
基于BP神经网络和遗传算法优化S Zorb装置汽油辛烷值损失
2021-07-14 07:23:14欧阳福生赵明洋
石油炼制与化工 2021年7期
高 萍,刘 松,程 顺,欧阳福生,赵明洋
(1.华东理工大学化工学院石油加工研究所,上海 200237;2.中国石化上海高桥分公司)
重油催化裂化(RFCC)工艺不仅可以将重油转化成汽油、柴油等轻质燃料,还能同时生产低碳烯烃,是炼油化工一体化的核心工艺之一[1-2]。我国催化裂化装置生产的汽油约占成品汽油的70%左右[3],并且成品汽油中的硫主要来自RFCC汽油[4]。随着环保要求的日益严格,汽油的深度脱硫在世界范围内引起了广泛重视。我国汽油质量升级较快,国Ⅴ汽油标准中硫质量分数要求不大于10 μg/g[5]。吸附脱硫(S Zorb)技术是针对FCC汽油深度脱硫的最有效工艺之一。与传统的加氢脱硫技术相比,它不仅能在辛烷值损失较低的情况下生产硫质量分数低于10 μg/g的汽油,还能降低操作成本和能耗。到目前为止,国内共有38套S Zorb装置投产[5]。但在实际运行过程中,某炼油厂S Zorb装置的精制汽油辛烷值损失长期在1以上,严重影响了企业的经济效益。
鉴于RFCC工艺在石油加工中的重要地位,对该工艺过程的建模优化一直是该领域的研究重点。自20世纪60年代起,国内外就通过机理建模来指导优化RFCC的操作。但由于催化裂化各操作变量之间具有高度非线性和强耦联性,机理模型的精度和时效性受到很大挑战[6-7]。
人工神经网络(Artificial Neural Network,ANN)是一个非线性动态系统,具有良好的自学习、自组织、自适应和非线性映射能力,不用依赖模型来实现多项控制。因此,人工神经网络在工业中有广泛的应用,尤其是在化工领域[8-10]。其中,BP神经网络模型是目前应用最广泛的模型之一。本研究以S Zorb工业装置的大量实时数据为基础,通过建立BP神经网络模型并结合遗传算法(Genetic Algorithm,GA)优化S Zorb装置操作条件,使精制汽油辛烷值损失降低30%以上。
1 数据收集
以国内某石化企业1.2 Mt/a S Zorb装置为研究对象,采集了2017年4月至2019年10月时间段,包括LIMS系统(Laboratory Information Management System)和DCS系统(Digital Control System)的数据。LIMS系统包括了原料油研究法辛烷值(RON)、硫含量、饱和烃含量、烯烃含量、芳烃含量、溴值、密度,吸附剂的硫含量、碳含量,产品RON和硫含量等13个性质数据;从DCS系统中采集了包括氢油体积比、反应器底部温度、反应器顶部压力、原料进装置流量、再生风流量、再生器温度、反应器质量空速等在内的355个操作变量数据。对本研究而言,最重要的产品性质为其RON,在LIMS系统该数据采集频次为2次/周;DCS系统各操作变量的采集频次为每3 min 1次。将采集到的DCS数据以LIMS系统RON测定时间点为中间点,取前2 h数据的平均值作为对应的操作变量数据,共得到265个样本,如表1所示,其对应的原料、吸附剂和产品性质分布数据如表2所示。

表1 来自DCS系统中的操作变量数据(部分)

表2 LIMS系统中的原料、吸附剂及产品性质分布数据
2 建模变量的筛选
为了尽可能降低神经网络建模变量的维数,以满足后续优化的实施要求,必须保证输入变量之间不相关或弱相关,而与目标值之间强相关。采用灰色关联分析[11-12]作为变量相关性检验方法,其相关系数r与变量间的相关关系见表3。

表3 相关系数r与变量间的相关关系
在S Zorb装置的有关物性变量中,原料RON是重要的建模变量,产品RON是目标变量,对于LIMS系统中其他11个物性变量和355个操作变量,其与目标变量之间的相关性分析结果如表4和表5。

表4 物性变量与产品RON相关性分析结果

表5 与产品RON相关性在0.7以上的操作变量
由表4可知,待生吸附剂硫含量、再生吸附剂硫含量、原料硫含量、原料芳烃含量和产品硫含量5个变量与产品RON的r在0.7以上,说明它们与产品RON之间高度相关,因而应该保留。表5列出的是r在0.7以上的130个操作变量。对于建模来说,变量数仍旧太多,若采用灰色相关度计算这些变量间的相关性会十分复杂。因此,本研究利用SPSS(Statistical Product and Service Solutions)软件对操作变量之间进行相关性分析,结果如表6所示。
以表6中还原器流化氢气流量(2)、反应过滤器压差(7)和反吹氢气压力(8)为例,其两两之间的r分别为0.902,0.782,0.891,均大于0.7,因此可选择其一作为建模变量。考虑到在实际生产中还原器流化氢气流量容易控制与调节,最后选定其作为建模变量。

表6 操作变量之间的相关性分析结果(部分)
从以上分析可知,采集的装置数据质量较好,变量间的相关性结果可靠,符合实际生产情况。因此,以变量间的相关性结果作为筛选依据是合理可靠的。此外,参考装置相关技术人员的意见,在相关度较高的两个或多个变量中,应选定易于控制与调节的变量。最终选定建模操作变量15个,加上筛选出的原料、产品和吸附剂性质中的5个变量以及原料RON和产品RON,建模变量最终选定22个,其中输入变量21个,目标变量(产品RON)1个,如表7所示。
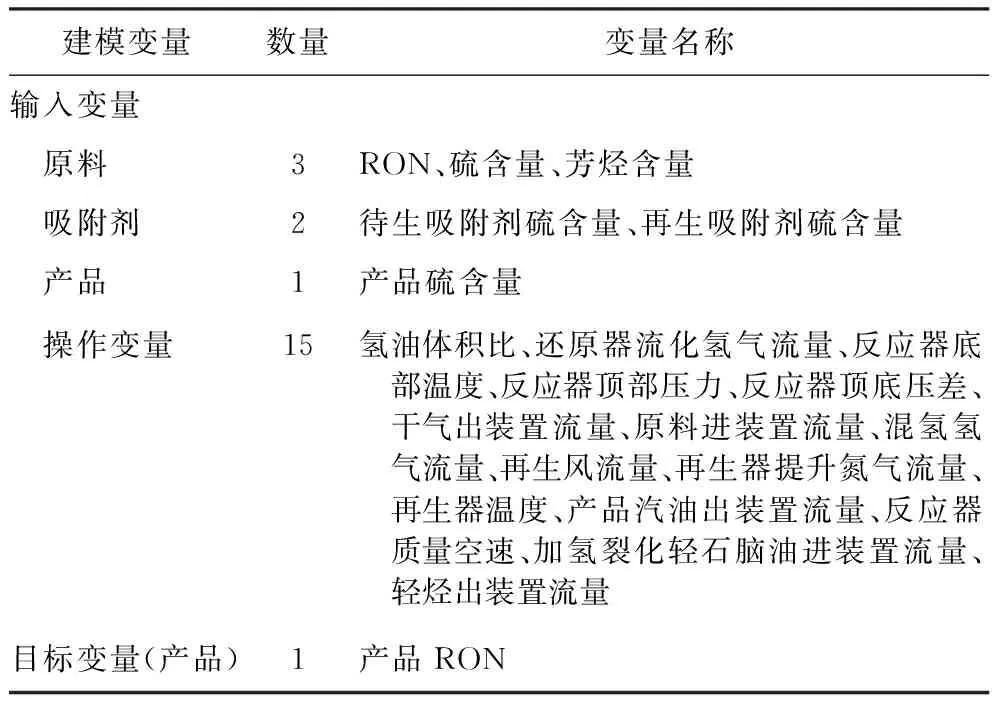
表7 建模变量筛选结果
3 原料油的聚类分析
聚类分析是根据研究对象或对象的指标进行分类的数据分析方法。它将群集中具有相似属性的对象划分为同一子集,使得同一子集中的对象具有高度的相似性,而子集之间的对象彼此不相似。模糊C均值(FCM)算法是应用最广泛的聚类算法[13-15]之一。本研究针对265组样本中原料油性质(饱和烃含量、烯烃含量、芳烃含量、硫含量、密度和溴值)数据,采用FCM算法对S Zorb装置的原料油进行分类,以期为后续针对不同种类的原料油分别建立产品RON预测模型、寻找最佳操作条件来降低产品RON损失打下基础。
使用FCM算法的关键是确定最佳分类组数copt。为此,先确定最佳分类组数的上下限,令最小分类组数cmin=2,根据经验式(1)求得最大分类组数cmax=16。
(1)
式中,N为样本数目。
本研究利用Matlab编程平台,并采用吴成茂等[16]提出的归一化划分系数来确定copt,其结果如图1所示。

图1 归一化划分系数随分类组数的变化曲线
由图1可见:当分类组数为3和5时,归一化划分系数明显更大。本研究样本组数为265,若将其分成5类,每一类的平均样本数较小,会使得后续的建模结果准确性下降,因此选择copt为3。再分别计算出每一类原料油的聚类中心的原料性质及原料油样本的分配,结果见表8。
由表8可见,聚类中心相互之间区分度较大的原料性质是硫含量、饱和烃含量、烯烃含量,因此选取此三者的高低来度量不同类别原料油性质的差异。第1类原料油命名为低硫低烯烃高饱和烃原料油,第2类原料油命名为高硫高饱和烃高烯烃原料油,第3类原料油可命名为低硫低饱和烃高烯烃原料油。此外,3类原料油的样本分布数均不小于80。

表8 最佳分类组数时的每类原料油的样本数及其聚类中心值
4 预测RON的BP神经网络模型的建立
BP神经网络一般是包含输入层、隐含层和输出层的3层前馈神经网络,每一层由若干神经元组成,信号传递到每个神经元时,会通过固定形式的激励函数关系变换形成新的输出信号传递给下一层神经元。BP 神经网络中应用最广泛的激励函数是S函数和线性函数,S函数表达如式(2)所示。
(2)
S函数一般用于隐含层神经元的激励函数,它能将神经元的输入范围从(-∞,+∞)映射到(-1,+1)。线性函数表达如式(3)所示。
f(x)=x
(3)
线性函数一般用于输出层神经元的激励函数,它能处理和逼近输入变量与输出变量的非线性关系[17]。
4.1 BP神经网络模型结构
采用基于FCM 算法的3类原料油的数据样本和已筛选出的22个建模变量来建立预测产品RON的BP神经网络模型。在利用Matlab编程平台建立S Zorb装置产品RON预测模型的过程中,随机产生固定组数的样本数据用于训练预测模型,剩余的样本用于验证预测模型,具体的样本数分配见表9。

表9 训练样本和验证样本分配
建立神经网络的关键是确定隐含层神经元的个数。因为隐含层神经元个数对BP神经网络预测精度有较大的影响:神经元个数过多,运算时间过长,样本易出现过拟合;神经元个数太少,网络不能很好地学习,需要增加训练次数。隐含层神经元个数计算如式(4)所示。
(4)
式中:H为隐含层神经元个数;m为输入层神经元个数;n为输出层神经元个数;L为1~10区间内的一个可调常数。
由式(4)得到隐含层神经元的个数为6~15,但由于BP神经网络中包含大量并行分布结构和非线性动态特性,实际计算中,在按式(4)所得的神经元个数范围内往往很难达到理想效果。为寻找最优的网络结构,本研究将隐含层神经元个数从6依次增加到25,分别建立产品RON的BP神经网络预测模型。将所选择的训练数据导入神经网络模型进行训练,并比较每次的均方误差(MSE),出现MSE值最小的神经元数即为最佳隐含层神经元个数,结果见图2。由图2可知:第1~第3类原料精制产品的RON预测模型的最佳隐含层神经元个数分别为20,18,17。由此可得,第1~第3类原料的精制产品产品RON预测模型三层网络结构分别是21-20-1,21-18-1,21-17-1。

图2 隐含层神经元个数与MSE的关系■—第1类原料; ●—第2类原料; ▲—第3类原料
4.2 BP神经网络模型预测结果
采用上述BP训练模型分别对3类原料的16,20,16组验证样本的产品RON进行预测计算,训练样本及验证样本预测值与实际值的比较如图3所示。结果表明,第1~第3类原料的验证样本的产品RON实际值和预测值的最大相对误差分别为0.42%,0.75%,0.48%,平均相对误差均小于0.15%,且与训练样本的相对误差相差不大,说明分别针对3类原料建立的产品RON预测模型的预测效果好。

图3 3类原料的RON预测模型的预测效果■—真实值; *—预测值
5 产品汽油的RON优化
在采用BP 神经网络建立的S Zorb 装置产品RON预测模型的基础上,利用GA算法[18]来优化操作条件,以达到降低RON损失的目的。在对产品RON优化的同时,还需要保证产品的脱硫效果。分析产品硫含量的历史数据,发现其平均值为4.75 μg/g,而国Ⅵ汽油标准对硫含量要求质量分数不大于10 μg/g。为了给装置对产品硫含量的控制留有余地,调优时产品硫质量分数控制在0~5 μg/g。在此过程时,设置种群中的初始种群为20、最大迭代次数为50,对个体产品RON进行预测,并将预测结果作为此个体的适应度大小,计算见式(5)。
Fi=yRON,i
(5)
式中:Fi为个体i的适应度值;yRON,i为个体i的产品RON预测值。
采取轮盘赌法选择个体,计算式见(6)和式(7)。

式中:k为常数;N为种群规模;fi为群体中第i个个体的适应度;pi为第i个个体被选中的概率。
交叉是产生新个体的主要方式,但随机进行交叉操作可能会导致某些有效基因的缺失[19]。一般而言,GA中的交叉概率范围为0.6~0.9,变异概率在0~0.1之间。本研究选择0.6作为交叉概率,0.05作为变异概率。
为了确保装置的安全运行,诸多变量必须严格控制在一定的范围之内(具体由装置界定)。完成 GA参数设定和操作条件范围界定后,将原料及吸附剂性质输入优化模型中进行操作变量的寻优,结果见表10;优化后产品RON损失和实际产品RON损失数据见图4。

表10 3类原料的RON的GA优化结果
由表10和图4可知,3类不同原料的产品汽油RON损失平均降幅均超过30%,RON损失降幅大于30%的样本占比平均达73.58%,说明绝大多数的样本经过优化后,产品汽油RON损失降幅能够达到目标。分别以第1类原料中第20组、第2类原料中第90组、第3类原料中第40组数据样本的LIMS数据为基础,得到优化后的产品汽油RON、硫含量及对应的15个操作变量的优化值,结果见表11。

图4 产品RON损失实际值和优化后值对比◆—实际RON损失; ■—优化后RON损失; —实际RON损失平均值; —优化后RON损失平均值
由表11可见,以原料数据样本的物性数据为基础对15个操作变量进行优化,产品汽油RON损失均有降低的空间。其中,3类原料中氢油比、反应器底部温度和反应器顶部压力的优化方向比较一致。因此,可认为适当减小氢油比、反应器底部温度和反应器顶部压力能有效降低产品汽油RON的损失。
综上所述,通过所建立的BP神经网络模型与GA算法相结合,可以对S Zorb装置操作变量进行优化,为降低精制汽油RON损失提供指导。

表11 3类原料的RON的GA操作变量优化结果
6 结 论
(1) 以S Zorb工业数据为基础,采用灰色关联分析和SPSS方法并结合装置技术人员的建议,确定了包括原料油性质、吸附剂性质、产品性质和操作条件在内的22个建模变量。
(2)采用FCM聚类算法将S Zorb工业装置的FCC原料油分成3类,在此基础上,分别建立了结构为21-20-1,21-18-1,21-17-1的产品汽油RON的BP神经网络预测模型。结果表明:3类原料油的产品RON预测模型的预测值和实际值相对误差均小于1%,平均相对误差小于0.15%,说明所建立的3类RON预测模型效果良好。
(3)通过BP神经网络模型结合GA算法对S Zorb装置操作变量优化,3类原料的产品汽油RON损失平均降幅为44.15%,RON损失降幅大于30%的样本占比达73.58%。说明基于原料油聚类结果分别建立的产品RON优化模型,可在保证汽油脱硫效果的前提下明显降低产品RON损失,为S Zorb装置降低产品RON损失的实际操作提供重要指导。
猜你喜欢
山东冶金(2022年3期)2022-07-19 03:27:06
昆钢科技(2022年2期)2022-07-08 06:36:28
江苏安全生产(2021年10期)2022-01-18 03:21:52
加油站服务指南(2021年4期)2021-07-21 02:29:30
石油炼制与化工(2020年7期)2020-07-08 07:11:42
山东冶金(2019年3期)2019-07-10 00:53:54
石油石化绿色低碳(2019年6期)2019-01-14 01:16:12
咸阳师范学院学报(2016年6期)2017-01-15 14:18:46
化工管理(2015年36期)2015-08-15 00:51:32
重庆三峡学院学报(2015年3期)2015-06-27 05:53:57
