
基于深度学习的两阶段多假设视频压缩感知重构算法
2021-07-12 01:38:42杨春玲凌茜
华南理工大学学报(自然科学版) 2021年6期
杨春玲 凌茜
(华南理工大学 电子与信息学院,广东 广州 510640)
压缩感知重构算法旨在接收端利用观测值恢复出原始信号,是压缩感知研究任务的核心。图像压缩感知重构算法利用图像信号的空间相关性获得高质量的重构图像,而视频压缩感知重构(Compressed Video Sensing,CVS)则在其基础上通过挖掘视频信号特有的时间相关性来提升重构质量。传统基于分块的CVS重构算法通常结合运动估计与运动补偿算法(Motion Estimation/ Motion Compensation,ME/MC)实现时间相关性的有效利用。文献[1- 2]提出“预测-残差重构”的视频重构框架,首先采用多假设预测算法(Multi Hypothesis,MH)在相邻帧中搜索相似块组成假设集,而后利用Tikhonov正则项求出各假设块的预测权重,从而得到重构帧的预测信息,最后针对预测残差更稀疏的特性,采用基于分块的平滑投影迭代重构算法(Block Compressed Sensing based Smoothed Projected Landweber,BCS-SPL)[3]进行残差重构提升重构质量;该框架结构简单、重构性能好,是CVS领域经典的重构框架,基于此,多种改进算法被提出。为了优化假设集的构成,文献[4]在多个候选参考帧中选择最优参考帧进行多假设预测;文献[5]同时利用多个参考帧对当前帧进行多假设预测;文献[6]提出基于多参考帧的二阶段多假设重构算法(Two-Stage Multi-Hypothesis Reconstruction,2sMHR),在观测域多假设重构的基础上引入第二阶段图像域重叠分块多假设,有效地减轻了块效应。为了提高假设块权值的求解精度,文献[7]引入弹性网模型,将l1范数与l2范数作为权值求解的正则约束项;文献[8]则在此基础上对l2范数正则化项进行权值调整。为了适应更稀疏的残差信号的重构需求,文献[9]利用MH[2]算法进行残差重构,减少了BCS-SPL带来的重构噪声。结合ME/MC的多假设CVS重构算法能很好地挖掘帧间相关性,获得了较好的重构质量。然而基于固定分块的运动估计将导致块内各像素的运动向量丧失差异性,从而产生不必要的伪影与错误重构,不适应运动较为复杂的序列。另外,此类算法由于繁琐的搜索与迭代计算,复杂度往往较高,严重限制了传统CVS算法的应用。
近年来,深度神经网络(Deep Neural Netwrok,DNN)在图像压缩感知重构领域取得了一系列的突破。文献[10]首次利用深度神经网络的方法,构建了由全连接层与卷积层组成的重构网络实现图像分块压缩感知重构,在提高重构质量的同时重构时间有数量级降低。在此基础上,文献[11]提出了基于深度学习的图像压缩感知算法(Deep Networks for Compressed Image Sensing,CSNet),设置了可学习的卷积采样网络以保留更多有效信息,并在重构端采用卷积全图重构,有效地减轻了块效应。文献[12]结合传统迭代阈值收缩算法(Iterative Shrinkage Thresholding Algorithm,ISTA)[13]与深度学习技术,提出了ISTA-Net+算法,具有一定理论可解释性的同时实现图像高质量快速重构。以上算法体现了深度学习在图像压缩感知与重构中的优越性,也为视频压缩感知与重构算法的发展提供了思路。文献[14]首次提出一个端到端视频压缩感知重构算法(A Learning Framework for Video Compressive Sensing,CSVideoNet),该算法在利用多层卷积层进行简单的单帧图像初始重构后,通过一个合成运动估计的长短期记忆网络(Long Short-Term Memory,LSTM)将关键帧丰富的细节信息传递至非关键帧,实现了时间信息流动,然而LSTM很难建模像素空间相关性,且训练难度大,影响了重构性能。文献[15]在CSNet[11]重构的基础上,引入多级特征补偿卷积网络,利用关键帧的多级特征补偿非关键帧,然而基于卷积的神经网络难以挖掘视频信号的准确运动信息,对于运动较快且复杂的运动序列,重构性能不佳。
为了解决上述问题,本研究提出一个基于深度学习的两阶段多假设视频压缩感知重构网络(Two-stage Multi-hypothesis Network for Compressed Video Sensing,2sMHNet),包括帧内图像压缩感知重构网络与帧间运动增强网络两部分。CSNet[11]由于结构简单且性能优良,是理想的帧内图像重构网络,但该网络单纯前馈式的重构方式容易导致重构误差逐级传播放大,基于此,本研究提出残差重构模块,利用观测值的反馈进行监督校正,提升重构质量。对于帧间运动增强重构网络,传统多假设重构算法虽然能高效地挖掘视频时间相关性,但存在复杂度过高、块效应严重、预测精度受限等不足,因此本研究提出基于深度学习的多假设预测网络以及残差重构网络。前者通过时域可变形卷积对齐网络实现基于深度学习的多假设预测,其自适应参数学习以及像素卷积的实现方式提高了预测质量,后者专项训练的残差重构网络更适应残差更稀疏的特性。为了尽可能利用图像组已得到的视频帧信息提升重构质量,本研究提出串行式两阶段多假设增强重构模式,针对信号特性在不同阶段选择不同的参考帧进行运动补偿,更适应于运动快且复杂的序列。
笔者针对该类研究的基本思想和初步实现——基于对齐预测与残差重构的视频压缩感知重构算法(Compressed Video Sensing Network Based on Alignment Prediction and Residual Reconstruction,PRCVSNet)[16]已公开报道,文中的2sMHNet是对文献[16]的改进与扩展,其改进包括以下几个方面:首先,优化了运动增强重构网络,提出了两阶段的预测残差增强重构网络,提高了运动估计与补偿的准确性与效率;第二,优化了参考帧选择机制,在第二阶段选择相关性较高的相邻帧作为参考帧,适应运动较快的序列;第三,简化了网络结构,提高实现效率;第四,文中提供了更多的实验结果和更全面对比分析。
1 图像与视频压缩感知重构
1.1 图像压缩感知重构
受限于压缩端算法复杂度,压缩感知通常利用观测矩阵Φ来实现随机采样:
y=Φx
(1)
(2)

传统图像压缩感知重构算法[2- 3,13]一般通过构造正则项,求解优化问题得到重构图像,然而此类算法由于复杂的迭代过程导致重构时延较长。近年来神经网络监督式学习优化的思想为图像压缩感知与重构提供了新思路,其中CSNet[11]构建了端到端可学习的图像压缩感知采样与重构网络,取得了优良的性能。在采样端,CSNet利用N个核大小为B×B×1(M=B2)的可学习卷积核模拟分块采样矩阵Φ,使其更偏向于保留低频结构信息。在重构端,CSNet采用全图重构的模式,利用一个1×1的卷积层实现线性初始重构,n个3×3的卷积层进行后续深度重构,有效挖掘了图像的空间相关性。然而该重构网络仅在第一个卷积层中利用观测值,未能充分利用观测值中包含的丰富的准确信息。因此本研究提出残差重构模块,在后续重构中利用观测值对重构信号进行校正,提升重构精度。
1.2 视频压缩感知重构与运动估计补偿
视频压缩感知一般采用多采样率采样策略对视频帧进行独立采样,该策略将视频序列划分为多个由一个关键帧与T-1个非关键帧组成的图像组(Group of Picture,GOP),GOP中第一帧被指定为关键帧以较高采样率rk进行采样以保留更多细节信息,而其余的非关键帧则以极低的采样率rnk进行单帧独立采样以降低平均采样率,其平均采样率表示为
(3)
由于视频是图像信号的集合,利用图像重构算法进行独立重构是最简单的方式,然而该方式忽视了视频信号中丰富的时间相关性,重构质量很差。现有的基于深度学习的重构网络[16- 17]多采用隐式的运动补偿方式,无法针对性地挖掘运动信息,重构效果有限。近年来很多优秀的基于深度学习的显式运动估计与运动补偿算法被提出。其中,基于神经网络的光流法[18- 19]利用像素在时域上的变化以及像素相关性估计两帧之间各像素的运动矢量,是常用的运动估计算法之一;然而,此类算法存在像素无法完全对应、估计误差逐级传递等问题,不适用于初始重构质量较差、参考帧与待重构帧非近邻的CVS重构问题,再者由于CVS数据集缺少光流标签,严重影响了估计的准确性。时域可变形卷积对齐网络[20- 21](Temporally Deformable Alignment Network,TDAN)则采用隐式的运动估计,减少了估计错误带来的误差;该算法利用多层级联的可变形卷积在高阶特征域利用卷积偏移实现了参考帧到当前帧的卷积对齐[22],取得了优良的补偿效果。利用可变形卷积实现的运动补偿无需运动估计监督,在初始重构质量较差,且两帧运动较大时仍能取得良好的运动补偿效果,更适合压缩感知与重构问题。
2 串联式两阶段多假设重构网络
基于传统多假设CVS重构算法可以有效地挖掘视频时间相关性,而深度学习卷积网络的重构方式则可以在大大缩短重构时间的同时通过大数据学习优化重构参数提升重构性能,因此本研究结合其优势,提出了基于深度学习的两阶段多假设CVS重构算法2sMHNet,其压缩与重构实现的整体框架如图1所示。在采样端,关键帧与非关键帧分别通过其对应的采样矩阵实现独立采样,即输入原始信号x0,得到观测值y0=Φx0。由于可学习采样矩阵优越的性能,文中采用rB2个核大小为B×B×1的卷积滤波器模拟采样矩阵,且在具体实现中,设置分块大小B为16以提高复用效率。在重构端,本研究设置了帧内图像压缩感知重构网络和帧间运动增强重构网络,分别挖掘帧内空间相关性与帧间时间相关性。帧内图像重构网络在CSNet的基础上增加了一个新的残差重构模块,利用原始观测值补偿重构过程中损失的细节信息。帧间运动增强网络(Enhanced Reconstruction Network,ERecNet)引入时域可变形卷积对齐网络与残差重构模块实现基于神经网络的两阶段的串联式多假设重构,充分挖掘图像组中不同视频帧的时间相关性。下文将详细描述所提重构网络的具体实现。
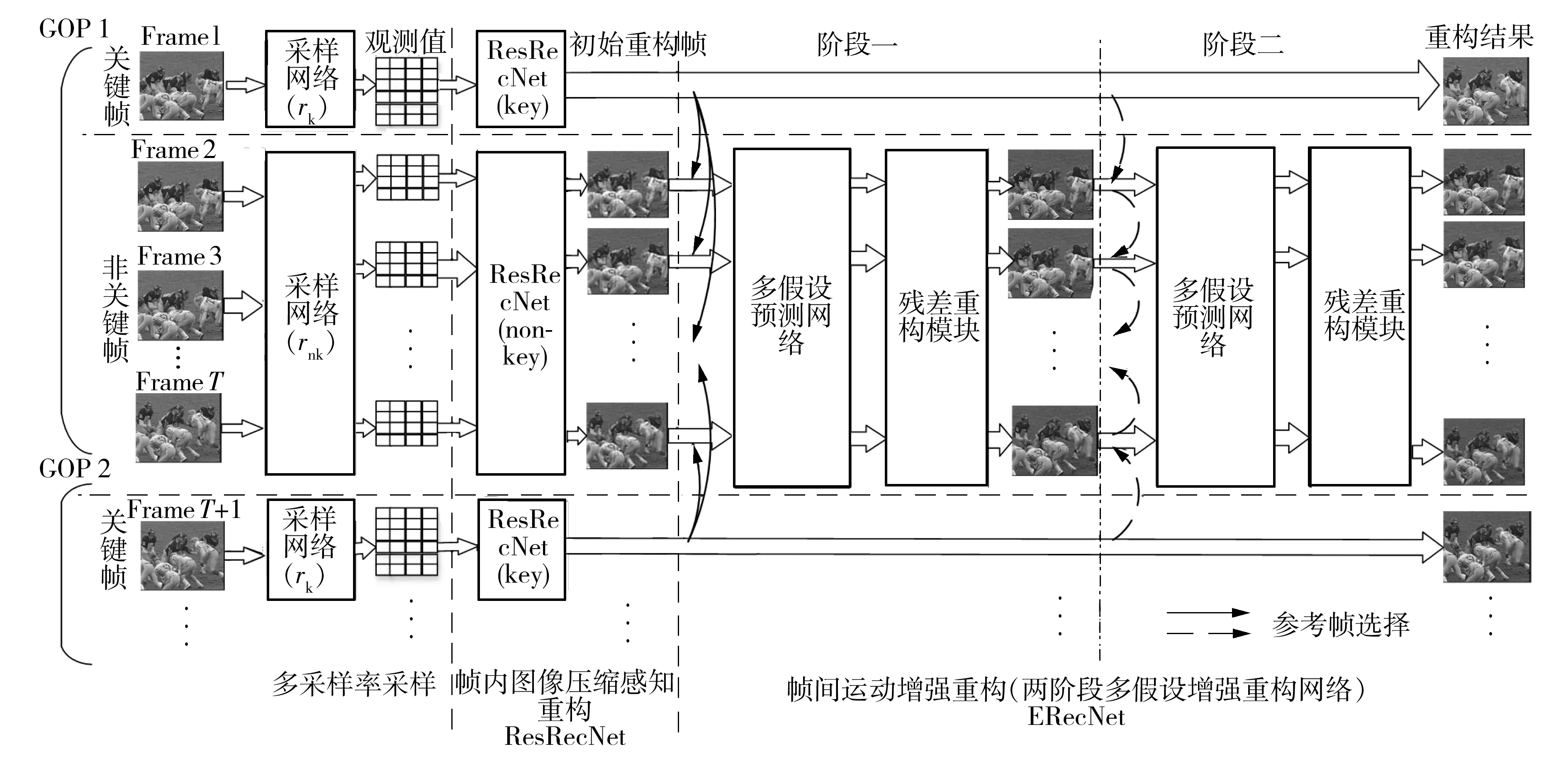
图1 2sMHNet的算法框架
2.1 基于残差重构的帧内图像压缩感知重构网络
在CVS重构中,帧内图像压缩感知重构方法至关重要,关键帧利用它得到重构结果,非关键帧依赖它获得初始重构。不同于以往的图像压缩感知重构网络通过单纯前馈的方式学习测量值到重构图像的非线性映射,本研究基于残差重构思路,提出一个新的图像压缩感知重构算法ResRecNet,利用观测值的残差反馈来提升重构精度。
在图像压缩感知重构问题中,从观测值恢复重构原图像的问题相当于采样矩阵求逆问题,即:
x0=Φ-1y0
(4)
然而该问题是病态问题,因此压缩感知重构算法旨在得到Φ-1的最优近似-1,其重构过程如下:
x1=-1y0≈x0
(5)
由于卷积网络的强拟合能力,ResRecNet采用图2虚线框区域所示重构网络来获得初始粗重构图像x1,该重构模块与上文1.1节所描述的CSNet[11]重构网络一致并设置深度重构网络层数n=4。然而,此重构过程中仍然存在着信息丢失,表示为xres=x0-x1,因此可利用残差信号xres对粗重构结果进行补偿,提升重构精度。而在压缩感知问题中,xres可由其观测域残差yres重构得到,即:
yres=y0-y1=y0-Φx1
(6)
xres=Φ-1yres≈-1yres
(7)
如图2实线框区域的残差重构模块所示,粗重构图像x1通过采样矩阵Φ得到其观测域表示y1,y1与原始观测值y0作差即获得残差信号的观测域表示yres。而后,为了得到残差信号的图像域表示,yres再次通过重构模块进行重构,如式(7)所示。最后ResRecNet通过将残差信号xres与粗重构x1相加完成了残差的补偿,得到最终重构帧x2。

图2 ResRecNet网络结构
在训练过程中,采样矩阵与帧内图像重构网络进行端到端优化,且重构网络中两个重构模块的参数施行共享以减少参数量。本研究采用均方误差衡量重构帧与真实帧的像素差异,并将其作为损失函数用于采样矩阵与网络参数的训练,具体数学描述如式(8):
(8)
其中:xj表示不同阶段的重构帧,x0为原始信号。
为了保证网络的每个模块都实现其设计的功能,本研究对重构的每个阶段都进行严格监督,其损失函数表示为
LResRecNet=L(x1,x0)+L(x2,x0)
(9)
2.2 用于非关键帧的两阶段多假设增强重构网络
经过视频压缩感知帧内初始重构之后,关键帧由于其高采样率拥有较高的初始重构质量,而更多的非关键帧初始重构效果很差。因此本节帧间运动增强重构网络旨在利用视频帧间时间相关性提升非关键帧的重构质量。遵循“预测-残差重构”的多假设重构框架,本研究设计了一个两阶段多假设重构网络,如图1所示,该网络包含参数共享的两个阶段,每个阶段都将包含一个多假设预测网络和一个残差重构模块。
2.2.1 多假设预测网络
传统多假设预测算法以块为单位搜索假设集并进行加权线性组合得到当前帧的预测帧,而本研究基于深度学习可变形卷积的概念实现了基于像素的多假设预测。可变形卷积[22]是传统卷积的一个优化分支,通过学习像素的偏移使得卷积层从其规则的感受野之外获得有用信息,提高了卷积的性能。而时域可变形卷积对齐网络利用可变形卷积层学习两帧之间的运动偏移[20- 21],并利用偏移指导参考帧到当前帧的对齐,实现了两帧之间的运动补偿。为了减少网络负担,本研究提出一个简化版的时域对齐预测网络,如图3所示,该网络通常分为3个步骤。
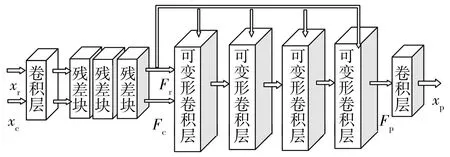
图3 时域可变形卷积对齐网络的网络结构
首先,利用特征提取模块将输入的参考帧与当前帧(xc,xr)映射至其特征域(Fc,Fr)以充分利用高阶的运动特征学习更准确的运动偏移,该特征提取模块通常由一个3×3卷积层与3个残差学习块组成。

(10)
其中,wk为学习得到的第k个采样位置的对应权重。为了保证假设集与待预测像素的运动相关性,可变形卷积网络在全图范围内寻找匹配像素点,p0+pk+Δpk表示该匹配位置的位置信息,其中pk为卷积固定偏移,而Δpk为可学习的运动偏移,取决于当前帧与参考帧的运动关系,表示为
Δpk=Woffsct(Fr⊕Fc)
(11)
其中,Woffsct为卷积层权重参数,⊕表示两帧通道拼接操作。为了提高预测精度,本研究采用四层级联的可变形卷积进行特征域的对齐,得到特征域预测帧Fp。
最后,为了输出预测图像xp,利用一个卷积层实现特征域到像素域的映射。
相比于传统多假设预测,该网络有以下3个优点:①该网络以像素为最小单位进行运动估计与补偿,避免了分块带来的块效应与伪影,同时提高了运动补偿的灵活性与准确性;②通过端到端的学习,自适应得到特征域最优偏移向量,从而得到最优假设集;③通过卷积核参数学习得到线性加权的权重,提高假设集权值的求解精度。在具体实验中,设置K=9,采用核大小为3×3的可变形卷积进行多假设预测,并且在训练过程中对输出的预测图像进行监督以保证预测网络的正确学习,其损失函数为
Lp=L(xp,x0)
(12)
2.2.2 残差重构网络
多假设预测网络可以很好地对齐参考帧与当前帧共有的信息,然而对于当前帧独有的信息则难以实现有效预测,因此本研究再次引入残差重构模块,利用当前帧的原始观测值补偿预测帧遗失的运动信息与细节信息,也为下一阶段的增强重构提供更准确的当前帧信息。该残差重构模块的网络结构与上文2.1节中ResRecNet的残差重构模块相同,即输入预测帧xp后,该模块将其与原始观测值y0在观测域进行求残差运算,得到残差重构帧xr。在此过程中,残差重构模块中的重构网络参数将重新训练以适应更稀疏的残差信号的重构需求。
在压缩感知问题中,重构图像越接近于原始图像,则它们的观测值也将更为相似。因此本研究将在得到重构帧后联合图像域与观测值域的均方误差损失对重构过程进行监督,表示为
Lr=L(xr,x0)+L(yr,y0)
(13)
其中,yr、y0分别表示残差重构帧xr与原始帧x0经过Φ采样得到的观测值。
2.2.3 串行式两阶段增强重构
运动补偿过程中,参考帧的选择是得到高质量预测帧的关键,而参考帧的选择主要取决两个因素:参考帧与待重构帧的相关程度(若相关程度较低,则容易出现运动信息匹配错误或者无法匹配的问题,导致运动补偿效果较差)和参考帧的质量(低质量参考帧由于其自身高频细节信息的缺乏无法在运动补偿过程中提供高质量高频信息,导致重构效果受限)。
基于图像组中各帧质量不均衡以及帧间相关程度差异等特点,本研究提出串行式两阶段多假设增强重构模式。第一阶段由于关键帧初始重构质量远远高于非关键帧,因此选择关键帧作为参考帧以提供更多细节信息。为了避免参考帧离关键帧过远导致相关度过低,每个GOP的前⎣N/2」个非关键帧将选择当前GOP的关键帧作为参考帧,而剩余帧选择下一个GOP的关键帧为参考帧。第一阶段重构后,关键帧与非关键帧重构质量的差异大大缩小,因此第二阶段选择帧间相关程度更高的相邻帧作为参考帧来提高匹配效率。同样的,每个GOP的前⎣N/2」个非关键帧选择当前待重构帧的前一帧作为参考帧,而其余非关键帧选择当前帧的后一帧作为参考帧。以GOP的大小N=8为例,两个阶段的参考帧的选择方案如图4所示,其中阶段一的参考帧选择由实线箭头表示,阶段二的参考帧选择由虚线箭头表示。在两阶段多假设增强重构过程中,每个增强重构阶段都包含一个多假设预测网络与残差重构网络以充分利用所选参考帧与当前帧的时间相关性。

图4 各阶段参考帧的选择(N=8)
由于GPU显存的限制,本研究共享每个阶段增强网络的网络参数,且在训练过程中固定采样与初始重构网络参数,对增强重构网络独立训练。两阶段的增强重构皆设置了对应的监督损失函数,因此该帧间运动增强重构网络的损失函数表示为
(14)
其中,xpi、xri、yri分别表示第i阶段的预测帧、残差重构帧以及残差重构帧的观测域表示。
3 仿真与分析
3.1 网络训练
由于网络结构复杂且包含多个阶段,因此选择一个大的数据集对于网络的充分训练是很有必要的。与CSVideoNet相同,本研究选择了UCF- 101数据集来进行两个部分的网络的训练,该数据集包含101个类别的13 320个视频序列,其庞大的数据量基本满足了网络的训练需求。在具体实验中,按照8∶1∶1的比例划分训练集、验证集以及测试集,且为了加速训练将每个序列的每帧图像中心裁剪为160像素×160像素,并进行灰度化处理。
自适应矩阵估计优化器将被用于网络参数的优化,设置学习率为0.000 1,动量估计为0.9和0.999。使用PyTorch框架来实现文中提出的模型并且在NVIDIA 2080Ti进行训练与测试。
3.2 实验结果与分析
为了更好地评估本研究提出的2sMHNet的性能,将其与目前优秀的CVS重构算法进行对比,并分析了网络中各模块的性能。
3.2.1 与基于深度学习的图像视频压缩感知重构算法的对比仿真实验
将2sMHNet与两种深度学习图像压缩感知重构算法(ISTANet+[12],CSNet[11])、两种加入了时间融合网络的视频压缩感知重构算法(VCSNet[15],CSVideoNet[14]),以及笔者所在课题组前期研究提出的算法(PRCVSNet[16])进行对比。基于作者给出的代码,CSNet与ISTANet+的仿真结果容易获得,但视频压缩感知重构网络无源码且仿真较复杂,因此本研究基于文献[14- 15]给出的各采样率下的实验数据,训练2sMHNet与之对比。


表1 2sMHNet与几种深度学习重构算法的重构结果对比
2sMHNet与PRCVSNet的网络参数量以及CIF序列每个GOP的平均重构重构时间的对比如表2所示。结果表明,2sMHNet相比于PRCVSNet,在降低了网络复杂度的同时可以更有效地挖掘视频的时间相关性,提高重构质量。
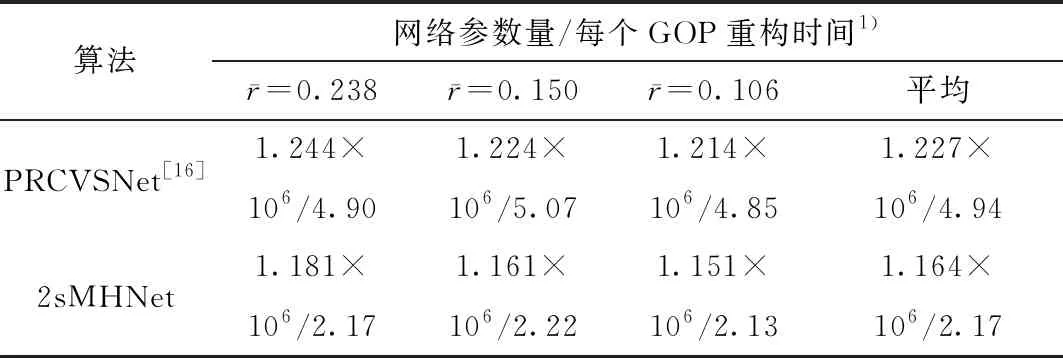
表2 2sMHNet与PRCVSNet的算法复杂度对比
由于实验条件不同,文中算法将单独与另一种优秀的CVS重构算法CSVideoNet进行对比。基于原文给出的实验条件[14],即GOP大小为10,关键帧采样率rk为0.2,非关键帧采样率rnk分别为0.037、0.018、0.009,相应地平均采样率分别为0.053、0.036、0.028。UCF- 101数据集中随机抽取的10%序列将被用作测试集,其PSNR与SSIM的对比结果如表3所示。由表3可见,文中算法取得了更优的重构结果,相比于CSVideoNet,PSNR平均提升了4.25 dB、SSIM平均提升了0.11。

表3 2sMHNet与CSVideoNet的重构结果对比
3.2.2 与传统视频压缩感知重构算法的对比仿真实验
将2sMHNet与两种具有代表性的传统CVS重构算法(2sMHR[6],SSIM-InterF-GSR[17])进行比较。2sMHR为性能优良的传统分块多假设算法;SSIM-InterF-GSR利用组稀疏特性融合时空相关性,是目前性能较好的传统CVS重构算法。基于作者给出的实现代码,本研究在Matlab2016a中实现这两种传统算法,并且为了缩短传统算法的重构时间,采用分辨率更小的6组QCIF格式的标准视频序列进行仿真实验,包括运动较快序列Soccer、Football、Ice与运动较慢序列Foreman、Hall、Su-zie。仿真测试了上文给出的平均采样率分别为0.238、0.150、0.106、0.053、0.036、0.028的条件下各算法的重构性能,并且为了保证GOP大小改变时总帧数不相差过大,GOP大小设置为8的实验中选取每个序列的前12个GOP进行重构,而GOP大小设置为10的实验中则选取每个序列的前10个GOP进行重构。
2sMHNet、PRCVSNet与传统CVS重构算法重构结果的对比如表4所示;为了验证运动增强网络的性能,表4同时给出了2sMHNet与PRCVSNet的初始重构网络ResRecNet的重构结果。

表4 2sMHNet以及PRCVSNet与传统重构算法的重构结果对比
实验结果表明,文中算法无论在快序列或者慢序列中都取得了最好的重构效果,并且随着平均采样率的降低该网络重构质量提升效果更加明显。当平均采样率为0.238时,相较于2sMHR,在6个序列中的PSNR平均提升了2.87 dB、SSIM平均提升了0.031 3,相较于SSIM-InterF-GSR,PSNR平均提升了0.56 dB、SSIM平均提升了0.016 1;平均采样率下降至0.028时,相较于2sMHR、SSIM-InterF-GSR,2sMHNet的PSNR平均提升了8.54、3.98 dB,SSIM平均提升了0.287 9、0.096 2。再者,文中算法2sMHNet相较于传统方法在快序列与慢序列中的提升效果不一;对于快速运动序列,由于运动较快导致的帧间相关性较低使得传统的视频压缩感知重构算法因难以找到合适的匹配块而导致不准确运动估计,使得重构质量较差,在文中算法的重构网络中,由于其较好的初始重构质量再加上增强重构网络进一步地提升,重构质量较SSIM-InterF-GSR有了明显改善;对于慢速序列,传统方法可以利用准确的运动估计获得优秀的重构质量,而2sMHNet加入了两阶段预测残差增强网络之后,相较于其初始重构结果平均PSNR得到了较大地提升,高达2.1~9.5 dB。
序列Hall在不同重构算法及不同平均采样率下的重构结果如图5所示。图5(a)为平均采样率0.150情况下第32帧的重构结果,观察可知,图像重构算法ResRecNet重构效果最差,传统算法2sMHR与SSIM-InterF-GSR均出现了不同程度的模糊,特别是运动程度较大的人物腿部部分,而PRCVSNet与2sMHNet均能较准确地重构,且2sMHNet精度更高;图5(b)为极低平均采样率0.036时Hall序列第22帧的重构结果,观察可知,不同算法的重构差异更为明显,2sMHR几乎无法重构,SSIM-InterF-GSR重构图出现了严重的变形,细节信息缺失,但2sMHNet在初始重构质量较差的情况下仍旧能通过运动补偿较好地重构出原信号。

图5 序列Hall在不同重构算法及不同平均采样率下的视觉重构结果
3.2.3 图像残差重构网络的性能分析
文中作为帧内图像重构网络的ResRecNet是在CSNet[11]的基础上加入残差重构模块以进行残差补偿。为了验证其残差重构块的性能,本研究对比了相同实验条件下两种图像重构算法的重构性能。为了保证对比的公平,在CSNet的实验条件下进行端到端训练及测试,即设置采样分块大小为32,采用裁剪为96像素×96像素的图像块的BSDS500数据集,在Tensorflow框架GPU2080Ti加速下训练迭代140 000次。文献[11]给出CSNet重构网络深度重构卷积层层数n=5,而为了减轻网络的负担,本研究在n=4,5的情况下分别训练了两个网络深度不同的ResRecNet。对于各网络,本研究用分辨率为512×512的Lena、Baby、Peper及分辨率为256×256的Butterfly、House、Barbara标准图像进行了测试。表5给出3个采样率(0.1,0.2,0.3)下各算法的重构结果。
由表5所示结果可见,ResRecNet(n=5)相比于CSNet(n=5)在3个采样率下,PSNR分别提升了-0.14、0.22、0.56 dB,SSIM分别提升了0.007、0.003、0.011,证明残差重构块在重构中确实有助于重构性能的提高。另外,ResRecNet(n=4)与ResRecNet(n=5)重构性能相差不大,甚至在较多情况下层数较少的ResRecNet(n=4)重构性能反而较高,因此本研究中视频压缩感知重构算法选用n=4的ResRecNet作为其初始重构。
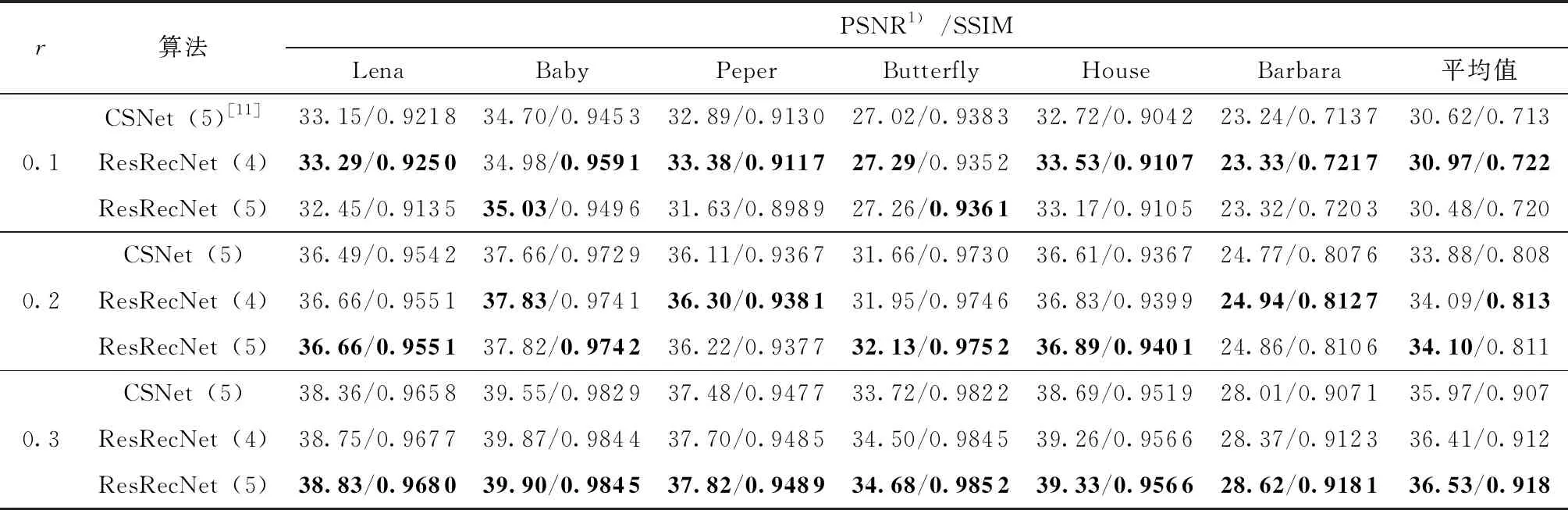
表5 不同采样率下各算法的重构质量对比
3.2.4 多假设增强重构网络性能分析
为了验证多假设增强重构网络各模块的性能,文中列出了2sMHNet的初始重构帧,两个阶段的预测帧与残差重构帧的PSNR重构结果如表6所示。与3.2.2节一致,在平均采样率为0.150、0.036时对QCIF格式的快速运动序列(Soccer、Football、Ice)与慢速运动序列(Foreman、Hall、Suzie)进行测试。由表6可知,两个阶段的多假设预测网络与残差重构网络都实现了其既定功能,有利于重构质量的提升。
为了充分利用时间相关性,本研究引入了串行式的两阶段重构,由表6可见,平均采样率分别为0.150与0.036情况下,快速运动序列的第二阶段重构结果相较于第一阶段分别提升了0.24、0.31 dB,而相同情况慢速运动序列仅仅提升了0.01、0.17 dB,证明了该重构模式在快速且复杂运动情景中的优越性。
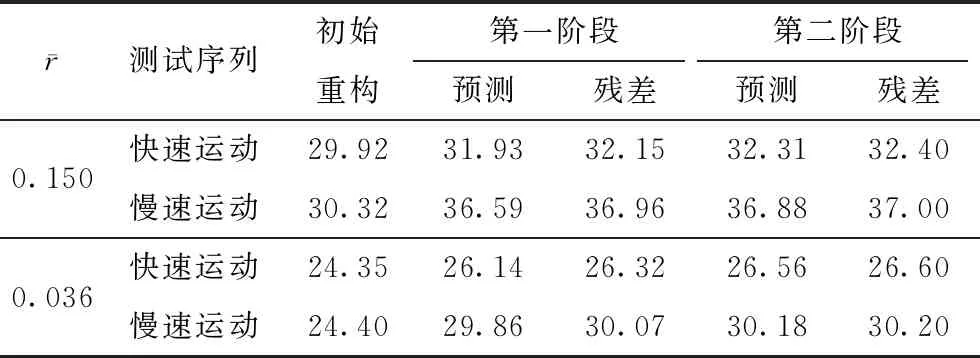
表6 2sMHNet各个阶段的预测帧与残差重构帧的重构结果
4 结论
结合深度学习自适应优化与传统CVS多假设运动补偿的思想,提出了深度学习两阶段多假设重构算法(2sMHNet)。该算法的帧内图像重构部分基于CSNet提出了一个新的图像重构算法ResRecNet,利用残差重构块补偿了细节信息,不仅为视频压缩感知重构提供了更好的初始重构结果,也被应用于视频的帧间重构网络中利用观测值进行校正。两阶段多假设增强重构网络基于传统多假设运动补偿的思想,首先引入深度学习时域可变形卷积对齐网络实现了基于像素的多假设预测,提升了预测精度,而后利用残差重构模块重构预测帧残差再次进行提升。另外为了充分利用图像组帧间相关性,本研究设置了串行式两阶段的重构模式,在不同阶段选择不同的参考帧以便获得更好的预测效果。实验结果表明,文中所提算法2sMHNet相较于目前优秀的视频压缩感知重构算法有着更优的重构性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
摄影世界(2022年1期)2022-01-21 10:50:14
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
大连理工大学学报(2017年4期)2017-08-07 07:03:20
山东大学法律评论(2016年0期)2016-08-16 03:24:12
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
