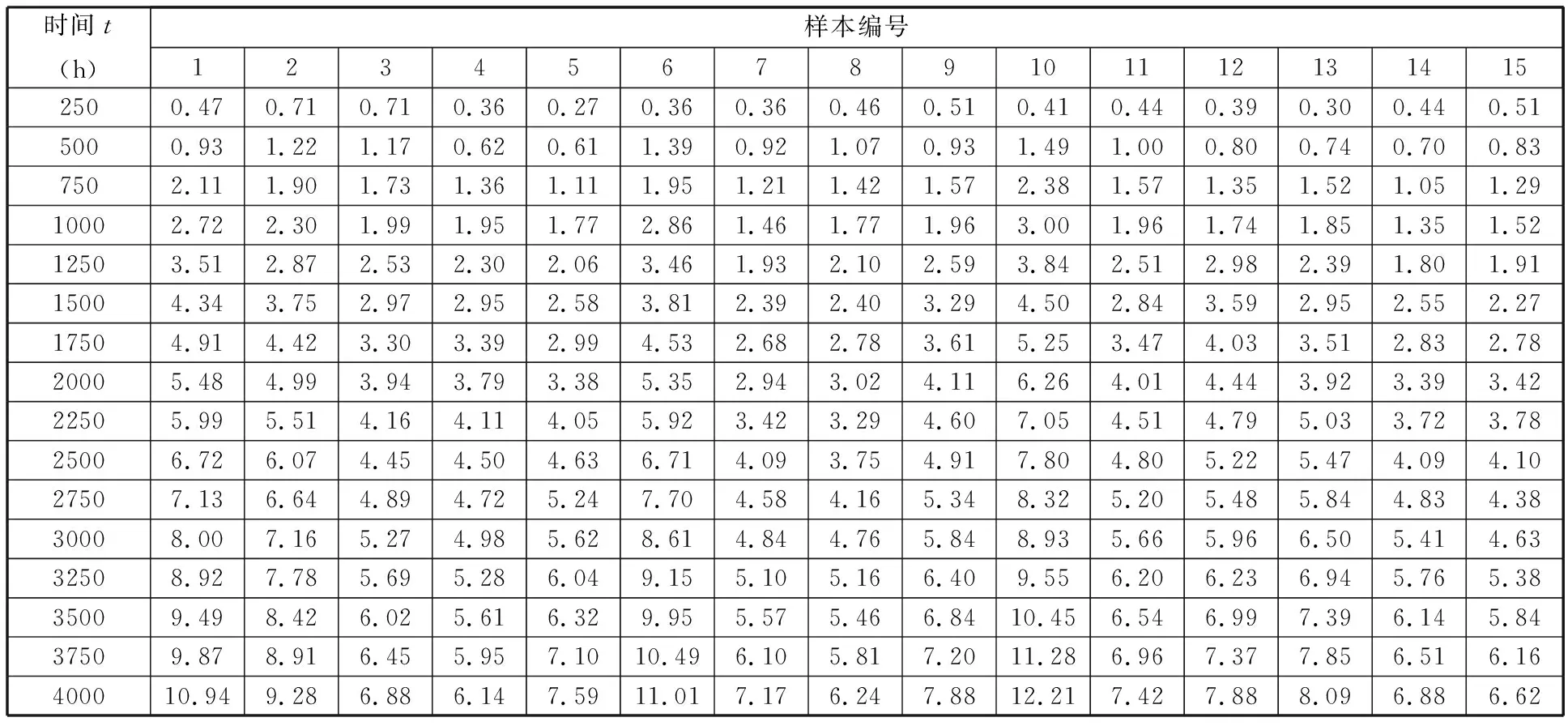
表1 GaAs激光器在80 ℃热应力下的性能退化数据(工作电流增加百分比)
2.2 结果与分析
本实验中,设定最大抽样次数H=10,分别对测试样本状态2和状态3下的数据进行整群抽样,则可获得121种测试结果。状态2和状态3下的抽样次数均为0时,本文方法等同于传统SVR方法。以样本1为例,在状态2和状态3两个状态下所有测试结果的误差如图5所示,其中,最大MAE为473.76 h,最小MAE为4.27 h。测试结果表明,采用本文方法可以有效地减小离失效阈值更为接近的关键预警阶段的预测误差,可以使得设备在更接近失效阶段预测RUL更加准确,更有利于维护决策。在本实验中,假定性能退化状态值取4时为关键预警值,当性能退化状态值超过4但不超过6时则认为设备性能状态处于关键预警阶段,即状态2和状态3为关键预警阶段。对于样本1,在1500~2250 h时的性能退化数据超过关键预警值且处于状态2和状态3下,期间的预测结果直接关系到维护决策任务的经济性和可靠性。测试结果如表2所示,假设决策者要求的预测结果置信区间为预测值±10%,则在样本1的测试结果中,仅本文方法在1500 h、1750 h和2000 h处达到要求,传统SVR方法、SbRP方法和SbDA方法的预测结果均不符合要求。这主要是因为在训练样本有限的情况下,训练样本的性能退化模式不能很好地概括产品总体的所有退化模式,当要进行预测的目标样本的退化曲线与训练样本的群体退化曲线差异较大时,有限训练样本的不足就很明显,这会造成传统SVR方法、SbRP方法和SbDA方法在实际应用时很容易受到数据不确定性的影响。相比之下,采用本文方法则更为稳健,其预测结果的MAE最小且远小于其他几种方法对应的MAE,由图6可以看出,采用本文方法得到的预测结果更接近实际值。
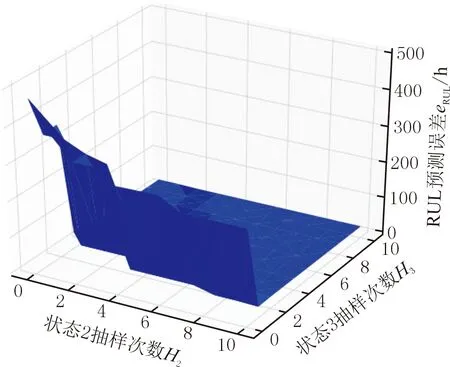
图5 H=10时,样本1采用本文方法的全部测试误差Fig.5 While H=10,all the testing errors of sample 1 by the proposed method
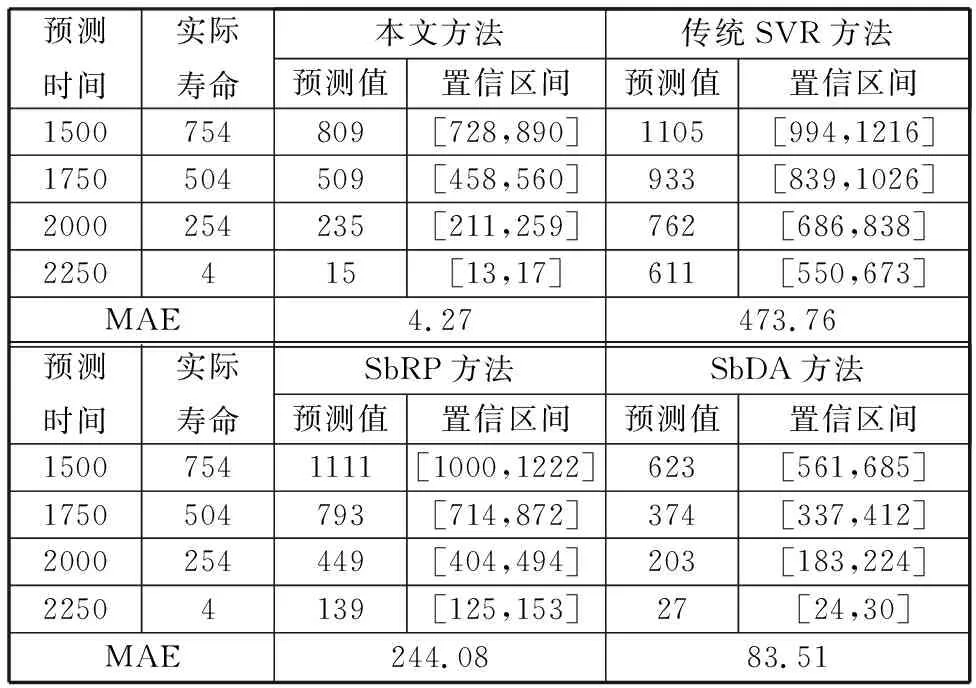
表2 样本1采用几种常用方法的预测结果
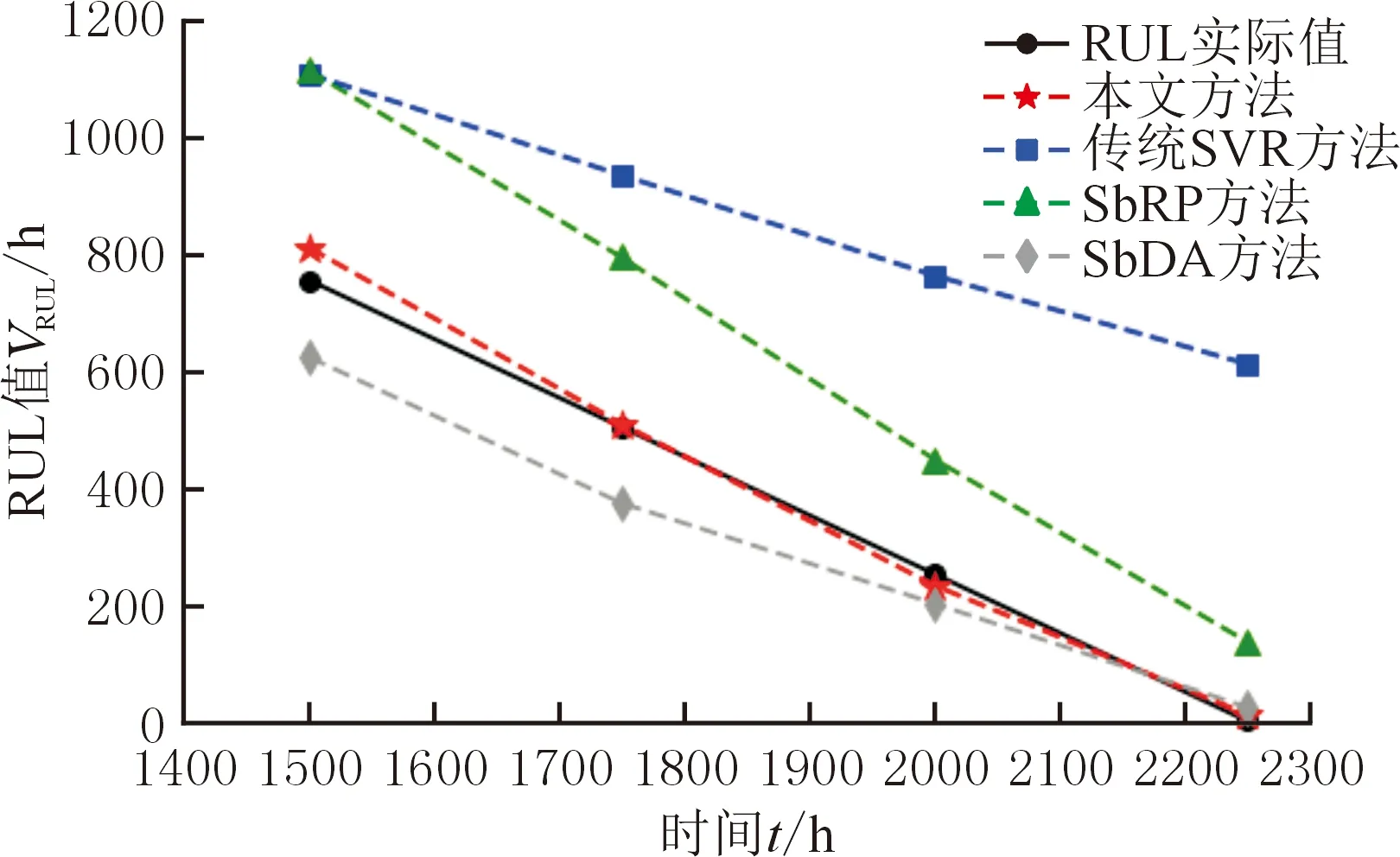
图6 样本1的预测结果Fig.6 Predicted results of sample 1
同样,样本2~5在状态2和状态3下的测试结果见图7。图7a中,样本2与样本1类似,其退化模式与训练样本的群体退化模式差异较大,采用传统SVR方法和SbRP方法得到的预测结果与实际值相差较大,采用SbDA方法得到的预测结果较传统SVR方法和SbRP方法的预测结果相对更准确一些,但这三种方法的预测结果均不如采用本文方法准确。图7b~图7d中,采用传统SVR方法得到的预测结果比采用SbRP方法和SbDA方法准确,更为接近实际值,但不如采用本文方法准确。此外,表3详细列出了所有测试样本采用这几种方法的预测误差,传统SVR方法、SbRP方法和SbDA方法互有优劣,相比之下,本文方法更加准确有效,且更为稳健。

(a) 样本2
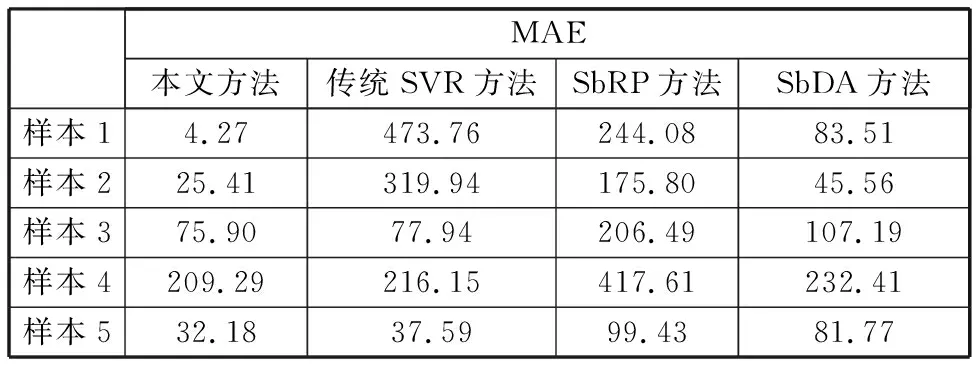
表3 本文方法与几种常用方法的预测误差对比结果
3 结论
本文提出了一种基于整群抽样和支持向量回归(SVR)模型的剩余使用寿命(RUL)预测方法,对测试样本关键预警阶段观测数据进行多次整群抽样后用于SVR模型测试,以寻找对后期数据拟合更好的模型参数,并构建了符合维修决策要求的预测模型。
(1)相比于传统SVR方法在模型参数寻优过程中侧重于使得测试样本的整体误差最小,本文方法在参数寻优过程中更注重对关键预警阶段数据的拟合,可保证所得预测模型在关键预警阶段的输出最优,进而有效地提高了关键预警阶段剩余寿命预测结果的准确性和可靠性。
(2)通过实验发现,本文方法相比传统SVR方法及两种基于相似性的方法具有更好的准确性和可靠性,能有效用于支持激光器的维护决策,也为提高RUL预测方法的性能提供了一条新的技术途径。
(3)相比于重新设计机器学习算法中的函数,通过整群抽样来优化提高模型预测效果更便于在实际故障预测与健康管理中实施,值得进一步研究整群抽样方法在其他数据驱动的RUL预测方法中的应用。
猜你喜欢
军事文摘(2024年4期)2024-03-19 09:40:02
中国卒中杂志(2023年1期)2023-03-12 07:09:24
现代计算机(2022年14期)2022-09-20 02:55:52
科学与社会(2022年1期)2022-04-19 11:38:42
科学(2020年6期)2020-02-06 09:00:06
莫愁(2019年36期)2019-11-13 20:26:16
农村农业农民·B版(2017年2期)2017-03-11 06:59:54
光学精密工程(2016年5期)2016-11-07 09:06:14
工业设计(2016年4期)2016-05-04 04:00:27
营销界(2015年22期)2015-02-28 22:05:18
