
PHP代码缺陷检测技术研究
2021-07-13 03:18赵勇涛
信息记录材料 2021年6期
赵勇涛
(湖北第二师范学院 湖北 武汉 430205)
1 引言
PHP语言凭借易于访问、功能丰富、代码运行效率高等优点成为开发Web应用程序系统的最受欢迎的语言之一。PHP的广泛使用也导致对Web应用中PHP安全漏洞的攻击逐渐增多,这些漏洞对Web应用程序构成了严重的安全威胁。因此,在发布Web应用之前,应检查Web应用的源代码,确保在攻击者发现Web应用上的安全漏洞之前尽快完善安全防护,提高Web应用对安全风险的能力,有效抵制针对Web应用的非法入侵。
2 PHP代码缺陷检测常用技术
2.1 静态代码分析
静态代码分析是指在不启动程序的情况下分析程序的源代码,并根据可配置的安全规则检测代码中的缺陷。根据不同的实现原理,静态代码分析可以分为两类。一种是分析源代码编译后分析中间文件,如字节码;另一种是分析源文件。分析字节码主要用于检测诸如规范和代码样式之类的问题。源文件解析是指用静态代码分析工具解析、编译、链接代码,以生成中间系统数据,如控制流图。完成此步骤后,再使用复杂的静态分析工具的验证规则来匹配和跟踪中间文件数据,以查找和检测缺陷并最终获得检测结果。基于源文件的常见静态分析技术,包括词法分析、语法分析、数据流分析等[1]。
词法分析是前端编译的第一步,主要原理是从左到右逐个字符地扫描组成原始程序的字符串。换句话说,词法分析就是逐字符扫描源代码并进行适当的分析,识别出一个个令牌。令牌是指具有词法意义的最小单元,如变量、关键字,将源代码分割成很多令牌组成的数组,从而形成令牌流。
2.1.1 语法分析
词法分析的结果是一系列令牌。这些令牌彼此独立,彼此没有任何连接。因此,直接基于此令牌序列分析数据流非常繁琐。语法分析可以识别这些令牌序列之间的关系,并将其表示为易于理解的中间表达形式,即抽象语法树。解析后获得的抽象语法树实际上是一个数组,但是数组中的每个元素都不是标记,而是类的一个对象。这些对象是上面定义的数据结构对象,以简化后续程序处理。例如,有如下代码,见图1。

图1 PHP代码片段
其抽象语法树是一个数组,而第一个元素是PhpParserNodeExprAssign类的对象,它对应于源代码分配运算符。第二个元素是PhpParserNodeStmtEcho_,它对应于第二行代码中的echo指令。每一行代码恰好对应于类对象,并且该类包含var、expr等变量、常量符号,方便在进行数据流时根据类的名称判断代码是复制语句还是输出语句,同时,通过获取成员变量的值可以轻松地获取变量的名称以及有关其分布的信息。可见分析语法树比基于token序列的词法分析方便得多,并且具有更高的抽象级别,更适合于编程操作[2]。
2.1.2 数据流分析
数据流分析是指用于获取有关数据如何沿程序执行路径传递相关信息的一组技术,目的是提供有关流程如何处理其数据的全局信息,实际上并没有启动该程序。在程序运行时,它使用静态代码显示相关信息。数据流分析是静态代码分析的一种常用方法,并且是根据编译原理来优化代码的有效方法。数据流分析中的大多数问题与捕获各种程序对象(例如固定值、表达式、常量、变量等)有关。由于静态分析本身的局限性,数据流分析通常忽略条件判断,即if或for语句的控制条件,这意味着默认情况下所有路径都是可访问的,目的是减少检测遗漏。
数据流分析方法通常分为两种:自下而上的分析和自上而下的分析。自下而上的数据流分析意味着,如果在程序代码分析过程中检测到危险的函数调用,则监视函数的参数,直到确认参数是否来自程序为止,这种分析方法要求安全审核员熟悉内部功能和机制的使用。毕竟,一个函数可以有多个参数,但是实际漏洞也许只是一个参数。自上而下的数据流分析使用用户输入,请求标头输入,环境变量输入等作为跟踪的起点,然后依次遍历解析器逻辑,收集被其“污染”的所有变量和函数,形成一个树结构,该树结构显示用户输入的传播路径。调用危险函数时,要做的就是查看参数是否在路径树中。如果在,则意味着产生漏洞。
2.2 动态检测技术
2.2.1 Fuz技术
Fuzz技术,也称为模糊测试,近年来已成为一种流行的安全测试方法,该技术通过将大量意外数据注入目标系统并监视系统异常反应来检测软件漏洞。该技术可以充分利用计算机的功能来随机生成和发送测试人员预先生成的大量结构数据。同时,还能客观地引用测试人员的安全测试经验。执行模糊测试的过程可以分为四个阶段。
(1)生成大量的测试数据;
(2)将生成的测试数据发送到目标系统;
(3)自动监视目标系统的注释和状态,确认是否有错误、故障等反馈;
(4)根据目标系统的注释确定是否存在任何潜在的安全漏洞。
在信息安全中,模糊测试通常用于自动检测二进制软件中的堆栈溢出漏洞。近年来,越来越多的Web安全研究人员对模糊测试进行了迁移应用,用于查找Web安全漏洞。通过创建各种特定的攻击有效负载集并与适当的模糊测试程序配合使用来对目标Web系统进行Fuzz检测,可以有效地提高检测效率。
2.2.2 黑盒/灰盒测试技术分析
黑盒测试是一种软件测试方法。测试人员不需要知道有关程序的任何内部信息,也不需要知道用于开发程序的相应程序代码、体系结构和语言。只需要了解有关程序的输入、输出和逻辑功能的信息。用于Web应用程序的大多数动态检测工具都基于黑盒测试,这些工具通常以扫描仪或漏洞测试工具的形式存在。前者自动化程度更高,并且可以跨Web应用程序执行完整的故障检测,如指纹识别、爬虫程序等。对于漏洞检测,主要利用负载测试库检测漏洞,自动扫描目标Web应用程序中包含的页面,并测试其中的输入点,然后通过分析从测试数据(例如AWVS和AppScan)返回的信息,达到检测Web应用程序漏洞的目的。
大多数黑盒检测工具都使用Fuzzing技术。在测试Web应用程序时,通常会根据漏洞创建的原理使用手动编写的测试数据集,较少使用随机生成的测试数据。
3 静态检测与动态检测相结合的检测方案
3.1 静态分析代码的输入输出设计
静态分析部可以检查代码、实现逻辑,遍历MVC体系结构的各层。动态检测本身无法解析代码,因此,本次设计的静态分析、动态分析组合框架的静态分析部分不是完全独立的,而是具有两个重要的接口,即输入接口、输出接口。输入接口的定义是URL参数的map/list结构,来自动态分析得到的值域序列转换而来,将URL参数的map/list结构并传输给静态分析部分。静态分析包括一个专门开发的模块识别部分。将该数据结构与路由代码的详细逻辑相结合以进行静态分析,从而在数据结构中的参数值域中找到“路由”,并基于不同的值域按照不同用户自定义的分析逻辑对代码进行分析[3]。例如,如果静态程序输入接口接收到图2中所示的数据结构时,会从Web应用程序的“路由”代码查找role,moduie,op的相关部分,再用[userir,info,show]等值域集合找到程序代码,然后进行静态分析。
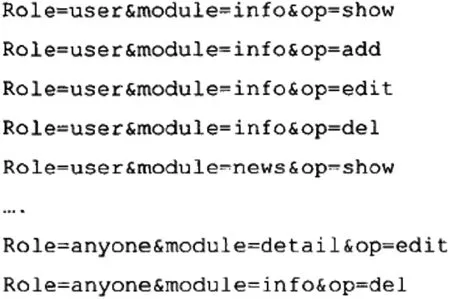
图2 URL参数map/list结构
静态分析的输出接口主要用于为动态检测的第二次启动提供数据,提取与MVC体系结构应用程序的各个分支代码相对应的各种路由参数,并通过对代码部分(尤其是路由代码部分)的详细分析来获得其完整值域。通过输出接口传输值域给动态分析模块,有效弥补动态分析的不足。
3.2 动态分析二次启动设计
本次研究的动态分析+静态分析的检测模式中的动态分析需要启动两次,这是该模式的重要特点。动态分析第一次启动时进行纯动态检测,识别过程属于传统的动态识别方法。识别结果分为两部分:第一部分,获得的部分检测结果用作最终的动态分析结果;第二部分,获得的URL参数域和值域,作为参数传送给静态分析模块。静态分析接收参数,进行分析后返回值域参数给动态分析模块,以补充第一次动态分析获得的URL参数值域,从而得到完整的值域。在进行逻辑判断后,动态分析模块将第二次启动,再次执行动态检测和分析,以补充完善第一次动态检测分析的结果。
4 结语
综上所述,目前,网络安全攻击手段越来越多,PHP语言开发的Web应用是网络黑客的攻击重点。如果未及时发现代码缺陷,找出安全漏洞,就容易被黑客攻击破坏。本文提出了一种静态分析和动态分析相结合的PHP代码缺陷检测方案。但要真正实现此方案是非常复杂的工程,需要后续进行不断研究。
猜你喜欢
小猕猴学习画刊·下半月(2022年2期)2022-04-16
新世纪智能(数学备考)(2021年9期)2021-11-24
汽车维修与保养(2020年10期)2021-01-22
新世纪智能(数学备考)(2020年9期)2021-01-04
汽车维修与保养(2020年11期)2020-06-09
网络安全技术与应用(2019年7期)2019-12-24
中学生数理化·高一版(2018年10期)2018-11-08
计算机工程(2018年8期)2018-08-17
理科考试研究·高中(2017年10期)2018-03-07
西北工业大学学报(2015年3期)2015-12-14
