
细粒度分层时空特征描述符的微表情识别方法
2021-07-14 16:21张力为王甦菁段先华
计算机工程与应用 2021年13期
张力为,王甦菁,段先华
1.江苏科技大学 计算机学院,江苏 镇江212003
2.中国科学院 心理研究所 行为科学重点实验室,北京100101
脸部表情携带大量的交流信息,甚至比言语和肢体还多。与宏表情不同,微表情还具有运动强度低和持续时间短的特点[1],这使得微表情很难被抑制和隐藏。通过识别分析微表情可以在一定程度上揭示人类内在的意图和心理状态。为了帮助人们理解微表情的特性,Ekman 团队开发了一套微表情训练工具(METT)。接受该训练的人可以识别出7种基础的微表情类别,但是人工识别微表情不但严重依赖专业经验而且准确率不高,只有40%左右。此外,文献[2]的工作表明由微表情引发的运动发生于人脸的肌肉和血管的局部小区域中,而捕捉微小的形变并不容易。因此,到目前为止微表情的识别任务仍然有许多困难要解决,而高准确率的识别算法是很有价值的。
算法在微表情识别任务上的表现很依赖于具有区分性的特征。高质量的特征提取能准确描述微表情的特性,在识别过程中容易被分类。文献[3-4]的工作表明在基于视频形式的微表情识别任务中,结合三个正交平面的局部二元模式(LBP-TOP)在提取视频的时空特征上很有效。之后许多研究者改进了LBP-TOP算法。文献[5]提出了一个新的方法编码LBP-TOP,使用二阶高斯射流的重参数化生成适合不同面部分析任务的可靠直方图特征。文献[6]提出基于六个交叉点的局部二元模式(LBP-SIP),LBP-SIP 方法减少了LBP-TOP 的冗余度和计算复杂度,提供了更轻量化的微表情表征。文献[7]使用图像投影技术构造了一个新的基于局部二元模式的时空特征(STLBP-IP),增强了对缩放图像的鲁棒性。文献[8]在局部时空二进制模式中,将人脸的形状属性合并到时空纹理特征中,提出了基于整体投影的局部时空二进制模式(DiSTLBP-RIP)。文献[9]根据微表情低强度的特性,引入包含微小运动的稀疏信息,改善了LBP-TOP不能很好地提取微小运动的问题。最近一段时间,其他基于光流域的时空特征描述符也被提出,如文献[10]中提出的主方向平均光流(MDMO),文献[11]改进了MDMO 提出的稀疏化的主方向平均光流(sparse MDMO)和文献[12]提出的双加权定向光流(Bi-WOOF)解决了LBP-TOP 对全局变化敏感的问题。实验表明MDMO、sparse MDMO 和Bi-WOOF 在不同的开放微表情数据集上都获得了很好的表现。
值得注意的是在微表情识别任务中,以上提出的基于时空描述符的方法大都应用了脸部区域分割操作以增强时空特征的区分性。具体来说就是将微表情视频中的每一帧划分成n×n的网格块,提取每个块中如LBP-TOP 等类似的时空特征再将它们连接在一起。文献[13]中的工作表明了分割操作的有效性,设计的分层时空特征是1×1、2×2、4×4 和8×8 网格模式下的所有块的时空特征的连接。分层时空特征用于描述微表情而不用考虑对不同数据集用何种分割方式最合适。进一步提出了核化稀疏参数组学习模型(KGSL)用于建立分层时空特征和微表情之间的联系,量化分析了不同网格模式下区域块的贡献程度。
本文在文献[13]的基础上,提出了一种新的细粒度分层时空特征描述符。该算法首先使用核函数将分层时空特征映射到高维向量空间以增加其区分性,然后利用KGSL 模型估计有贡献的区域块。运用统计方法找到具有整体最大贡献度的网格模式,将该网格模式下所有被选中的区域块依次和前一个更稀疏的网格模式下被选择的区域块进行交集运算。在交集不为空的区域和未曾相交但具有巨大贡献的区域提取时空特征。该算法通过区域再选择的方式剔除了冗余的空间区域并且保留了具有高区分度的时空特征。
1 基于分层时空特征的KGSL模型
假设选择M个微表情视频片段作为训练样本,提取它们的分层时空特征将其记作X=[x1,x2,…,xM]∈ℝd×M,其中d是分层时空特征的维度。样本的标签不是由离散的数字表示而是用one-hot 编码,每个标签向量只有一位有效。具体来说,令L=[l1,l2,…,lM]∈ℝc×M为相应的标签矩阵,其中c是微表情类别的个数并且lk=[lk,1,lk,2,…,lk,c]T是一个列向量,其中的每个元素都是二元值0或1。可以根据如下公式求得:

很明显标签向量是一组标准正交基向量,它们可以被扩张成一个包含正确标签信息的向量空间。这里使用一个投影矩阵去桥接特征空间和标签空间。使用如下公式建立二者的联系:

其中U是投影矩阵。使用分块矩阵的技巧,UTX可以被重新写为这里Xi是视频片段的任意分块的时空特征,Ui是Xi对应的子投影矩阵。用代替UTX就可将公式(2)的最优化问题等价为如下形式:

由于不同层次的划分方式对于描述微表情的贡献不尽相同,对各个层次下所有分割块提取的时空特征赋予权重参数βi并且对其施加一个l1范数正则化的操作,还要满足βi为非负数的约束条件。公式(3)被扩展为如下形式:
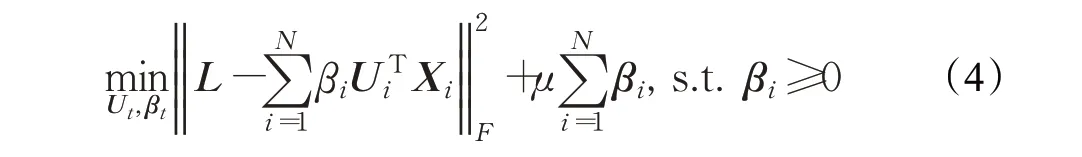
这里μ是一个权衡参数用于平衡权重向量β的维度大小。
接下来基于时空特征非线性可分的特性,应用非线性映射操作ϕ将Xi和Ui映射到核空间F。如下所示:



很明显pj应当是稀疏的,由于微表情发生区域范围很小,只有少数列对应的分割块可以覆盖这些区域。因此,对P施加一个l1 范数正则化的操作。按照这种方式,可以得到如下形式的KGSL模型:

这里λ也是一个权衡参数用于控制P的稀疏程度。
通过交替方向法(ADM)[14]不断迭代更新{β,P}直到其收敛,这样可以解决式(8)中的最优化问题。
2 细粒度分层时空特征
KGSL 模型综合考虑不同密度下的分割块的时空特征的贡献程度。在不同的网格模式下选出的分割块在脸部空间中是有重叠的,低密度方式下选中的分割块往往会覆盖大部分高密度方式下选中的分割块,这样就导致提取得到的时空特征包含冗余信息。基于微表情发生强度低,持续时间短,发生区域面积小的特点,提取的时空纹理特征很容易受到全局晃动等因素的干扰,加入不相关的特征不仅不起作用还会增加任务的学习难度。因此,选中的分割块的冗余部分应当去除。
如图1中的流程所示,本文改进分层时空特征学习算法,对贡献度最大的分割方式下选中的区域块进行再选择,依据相邻密度分割方式下选出区域块的相似性,将贡献度最大的分割方式下的区域快与前一层更加稀疏的分割方式下选出的区域块相交,从交集区域可以提取出更具细粒度的分层时空特征。用衡量分割方式的总贡献程度,其中n是不同密度下分割方式的索引,i是微表情视频片段的索引。假设是具有最大贡献的分割方式,依次将中有贡献的区域块和前一层中有贡献的区域块相交再将重叠部分合并得到细粒度目标区域Ai,如下式所示:

其中Ai就是最有效分割方式下有贡献的区域块与前一层次有贡献的区域块相交部分的并集。基本的区域块都是规则的矩形,不同尺寸的矩形的交集区域也应当是规则的,因此提取交集区域的时空征的过程与提取原始区域的时空特征的过程没有本质的差异。

这里Bi就是中没有交集但是有巨大贡献的区域块的集合。所以,细粒度目标区域由Ai和Bi两个部分组成,将二者取并集操作得到去除冗余部分并且对微表情表征有巨大贡献的区域Qi,如下所示:

其中Qi就是要提取微表情分层时空特征的细粒度区域。图1 的一个例子展示了如何提取细粒度分层时空特征的过程,对于微表情样本Mk按照上述方式选择出细粒度区域后,该区域共由N个不同尺寸的分割块组成。从每个分割块中提取的时空特征记作这里的是列向量。为了整合所有分割块的信息,将每个块提取的特征一个接一个的连接在一起组成一个超特征。这样提出的细粒度分层时空特征可以被表示成这里的T 是转置符号。由于对具有较多贡献区域的再选择,得到了细粒度的区域范围,可以更加精确地覆盖微表情发生的位置。因此,超特征vk充分包含了不同层次下的区域特性并且在此基础上剔除容易造成干扰的区域信息。
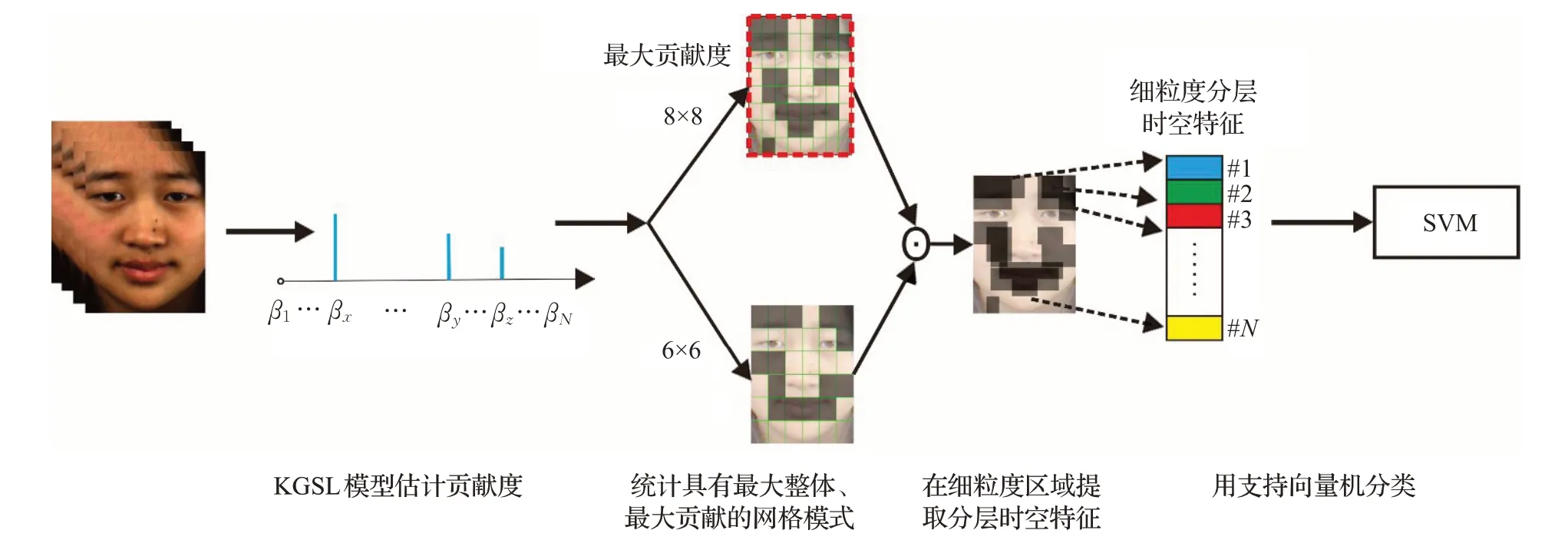
图1 基于细粒度分层时空特征的微表情识别流程
在提取每个微表情样本的细粒度分层时空特征后,训练SVM 并用其做出预测。SVM 是非常流行的二元分类器,应用不同的核函数将特征映射到更高维的向量空间,然后依据特征向量在空间中的分布构建超平面将测试样本分成两个类别。
为了使得不同微表情类别的特征在高维空间中更具区分性,本文选用ChiSquare 核作为映射核函数。文献[15]的工作表明ChiSquare 核比一般的线性核更加合适时空特征的分类。
3 实验结果与分析
为了验证提出的细粒度分层时空特征的有效性,采用CASMEⅡ微表情数据库来评估提出的方法在微表情识别任务上的表现。对数据库中的每一帧图片都裁剪出其脸部区域并变换到统一尺寸308×257像素,利用密度逐渐增加的网格模式进行分割。选择时空描述符中最具有代表性的LBP-TOP算法提取时空特征。依据文献[13]中的工作,设置KGSL 模型中的参数λ和μ为10和0.1。对于LBP-TOP 算法,设置XY、XT和YT这3个平面的领域半径都为3,在其邻域内的像素点个数为8。实验中使用留一人验证法(LOSO)评估提出方法的准确率,即每个人的视频样本都会被作为测试集,剩余的其他人的视频样本作为训练集。由于数据库的不平衡性,会出现一种微表情类别的样本个数过多或过少的情况。因此也用F1 值来评估提出方法的总体表现,依据公式可以计算。其中c是微表情的类别个数,Pi是第i个微表情类别的准确率,Ri是第i个微表情类别的召回率。
3.1 CASMEⅡ微表情数据库
CASMEⅡ微表情数据库是由中国科学院心理研究所在2014年负责发布和维护的。该数据库的建立是在控制良好的实验室环境中进行的,四盏放置在不同方向的灯光提供稳定的光照并且避免了交流电引起的闪烁问题。CASMEⅡ与CASME 等微表情数据库有3 个优势[16]:
(1)被采集者要求在观看视频片段时保持中性的面孔来诱发微表情,这样可以诱发出更多的微表情而不是宏表情。
(2)为了采集到高质量的视频数据,采用帧率为200 frame/s的高速相机进行拍摄,每一帧画面脸部的尺寸为280×340 像素。而CASME 数据库只有60 frame/s的拍摄帧率和100×230 的脸部尺寸。更高的帧率和脸部尺寸有助于捕捉微小的微表情变化。
(3)CASMEⅡ共有247 个微表情样本,其中情绪分类的组成为:快乐(33 个样本)、压抑(27 个样本)、惊讶(25个样本)、厌恶(60个样本)和其他(102个样本)。与CASME相比CASMEⅡ有相对平衡的样本数量的分布,不会出现CASME中个别样本数只有3或更少的情况。
3.2 实验结果分析
本文提出的方法对于网格的分割方式是敏感的,因此评估提出的方法在不同网格的组合下的表现。选择3种类型的网格组合方式,分别为{1×1,2×2,3×3,…,8×8}(TypeⅠ)、{1×1,2×2,4×4,6×6,8×8}(TypeⅡ)和{1×1,4×4,7×7,8×8}(TypeⅢ)。以上3种类型是根据步长为1、2和3递增最大到8进行设置的。
表1 列出了3 种类型的实验结果和在该类型下总共的区域块数量。从表中可以看到与最为稀疏的Type Ⅲ类型相比,提出的方法在步长分别为1 和2 的TypeⅠ类型和TypeⅡ类型下具有更好的表现,表明与较为密集的网格组合相比,过于稀疏的网格组合不能准确地覆盖和微表情相关的脸部区域。同时从表1 中看到步长为2 的TypeⅡ类型具有最高的准确率和F1 值,比最为密集的TypeⅠ类型的表现还要好,表明TypeⅡ类型虽然提取的区域块更多,包含了更多的表征,但是也带来了无用的信息增加了分类的难度。此外,图2的直方图展示了提出的算法在3 种类型的网格组合下的运行时间情况,注意到运行时间和网格组合的步长有关,小步长的的网格组合类型分割密度更大,导致需要提取的子特征数量更多,并且在进行特征连接时会增加超特征的维度,从而更加耗时。对比所有类型的耗时情况可以发现本文算法在TypeⅡ类型下的效率最高。综合以上分析,在算法运行高效的同时,避免过小的区域块丢失有效信息和过大的区域块引入无效信息的情况,选择TypeⅡ类型的网格组合进行实验。

表1 不同类型的网格组合方式在微表情识别任务的表现

图2 3种类型的网格组合的运行时间对比
为了验证提出的方法在微表情识别任务上的优越性,先将其和单一固定的分割方式比较,分别选择2×2、4×4、6×6和8×8这4种网格模式,应用LBP-TOP提取微表情时空特征之后用ChiSquare核的SVM进行分类。此外,也和文献[13]中提出的基于分层时空特征的SVM分类方法和基于分层时空特征的KGSL方法进行了对比。
表2 列出了各类基于分层时空特征方法在微表情识别上的性能比较结果。对于单一的分割方式,随着网格密度的增加,识别率也在增加。从2×2网格到4×4网格分割方式识别率有一个快速的增长,准确率和F1 值提高了3.42%和0.061 4。之后6×6和8×8的网格分割方式对识别率和F1 值有进一步的上升,提高了1.06%和0.003 4,但是提升幅度减小。说明随着分割密度的提高,提取出的微表情的细粒度信息也越多并且逐渐区域饱和。基于分层LBP-TOP 特征的SVM 分类算法提取所有网格密度下区域块的时空特征,但识别率反而有所下降。说明提取的特征中包含太多的冗余信息,多余的维度稀疏了属于同一类别的特征在向量空间中的分布,干扰了分类器对微表情表征的学习。基于分层LBP-TOP特征的KGSL 算法相较于前几种算法在识别结果上有很大的提升,准确率和F1 值提高了3.84%和0.034 7。主要是因为KGSL 模型利用投影矩阵去桥接LBP-TOP特征和微表情的标签,对区域块的贡献度程度进行估计。部分冗余的区域会被认为有低贡献度,从而在一定程度上减弱了冗余区域的影响。从表1 观察到本文提出的方法比上述性能最高的算法的识别率提高了2.15%,F1值提高了0.015 9。表明在最大贡献的区域块上进行再选择的操作是有效的。从中提取的细粒度分层时空特征进一步剔除了冗余信息。由于大部分提取的区域都属于具有整体最大贡献的网格模式,与分层时空特征相比降低了特征的维度,所属同一类的微表情特征更加紧凑,从而在高维空间中更具区分性。
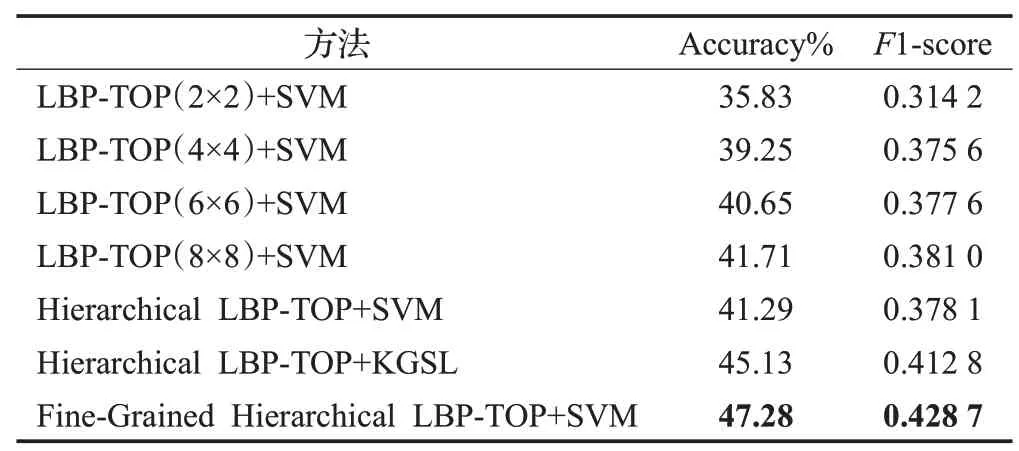
表2 基于分层时空特征的方法在微表情识别任务的表现
此外,图2 的耗时对比结果表明,本文提出的算法的耗时在不同类型的网格组合下的耗时都低于基于LBP-TOP的分层KGSL方法,这是因为再选择的操作筛掉了大量的区域块,大幅减少了特征提取的计算次数。另一个方面是因为交集的操作细粒度化了微表情发生区域,由于提取基于纹理信息的时空特征是提取XY、XT和YT这3 个平面的区域信息再加以融合得到的,细粒度化的区域减少了XY平面的提取区域进而降低了算法的复杂度。
为了进一步展现本文提出方法的优越性,将本文提出的方法和文献[17-20]提出的微表情识别方法比较(见表3)。这些方法的实验结果都是经过各自不同的预处理并且选用最佳参数得出的。其中文献[17]基于LBP-TOP时空特征描述符,一方面使用面部配准、裁剪和时序插值增加类内的不相似性,另一方面训练个性化的AdaBoost 分类器改善样本不平衡的问题。取得了43.78%的准确率和0.333 7 的F1 值,明显低于本文的47.28%和0.428 7,这是由于插值技术在均衡样本的同时也掩盖了部分的微表情表征,额外的帧可能会引入多余的细微运动。

表3 本文方法和主流微表情识别方法的比较实验结果
文献[18]基于Riesz Wavelet时空特征描述符,从多个尺度下提取幅值、相位和方向3 个低级的特征,在分类阶段将每个尺度下提取的3 个分量都视为独立的特征以避免信息的损失。取得了46.15%的准确率和0.430 7的F1值,低于本文的47.28%,略高于0.428 7,表明综合所有尺度下的表征信息有助于分类表现,但是将所有层次的特征不加以选择而当作独立的信息使用难以使性能进一步提升。
文献[19]基于LBP-MOP 时空特征描述符,使用差值图像的整体投影方法获得水平和垂直投影以保留面部的形状属性,再利用局部二元模式提取外观和运动在水平和垂直方向的特征。取得了45.75%的准确率,低于本文的47.28%。表明加入的面部形状属性并不能完全消除个体差异,面部区域的选择更为重要。
文献[20]基于FDM时空特征描述符,使用光流算法估计连续帧之间的运动,将小规模的区域在光流场上对齐并且从中提取主方向信息。取得了41.96%的准确率和0.297 2的F1值,远低于本文的47.28%和0.428 7。这是由于光流算法对光照的要求严格并且在用优化方法对齐的过程中会扭曲部分细微的脸部运动,所以表现并不理想。
注意到本文提出的方法比文献[17]方法的准确率和F1 值提高3.5%和0.059;比文献[18]的准确率高1.13%,F1 值低0.002;比文献[19]方法的准确率提高1.53%;比文献[20]的准确率和F1 值提高5.32%和0.130 6。总体上,提出的微表情识别方法有更好的性能并且对样本的不平衡性的表现更好。
从视觉效果方面分析,如图3所示右侧是根据脸部动作编码系统(FACS)设计的区域,这些区域是多个脸部动作单元(AU)的组合。具体来说,眉毛附近的AU1和AU4主要是额叶肌和眉间降肌的肌肉运动形成的微表情动作。脸颊上的AU6和AU9是眼轮匝肌和上脸提肌的肌肉运动形成的微表情动作。嘴角周围的AU10和AU12 等是唇方肌的肌肉运动形成的微表情动作。图3 左侧的灰度值较小的深色阴影部分是再选择的细粒度区域,而灰度值较大的浅色阴影部分是交集为空的区域。观察到选择的区域与根据FACS 理论划分的区域基本是重合的,对微表情有贡献的区域块都落在AU相关的区域,表明提取的特征反应了AU相关区域的肌肉运动情况。图4展示了区域选择的对比效果,给出四个不同微表情类别样本的例子。可以看到选中的嘴部区域和之前的区域相比更加的精准,保留了嘴部主体区域并且细化了轮廓形状。在眉毛区域,选中的部分和之前区域相比,剔除了头发遮挡的部分,使得再选择的区域更适合提取微表情表征。

图3 选中的细粒度区域和手动划分AU区域的关联

图4 区域再选择的效果对比
4 结论
本文提出一种新的细粒度分层时空特征的微表情识别方法,首先选择对微表情识别任务有巨大贡献的区域,然后对这些区域进行再选择得到更加细粒度化的区域,从中提取出的时空特征充分融合了微表情发生区域的信息并且更加有区分性,在微表情识别任务中展现了其优越性,促进了测谎和犯罪审讯等公共安全领域的应用。然而提出的方法并未对选择的细粒度区域和AU相关区域两者之间的联系做出量化性的评估。今后的工作中,将进一步研究两者关联性的理论依据以此来选择最优的关联区域。
猜你喜欢
红外技术(2022年11期)2022-11-25
四川党的建设(2022年8期)2022-04-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
高技术通讯(2021年1期)2021-03-29
农业科技与信息(2021年2期)2021-03-27
小学生学习指导(低年级)(2020年11期)2020-12-14
安阳工学院学报(2020年2期)2020-06-05
作文大王·低年级(2018年10期)2018-12-06
中国交通信息化(2018年5期)2018-08-21
