
基于图卷积网络的谣言鉴别研究
2021-07-14 16:21唐恒亮
计算机工程与应用 2021年13期
米 源,唐恒亮,2
1.北京物资学院 信息学院,北京101149
2.北京工业大学 多媒体与智能软件技术北京市重点实验室,北京100124
互联网时代,社交媒体成为最大的信息传播渠道。有研究发现,与传统大众媒体不同,社交媒体传播信息速度快、范围广,正成为网络谣言的主要传播渠道。网络谣言是以互联网媒体平台或网页为主要载体,公开或半公开的传播未经证实或缺乏事实依据的信息,混淆视听形成替代性新闻。造谣者借助事件本身的重要性以及网络信息的模糊性,利用富有煽动性的语气蛊惑网民对谣言进行转发,扩大传播面积,将事件推向舆论中心。例如“是中国人就转”“信不信由你”等都是常见扩散网络谣言的煽动性语句。倘若未证实的消息上升为公众话题,很可能混乱社会治安,形成谣言风暴,造成一系列难以预见的连锁反应。
自武汉卫健委通报不明原因肺炎事件开始,新冠肺炎病毒已引起国内外公众的关注,随之而来的是,网络上出现各类不实的信息。从初期的“吸烟可以预防非典,因为烟油可以阻挡病毒进入肺细胞”“吃维生素C泡腾片能预防新型冠状病毒”等传播虚假健康消息、影响疫情防控工作的谣言,到最近的“特朗普新冠病毒测试结果呈阳性”等可能造成社会恐慌的谣言,可以看出,借助网络传播渠道,网络中的谣言对社会生活已造成极坏的影响。
目前网络谣言信息繁杂,国内外网络谣言治理主要是依靠政府网络管理部门监管及一些公司建立的网络辟谣平台。鉴于手工监测网络谣言存在周期性和滞后性,因此对网络谣言实现自动鉴别,具有较为紧迫的现实意义。
1 研究现状
鉴于网络信息庞大,同时社交类本文其字数少、特征分散的特点,有些网络谣言信息很难被技术识别。例如在关键词中插入字符、中英文交替、使用拼音叠字谐音字等,甚至采用隐喻、反语等手法,均可在一定程度上避开句式特征的截取。
研究发现网络谣言存在规律性,常见的谣言样式可见表1。总结分析这些规律对实现网络谣言实时监测和主动预警有重要意义。

表1 常见谣言样式
此外,与真实信息在字面上差别很小的谣言或不包含词库关键词的谣言很难被鉴别。为实现谣言文本特征的精准鉴别,大量的学者主要建立敏感词库和采用机器学习、深度学习、强化学习等技术的网络谣言鉴别方法。
1.1 基于敏感词库与机器学习的传统网络谣言鉴别方法
众多学者从识别谣言的要素入手,构造相关特征实现对网络谣言的自动鉴别。很多研究一般是从敏感事件和热点话题的敏感词库和热点词库入手,类似于关键字提取,采用计算特征词权重的方法,取得了较好的效果。
构建敏感词库主要在于识别敏感词汇信息、提取及扩展敏感词汇[1]。学者们大多通过人工标记或者基于传统权重计算方法[2]去衡量与选择敏感信息,构建的词库多为专业词汇。随后,基于词库去迭代地识别敏感信息。仅仅构建基础词库对网络谣言的鉴别是不够的,需要对其进行不断扩充从而得到较为完备的词库。词库扩展,同样类似于关键字扩展,可通过聚类等相关算法计算词义相似性或语义相似性进行敏感词汇的扩充[3]。刘耕等[4]采用基于广义的jaccard 系数方法来计算词汇间相似性,扩充得到敏感词的相关联词汇。Chen等[5]提取词典中近似敏感词库语义信息的词作为扩展。Yu等[6]主要是通过调用嵌入在Web浏览器中的分析器来获取DOM 结构以及视觉相关信息的VIPS(VIsion-based Page Segmentation)算法进行查询扩展。Pnote等[7]将词频和文档频率按综合频率对词信息进行排序,提出将统计语言模型和信息检索相结合的扩展方法。Pedersen等[8]通过聚类算法实现到语义扩展。Turney等[9]通过计算倾向性基准词与目标词汇间相似度的方法识别词汇语义倾向性。Neviarouskaya等[10]通过同义词和反义词的关系、上下文语义关系、推导关系以及与已知的词汇单位复合来进行词库的扩展。Peng 等[11]利用线性链条件随机场(CRFs)来进行基于字、词、多词等形式的领域集成的中文分词,并通过基于概率的新词检测方法进行新词识别。彭云等[12]从词义理解、句法分析等角度获得词语间语义关系,并将其嵌入到主题模型,提出基于语义关系约束的主题模型SRC-LDA,从而实现主题词的提取。Castillo 等[13]归纳文本特征、用户特征、传播特征和话题特征4个方面的要素以鉴别谣言,并在此基础上总结出15项关键特征并利用决策树算法实现对谣言的检测。Ma 等[14]考虑谣言演变的时间特征,使用动态时间序列模型对谣言进行鉴别。祖坤琳等[15]基于微博的评论消息,将微博评论的情感倾向性加入模型,实现谣言的有效鉴别。李吉等[16]构建基于PAD 模型的网络口碑情感强度测度模型,实时监控网络口碑舆情。王晰巍等[17]构建基于移动环境下网络舆情用户评论情感分析模型,加强移动环境下网络舆情信息监管。
1.2 基于深度学习的主流网络谣言鉴别方法
以上所提到的方法虽然已取得一定效果,但是大多基于手工提取特征,只实现谣言特征的浅层提取,因而无法进一步提升准确率。鉴于深度学习技术可对文本特征进行深层提取,于是基于深度学习的网络谣言鉴别方法成为主流。
Ma等[18]使用RNN及其衍生模型对Tweet谣言事件进行深层特征提取,实现网络谣言的有效鉴别。Chen等[19]在此基础上,引入注意力机制,同样取得较好效果。Zhang等[20]提出借助多层自编码器实现对谣言的无监督学习鉴别方式。Chen等[21]引入层次网络,采用多层RNN模型,进一步提升模型的效果。刘勘等[22]提出一种深度迁移网络,以Multi-BiLSTM 网络为基础,加入MMD 统计量计算的领域分布差异,训练过程中同时学习源领域的标签损失与领域间的分布差异,完成标签信息在领域间的有效迁移。
传统机器学习模型与深度学习模型都通过提取文本信息来实现网络谣言鉴别[23],但都存在一个问题:模型需要借助海量的标注数据来训练得到相关参数。但目前网络谣言的标注大都需要用时较长的官方辟谣来实现人工标注数据,于是本文针对这一问题,提出采用半监督学习的图卷积网络来探寻解决方法。将大量的无标注数据和有限的有标注数据引入图卷积网络,通过聚合节点邻域,不断地训练模型,进一步提升网络谣言鉴别的准确性和稳定性。
2 半监督学习的图卷积网络
图卷积网络GCN 可以看作是常规卷积网络CNN的改编,用于对非结构化数据的本地信息进行编码。本文使用图卷积网络GCN对所有带标注的节点进行基于监督损失函数的训练,并使其能够学习所有节点(有标注或无标注)的表示。在半监督学习中,图卷积网络GCN通过聚合当前有标注节点及节点附近无标记节点的特征来生成当前有标注节点的特征表示。通过计算已知有标注节点的损失函数,反向传播更新所有节点之间的共享权重,以此达到训练模型的目的。
2.1 图卷积网络框架
对于具有k个节点的给定图G=(V,E),其中V是图G的节点集,E是图G中节点间的边集。图G中节点的数量为文档节点的数量与词汇节点的数量之和,即|V|=k。图G中边集E包含两种边,分别是文档节点与其所属词汇节点间的边和词汇间的边。其中,词汇间的边只选取每个词汇与其左侧词汇、右侧词汇间的边,以利用语句中的词序信息。在图卷积运算时,由于每个文档的词汇数量不同,故文档节点附近的邻居节点是不固定的。
本文将单位矩阵I∈Rk×k设置为初始特征矩阵X,其中每个词汇与文档的向量被表示为one-hot形式。为了方便起见,将节点i的第l层的输出表示为其中表示节点i的初始状态。对于一个L层的图卷积网络GCN,l∈[1,2,…,L],是节点i的最终状态。由于图卷积操作仅编码直接邻居的信息,因此一个L层图卷积网络GCN(如图1 所示)其图中的节点只能受到L步内的相邻节点的影响。对图中节点i的图卷积操作可表示为:
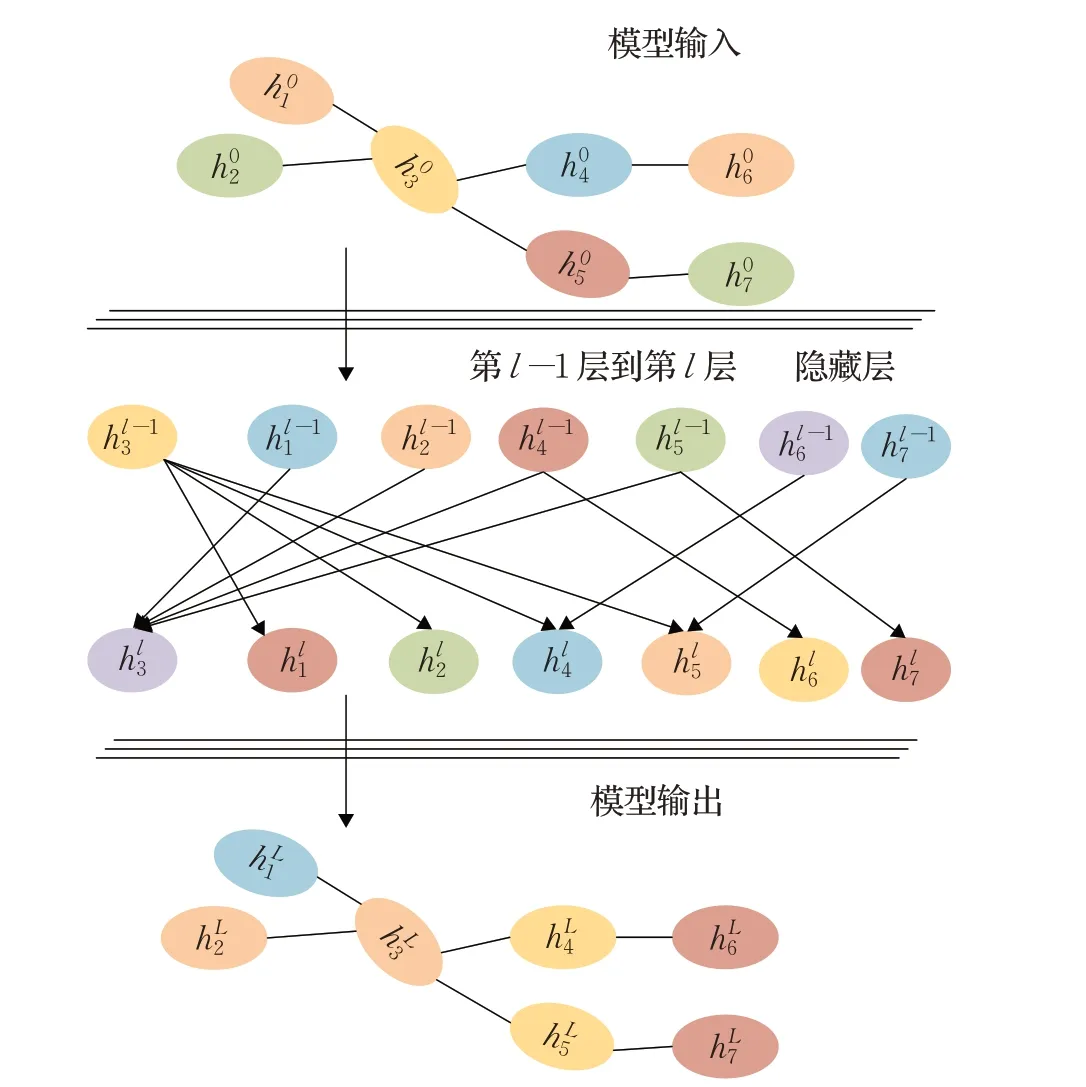
图1 GCN模型

其中,Wl是可训练线性变换权重矩阵,bl是偏置项,A∈Rk×k为图G的带自环邻接矩阵,TFIDFij表示文档节点i中词汇节点j的词频逆文档频率(TF-IDF),D∈Rk×k为图G的度矩阵,σ是非线性激活函数,例如ReLU,可由计算得来。

其中,Wp和bp分别是学习的权重和偏差。
2.2 损失函数
由于图卷积网络的操作基于有标记节点的特征表示,而其特征表示又取决于有标注节点及其附近未标注的邻居节点,故本文模型通过标准梯度下降算法进行训练,使用所有有标注节点上的期望交叉熵作为损失函数:

其中,yi表示真实值,pi表示由公式(5)求出的概率值,M为有标注的节点集合YL的大小。
2.3 模型变种
尽管图卷积网络GCN 通常不考虑方向,但可以将其调整为适合方向感知的情况。因此,本文提出图卷积网络GCN的两个变体,即在无向图上的GCN-UG,以及在有向图上的GCN-DG。实验中,GCN-UG和GCN-DG之间的唯一区别在于它们的邻接矩阵A∈Rk×k。无向图GCN-UG与有向图GCN-DG的邻接矩阵可表示为:

可以发现,有向图模型GCN-DG的邻接矩阵比无向图模型GCN-UG的邻接矩阵稀疏得多,其实验设置的目的是为验证父节点是否会广泛受其子节点影响。
3 实验与结果分析
3.1 数据获取及预处理
本实验所使用的数据存在已经被证实为网络谣言的数据和网络谣言被辟谣后的真实事件,其来源有三:
(1)腾讯新闻疫情平台,收集关于“新冠肺炎病毒”的2020年1月18日至2020年3月15期间483条具有代表性的网络谣言数据。同时,根据收集到的483条谣言信息反查是否存在对应的辟谣信息,将辟谣信息一并整理。
(2)新浪微博虚假消息辟谣官方账号“微博辟谣”账号,收集关于“抗击新冠肺炎第一线”2020年1月1日至2020年3月15日期间该平台公布的758个谣言事件。
(3)新华网承办的中国互联网联合辟谣平台,收集5 000条具有代表性的网络谣言数据。此来源数据去除标注,用于半监督学习。
本文对这些不同渠道得到的数据进行人工筛选、去重、和汇总,最终得到包含5 246条网络谣言的数据集以验证半监督学习的图卷积网络对网络谣言鉴别的提升作用,可见表2。随后,这些数据都经过去噪声、去停用词等预处理过程。其中,去噪声主要是删除了总长度不足2 个字的数据,由于这类数据携带信息较少,处理的意义不大,删除后可提高处理效率。此外,本文的训练集包含2 627条数据,测试集包含2 627条数据。以上数据均被随机选取生成数据集。

表2 已收集疫情网络谣言样例
本文在对收集到的5 246条以文字为传播形式的网络谣言的分析过程中,发现疫情相关网络谣言的传播跟疫情的发展存在一定联系。图2 显示的是新冠肺炎疫情期间的每日新增确诊曲线图,图3显示的是新冠肺炎疫情期间的每日谣言数量曲线图。可以发现,当每日的新冠肺炎确诊人数在增多时,随之而来的是每日谣言的数量在增多。

图2 每日新增确诊曲线图

图3 每日谣言数量曲线图
3.2 实验参数
本文采用一个两层的图卷积网络GCN 进行实验,简化之前第2.1节的图卷积网络模型得到:
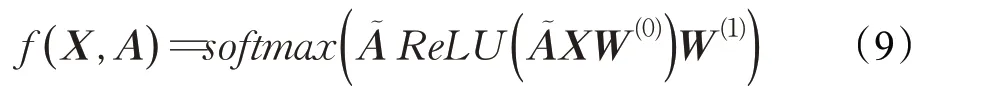
其中,W(0)输入层到隐藏层的权重矩阵,W(1)为隐藏层到输出层的权重矩阵,可通过梯度下降法训练得到。
对于图的邻接矩阵A,本文使用LIL格式稀疏矩阵表示,以降低空间复杂度。模型通过Dropout 引入训练过程中的随机性,Dropout率为0.3,隐藏层为32个单元,最大迭代次数为100次,采用Adam优化算法,训练过程中的学习率为0.001,省略L2 正则化。模型的停止条件为验证集损失函数L连续10个迭代周期没有下降为止。
此外,本文实验环境所用硬件设备:操作系统为Windows 10 家庭版;CPU 为英特尔i5-8300H(四核,2.30 GHz);GPU为Nvidia GTX 1060(6 GB);内存为三星DDR4(16 GB)。
3.3 比较模型
为了全面评估模型的两个变体,即GCN-UG 和GCN-DG,将它们与一系列基线和最新模型进行了比较,如下所示:
(1)SVM(Support Vector Machine)算法是由Cortes和Vapnik[24]提出的一种属于监督学习的二分类模型,学习策略是间隔最大化,常用来对小样本、非线性及高维数据进行模式识别、分类以及回归分析,并可以取得很好的效果。
(2)逻辑回归(Logistic Regression,LR)算法通常是利用已知的自变量来预测一个离散型因变量的值,通过拟合一个逻辑函数来预测一个事件发生的概率值,其输出值在0到1之间。
(3)LSTM(Long Short-Term Memory)最早由Hochreiter 和Schmidhuber[25]于1997 年提出,本文选取LSTM算法的优化算法BiLSTM进行实验。
3.4 评估指标
评估指标用于反映模型效果。在预测问题中,要评估模型的效果,就需要将模型预测结果和真实标注进行比较。由于模型重点在于鉴别网络谣言,故本文要求模型的召回率Recall,即本身是谣言且被正确识别出来的比例尽量大,同时模型要保证其准确率Accuracy要尽量高。本文同时选取准确率Accuracy、精确率Precision、召回率Recall、F-measure 四种指标来评估模型的性能。本文引入混淆矩阵,如表3所示,表中,TP+FN+FP+TN=样本总数。
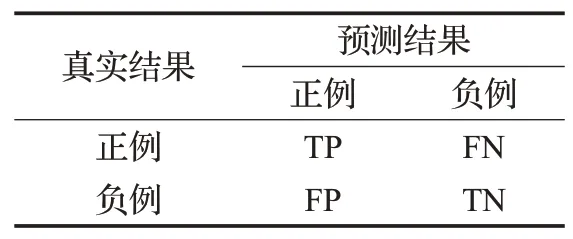
表3 混淆矩阵
(1)准确率Accuracy是指正确分类的百分比。通常准确率越高,分类器越好,其定义如公式(10)所示:
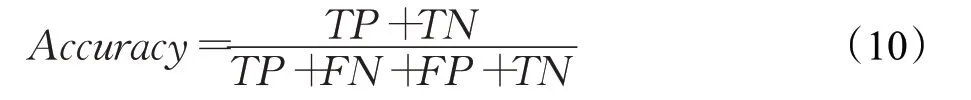
(2)精确率Precision是指预测为正的样本中有多少是真正的正样本,其定义如公式(11)所示:

(3)召回率Recall是指所有准确的条目有多少被检索出来,其定义如公式(12)所示:

(4)F1值是精确率P和召回率R的调和均值,通常F值越大,分类器越好,其定义如公式(13)所示:

3.5 结果对比与分析
本文实验采用以上收集的数据集,通过SVM、LR、BiLSTM 和GCN 四种分类模型分别构建网络谣言分类器,以实现对网络谣言的自动鉴别,其中,SVM、LR模型在实验中采用十折交叉验证。四种模型评估指标的对比结果如表4所示。

表4 实验结果
如图4所示,尽管图卷积网络的用时较长于三种比较模型,但无向图模型GCN-UG 在数据集上的准确率、召回率和F1 值始终高于SVM、LR、BiLSTM 三种比较模型,取得了可观的结果。

图4 实验结果
通过实验可知,采用半监督学习的图卷积网络可提升网络谣言鉴别的准确率、召回率和F1 值,其中GCN-UG 的准确率达到85%,召回率达到86.1%,F1 值达到85.3%。可以看出,图卷积网络在提升网络谣言的鉴别方面达到了预期的效果。同时,结果显示无向图模型GCN-UG的性能要优于有向图模型GCN-DG,原因是有向图相对于无向图,其邻接矩阵丢失了一部分重要的信息。对于基于图的模型来说,来自父节点的信息与来自子节点的信息一样重要。
此外,由于图卷积网络GCN 涉及其层数L,因此本文还研究了GCN 模型层数对模型最终性能的影响。由于上述实验结果显示,GCN-UG 模型的性能最优,故本文选择GCN-UG 模型进行实验。随后,本文假定集合L={1,2,3,4,5,6},并在数据集上检验模型层数对无向图模型GCN-UG 的影响。相关结果如图5 所示。在评价模型的四个指标上,当L为2 时,无向图模型GCN-UG 均达到最佳性能,这证明了在实验中选择层数是合理的,此外,随着L的增加,四个指标都呈现下降趋势,且当L等于6时,由于大量参数,GCN-UG基本上变得更难训练。
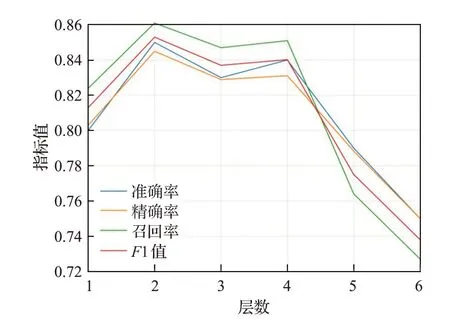
图5 模型层数对模型性能的影响
4 结论
目前网络谣言鉴别领域仍存在很多不足,面对如何更好的鉴别网络谣言这个问题还有漫长的道路。为实现对网络谣言的自动鉴别,本文提出采用基于半监督学习的图卷积网络对网络谣言进行鉴别。通过图卷积网络获取文本完整的特征向量表示,最终送入预测层生成类别预测概率。相较于基于传统机器学习与深度学习的网络谣言鉴别方法,本文所采用方法在召回率、F1值两个评价指标上分别达到86.1%、85.3%,进一步提升网络谣言鉴别的准确性和稳定性,有效利用无标注数据减少标注代价,同时解决监督学习模型泛化能力不强问题和无监督学习模型不稳定的问题。
本文所采用的数据集具有时效性,需依赖官方或者公众平台发布的辟谣信息作为语料标注,虽可通过程序自动获取,但仍耗费一部分的时间和资源,本文后续将对此进一步研究,引入更先进的方法以便更好地解决时效性问题。同时,本文研究发现,文本存在领域性问题,相同的文本在不同领域表现不同,如“癌症”在医学领域属于常见中立倾向,但在一些其他领域属于贬义倾向。现有的网络谣言鉴别方法对此表现不好,鉴别准确率较低。本文未来会在优化算法方面展开深入研究,以进一步提升算法性能。
相较于传统的人工鉴别谣言方法,本文提出的模型拦截社交媒体和网络新闻中的谣言数量可观,为网络谣言的治理提供新思路。同时,本文算法并不仅仅只适用于网络谣言鉴别,也可用于其他文本类分类场景中。
猜你喜欢
环球时报(2022-04-13)2022-04-13
北京航空航天大学学报(2021年9期)2021-11-02
动漫界·幼教365(大班)(2020年7期)2020-06-26
电子制作(2019年11期)2019-07-04
中国盐业(2018年17期)2018-12-23
北京航空航天大学学报(2018年1期)2018-04-20
电脑爱好者(2017年5期)2017-05-04
民间文化论坛(2016年2期)2016-12-01
英语知识(2016年1期)2016-11-11
学生天地(2016年32期)2016-04-16
