
电子商务代理人协商模型的建立与评估
2021-07-10 11:13吴磊
科技视界 2021年17期
吴 磊
(合肥市食品药品检验中心,安徽 合肥230088)
0 引言
互联网的普及使得消费者与企业或企业与企业间利用电子商务进行协商交易已成必然,通过代理人就可以自动快速、无距离限制完成交易。代理人协商是两个或多个软件代理人之间,通过不断重复地提出提议值,达成相互可接受协议的过程,要求代理人具有智慧学习能力,可学习动态协商战略。假设代理人在协商前已经拥有与其他使用时间依赖策略(Timedependent Tactic,TDT)[1]为协商战略的代理人的协商经验,进而建立规则库帮助协商,根据其中的规则猜测对方的态度,再配合修正的TDT来建构一种协商模式。选择判定树来建立规则库,判定树是人工智能领域里的分类和预测工具,是以树形图为基础的最简单明了的归纳式学习方法,通过分类已知的某些例子来建构判定树,从中可归纳出某些规律性。产生出来的判定树,也能应用来对未知的结果做预测。相较其他方法,判定树具备良好的解释能力,可以帮助用户建立其专业知识。并且以协商次数、联合效用与效率作为绩效指标,发现所提的协商战略能有效地改善协商结果。
1 协商基础理论
1.1 协商决策函数
常用的协商决策函数[2]包括时间依赖策略(TDT)、资源依赖策略与行为依赖策略。在此以TDT为协商双方使用的策略。在协商过程中,TDT依协商时间调整提议值,该策略行为主要受态度参数β的影响。时间依赖的提议值为式(1)、式(2)。其中xja→b(tn)为代理人α对代理人b在时间tn对议题j的提议值,tmax表代理人的协商期限,因此t0≤t≤tmax,而αaj(tn)为随时间变动的函数,其中kja为常数,表示代理人a对议题j提出的初始值。
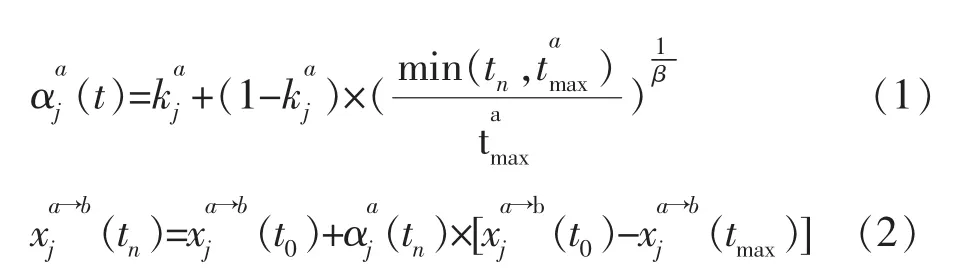
β值是影响收敛速度的主要因素,根据β的大小,TDT可分为两类函数,分别是Boulware(B)和Conceder(C)[3],两类函数在让步程度上存在差异。当β<1时,为Boulware策略,代理人将会尽力保持初始值,直到接近协商期限时,才会开始大幅收敛。当β>1时,提议值会很快逼近保留值。式(3)与式(4)为代理人的评分函数,其功能为评估自身与对方代理人所提的提议值,给1个分数,然后利用方程式(5)来判断是否接受对方代理人的提议值。
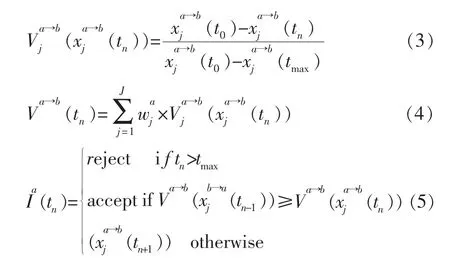
1.2 绩效指标
可通过很多绩效指标来测量协商结果的公平性与合理性。如协商次数、效率与公平性等[4]。各绩效指标如图1所示。在此采用协商次数、联合效用与效率作为评估协商结果的协商指标。
(2)联合效用:此绩效指标测量双方的社会福利。以协商双方的效用和作为计算式,见公式(6),其中x为协商的协议;Ua(x)与Ub(x)为代理人a与b的效用:

(3)效率:效率在图1中表示为曲线“效率协议”。当协议越靠近该曲线,表示越有效率。而在该曲线上必定会有一个以上的点相对于其他的点联合效用最大,此点称为“柏拉图最佳解”。
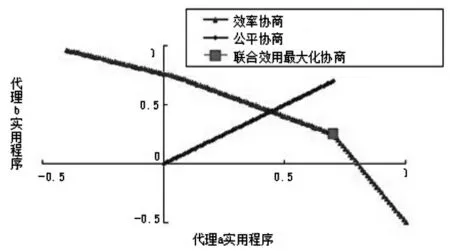
图1 效率、联合效用与公平性
2 协商模式的建立
2.1 资料选取
因协商空间庞大,特设定以下假设条件:
(1)协商议题为价格与数量,价格议题的协商区间固定为60,数量议题的协商区间固定为100。
(2)Boulware策略以β=0.3代表,Conceder策略以β=3.0代表。
(3)协商期限固定为50。
(4)卖方先出价。
表1为建立推测模型学习例的双方的实验参数组合,议题以间隔10为一个实验条件,权重以间隔0.4为1个实验条件,策略有Boulware和Conceder两种选择。双方以TDT为协商战略,共进行20 736组实验,如果协商次数在50次前结束的实验则不列入实验数据,因此实验数据共有20 731组数据。根据方程式(7),选取每组协商时间t为9、19、29、39与49时,双方的提议值加上计算双方提议值在整个协商区间的比例R(tn)。t*为t9、t19、t29、t39、与t49。因此判定树的输入属性为卖方的β值、R(t9)、R(t19)、R(t29)、R(t39)与R(t49),输出属性则为买方的β值。
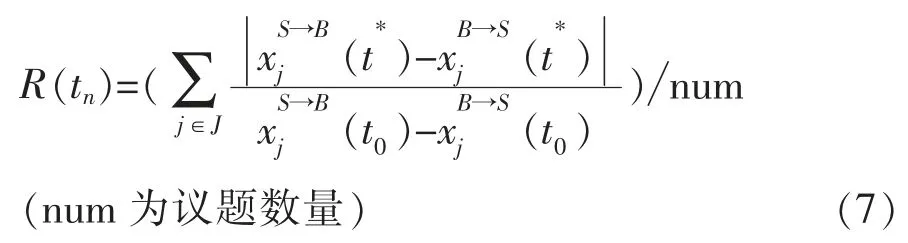
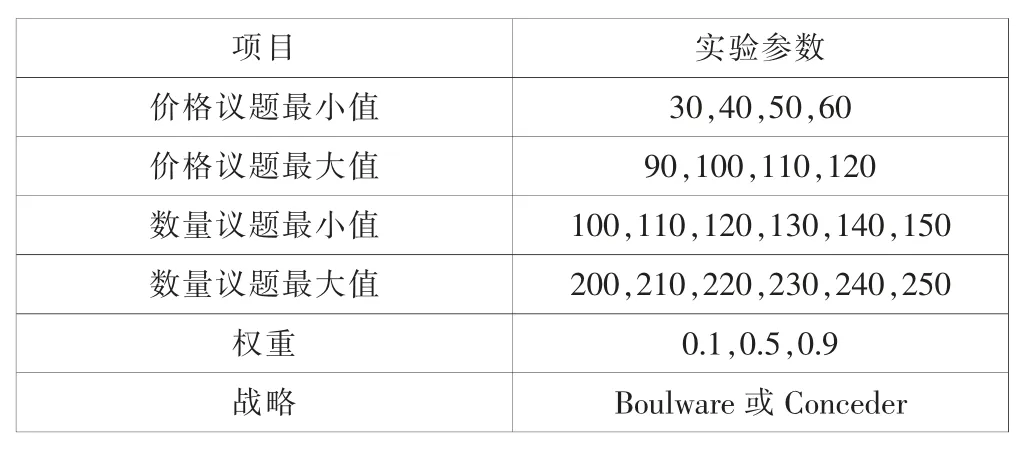
表1 建立推测模型学习例的实验参数组合
2.2 协商战略建构
在协商过程中,一旦卖方代理人猜测出买方代理人的态度(β值),为了保持出值过程的单调性,如果卖方代理人须改变自己的态度(β值),卖方代理人的协商战略即从方程式(2)修正为MTDT,如方程式(8)。
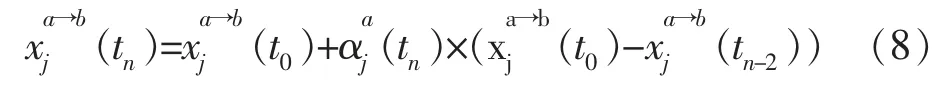
2.3 协商架构
在此设计的协商架构如图2所示,实线表示每回合都进行的动作,而虚线表示不是每回合都有回传值。相较于买方,卖方有两种出价战略,一为TDT,二为MTDT。每回合中,买卖双方都会通过TDT提出提议值,但卖方同时会将协商的数据传入推测模型,期望能猜出对手的态度,一旦猜出对手的态度,则卖方可选择使用TDT或MTDT。协商流程如图3所示,卖方先提出提议值后,买方使用方程式(4)与方程式(5)计算双方的评分值,再使用方程式(6)判断是否接受对方的提议值。如果接受对手的提议值,则代表买方代理人协商成功,则此次协商会立刻结束,反之则会继续协商。卖方在接收到买方所提出的反提议值后,也会判断是否接受买方所提的提议值。当双方都不满意对方的提议值时,就会一直进行协商,如此反复协商直到有一方接受协商,或是超出协商时间,才会结束本次协商。然而卖方与买方不同的是卖方有猜测对方协商态度的机制与MTDT,卖方会在每回合根据推测模型里的规则猜测对方的协商态度,假设已符合某规则,则卖方会决定协商战略是否变更,直到协商结束。
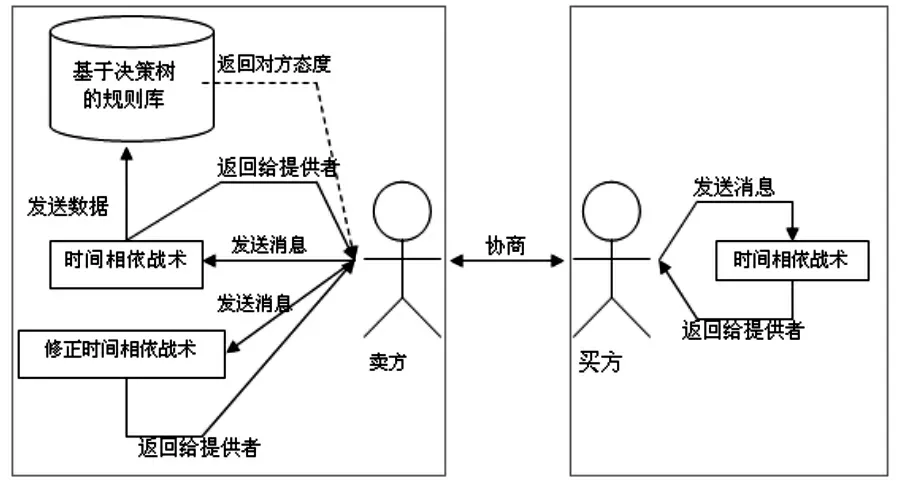
图2 协商架构
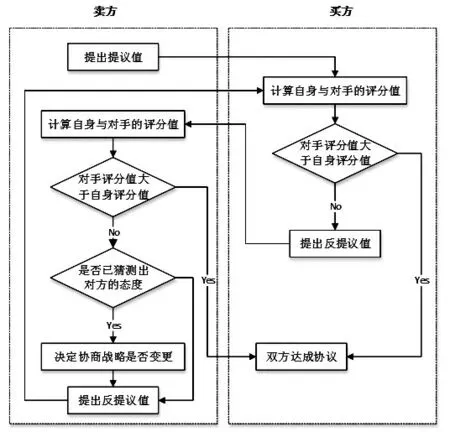
图3 协商流程
2.4 协商实验验证
为了验证在卖方猜出买方的态度后,是否愿意改变自身态度,将协商决策函数(NDF)与之前提出的协商模式进行比较,并以(I)卖方态度为Boulware,买方态度为Boulware;(II)卖方态度为Boulware,买方态度为Conceder;(III)卖方态度为Conceder,买方态度为Boulware;(IV)卖方态度为Conceder,买方态度为Conceder为实验,试图找出卖方较好的决策。表2为协商条件,得出的结果如表3所示。
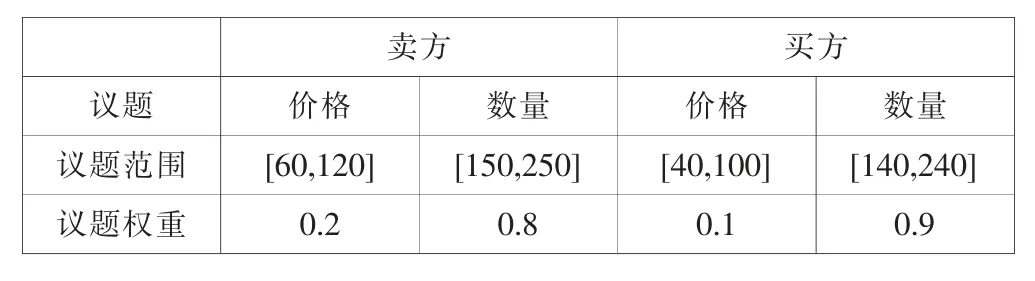
表2 协商实验条件
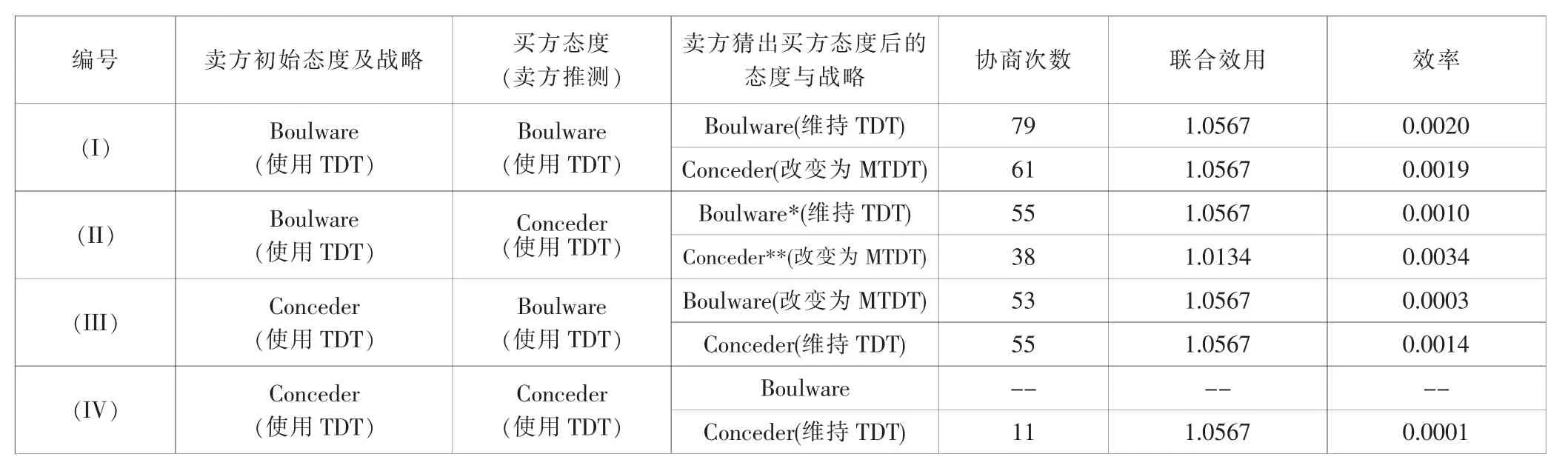
表3 协商结果
所有战略组合的协商结果见表3,粗体字为卖方在改变自身的态度与否的情况比较下较佳的结果。在实验(I)与实验(IV)中,也就是买方态度为Boulware战略时,卖方改变自身的态度会得到较短的协商次数与较佳的效率,而联合效用不变。在实验(IV)中,因为双方都使用Conceder战略,因此协商在卖方尚未判断出买方的态度即协商结束,在此情形下卖方只能采取TDT。在实验(II)使用TDT会得到较佳的联合效用与效率,但若使用判定树则是可以缩短协商时间。由上述实验可得卖方的最适协商态度与战略。
3 结论
电子商务代理人协商模型的构建具有重要的应用价值,假设卖方代理人在协商前拥有与其他使用TDT为协商战略的买方代理人的协商经验,以此经验建立推测买方态度的判定树,进而利用此判定树建立推测买方态度的推测模型,准确推测到买方的协商态度,卖方可根据买方的态度决定是否变更自己的态度与战略,以期达到较佳的协商结果。实验结果发现,不论买方的态度为何,使用判定树与所对应的最适协商态度与战略,都可在维持原有联合效用不变下,显著降低协商次数。
猜你喜欢
证券市场周刊(2023年46期)2024-01-07
证券市场周刊(2022年45期)2022-12-25
专利代理(2019年3期)2019-12-30
专利代理(2019年4期)2019-12-27
法大研究生(2019年1期)2019-11-16
对外经贸实务(2019年6期)2019-06-20
专利代理(2019年1期)2019-04-13
中华建设(2017年3期)2017-06-08
湖南农业(2016年3期)2016-06-05
专利代理(2016年1期)2016-05-17
