
食品质量追溯中RFID多标签识别防碰撞算法
2021-07-06 02:12姚金玲闫雪锋
食品与机械 2021年6期
姚金玲 刘 婕 闫雪锋
(1.天津职业大学,天津 300410;2.天津理工大学天津市先进机电系统设计与智能控制重点实验室,天津 300384;3.天津职业技术师范大学,天津 300110)
随着信息技术的快速发展,射频识别(Radio Frequency Identification,RFID)技术由于其非接触式信息交互、安全可靠信息传输、灵活快捷标识追溯等优点而被广泛用于工业、农业和商业等领域[1]。在食品质量追溯过程中,尤其是在运输和仓储中,需要对整车货品标签进行批量识别。多标签识别是RFID最为明显的优势,但当多个标签同时发送标识信息时,其发送信号会在数据传输到读取器时发生干扰形成碰撞[2]。碰撞不仅会降低系统的识别效率,还会导致识别时间变长,一定程度上限制了RFID技术的应用。
国内外学者对基于RFID标签冲突检测的防碰撞算法进行了大量研究,并取得了一定的成果,大部分防碰撞算法研究集中在ALOHA算法和二叉树算法。王祖良等[3]提出了一种用于农产品可追溯性的标签防碰撞自适应动态帧时隙ALOHA算法,该方法适用于设计的农产品追溯系统,大大提高了识别效率。与广泛采用的国际标准相比,吞吐量提升了30%。潘雪峰等[4]提出了一种结合动态帧时隙ALOHA算法和生日悖论概率理论的RFID系统防碰撞算法,该方法可以有效提高标签识别的准确性,减少识别过程的时间,提高射频系统信道的利用率及系统性能。尚弘[5]提出了一种基于搜索树的轻量级防碰撞方法,并设计了一种新的查询响应模式(单查询—双响应),可以提高标签识别的效率。结果表明,采用双响应模式和计数器触发的单查询模式可将整体通信开销减少42%。贺晓霞等[6]提出了一种基于锁定位的并行二进制分区(LPBS)防碰撞算法,该算法减少了读取器和标签之间发送的位数,同时降低了竞争时隙。仿真结果表明,大多数情况下,该算法在吞吐量和延迟方面均优于传统的防碰撞算法。但是,上述研究并没有全完消除空闲时隙,造成一部分时间和资源浪费,具有一定的局限性。
在食品质量追溯过程中,多标签识别是追溯的关键,而多标签识别不可避免地会产生碰撞。针对目前防碰撞算法查询时间过程会产生大量的沉余,增加通信开销,文章拟结合帧时隙ALOHA(Frame Slotted ALOHA, FSA)算法和最小均方误差(Minimum Mean Square Error, MMSE)预编码技术,提出一种RFID多标签识别防碰撞算法,即预编码帧时隙ALOHA算法,旨在为RFID多标签技术的发展提供依据。
1 RFID多标签识别技术基础
1.1 RFID系统构成及工作原理
RFID系统由标签、天线、读取器和后台数据库系统4部分组成(图1)。每个标签都有一个唯一的ID号,该ID号使用电磁波和天线进行数据交换和能量传输[7]。天线是位于RFID系统标签和读取器之间的数据收发器。读取器是RFID系统的信息传输站,负责读取和写入标签信息。后端数据库系统由中间件和信息处理等内部组件组成,对信息进行采集、分类、分析等[8],还可以控制阅读器和电子标签之间的双向标识。

1.后台数据库 2.读取器 3.天线 4.RFID标签 5.待识别食品
RFID的基本工作原理:在后台数据库系统的控制下,读取器通过天线将特定频率的电磁信号发送到标签,标签接收到该信号后,便会通过改变自身的阻抗来存储ID,信息被调制并反射回来。阅读器通过天线接收反射信号,对标签信息进行解调和解码,然后将其发送到数据库系统。后台数据库系统将根据接收到的信息执行相应的动作。
由于电子标签和读取器通过非接触进行信号传输,因此在进行多数据传输时有干扰的可能,严重时会导致传输失败[9]。RFID系统碰撞可分为标签—标签碰撞、标签—读取器碰撞、读取器—读取器碰撞3类。文章主要针对标签—标签碰撞问题进行相关算法和RFID多标签识别防碰撞算法改进。
1.2 帧时隙ALOHA算法
RFID多标签识别防碰撞算法包括基于树搜索的算法系列和基于ALOHA的算法系列。帧时隙ALOHA(FSA)算法与时隙ALOHA算法的最大区别为时隙ALOHA算法将识别周期划分为不同的时隙间隔[10]。FSA是一个由多个时隙组成的帧,并且该时隙由多个时间段组成。在数据传输过程中,每个帧的大小由系统确定。如果标签需要发送数据,读取器将随机生成一些时隙发送给标签[11]。整个过程的时隙数据就是唯一的标识号。标签还具有一个时隙计数器,一段时间后,时隙计数器增加1。如果时隙计数器的值等于帧中时隙的随机数,则标签可以发送数据,并且在数据发送过程中不会产生冲突。图2为帧时隙ALOHA算法。
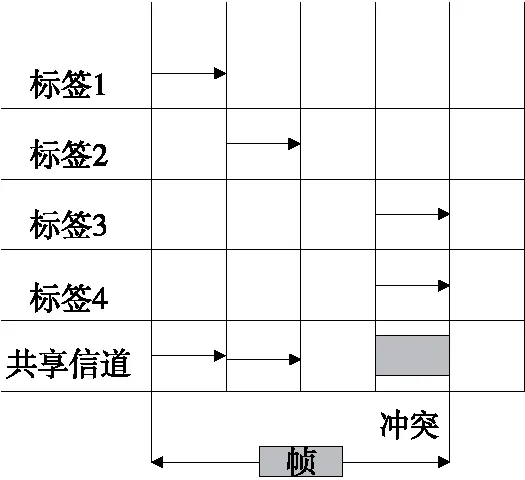
图2 帧时隙 ALOHA算法通信原理
为系统设置特定的帧长L,待识别标签个数n,当读取器与标签进行通信时,标签随机选择时隙返回序列码信息的概率p=1/L。由于该算法基于二项式分布,m个标签在同一时隙中响应读取器的查询命令的概率如式(1)所示[12]。
(1)
如果该时隙没有标签响应读取器的查询命令时,则该时隙为空闲时隙I,即m=0,概率如式(2)所示。
(2)
如果时隙中对查询命令的响应仅一个标签,则该时隙为成功的时隙S,即m=1,概率如式(3)所示[13]。
(3)
如果时隙中对多个同时标记响应阅读器的查询命令,则该时隙为碰撞时隙C,即m>1,该概率如式(4)所示。
Pc=1-Pi-Ps。
(4)
一个帧长时间内,成功识别标签的时隙数目如式(5)所示[14]。
(5)
算法系统的吞吐量如式(6)所示[15]。
(6)
对式(6)进行求导,则
(7)
整理可得:
(8)
当n为无穷大时,将式(8)按泰勒级数展开,得到最优帧长[16]:
(9)
当帧长L=n时,系统的最大吞吐率S如式(10)所示[17]。
(10)
因此,在处理大量标签识别问题时,帧长等于标签数时,识别效率最高,识别时间最短。但是,帧时隙也有其缺点。如果标签数量较多,则不能将帧长度增加到任意长度值,即帧时隙是有限的。当帧长达到最大时,随着标签的增加,效率逐渐下降。如果标签数远小于帧长度,则空闲时隙较多,造成大量的时隙浪费。
2 改进帧时隙ALOHA算法
2.1 预编码技术
考虑到噪声在信息传输过程中的影响,采用最小均方误差预编码技术对帧时隙ALOHA算法进行改进,以最小化实际传输符号与接收器估计输出值之间的差异,从而找到最优的预编码矩阵[18]。
argminE‖s-β-1s‖2,
(11)
(12)
式中:
β——功率影响系数;
Pt——系统的总发射功率,W。
当式(12)成立时,实际传输信号与接收机估计输出信号的差异最小。
根据式(12)建立拉格朗日函数,得到该函数的解:
FMMSE=HH(HHH+δI)-1,
(13)
式中:
H——信道矩阵;
δ、I——功率控制因子和单位矩阵。
(14)
式中:
(·)H——共轭转置运算;
(·)-1——求逆运算;


功率归一化因子β为[19]:
(15)
式中:
Tr(·)——迹运算。
此时预编码矩阵为:
(16)
预编码模型方框图如图3所示。

图3 预编码模型
信道矩阵H由Nt根发射天线和Nr根接收天线组成Nt×Nr,通过天线优化算法对信道矩阵进行选取。
2.2 预编码帧时隙ALOHA算法
基于预编码技术提出了预编码帧时隙ALOHA(MMSE-FSA算法),该算法将一些预设时隙组合为一帧fs,并将读取器工作辐射区的标签数设置为N。当识别认证标签时,标签随机且独立选择1-fs个时隙发送响应信号。
时隙中标签数量k的概率为:
(17)
时隙中标签数为1的概率为:
(18)
如果标签数量为1,此时隙中没有碰撞,可以成功完成标签标识。因此,根据式(19)可以正确识别帧中的标签时隙数。
(19)
则碰撞时隙数为:
fcollosion=fs-fsuccess。
(20)
2.3 MMSE-FSA算法工作流程
假设读取器在工作辐射区有天线,则工作辐射区可以识别很多标签,标签数量为N,MMSE-FSA算法步骤如下:
① 当读取器的工作辐射区中有标签进入,就会广播一个请求命令,RFID系统开始识别认证。
② 识别前对所有未识别的标签进行分组,并通过预编码技术进行预处理。通过式(14)建立预编码矩阵,发射机发送信号为:
x=smPek,
(21)
式中:
sm——发射信号映射;
ek——信号映射的调制符号;
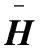
接收信号为:
(22)
③ 使用FSA算法对接收信号进行识别。
④ 检查是否识别了堆栈中的所有标签。如果未识别完,执行③,否则继续执行下一步。
⑤ 确定所有标签后,算法完成。
改进算法的流程图如图4所示。
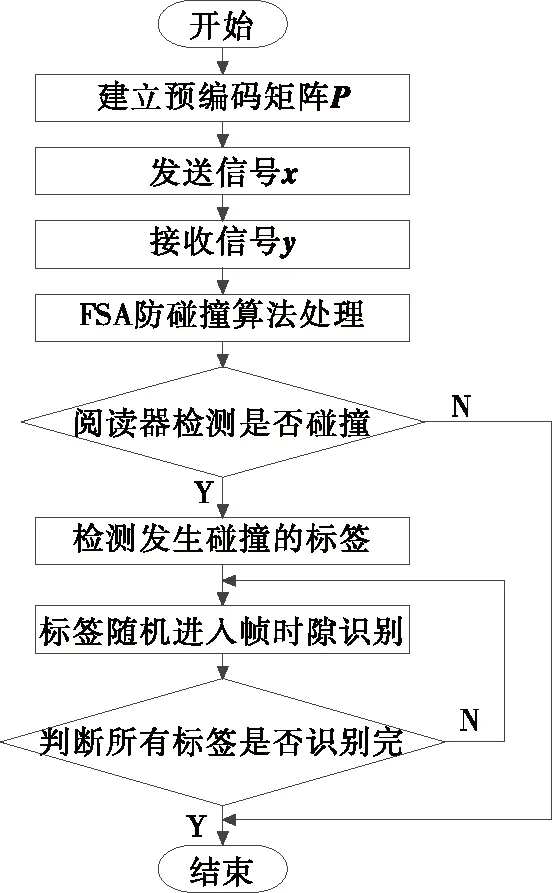
图4 改进算法流程
3 仿真试验及结果分析
3.1 仿真试验设置
仿真设备为联想PC机,操作系统为Windows 7 64位旗舰版,Intel i5 2450m CPU,2.5 GHz频率,8 GB内存和Matlab r2018a作为仿真平台。将MMSE-FSA算法(帧时隙ALOHA算法和最小均方误差预编码技术相结合)与帧时隙ALOHA算法、后退二进制搜索树算法(Regressive-style Binary Search Tree,RBST)[20]进行时隙总数、吞吐量、冲突时隙和识别时间分析。RBST算法引入标签状态计数器进行分组,利用前、后向搜索方法来减少标签的搜索范围。标签数量N在[0,1 000]变化,50为一个间隔。
3.2 仿真结果分析
MMSE-FSA算法、帧时隙ALOHA算法和RBST算法所需总时隙数比较结果见图5。由图5可知,MMSE-FSA算法的总时隙数随标签数量的增加呈线性增加,但是与帧时隙ALOHA算法和RBST算法相比,具有明显的优势。当标签总数从0~1 000变化时,帧时隙ALOHA算法生成的时隙曲线总数呈指数增长。RBST算法生成的时隙曲线总数呈线性增长。当标签数为1 000时,改进算法所需的时隙总数约为800,比帧时隙ALOHA算法少4 000,比RBST算法少1 000。因此,MMSE-FSA算法总时隙数变化最为缓慢,符合预期效果。

图5 不同算法总时隙数变化曲线
MMSE-FSA算法、帧时隙ALOHA算法和RBST算法的吞吐率比较结果见图6。由图6可知,当读取器辐射区域内标签数相同时,MMSE-FSA算法的吞吐量高于帧时隙ALOHA算法和RBST算法的。当标签数为1 000时,MMSE-FSA算法的吞吐率为0.8,比帧时隙ALOHA算法和RBST算法的分别提高了340%,58%。在辐射范围内,MMSE-FSA算法的吞吐量可以保持在0.8左右,识别效率有了较大提升。

图6 不同算法吞吐率变化曲线
图7为MMSE-FSA算法、帧时隙ALOHA算法和RBST算法碰撞时隙数的比较结果。由图7可知,如果标签总数相同,MMSE-FSA算法产生的碰撞时隙数最少,当标签总数从0~1 000变化时,MMSE-FSA算法碰撞时隙数变化最为缓慢。当标签数为1 000时,MMSE-FSA算法相比于RBST算法碰撞时隙数减少了830个,比帧时隙ALOHA算法少3 200个。
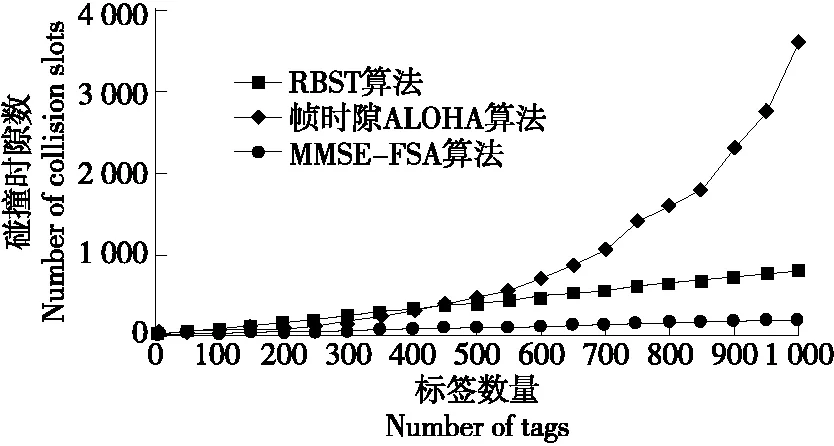
图7 不同算法碰撞时隙数变化曲线
图8为MMSE-FSA算法与帧时隙ALOHA算法和RBST算法的识别时间比较结果。由图8可知,当标签总数从0~1 000变化时,MMSE-FSA算法识别时间变化最为缓慢,比帧时隙ALOHA算法和RBST算法花费的时间短。当标签数为1 000时,MMSE-FSA算法的识别时间相比于RBST算法的降低了3.7 s,比帧时隙ALOHA算法的降低了8.2 s。MMSE-FSA算法有效降低了识别时间,相对于帧时隙ALOHA算法和RBST算法,其识别速度有了较大提升。

图8 不同算法识别时间变化曲线
综上,MMSE-FSA算法完成了对大量标签识别认证过程,采用最小均方误差预编码技术对帧时隙ALOHA算法进行了改进,不仅降低了时隙总数、碰撞数,而且识别时间也得到了一定的改善,稳定性较好,具有一定的实际意义。
4 结论
文中提出了一种结合帧时隙ALOHA算法和最小均方误差预编码技术的RFID系统防碰撞算法。当标签总数为1 000时,改进帧时隙ALOHA算法显著提升了系统吞吐量,降低了标签识别时间,减少了碰撞时隙数量。考虑到当前的试验设备和数据规模,文中提出的食品RFID标签冲突检测的防碰撞算法仍处于起步阶段,仅对[0,1 000]内标签进行了仿真分析,后续应对大规模识别数据进行研究,以适应未来不断变化的应用环境。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
舰船电子对抗(2020年2期)2020-06-23
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
经济研究导刊(2018年26期)2018-11-14
现代计算机(2017年5期)2017-03-29
舰船电子对抗(2016年3期)2016-12-13
电子制作(2016年1期)2016-11-07
