
一种柔性策略的图书信息自动采集研究
2021-07-14 07:07党小琴
机械设计与制造工程 2021年6期
党小琴
(陕西学前师范学院,陕西 西安 710100)
信息化时代中,海量的数据充斥着人们的生活,在信息大爆炸时代背景下如何合理地获取知识是值得探讨和需要解决的问题[1]。以图书信息为例,传统的知识信息获取方式在效率和精准度上已经无法满足人们快节奏的要求,如何在短时间内获取图书信息是亟需解决的问题,这样可以有效缩短搜索时间,提高借阅体验感[2-3]。
近年来,关于图书馆信息技术方面的研究成果虽然较多,但是大多数研究成果集中于图书管理系统的改良和图书信息的收录,少部分研究成果会涉及到图书信息的采集与过滤,相关研究不够深入[4-6]。目前来看,图书信息管理方面的研究存在如下问题[7-9]:1)图书信息不够精确,较为粗糙的算法无法打磨出精准的信息展示平台,导致用户黏性较低;2)启动方式不智能,目前主流的信息启动方式为冷启动,分为物品冷启动和用户冷启动,刚接触系统的用户由于在系统中没有留下任何浏览记录,系统无法计算出用户是否对某一门类书籍感兴趣;3)图书信息的多样性欠缺,现有的图书管理信息系统主要对与用户感兴趣图书的类似文献进行集中推荐,缺乏扩展,用户易产生查阅疲劳,对于用户来说,单一推荐他们感兴趣的书籍无法对搜索结果进行解释,也无法达到最佳的用户体验。
本文提出了一种基于柔性策略的用户信息优化图书推荐方法,将其用于图书信息的自动采集和优化筛选,该方法能够提高信息采集的速率和信息推进的精准度。
1 柔性策略优先级算法
1.1 常用算法简介
目前,关于优先级推荐算法的研究成果虽然很多,但是应用于图书信息推荐的较少,较为常见的算法主要有以下3种[10]。
1)内容推荐算法。
内容推荐算法是一种最为常用的图书信息个性化推荐方法,该算法基于用户历史搜索数据,将其搜索较多的一类图书分类后给予推荐,主要推荐的是用户偏好模型中的相似书籍,在评估过程中用户兴趣信息和图书信息呈现相似性关联关系。其流程如图1所示。
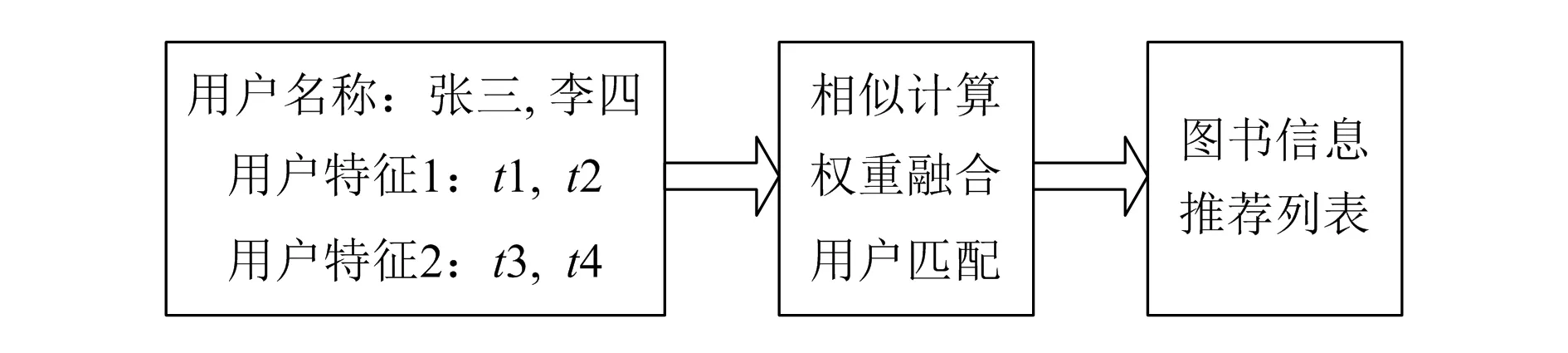
图1 内容推荐算法流程
2)邻域推荐算法。
邻域推荐算法主要是将当前用户搜索过程中发现的与其搜索内容相似的邻近用户的搜索内容筛选出来进行匹配和评分,将得分最高的信息推荐给用户。该算法计算思路如下:首先输入k个邻近参数(用于指代图书信息关键词),然后将用户搜索数据拆分为训练集和测试集,在分拆过程中数据进行相似性排序形成新用户矩阵,当矩阵排列完成后对k个邻近用户分别进行相似度匹配,最终根据不同匹配分数获取推荐物品信息。
3)混合推荐算法。
由于不同的个性化信息推送算法各有优劣,因此在工业实践中往往将不同算法进行组合形成新的混合推荐算法,这类算法能够取长补短,提高数据推送的准确性。目前主流的混合推荐算法有整体融合、并行融合和线性融合3种,其中线性融合算法是较为流行的算法,该算法利用协同过滤技术将一定数量的信息进行排序和分类,然后将结果导入混合模型通过分析得出推荐内容。
1.2 柔性策略混合算法
常用的算法虽然有一定适用性,但是在运行效率和个性化程度上依然存在一些短板,因此本文提出了柔性策略混合算法。该算法将不同类型的图书信息划分到不同的象限进行归纳,计算出不同优先级,采集过程中利用柔性采集方案避免发生信息相互干扰,然后利用双重量化判定降低数据波动程度,以此形成一个良性的信息推荐及调整方案。
在建立图书信息的过程中,本文利用模糊综合评价法进行量化处理,从而划分出不同的象限组合进行判断。
1)构建判定因子U子集:U={u1,u2},其中u1为判别信息的重要性,u2为判别信息的效率;
2)构建图书信息因子的权重集合A:A={a1,a2,…},权重值在对因素进行审慎分析后得出;
3)构建判定集V,V={v1,v2,…},以专业技术人员的研究结果为指导,获得图书信息的判定矩阵R。
(1)
模糊综合判断法的判别公式如下:
(2)
式中:B为模糊综合判别值;aj为标准信息文本数量集;rjk为判定子集中的向量;k为某一阈值参数。
由式(2)可获得采用象限优先级的判别结果。另外,当临近数据发生变化时,采集方案也应该变化,由于临时变化导致的数据采集间隔发生了无序变动会产生误差,因此本文采用双重误差判别,判别公式如下:
第一次判别
(3)
第二次判别
(4)
式中:f0为原始判别平均值;f1为第一次判别结果;f2为第二次判别结果;i为某一个数据采集点;fi为判别中间结果。
1.3 算法评价指标
信息推荐算法是否合格并满足用户需求,需要用评分准确率、推荐准确率和覆盖率3个指标去评价:第一,评分准确率,可以先建立用户偏好模型,然后采用均方根误差算法对用户对陌生领域的书籍的兴趣爱好进行评估;第二,推荐准确率,通过召回率和准确率两者来衡量,例如给用户推荐了n本书籍,以其占用户喜欢的图书集的比例作为准确率;第三,覆盖率,主要用于评价算法对潜在图书数据的挖掘能力,是否可以帮用户找出那些不够流行但又比较感兴趣的信息。
2 图书信息自动采集与过滤
以某网站图书信息推荐版块的数据作为源数据,该网可以获取用户对不同图书的评分、评价和爱好程度,还可以获取图书的基本信息如目录、出版日期、出版单位和评论人数等。在浏览图书的过程中,界面会给用户提供一个“最受关注图书”版块,目的是给用户推荐其感兴趣的书籍,但是研究后发现针对不同用户所推荐的图书目录基本一致,如图2所示。

图2 图书推荐界面
从网站推荐结果来看,网站所采取的算法个性化程度较低,无法满足信息个性化需求,对于用户偏好的解析较慢。本文采用柔性策略算法的目的便是改良这一信息推荐算法,具体的算法流程如图3所示。

图3 柔性策略信息采集算法流程
首先依据模糊综合评价来实现图书信息建模和图书内容向量化;然后将用户感兴趣的图书进行整合,建立用户偏好模型;最后采用二次校正判别方法对偏好模型和图书内容模型进行匹配,从而获得用户最感兴趣的图书信息。具体算法步骤如下:
1)图书信息采集和建模。
首先,将图书信息按照图书编号、书名、作者、关键词等信息进行归纳整理,见表1;然后将图书划分为不同的象限之后,对书籍的关键信息权重大小进行自动分类。本文使用的建模软件为MATLAB,该软件中的model模块能够对信息输入文本进行向量化表达,从而获得最合理的向量值。

表1 图书关键信息分类表
2)用户借阅偏好建模。
基于评分法(5分为满分),若一本图书用户评分为3分,表示该图书比较受读者青睐,是用户比较偏爱的图书,然后收集和统计该图书的关键信息,提取用户较为重视的关键词,调用Doc2vec算法再次对其进行训练,得到用户与图书之间的相识度平均值。
3)相识度预测。
本文利用Person算法计算用户偏好与图书信息之间的关联度,Person算法中,用户对某一个图书信息的喜好程度可以量化为[-1,1],若预测分数为正值代表用户偏好这本图书,若为负值代表用户对该图书不感兴趣,预测评分公式为:
(5)
式中:f(·)为用户u对某图书s的感兴趣程度评分;r为用户和图书之间的相识度;M为达标关键词。
4)二次矩阵判断。
经过上述步骤获得了采用象限优先级的判别结果,基于这个结果再以用户点击频率高为原则,依据图书信息采集量和运行状态数进行二次判别,判别过程中剔除无序变动和临时变化所产生的图书信息,最后根据预测分值排序得到用户最感兴趣的图书集。
3 实证分析评价
为验证该柔性策略的图书信息推荐准确率,以某网站所收集的读书评分数据为原始依据,采集用户评分共计3万条(其中评论数据2.5万条,图书数据0.5万条),截止时间为2020年10月18日。由于部分用户阅读量太小导致评价结果不够合理,算法训练容易受到干扰,因此本文选取图书借阅数量在100本以上的用户评分作为有效评分。
3.1 评分准确率对比
以评分准确率作为本文算法优劣的评价指标之一。采用评分准确率的RMSE均方根误差来进行评判,RMSE值越高,误差越大,RMSE值越低,则误差越小。评价过程中考虑数据量过于庞大,选取针对性的10次随机验证过程,每次验证抽取10名用户进行反馈和推荐图书,其RMSE值如图4所示。

图4 评分准确率RMSE均方根误差对比结果
从图4可以看出,采用柔性策略的Doc2vec算法其RMSE值为0.2~1.0,而一般算法的RMSE值最大接近2.5,最小为0.4,由此可以看出柔性策略算法的预测误差值更小。另外发现,一般算法的预测误差值离散度较大,其推荐给用户感兴趣的图书稳定性差,说明后者对于图书信息的把握更稳定和准确。
3.2 推荐准确率评价
为对比不同算法的推荐准确率,采用召回率和准确率作为评价指标,内容推荐算法、邻域推荐算法和柔性策略混合Doc2vec算法的测试结果对比如图5和图6所示。
从图5可以看出,内容推荐算法与邻域推荐算法的召回率基本相近,均值在10%左右,柔性策略算法的召回率明显高于前两者,为19%~20%。从图6可以看出,基于内容推荐算法的准确率最低,约为0.07%;基于邻域推荐算法的准确率为0.08%~0.09%,而柔性策略算法的准确率为0.14%~0.16%。整体上来说,采用柔性策略的混合算法大幅度提高了图书信息采集效率和推荐准确率。

图5 召回率对比曲线

图6 准确率对比曲线
4 结束语
为解决传统的图书信息采集和推荐算法在速率和推荐精度上低效的问题,本文提出了基于柔性策略的混合(Doc2vec)算法,设计了图书信息采集和优化过滤方案,并以某网站图书数据为例进行了实证研究对比,结果发现该方法能够大幅度提高图书信息采集的效率和推荐准确率,具有一定的实用价值和推广意义。
猜你喜欢
机械工业标准化与质量(2022年9期)2022-09-30
石油沥青(2021年5期)2021-12-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
文化创新比较研究(2020年7期)2021-01-13
含能材料(2021年1期)2021-01-10
中国交通信息化(2018年5期)2018-08-21
工业设计(2016年8期)2016-04-16
老同志之友(2009年9期)2009-06-29
